Showing posts with label T-SQL. Show all posts
Showing posts with label T-SQL. Show all posts
Wednesday, November 29, 2017
Use T-SQL to create caveman graphs
{kind=link}
I found this technique on Rich Benner's SQL Server Blog: Visualising the Marvel Cinematic Universe in T-SQL and decided to play around with it after someone asked me to give him the sizes of all databases on a development instance of SQL Server
The way it works is that you take the size of the database and then divide that number against the total size of all databases. You then use the replicate function with the | (pipe) character to generate the 'graph' so 8% will look like this ||||||||
You can use this for tables with most rows, a count per state etc etc. By looking at the output the graph column adds a nice visual effect to it IMHO
Here is what the final query looks like
SELECT database_name = DB_NAME(database_id) , total_size_GB = CAST(SUM(size) * 8. / 1024/1024 AS DECIMAL(30,2)) , percent_size = (CONVERT(decimal(30,4),(SUM(size) / (SELECT SUM(CONVERT(decimal(30,4),size)) FROM sys.master_files WITH(NOWAIT)))) *100.00) , graph = replicate('|',((convert(decimal(30,2),(SUM(size) / (SELECT SUM(CONVERT(decimal(30,2),size)) FROM sys.master_files WITH(NOWAIT)))) *100))) FROM sys.master_files WITH(NOWAIT) GROUP BY database_id ORDER BY 3 DESC
And here is the output (I blanked out the DB name in the output below), there are 48 databases, 15 of them show a bar, the rest don't because they use less than 0.5% of space.
{kind=link}
Do you see how you can quickly tell visually that the top DB is about twice as large as the next DB?
Those guys in Lascaux would have been so proud, only if they could see this :-)
Monday, July 10, 2017
T-SQL Tuesday #92, Lessons learned the hard way
This month's T-SQL Tuesday is hosted by Raul Gonzalez, he proposed the following: For this month, I want you peers to write about those important lessons that you learned the hard way, for instance something you did and put your systems down or maybe something you didn’t do and took your systems down. It can be also a bad decision you or someone else took back in the day and you’re still paying for it…
There are so many things to share here so everybody can learn from each others mistakes, because all of us were once a beginner and no one is born with any knowledge about SQL Server.
Please do not be ashamed of sharing your experiences, you can anonymize the whole story if you want but remember all people make mistakes, the important is to learn from them and try not to repeat them in the future.
Before we start, do you ever wonder why in job postings they ask for a minimum of n years of experience? Well what is experience but the accumulation of mistakes you have made over time. Once you drop a table, I guarantee you, you won't do it again :-) So when they ask for n years of experience what they are saying is.... hey I know you messed up, and I know you did it somewhere else and not here, we are glad you did it somewhere else, but I think you won't make those mistakes again, so we are willing to hire you now.....
So here are my stories
Script out proc with drop dependent object
I still remember this one, even though it has been over 15 years ago. In Enterprise Manager/ Query Analyzer on SQL Server 7, when scripting out a proc there was an option you could check, this was the drop dependent objects option. Somehow that was checked and the table used in the proc was also dropped
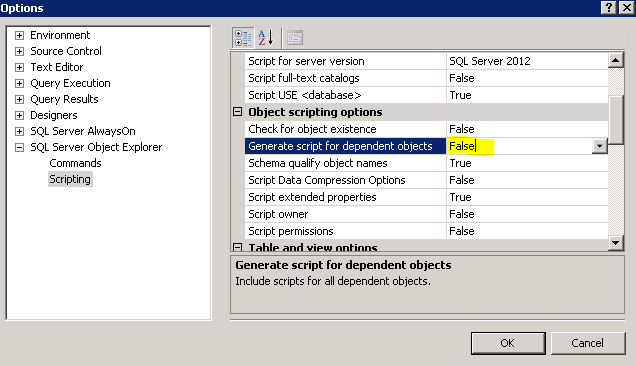
I don't have Query Analyzer installed anywhere but even in SSMS there is an option to script the dependent objects...luckily the default is false..
So I got a nice call from one of the New York City agencies that data wasn't there. I was just about to start my lunch. I lost my appetite real quick. SO what I did was take a full backup and then did a restore with stop at to 2 minutes before I dropped the table. This worked and all the data was there. I however lost my appetite and did not eat my lunch that day. But I can tell you that I have never dropped a table again.
Script out table to make history table
This is one of my favorite lessons, lucky for me a co-worker managed to do this
We needed a history table, this table would be populated each month with the current data, the main table then would be cleaned and repopulated via a DTS package. So what do you do? You script out the current table, change the table name and run the script right? Seems easy enough.....
So this was done.... an hour or 2 passes and we get a call that the original table doesn't exist.
What happened? Well the script had a drop table and a create table part, the table name change was only done in the create part...ooops.... not good
Staging server, test server..what's that?
I worked in at least 2 companies that did not have any test/staging or QA environment. need a change..right click DTS package right on production, make changes and save.... how productive people were..... I am still amazed that nobody did any real bad things... But I believe we did use source control, but it was Visual SourceSafe 6.0
Start transaction... walk away casually
One time I had a query window open in SSMS and there was an insert or update statement and nothing else. hit F5 and casually walked away. After a couple of minutes some people told me things started to take a long time and timing out. Alright I executed sp_who2 and saw a SID in the BlkBy column in many rows. Ready to go find the person and give this person a nice lecture, I noticed that the SPID was mine? WTF, I looked at my query window..nothing. I then scrolled up and as you can guess by now there was a nice BEGIN TRANSACTION statement at the first line.... Argh... so I commited the thing and that was the end of that. At least I didn't go home for the day yet.
Insert SELECT after DELETE and before WHERE clause
Sometimes, you have code like this
DELETE Sometable
WHERE a= b
you want to see what that will affect, so you do this and run the bottom 2 lines
DELETE Sometable
SELECT * FROM Sometable
WHERE a= b
Of course if you leave it like that, for example in a SQL Agent job, you will learn the hard way that all your data is gone, not just the stuff that the WHERE clause applies to
Use SQL to bring down other things in the company
The request was that support wanted to know immediately when an order was placed. No problem, we can add a trigger that populates a table and then we have a job that runs once a minute to email the support group. Sounds reasonable right? Someone decided to do a little testing.... this person created 100,000 entries.... I guess you can imagine what happens next. Yep, the email server was overloaded. We had to quickly delete these rows and truncate the table that was used to send the emails.
Change the user without telling anyone
Another one brought to you by a co-worker. This person needed some stored procedures to be deployed to production. No problem, put in ticket and we will get it done. So stored procedures were deployed and the front end code was getting some errors. It turns out that this person decided to create a new user and use that instead of the user used in all the other connection strings. At least this was easy to fix
I will leave you with this horror story from the microsoft.public.sqlserver newsgroup, I tried to find this thread but I was unable to find it.
Some person tried to do a backup but this person got confused and somehow managed to do a restore from the only backup they had, this backup was 1 year old. The advice this person got? Update resume.
Not good, not good at all
There are so many things to share here so everybody can learn from each others mistakes, because all of us were once a beginner and no one is born with any knowledge about SQL Server.
Please do not be ashamed of sharing your experiences, you can anonymize the whole story if you want but remember all people make mistakes, the important is to learn from them and try not to repeat them in the future.
Before we start, do you ever wonder why in job postings they ask for a minimum of n years of experience? Well what is experience but the accumulation of mistakes you have made over time. Once you drop a table, I guarantee you, you won't do it again :-) So when they ask for n years of experience what they are saying is.... hey I know you messed up, and I know you did it somewhere else and not here, we are glad you did it somewhere else, but I think you won't make those mistakes again, so we are willing to hire you now.....
So here are my stories
Script out proc with drop dependent object
I still remember this one, even though it has been over 15 years ago. In Enterprise Manager/ Query Analyzer on SQL Server 7, when scripting out a proc there was an option you could check, this was the drop dependent objects option. Somehow that was checked and the table used in the proc was also dropped
I don't have Query Analyzer installed anywhere but even in SSMS there is an option to script the dependent objects...luckily the default is false..
{kind=link}
So I got a nice call from one of the New York City agencies that data wasn't there. I was just about to start my lunch. I lost my appetite real quick. SO what I did was take a full backup and then did a restore with stop at to 2 minutes before I dropped the table. This worked and all the data was there. I however lost my appetite and did not eat my lunch that day. But I can tell you that I have never dropped a table again.
Script out table to make history table
This is one of my favorite lessons, lucky for me a co-worker managed to do this
We needed a history table, this table would be populated each month with the current data, the main table then would be cleaned and repopulated via a DTS package. So what do you do? You script out the current table, change the table name and run the script right? Seems easy enough.....
So this was done.... an hour or 2 passes and we get a call that the original table doesn't exist.
What happened? Well the script had a drop table and a create table part, the table name change was only done in the create part...ooops.... not good
Staging server, test server..what's that?
I worked in at least 2 companies that did not have any test/staging or QA environment. need a change..right click DTS package right on production, make changes and save.... how productive people were..... I am still amazed that nobody did any real bad things... But I believe we did use source control, but it was Visual SourceSafe 6.0
Start transaction... walk away casually
One time I had a query window open in SSMS and there was an insert or update statement and nothing else. hit F5 and casually walked away. After a couple of minutes some people told me things started to take a long time and timing out. Alright I executed sp_who2 and saw a SID in the BlkBy column in many rows. Ready to go find the person and give this person a nice lecture, I noticed that the SPID was mine? WTF, I looked at my query window..nothing. I then scrolled up and as you can guess by now there was a nice BEGIN TRANSACTION statement at the first line.... Argh... so I commited the thing and that was the end of that. At least I didn't go home for the day yet.
Insert SELECT after DELETE and before WHERE clause
Sometimes, you have code like this
DELETE Sometable
WHERE a= b
you want to see what that will affect, so you do this and run the bottom 2 lines
DELETE Sometable
SELECT * FROM Sometable
WHERE a= b
Of course if you leave it like that, for example in a SQL Agent job, you will learn the hard way that all your data is gone, not just the stuff that the WHERE clause applies to
Use SQL to bring down other things in the company
The request was that support wanted to know immediately when an order was placed. No problem, we can add a trigger that populates a table and then we have a job that runs once a minute to email the support group. Sounds reasonable right? Someone decided to do a little testing.... this person created 100,000 entries.... I guess you can imagine what happens next. Yep, the email server was overloaded. We had to quickly delete these rows and truncate the table that was used to send the emails.
Change the user without telling anyone
Another one brought to you by a co-worker. This person needed some stored procedures to be deployed to production. No problem, put in ticket and we will get it done. So stored procedures were deployed and the front end code was getting some errors. It turns out that this person decided to create a new user and use that instead of the user used in all the other connection strings. At least this was easy to fix
I will leave you with this horror story from the microsoft.public.sqlserver newsgroup, I tried to find this thread but I was unable to find it.
Some person tried to do a backup but this person got confused and somehow managed to do a restore from the only backup they had, this backup was 1 year old. The advice this person got? Update resume.
Not good, not good at all
Sunday, January 01, 2017
Running queries against the songs you played with Alexa
{kind=link}
My son got an Amazon Echo for Christmas. We use the Echo mostly to play music. I have setup IFTTT (If This Then That) to save the name of any song we play in a Google Sheet.
Between December 26 and January 1st we played a little over 1000 songs. Most of the time I would just say something like "Alexa, play 80s music" or "Alexa, play 70s music" this is why you might see songs from the same period played in a row
It is no coincidence that a lot of George Michael songs were played, he died on Christmas day. The most played song was requested by my youngest son Nicholas, he loves Demons by Imagine Dragons
I decided to import the Alexa data into SQL Server and run some queries. If you want to follow along, you can get the file here from GitHub: Songs played by Alexa
I exported the Google Sheet to a tab delimited file, I saved this file on my C drive, I created a table and did a BULK INSERT to populate this table with the data from this file
USE tempdb GO CREATE TABLE AlexaSongs(PlayDate varchar(100), SongName varchar(200), Artist varchar(200), Album varchar(200)) GO BULK INSERT AlexaSongs FROM 'c:\Songs played with Alexa.tsv' WITH ( FIELDTERMINATOR =' ', ROWTERMINATOR = '\n' );
The date in the file is not a format that can be converted automatically, it looks like this December 26, 2016 at 09:53AM
I decided to add a date column and then convert that value with T-SQL. I did this by using the REPLACE function and replacing ' at ' with ' '
ALTER TABLE AlexaSongs ADD DatePlayed datetime GO UPDATE AlexaSongs SET DatePlayed = CONVERT(datetime, replace(playdate,' at ',' ')) GO
Now that this is all done, we can run some queries
What is the artist which we played the most?
SELECT Artist, count(SongName) As SongCount FROM AlexaSongs GROUP BY Artist ORDER BY SongCount DESC
Artist SongCount
George Michael 33
Nirvana 32
Imagine Dragons 22
Josh Groban 19
Eagles 17
Stone Temple Pilots 17
Mariah Carey 16
Meghan Trainor 15
Simon & Garfunkel 13
Pearl Jam 12
As you can see that is George Michael
How about if we want to know how many unique songs we played by artist?
SELECT Artist, count(DISTINCT SongName) As DistinctSongCount FROM AlexaSongs GROUP BY Artist ORDER BY DistinctSongCount DESC
Artist DistinctSongCount
Nirvana 25
Stone Temple Pilots 16
George Michael 15
Eagles 12
Simon & Garfunkel 12
Josh Groban 12
Mariah Carey 11
Michael Bubl+¬ 9
Snoop Dogg 9
Harry Connick Jr. 9
In this case Nirvana wins
How about the 10 most played songs? To answer that question and grab ties, we can use WITH TIES
SELECT TOP 10 WITH TIES Artist, SongName, COUNT(*) As SongCount FROM AlexaSongs GROUP BY Artist,SongName ORDER BY SongCount DESC
Here are the results
Artist SongName SongCount
Imagine Dragons Radioactive 12
Jason Mraz I'm Yours 9
Pearl Jam Yellow Ledbetter 6
Josh Groban When You Say You Love Me 5
Oasis Wonderwall (Remastered) 4
House Of Pain Jump Around [Explicit] 4
Meghan Trainor Lips Are Movin 4
Imagine Dragons Round And Round 4
Nirvana Smells Like Teen Spirit 4
Sir Mix-A-Lot Baby Got Back [Explicit] 4
George Michael Careless Whisper 4
George Michael Faith (Remastered) 4
George Michael Father Figure 4
George Michael Freedom! '90 4
So what other interesting queries can you come up with? How about how many Christmas related songs were there? Would the query look something like this?
SELECT TOP 10 WITH TIES Artist, SongName, COUNT(*) As SongCount FROM AlexaSongs WHERE SongName LIKE '%christmas%' OR SongName LIKE '%xmas%' OR SongName LIKE '%santa%' GROUP BY Artist,SongName ORDER BY SongCount DESC
Maybe you would want to know how many songs you played per day?
SELECT CONVERT(date, DatePlayed) as TheDate, count(*) FROM AlexaSongs GROUP BY CONVERT(date, DatePlayed) ORDER BY TheDate
Or maybe you want to know how many songs with the same title were sung by more than 1 artist?
Is this what the query would look like?
SELECT SongName, count(DISTINCT Artist) As SongCount FROM AlexaSongs GROUP BY SongName HAVING COUNT(*) > 1 ORDER BY SongCount DESC
If you want the song as well as the artist, you can use a windowing function with DENSE_RANK
;WITH cte AS( SELECT Artist, SongName, DENSE_RANK() OVER (PARTITION BY SongName ORDER BY Artist ) AS SongCount FROM AlexaSongs ) SELECT * FROM cte WHERE SongCount > 1
That is all for this post, I will keep collecting this data till next Christmas and hopefully will be able to run some more interesting queries
Sunday, August 17, 2008
Only In A Database Can You Get 1000% + Improvement By Changing A Few Lines Of Code
Take a look at this query.
SELECT * FROM
(
SELECT customer_id, ‘MTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table
WHERE YEAR(payment_dt) = YEAR(GETDATE())
and MONTH(payment_dt) = MONTH(GETDATE())
GROUP BY customer_id) MTD_payments
UNION ALL
(
SELECT customer_id, ‘YTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table
WHERE
WHERE YEAR(payment_dt) = YEAR(GETDATE())
GROUP BY customer_id) YTD_payments
UNION ALL
(
SELECT customer_id, ‘LTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table) LTD_payments
) payments_report
ORDER BY customer_id, record_type
Can you see the problem?
A person had this query, it would run for over 24 hours. Wow, that is pretty bad, I don't think I had ever written something that ran over an hour, and the ones I did were mostly defragmentation and update statistics jobs.
The problem is that the following piece of code
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
is not sargable. First what does it mean to be sargable? A query is said to be sargable if the DBMS engine can take advantage of an index to speed up the execution of the query (using index seeks, not covering indexes). The term is derived from a contraction of Search ARGument Able.
This query is not sargable because there is a function on the column, whenever you use a function on the column you will not get an index seek but an index scan. The difference between an index seek and an index scan can be explained like this: when searching for something in a book, you go to the index in the back find the page number and go to the page, that is an index seek. When looking for something in a book you go from page one until the last page, read all the words on all the ages and get what you need, that was an index scan. Do you see how much more expensive in terms of performance that was?
Let's get back to the query, what can we do to make this piece of code use an index seek?
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
You would change it to this:
where payment_dt>= dateadd(mm, datediff(mm, 0, getdate())+0, 0)
and payment_dt < dateadd(mm, datediff(mm, 0, getdate())+1, 0)
You can see the complete question on the MSDN forum site here:
http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3746751&SiteID=1
The Person said that his query went from over 24 hours to 36 seconds. Wow!! That is very significant. hardware cannot help you out if you have bad queries like that.
The same exact day I answered a very similar question, take a look here: http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3752248&SiteID=1
The person had this
If you are interested in some blogposts about dates, take a look at these two which I wrote earlier
How Are Dates Stored In SQL Server?
Do You Know How Between Works With Dates?
SELECT * FROM
Can you see the problem?
A person had this query, it would run for over 24 hours. Wow, that is pretty bad, I don't think I had ever written something that ran over an hour, and the ones I did were mostly defragmentation and update statistics jobs.
The problem is that the following piece of code
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
is not sargable. First what does it mean to be sargable? A query is said to be sargable if the DBMS engine can take advantage of an index to speed up the execution of the query (using index seeks, not covering indexes). The term is derived from a contraction of Search ARGument Able.
This query is not sargable because there is a function on the column, whenever you use a function on the column you will not get an index seek but an index scan. The difference between an index seek and an index scan can be explained like this: when searching for something in a book, you go to the index in the back find the page number and go to the page, that is an index seek. When looking for something in a book you go from page one until the last page, read all the words on all the ages and get what you need, that was an index scan. Do you see how much more expensive in terms of performance that was?
Let's get back to the query, what can we do to make this piece of code use an index seek?
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
You would change it to this:
where payment_dt>= dateadd(mm, datediff(mm, 0, getdate())+0, 0)
and payment_dt < dateadd(mm, datediff(mm, 0, getdate())+1, 0)
You can see the complete question on the MSDN forum site here:
http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3746751&SiteID=1
The Person said that his query went from over 24 hours to 36 seconds. Wow!! That is very significant. hardware cannot help you out if you have bad queries like that.
The same exact day I answered a very similar question, take a look here: http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3752248&SiteID=1
The person had this
ANDDATEDIFF(d,'08/10/2008', DateCreated)>= 0
ANDDATEDIFF(d, DateCreated,'08/15/2008')>= 0
I told him to change it to this
AND DateCreated>= '08/10/2008'
and DateCreated <= '08/15/2008'
And that solved that query. If you are interested in some more performance, I have written some Query Optimization items on the LessThanDot Wiki. Below are some direct links
Case Sensitive Search
No Functions on Left Side of Operator
Query Optimizations With Dates
Optimization: Set Nocount On
No Math In Where Clause
Don't Use (select *), but List Columns
If you are interested in some blogposts about dates, take a look at these two which I wrote earlier
How Are Dates Stored In SQL Server?
Do You Know How Between Works With Dates?
Labels:
database,
Dates,
Indexing,
Performance Tuning,
rdbms,
SQL,
T-SQL,
temporal data
Tuesday, May 27, 2008
Interview With Erland Sommarskog About SQL Server and Transact SQL
I have interviewed Erland Sommarskog, you can find that interview here: Interview With Erland Sommarskog About SQL Server and Transact SQL
Enjoy
Enjoy
Labels:
Interview,
SQL Server 2000,
SQL Server 2005,
SQL Server 2008,
T-SQL
Monday, May 07, 2007
Three Ways To Return All Rows That Contain Uppercase Characters Only
How do you select all the rows that contain uppercase characters only? There sre three ways to do this
1 Compare with BINARY_CHECKSUM
2 Use COLLATE
3 Cast to varbinary
Let's first create the table and also some test data
CREATE TABLE #tmp ( x VARCHAR(10) NOT NULL )
INSERT INTO #tmp
SELECT 'Word' UNION ALL
SELECT 'WORD' UNION ALL
SELECT 'ABC' UNION ALL
SELECT 'AbC' UNION ALL
SELECT 'ZxZ' UNION ALL
SELECT 'ZZZ' UNION ALL
SELECT 'word'
if we want only the uppercase columns then this is supposed to be our output
WORD
ABC
ZZZ
Let's get started, first up is BINARY_CHECKSUM
SELECT x
FROM #TMP
WHERE BINARY_CHECKSUM(x) = BINARY_CHECKSUM(UPPER(x))
Second is COLLATE
SELECT x
FROM #TMP
WHERE x = UPPER(x) COLLATE SQL_Latin1_General_CP1_CS_AS
Third is Cast to varbinary
SELECT x
FROM #TMP
WHERE CAST(x AS VARBINARY(10)) = CAST(UPPER(x) AS VARBINARY(10))
Of course if you database is already case sensitive you can just do the following
SELECT x
FROM #TMP
WHERE UPPER(x) = x
That will work, how do you find out what collation was used when your database was created? You can use DATABASEPROPERTYEX for that. I use the model DB here because when you create a new DB by default it inherits all the properties from the model DB.
When I run this
SELECT DATABASEPROPERTYEX( 'model' , 'collation' )
I get this as output: SQL_Latin1_General_CP1_CI_AS
What does all that junk mean? Well let's run the following function (yes those are 2 colons ::)
SELECT *
FROM ::fn_helpcollations ()
WHERE NAME ='SQL_Latin1_General_CP1_CI_AS'
The description column contains this info
Latin1-General, case-insensitive, accent-sensitive,
kanatype-insensitive, width-insensitive for Unicode Data,
SQL Server Sort Order 52 on Code Page 1252 for non-Unicode Data
You can read some more info about Selecting a SQL Collation here: http://msdn2.microsoft.com/en-us/library/aa176552(SQL.80).aspx
1 Compare with BINARY_CHECKSUM
2 Use COLLATE
3 Cast to varbinary
Let's first create the table and also some test data
CREATE TABLE #tmp ( x VARCHAR(10) NOT NULL )
INSERT INTO #tmp
SELECT 'Word' UNION ALL
SELECT 'WORD' UNION ALL
SELECT 'ABC' UNION ALL
SELECT 'AbC' UNION ALL
SELECT 'ZxZ' UNION ALL
SELECT 'ZZZ' UNION ALL
SELECT 'word'
if we want only the uppercase columns then this is supposed to be our output
WORD
ABC
ZZZ
Let's get started, first up is BINARY_CHECKSUM
SELECT x
FROM #TMP
WHERE BINARY_CHECKSUM(x) = BINARY_CHECKSUM(UPPER(x))
Second is COLLATE
SELECT x
FROM #TMP
WHERE x = UPPER(x) COLLATE SQL_Latin1_General_CP1_CS_AS
Third is Cast to varbinary
SELECT x
FROM #TMP
WHERE CAST(x AS VARBINARY(10)) = CAST(UPPER(x) AS VARBINARY(10))
Of course if you database is already case sensitive you can just do the following
SELECT x
FROM #TMP
WHERE UPPER(x) = x
That will work, how do you find out what collation was used when your database was created? You can use DATABASEPROPERTYEX for that. I use the model DB here because when you create a new DB by default it inherits all the properties from the model DB.
When I run this
SELECT DATABASEPROPERTYEX( 'model' , 'collation' )
I get this as output: SQL_Latin1_General_CP1_CI_AS
What does all that junk mean? Well let's run the following function (yes those are 2 colons ::)
SELECT *
FROM ::fn_helpcollations ()
WHERE NAME ='SQL_Latin1_General_CP1_CI_AS'
The description column contains this info
Latin1-General, case-insensitive, accent-sensitive,
kanatype-insensitive, width-insensitive for Unicode Data,
SQL Server Sort Order 52 on Code Page 1252 for non-Unicode Data
You can read some more info about Selecting a SQL Collation here: http://msdn2.microsoft.com/en-us/library/aa176552(SQL.80).aspx
Sunday, February 11, 2007
Ten SQL Server Functions That You Hardly Use But Should
Below are 10 SQL Server functions that are hardly used but should be used a lot more
I will go in more detail later on but here is a list of the ten functions that I am talking about
I also cross posted this here: http://dotnetsamplechapters.blogspot.com/2007/09/ten-sql-server-functions-that-you.html
BINARY_CHECKSUM
SIGN
COLUMNPROPERTY
DATALENGTH
ASCII, UNICODE
NULLIF
PARSENAME
STUFF
REVERSE
GETUTCDATE
BINARY_CHECKSUM
BINARY_CHECKSUM is handy if you want to check for data differences between 2 rows of data
In order to see what rows are in table 1 and not in table 2 and vice versa you can do 2 left joins, 2 right joins or 1 left and 1 right join. To get the rows that are different you can use BINARY_CHECKSUM. You have to run this example o SQL Server 2000 to see it work, you can ofcourse use any tables just modify the queries
Let’s get started…
--let's copy over 20 rows to a table named authors2
SELECT TOP 20 * INTO tempdb..authors2
FROM pubs..authors
--update 5 records by appending X to the au_fname
SET ROWCOUNT 5
UPDATE tempdb..authors2
SET au_fname =au_fname +'X'
--Set rowcount back to 0
SET ROWCOUNT 0
--let's insert a row that doesn't exist in pubs
INSERT INTO tempdb..authors2
SELECT '666-66-6666', au_lname, au_fname, phone, address, city, state, zip, contract
FROM tempdb..authors2
WHERE au_id ='172-32-1176'
--*** The BIG SELECT QUERY --***
--Not in Pubs
SELECT 'Does Not Exist On Production',t2.au_id
FROM pubs..authors t1
RIGHT JOIN tempdb..authors2 t2 ON t1.au_id =t2.au_id
WHERE t1.au_id IS NULL
UNION ALL
--Not in Temp
SELECT 'Does Not Exist In Staging',t1.au_id
FROM pubs..authors t1
LEFT JOIN tempdb..authors2 t2 ON t1.au_id =t2.au_id
WHERE t2.au_id IS NULL
UNION ALL
--Data Mismatch
SELECT 'Data Mismatch', t1.au_id
FROM( SELECT BINARY_CHECKSUM(*) AS CheckSum1 ,au_id FROM pubs..authors) t1
JOIN(SELECT BINARY_CHECKSUM(*) AS CheckSum2,au_id FROM tempdb..authors2) t2 ON t1.au_id =t2.au_id
WHERE CheckSum1 CheckSum2
--Clean up
DROP TABLE tempdb..authors2
GO
SIGN
Sometimes you are asked by the front-end/middle-tier developers to return a rowcount as well with the result set. However the developers want you to return 1 if there are rows and 0 if there are none. How do you do such a thing?
Well I am going to show you two ways. the first way is by using CASE and @@ROWCOUNT, the second way is by using the SIGN function
For CASE we will do this
RETURN CASE WHEN @@ROWCOUNT> 0 THEN 1 ELSE 0 END
So that's pretty simple, if @@ROWCOUNT is greater than 0 return 1 for everything else return 0
Using the SIGN function is even easier, all you have to do is this
RETURN SIGN(@@ROWCOUNT)
That's all, SIGN Returns the positive (+1), zero (0), or negative (-1) sign of the given expression. In this case -1 is not possible but the other two values are
So let's see this in action
USE pubs
GO
--Case Proc
CREATE PROCEDURE TestReturnValues
@au_id VARCHAR(49) ='172-32-1176'
AS
SELECT *
FROM authors
WHERE au_id =@au_id
RETURN CASE WHEN @@ROWCOUNT> 0 THEN 1 ELSE 0 END
GO
--Sign Proc
CREATE PROCEDURE TestReturnValues2
@au_id VARCHAR(49) ='172-32-1176'
AS
SELECT *
FROM authors
WHERE au_id =@au_id
RETURN SIGN(@@ROWCOUNT)
GO
--Case Proc, 1 will be returned; default value is used
DECLARE @Rowcount int
EXEC @Rowcount = TestReturnValues
SELECT @Rowcount
GO
--Case Proc, 0 will be returned; dummy value is used
DECLARE @Rowcount int
EXEC @Rowcount = TestReturnValues 'ABC'
SELECT @Rowcount
GO
--Sign Proc, 1 will be returned; default value is used
DECLARE @Rowcount int
EXEC @Rowcount = TestReturnValues2
SELECT @Rowcount
GO
--Sign Proc, 0 will be returned; dummy value is used
DECLARE @Rowcount int
EXEC @Rowcount = TestReturnValues2 'ABC'
SELECT @Rowcount
GO
--Help the environment by recycling ;-)
DROP PROCEDURE TestReturnValues2,TestReturnValues
GO
COLUMNPROPERTY
COLUMNPROPERTY is handy if you need to find scale, precision, if it is an identity column and more. I have listed all of them below
CREATE TABLE blah (ID DECIMAL(5,2) not null DEFAULT 99)
INSERT blah DEFAULT VALUES
SELECT * FROM blah
SELECT COLUMNPROPERTY( OBJECT_ID('blah'),'ID','AllowsNull') AS AllowsNull,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsComputed') AS IsComputed,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsCursorType') AS IsCursorType,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsDeterministic') AS IsDeterministic,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsFulltextIndexed') AS IsFulltextIndexed,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsIdentity') AS IsFulltextIndexed,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsIdNotForRepl') AS IsIdNotForRepl,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsIndexable') AS IsIndexable,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsOutParam') AS IsOutParam,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsPrecise') AS IsPrecise,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsRowGuidCol') AS IsRowGuidCol,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','Precision') AS 'Precision',
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','Scale') AS Scale,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','UsesAnsiTrim') AS UsesAnsiTrim
FROM Blah
So what does all that stuff mean?
AllowsNull
Allows null values. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsComputed
The column is a computed column. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsCursorType
The procedure parameter is of type CURSOR. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsDeterministic
The column is deterministic. This property applies only to computed columns and view columns. 1 = TRUE
0 = FALSE
NULL = Invalid input. Not a computed column or view column.
IsFulltextIndexed
The column has been registered for full-text indexing. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsIdentity
The column uses the IDENTITY property. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsIdNotForRepl
The column checks for the IDENTITY_INSERT setting. If IDENTITY NOT FOR REPLICATION is specified, the IDENTITY_INSERT setting is not checked. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsIndexable
The column can be indexed. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsOutParam
The procedure parameter is an output parameter. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsPrecise
The column is precise. This property applies only to deterministic columns. 1 = TRUE
0 = FALSE
NULL = Invalid input. Not a deterministic column
IsRowGuidCol
The column has the uniqueidentifier data type and is defined with the ROWGUIDCOL property. 1 = TRUE
0 = FALSE
NULL = Invalid input
Precision
Precision for the data type of the column or parameter. The precision of the specified column data type
NULL = Invalid input
Scale
Scale for the data type of the column or parameter. The scale
NULL = Invalid input
UsesAnsiTrim
ANSI padding setting was ON when the table was initially created. 1= TRUE
0= FALSE
NULL = Invalid input
DATALENGTH
Okay so you know the LEN function but do you know the DATALENGTH function? There are two major difference between LEN and DATALENGTH.
The first one deals with trailing spaces, execute the following code and you will see that LEN returns 3 while DATALENGTH returns 4
DECLARE @V VARCHAR(50)
SELECT @V ='ABC '
SELECT LEN(@V),DATALENGTH(@V),@V
The second difference deals with unicode character data, as you know unicode uses 2 bytes to store 1 character
Run the following example and you will see that LEN returns 3 while DATALENGTH returns 6
DECLARE @V NVARCHAR(50)
SELECT @V ='ABC'
SELECT LEN(@V),DATALENGTH(@V),@V
If you do DATALENGTH(CONVERT(VARCHAR,@V)) you will get the same as LEN because LEN does a RTRIM and converts to VARCHAR before returning
ASCII, CHAR,UNICODE
ASCII will give you the ascii code for a character so for A you will get 65
CHAR does the reverse of ascii CHAR(65) returns A
UNICODE will give you the unicode value for a character
NCHAR will give you the character for a unicode or ascii value
let's see how this works
SELECT ASCII('A'),CHAR(65),CHAR(ASCII('A')),
UNICODE(N'Λ'),NCHAR(923),NCHAR(UNICODE(N'Λ'))
NULLIF
NULLIF Returns a null value if the two specified expressions are equivalent.
Syntax
NULLIF ( expression , expression )
DECLARE @v VARCHAR(20)
SELECT @v = ' '
SELECT NULLIF(@v,' ')
You can combine NULLIF with COALESCE if you want to test for NULLS and Blanks for example
DECLARE @v VARCHAR(20)
SELECT @v = ' '
SELECT COALESCE(NULLIF(@v,' '),'N/A')
Here is another NULLIF example:
CREATE TABLE Blah (SomeCol VARCHAR(33))
INSERT Blah VALUES(NULL)
INSERT Blah VALUES('')
INSERT Blah VALUES(' ')
INSERT Blah VALUES('A')
INSERT Blah VALUES('B B')
--Using COALESCE and NULLIF
SELECT COALESCE(NULLIF(RTRIM(SomeCol),' '),'N/A')
FROM Blah
--Using CASE
SELECT CASE WHEN RTRIM(SomeCol) = '' THEN 'N/A'
WHEN RTRIM(SomeCol) IS NULL THEN 'N/A'
ELSE SomeCol END SomeCol
FROM Blah
Output for both queries
-----------------------
N/A
N/A
N/A
A
B B
PARSENAME
PARSENAME retrieves parts of string delimited by dots. It is used to split DataBaseServer, DataBaseName, ObjectOwner and ObjectName but you can use it to split IP addresses, names etc
DECLARE @ParseString VARCHAR(100)
SELECT @ParseString = 'DataBaseServer.DataBaseName.ObjectOwner.ObjectName'
SELECT PARSENAME(@ParseString,4),
PARSENAME(@ParseString,3),
PARSENAME(@ParseString,2),
PARSENAME(@ParseString,1)
CREATE TABLE #Test (
SomeField VARCHAR(49))
INSERT INTO #Test
VALUES ('aaa-bbbbb')
INSERT INTO #Test
VALUES ('ppppp-bbbbb')
INSERT INTO #Test
VALUES ('zzzz-xxxxx')
--using PARSENAME
SELECT PARSENAME(REPLACE(SomeField,'-','.'),2)
FROM #Test
Another example:
CREATE TABLE BadData (FullName varchar(20) NOT NULL);
INSERT INTO BadData (FullName)
SELECT 'Clinton, Bill' UNION ALL
SELECT 'Johnson, Lyndon, B.' UNION ALL
SELECT 'Bush, George, H.W.';
Split the names into 3 columns
Your output should be this:
LastName FirstName MiddleInitial
Clinton Bill
Johnson Lyndon B.
Bush George H.W.
SELECT FullName,PARSENAME(FullName2,NameLen+1) AS LastName,
PARSENAME(FullName2,NameLen) AS FirstName,
COALESCE(REPLACE(PARSENAME(FullName2,NameLen-1),'~','.'),'') AS MiddleInitial
FROM(
SELECT LEN(FullName) -LEN(REPLACE(FullName,',','')) AS NameLen,
REPLACE(REPLACE(FullName,'.','~'),', ','.') AS FullName2,FullName
FROM BadData) x
STUFF
STUFF is another function that is hardly used, it is useful if you want to replace or add characters inside data
Take a look at the code below. the first STUFF will replace X with 98765, the second STUFF will place 98765 before the X and the third stuff will replace X- with 98765
DECLARE @v VARCHAR(11)
SELECT @v ='-X-'
SELECT STUFF(@v, 2, 1, '98765'),
STUFF(@v, 2, 0, '98765'),
STUFF(@v, 2, 2, '98765')
The STUFF function is very handy if you need to insert dashes in a social security. You can accomplish that by using the function STUFF twice instead of using substring,left and right
DECLARE @v VARCHAR(11)
SELECT @v ='123456789'
SELECT @v,STUFF(STUFF(@v,4,0,'-'),7,0,'-')
REVERSE
REVERSE just reverses the value, for example the code below returns CBA
SELECT REVERSE('ABC')
Reverse is handy if you need to split values, take a look at this example
CREATE TABLE #TestCityStateZip (csz CHAR(49))
INSERT INTO #TestCityStateZip VALUES ('city ,st 12223')
INSERT INTO #TestCityStateZip VALUES ('New York City,NY 10028')
INSERT INTO #TestCityStateZip VALUES ('Princeton , NJ 08536')
INSERT INTO #TestCityStateZip VALUES ('Princeton,NJ 08536 ')
INSERT INTO #TestCityStateZip VALUES ('Long Island City, NY 10013')
INSERT INTO #TestCityStateZip VALUES ('Long Island City, NY 10013 ')
INSERT INTO #TestCityStateZip VALUES ('Long Island City , NY 10013')
INSERT INTO #TestCityStateZip VALUES ('Long Island City ,NY 10013 ')
SELECT LEFT(csz,CHARINDEX(',',csz)-1)AS City,
LEFT(LTRIM(SUBSTRING(csz,(CHARINDEX(',',csz)+1),4)),2) AS State,
RIGHT(RTRIM(csz),CHARINDEX(' ',REVERSE(RTRIM(csz)))-1) AS Zip
FROM #TestCityStateZip
GETUTCDATE
SELECT GETUTCDATE()
Returns the datetime value representing the current UTC time (Universal Time Coordinate or Greenwich Mean Time). The current UTC time is derived from the current local time and the time zone setting in the operating system of the computer on which SQL Server is running.
And that is all, those are the ten functions that you should be using but currently you are not using all of them. Look them up in Books On Line so that you can see some more examples
I will go in more detail later on but here is a list of the ten functions that I am talking about
I also cross posted this here: http://dotnetsamplechapters.blogspot.com/2007/09/ten-sql-server-functions-that-you.html
BINARY_CHECKSUM
SIGN
COLUMNPROPERTY
DATALENGTH
ASCII, UNICODE
NULLIF
PARSENAME
STUFF
REVERSE
GETUTCDATE
BINARY_CHECKSUM
BINARY_CHECKSUM is handy if you want to check for data differences between 2 rows of data
In order to see what rows are in table 1 and not in table 2 and vice versa you can do 2 left joins, 2 right joins or 1 left and 1 right join. To get the rows that are different you can use BINARY_CHECKSUM. You have to run this example o SQL Server 2000 to see it work, you can ofcourse use any tables just modify the queries
Let’s get started…
--let's copy over 20 rows to a table named authors2
SELECT TOP 20 * INTO tempdb..authors2
FROM pubs..authors
--update 5 records by appending X to the au_fname
SET ROWCOUNT 5
UPDATE tempdb..authors2
SET au_fname =au_fname +'X'
--Set rowcount back to 0
SET ROWCOUNT 0
--let's insert a row that doesn't exist in pubs
INSERT INTO tempdb..authors2
SELECT '666-66-6666', au_lname, au_fname, phone, address, city, state, zip, contract
FROM tempdb..authors2
WHERE au_id ='172-32-1176'
--*** The BIG SELECT QUERY --***
--Not in Pubs
SELECT 'Does Not Exist On Production',t2.au_id
FROM pubs..authors t1
RIGHT JOIN tempdb..authors2 t2 ON t1.au_id =t2.au_id
WHERE t1.au_id IS NULL
UNION ALL
--Not in Temp
SELECT 'Does Not Exist In Staging',t1.au_id
FROM pubs..authors t1
LEFT JOIN tempdb..authors2 t2 ON t1.au_id =t2.au_id
WHERE t2.au_id IS NULL
UNION ALL
--Data Mismatch
SELECT 'Data Mismatch', t1.au_id
FROM( SELECT BINARY_CHECKSUM(*) AS CheckSum1 ,au_id FROM pubs..authors) t1
JOIN(SELECT BINARY_CHECKSUM(*) AS CheckSum2,au_id FROM tempdb..authors2) t2 ON t1.au_id =t2.au_id
WHERE CheckSum1 CheckSum2
--Clean up
DROP TABLE tempdb..authors2
GO
SIGN
Sometimes you are asked by the front-end/middle-tier developers to return a rowcount as well with the result set. However the developers want you to return 1 if there are rows and 0 if there are none. How do you do such a thing?
Well I am going to show you two ways. the first way is by using CASE and @@ROWCOUNT, the second way is by using the SIGN function
For CASE we will do this
RETURN CASE WHEN @@ROWCOUNT> 0 THEN 1 ELSE 0 END
So that's pretty simple, if @@ROWCOUNT is greater than 0 return 1 for everything else return 0
Using the SIGN function is even easier, all you have to do is this
RETURN SIGN(@@ROWCOUNT)
That's all, SIGN Returns the positive (+1), zero (0), or negative (-1) sign of the given expression. In this case -1 is not possible but the other two values are
So let's see this in action
USE pubs
GO
--Case Proc
CREATE PROCEDURE TestReturnValues
@au_id VARCHAR(49) ='172-32-1176'
AS
SELECT *
FROM authors
WHERE au_id =@au_id
RETURN CASE WHEN @@ROWCOUNT> 0 THEN 1 ELSE 0 END
GO
--Sign Proc
CREATE PROCEDURE TestReturnValues2
@au_id VARCHAR(49) ='172-32-1176'
AS
SELECT *
FROM authors
WHERE au_id =@au_id
RETURN SIGN(@@ROWCOUNT)
GO
--Case Proc, 1 will be returned; default value is used
DECLARE @Rowcount int
EXEC @Rowcount = TestReturnValues
SELECT @Rowcount
GO
--Case Proc, 0 will be returned; dummy value is used
DECLARE @Rowcount int
EXEC @Rowcount = TestReturnValues 'ABC'
SELECT @Rowcount
GO
--Sign Proc, 1 will be returned; default value is used
DECLARE @Rowcount int
EXEC @Rowcount = TestReturnValues2
SELECT @Rowcount
GO
--Sign Proc, 0 will be returned; dummy value is used
DECLARE @Rowcount int
EXEC @Rowcount = TestReturnValues2 'ABC'
SELECT @Rowcount
GO
--Help the environment by recycling ;-)
DROP PROCEDURE TestReturnValues2,TestReturnValues
GO
COLUMNPROPERTY
COLUMNPROPERTY is handy if you need to find scale, precision, if it is an identity column and more. I have listed all of them below
CREATE TABLE blah (ID DECIMAL(5,2) not null DEFAULT 99)
INSERT blah DEFAULT VALUES
SELECT * FROM blah
SELECT COLUMNPROPERTY( OBJECT_ID('blah'),'ID','AllowsNull') AS AllowsNull,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsComputed') AS IsComputed,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsCursorType') AS IsCursorType,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsDeterministic') AS IsDeterministic,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsFulltextIndexed') AS IsFulltextIndexed,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsIdentity') AS IsFulltextIndexed,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsIdNotForRepl') AS IsIdNotForRepl,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsIndexable') AS IsIndexable,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsOutParam') AS IsOutParam,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsPrecise') AS IsPrecise,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','IsRowGuidCol') AS IsRowGuidCol,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','Precision') AS 'Precision',
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','Scale') AS Scale,
COLUMNPROPERTY( OBJECT_ID('blah'),'ID','UsesAnsiTrim') AS UsesAnsiTrim
FROM Blah
So what does all that stuff mean?
AllowsNull
Allows null values. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsComputed
The column is a computed column. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsCursorType
The procedure parameter is of type CURSOR. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsDeterministic
The column is deterministic. This property applies only to computed columns and view columns. 1 = TRUE
0 = FALSE
NULL = Invalid input. Not a computed column or view column.
IsFulltextIndexed
The column has been registered for full-text indexing. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsIdentity
The column uses the IDENTITY property. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsIdNotForRepl
The column checks for the IDENTITY_INSERT setting. If IDENTITY NOT FOR REPLICATION is specified, the IDENTITY_INSERT setting is not checked. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsIndexable
The column can be indexed. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsOutParam
The procedure parameter is an output parameter. 1 = TRUE
0 = FALSE
NULL = Invalid input
IsPrecise
The column is precise. This property applies only to deterministic columns. 1 = TRUE
0 = FALSE
NULL = Invalid input. Not a deterministic column
IsRowGuidCol
The column has the uniqueidentifier data type and is defined with the ROWGUIDCOL property. 1 = TRUE
0 = FALSE
NULL = Invalid input
Precision
Precision for the data type of the column or parameter. The precision of the specified column data type
NULL = Invalid input
Scale
Scale for the data type of the column or parameter. The scale
NULL = Invalid input
UsesAnsiTrim
ANSI padding setting was ON when the table was initially created. 1= TRUE
0= FALSE
NULL = Invalid input
DATALENGTH
Okay so you know the LEN function but do you know the DATALENGTH function? There are two major difference between LEN and DATALENGTH.
The first one deals with trailing spaces, execute the following code and you will see that LEN returns 3 while DATALENGTH returns 4
DECLARE @V VARCHAR(50)
SELECT @V ='ABC '
SELECT LEN(@V),DATALENGTH(@V),@V
The second difference deals with unicode character data, as you know unicode uses 2 bytes to store 1 character
Run the following example and you will see that LEN returns 3 while DATALENGTH returns 6
DECLARE @V NVARCHAR(50)
SELECT @V ='ABC'
SELECT LEN(@V),DATALENGTH(@V),@V
If you do DATALENGTH(CONVERT(VARCHAR,@V)) you will get the same as LEN because LEN does a RTRIM and converts to VARCHAR before returning
ASCII, CHAR,UNICODE
ASCII will give you the ascii code for a character so for A you will get 65
CHAR does the reverse of ascii CHAR(65) returns A
UNICODE will give you the unicode value for a character
NCHAR will give you the character for a unicode or ascii value
let's see how this works
SELECT ASCII('A'),CHAR(65),CHAR(ASCII('A')),
UNICODE(N'Λ'),NCHAR(923),NCHAR(UNICODE(N'Λ'))
NULLIF
NULLIF Returns a null value if the two specified expressions are equivalent.
Syntax
NULLIF ( expression , expression )
DECLARE @v VARCHAR(20)
SELECT @v = ' '
SELECT NULLIF(@v,' ')
You can combine NULLIF with COALESCE if you want to test for NULLS and Blanks for example
DECLARE @v VARCHAR(20)
SELECT @v = ' '
SELECT COALESCE(NULLIF(@v,' '),'N/A')
Here is another NULLIF example:
CREATE TABLE Blah (SomeCol VARCHAR(33))
INSERT Blah VALUES(NULL)
INSERT Blah VALUES('')
INSERT Blah VALUES(' ')
INSERT Blah VALUES('A')
INSERT Blah VALUES('B B')
--Using COALESCE and NULLIF
SELECT COALESCE(NULLIF(RTRIM(SomeCol),' '),'N/A')
FROM Blah
--Using CASE
SELECT CASE WHEN RTRIM(SomeCol) = '' THEN 'N/A'
WHEN RTRIM(SomeCol) IS NULL THEN 'N/A'
ELSE SomeCol END SomeCol
FROM Blah
Output for both queries
-----------------------
N/A
N/A
N/A
A
B B
PARSENAME
PARSENAME retrieves parts of string delimited by dots. It is used to split DataBaseServer, DataBaseName, ObjectOwner and ObjectName but you can use it to split IP addresses, names etc
DECLARE @ParseString VARCHAR(100)
SELECT @ParseString = 'DataBaseServer.DataBaseName.ObjectOwner.ObjectName'
SELECT PARSENAME(@ParseString,4),
PARSENAME(@ParseString,3),
PARSENAME(@ParseString,2),
PARSENAME(@ParseString,1)
CREATE TABLE #Test (
SomeField VARCHAR(49))
INSERT INTO #Test
VALUES ('aaa-bbbbb')
INSERT INTO #Test
VALUES ('ppppp-bbbbb')
INSERT INTO #Test
VALUES ('zzzz-xxxxx')
--using PARSENAME
SELECT PARSENAME(REPLACE(SomeField,'-','.'),2)
FROM #Test
Another example:
CREATE TABLE BadData (FullName varchar(20) NOT NULL);
INSERT INTO BadData (FullName)
SELECT 'Clinton, Bill' UNION ALL
SELECT 'Johnson, Lyndon, B.' UNION ALL
SELECT 'Bush, George, H.W.';
Split the names into 3 columns
Your output should be this:
LastName FirstName MiddleInitial
Clinton Bill
Johnson Lyndon B.
Bush George H.W.
SELECT FullName,PARSENAME(FullName2,NameLen+1) AS LastName,
PARSENAME(FullName2,NameLen) AS FirstName,
COALESCE(REPLACE(PARSENAME(FullName2,NameLen-1),'~','.'),'') AS MiddleInitial
FROM(
SELECT LEN(FullName) -LEN(REPLACE(FullName,',','')) AS NameLen,
REPLACE(REPLACE(FullName,'.','~'),', ','.') AS FullName2,FullName
FROM BadData) x
STUFF
STUFF is another function that is hardly used, it is useful if you want to replace or add characters inside data
Take a look at the code below. the first STUFF will replace X with 98765, the second STUFF will place 98765 before the X and the third stuff will replace X- with 98765
DECLARE @v VARCHAR(11)
SELECT @v ='-X-'
SELECT STUFF(@v, 2, 1, '98765'),
STUFF(@v, 2, 0, '98765'),
STUFF(@v, 2, 2, '98765')
The STUFF function is very handy if you need to insert dashes in a social security. You can accomplish that by using the function STUFF twice instead of using substring,left and right
DECLARE @v VARCHAR(11)
SELECT @v ='123456789'
SELECT @v,STUFF(STUFF(@v,4,0,'-'),7,0,'-')
REVERSE
REVERSE just reverses the value, for example the code below returns CBA
SELECT REVERSE('ABC')
Reverse is handy if you need to split values, take a look at this example
CREATE TABLE #TestCityStateZip (csz CHAR(49))
INSERT INTO #TestCityStateZip VALUES ('city ,st 12223')
INSERT INTO #TestCityStateZip VALUES ('New York City,NY 10028')
INSERT INTO #TestCityStateZip VALUES ('Princeton , NJ 08536')
INSERT INTO #TestCityStateZip VALUES ('Princeton,NJ 08536 ')
INSERT INTO #TestCityStateZip VALUES ('Long Island City, NY 10013')
INSERT INTO #TestCityStateZip VALUES ('Long Island City, NY 10013 ')
INSERT INTO #TestCityStateZip VALUES ('Long Island City , NY 10013')
INSERT INTO #TestCityStateZip VALUES ('Long Island City ,NY 10013 ')
SELECT LEFT(csz,CHARINDEX(',',csz)-1)AS City,
LEFT(LTRIM(SUBSTRING(csz,(CHARINDEX(',',csz)+1),4)),2) AS State,
RIGHT(RTRIM(csz),CHARINDEX(' ',REVERSE(RTRIM(csz)))-1) AS Zip
FROM #TestCityStateZip
GETUTCDATE
SELECT GETUTCDATE()
Returns the datetime value representing the current UTC time (Universal Time Coordinate or Greenwich Mean Time). The current UTC time is derived from the current local time and the time zone setting in the operating system of the computer on which SQL Server is running.
And that is all, those are the ten functions that you should be using but currently you are not using all of them. Look them up in Books On Line so that you can see some more examples
Labels:
SQL Functions,
SQL Server 2000,
SQL Server 2005,
T-SQL
Subscribe to:
Posts (Atom)