Monday, March 15, 2021
After 20+ years in IT .. I finally discovered this useful command
Very similar to my After 20+ years in IT .. I finally discovered this... post, I discovered yet another command I should have know about
Originally I was not going to write this post, but after I found out that several other people didn't know this, I figured what the heck, why not, maybe someone will think this is cool as well
Open up a command prompt or powershell command window, , navigate to a folder, type in tree... hit enter
Here is what I see
{kind=link}
I was watching a Pluralsight course and the person typed in the tree command.. and I was like whoaaaa.. How do I not know this? Perhaps maybe because I don't use the command window all that much? Anyway I thought that this was pretty cool
As you can see tree list all the directories and sub directories in a tree like structure. This is great to quickly see all the directories in one shot
The same command will work in Powershell
{kind=link}
Finally, here is an image of the command window output as well as the explorer navigation pane side by side
{kind=link}
Hopefully this will be useful to someone
Wednesday, May 06, 2020
You know about waitfor delay but did you know there is a waitfor time?
{kind=link}
I was looking at some code I wrote the other day and noticed the WAITFOR command.. This got me thinking. How many times have I used WAITFOR in code, probably as much as I have used NTILE :-)
I looked at the documentation for WAITFOR and notice there is TIME in addition to DELAY. Oh that is handy, I always rolled my own ghetto-style version by calculating how long it would be until a specific time and then I would use that in the WAITFOR DELAY command
Why would you use the WAITFOR command?
The WAITFOR command can be used to delay the execution of command for a specific duration or until a specific time occurs. From Books On Line, the description is as follows:
Blocks the execution of a batch, stored procedure, or transaction until either a specified time or time interval elapses, or a specified statement modifies or returns at least one row.
WAITFOR
{
DELAY 'time_to_pass'
| TIME 'time_to_execute'
| [ ( receive_statement ) | ( get_conversation_group_statement ) ]
[ , TIMEOUT timeout ]
}
Arguments
DELAY
Is the specified period of time that must pass, up to a maximum of 24 hours, before execution of a batch, stored procedure, or transaction proceeds.
'time_to_pass'
Is the period of time to wait. time_to_pass can be specified either in a datetime data format, or as a local variable. Dates can't be specified, so the date part of the datetime value isn't allowed. time_to_pass is formatted as hh:mm[[:ss].mss].
TIME
Is the specified time when the batch, stored procedure, or transaction runs.
'time_to_execute'
Is the time at which the WAITFOR statement finishes. time_to_execute can be specified in a datetime data format, or it can be specified as a local variable. Dates can't be specified, so the date part of the datetime value isn't allowed. time_to_execute is formatted as hh:mm[[:ss].mss] and can optionally include the date of 1900年01月01日.
WAITFOR with a receive_statement or get_conversation_group_statement is applicable only to Service Broker messages. I will not cover those in this post
I must admit that I only use these commands a couple of times a year when running something ad-hoc. In code, I will use WAITFOR DELAY when doing a back fill of data, and the table is replicated. In that case I will batch the data and after each batch is completed I will pause for a second or so. The reason I am doing this is because I don't want to increase replication latency, after all, I am a nice guy
WAITFOR TIME
Let's take a look how you would use the WAITFOR command. I will start with WAITFOR TIME
The command is very easy.. if you want the print command to run at 09:57:16, you would do the following
WAITFOR TIME '09:57:16' PRINT 'DONE 'The seconds are optional, if you want it to run at 9 hours and 57 minutes, you can do the following
WAITFOR TIME '09:57' PRINT 'DONE '
One thing to know is that you can't grab the output from a time data type and use that in your WAITFOR TIME command. The following will blow up
SELECT CONVERT(time, getdate()) --'09:57:16.9600000' WAITFOR TIME '09:57:16.9600000'
Msg 148, Level 15 , State 1, Line 32
Incorrect time syntax in time string '09:57:16.9600000' used with WAITFOR.
What you need to do is strip everything after the dot.
We need the command to be the following
WAITFOR TIME '09:57:16'
There are two ways to accomplish this... first way is by using PARSENAME, I blogged about that function several times, the first time here: Ten SQL Server Functions That You Hardly Use But Should
All you have to tell SQL Server which part you want, if you use PARSENAME,1 you will get everything after the dot, if you use PARSENAME,2 you will get everything before the dot.
1 2
SELECT PARSENAME('09:57:16.9600000',2), PARSENAME('09:57:16.9600000',1)
This returns the following
09:57:16 9600000
The easiest way would have been to just use time(0) instead
1 2SELECT CONVERT(time, getdate()) ,--'09:57:16.9600000' CONVERT(time(0), getdate()) --'09:57:16
Below is a complete example that will wait for 10 seconds to run the PRINT statement on line 12 if you run the whole code block in 1 shot.
Also notice that I use a variable with the WAITFOR TIME command on line 9. The caveat with that is that the variable can't be a time datatype. This is why I use a varchar datatype and store the value of the time data type in it. The reason I use the time datatype in my procs is so that I don't have to do a lot of validations when someone is calling the proc. If they pass in a string that can't be converted.. the proc won't even run... it will fail right at the proc call itself
1 2 3 4 5 6 7 8 9 10 11 12
DECLARE @DelayTime time(0)= GETDATE() PRINT @DelayTime SELECT @DelayTime =DATEADD(second,10,@DelayTime) PRINT @DelayTime DECLARE @d varchar(100) = @DelayTime -- you have to use varchar in command WAITFOR TIME @d -- Run your command here PRINT 'DONE ' + CONVERT(varchar(100),CONVERT(time(0), getdate()))
What is printed is the following
10:49:48
10:49:58
DONE 10:49:58
Now when would you really use WAITFOR TIME? You can accomplish the same with a scheduled job, the only time I use WAITFOR TIME is if I want a quick count of want to run something at a specific time but I know I won't be at my desk and I can't create a job without a ticket
But you also have to be aware that if your connection gets lost to the SQL Server instance, your command won't execute
WAITFOR DELAY
The WAITFOR DELAY command is similar to the WAITFOR TIME command, instead of waiting for a time, the command pauses for a specific period
Like I said before, I use WAITFOR DELAY as well as a batch size in my back fill procs. Both can be passed in, if you do a load during a weekday, your delay would be longer than on a weekend.
Sometimes I need to see how many rows are getting inserted every minute.. or something similar
I will then combine WAITFOR DELAY and the batch terminator with a count number to execute the batch of statements more than once
Here is such an example, it will run the INSERT statement 20 times, it will pause 1 minute between each execution
1 2 3 4
INSERT #temp(SomeCol, SomeTimeStamp) SELECT COUNT(*), GETDATE() FROM sometable WAITFOR DELAY '00:01:00' GO 20
That's all for this post.
Do you use the WAITFOR command, if so, what do you use it for?
Monday, December 30, 2019
Top 10 posts from the last decade
As we finish the tumultuous 2010s and are ready for the roaring 2020s, I decided to take a quick look at the ten most viewed posts from the past decade. Two of these posts were made posted before 2010
Without any fanfare, here is the list
10. Some cool SQL Server announcements SQL Graph, Adaptive Query Plan, CTP1 of SQL vNext, SQL Injection detection
This is my recap of the chalkboard session with the SQL Server team at the SQL Server PASS summit in Seattle.
A very old post showing you how to convert from milliseconds to "hh:mm:ss" format
08. Can adding an index make a non SARGable query SARGable?
A post showing you how adding an index can make a query use that index even though the index column doesn't match the query
07. A little less hate for: String or binary data would be truncated in table
Can you believe they actually managed to accomplish this during the past decade :-)
06. Some numbers that you will know by heart if you have been working with SQL Server for a while
After working with SQL Server for a while, you should know most of these
05. Use T-SQL to create caveman graphs
One of the shortest post on this site, show you how you can make visually appealing output with a pipe symbol
04. Ten SQL Server Functions That You Hardly Use But Should
03. Your lack of constraints is disturbing
A post showing the type of constraints available in SQL Server with examples
02. Five Ways To Return Values From Stored Procedures
A very old post that shows you five ways to return values from a stored proc
01. After 20+ years in IT .. I finally discovered this...
What can I say, read it and let me know if you knew this one....
Tuesday, June 11, 2019
Can adding an index make a non SARGable query SARGable?
This question came up the other day from a co-worker, he said he couldn't change a query but was there a way of making the same query produce a better plan by doing something else perhaps (magic?)
He said his query had a WHERE clause that looked like the following
WHERE RIGHT(SomeColumn,3) = '333'
I then asked if he could change the table, his answer was that he couldn't mess around with the current columns but he could add a column
Ok, that got me thinking about a solution, let's see what I came up with
First create the following table
USE tempdb GO CREATE TABLE StagingData (SomeColumn varchar(255) NOT NULL ) ALTER TABLE dbo.StagingData ADD CONSTRAINT PK_StagingData PRIMARY KEY CLUSTERED ( SomeColumn ) ON [PRIMARY] GOWe will create some fake data by appending a dot and a number between 100 and 999 to a GUID
Let's insert one row so that you can see what the data will look like
DECLARE @guid uniqueidentifier SELECT @guid = 'DEADBEEF-DEAD-BEEF-DEAD-BEEF00000075' INSERT StagingData SELECT CONVERT(varchar(200),@guid) + '.100' SELECT * FROM StagingDataOutput
SomeColumn
--------------------------------
DEADBEEF-DEAD-BEEF-DEAD-BEEF00000075.100
Time to insert 999,999 rows
Here is what the code looks like
INSERT StagingData SELECT top 999999 CONVERT(varchar(200),NEWID()) + '.' + CONVERT(VARCHAR(10),s2.number) FROM master..SPT_VALUES s1 CROSS JOIN master..SPT_VALUES s2 WHERE s1.type = 'P' AND s2.type = 'P' and s1.number between 100 and 999 and s2.number between 100 and 999
With that completed we should now have one million rows
If we run our query to look for rows where the last 3 characters are 333 we can see that we get a scan
SET STATISTICS IO ON GO SELECT SomeColumn FROM StagingData WHERE RIGHT(SomeColumn,3) = '333' SET STATISTICS IO OFF GO
(900 rows affected)
Table 'StagingData'. Scan count 1, logical reads 5404, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We get 900 rows back and 5404 reads
Here is what the execution plan looks like
{kind=link}
If we always query for the last 3 characters, what we can do is add a computed column to the table that just contains the last 3 characters and then add a nonclustered index to that column
That code looks like this
ALTER TABLE StagingData ADD RightChar as RIGHT(SomeColumn,3) GO CREATE INDEX ix_RightChar on StagingData(RightChar) GO
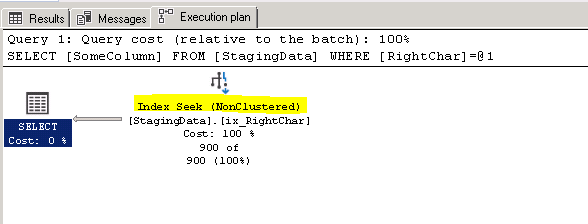
Now let's check what we get when we use this new column
SET STATISTICS IO ON GO SELECT SomeColumn FROM StagingData WHERE RightChar = '333' SET STATISTICS IO OFF GO
(900 rows affected)
Table 'StagingData'. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The reads went from 5404 to 10, that is a massive improvement, here is what the execution plan looks like
{kind=link}
However there is a small problem.....
We said we would not modify the query...
What happens if we execute the same query from before? Can the SQL Server optimizer recognize that our new column and index is pretty much the same as the WHERE clause?
SET STATISTICS IO ON GO SELECT SomeColumn FROM StagingData WHERE RIGHT(SomeColumn,3) = '333' SET STATISTICS IO OFF GO
(900 rows affected)Table 'StagingData'. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Damn right, the optimizer can, , there it is, it uses the new index and column although we specify the original column..... (must be all that AI built in... (just kidding))If you look at the execution plan, you can see it is indeed a seek
{kind=link}
So there you have it.. sometimes, you can't change the query, you can't mess around with existing column but you can add a column to the table, in this case a technique like the following can be beneficial
PS
Betteridge's law of headlines is an adage that states: "Any headline that ends in a question mark can be answered by the word no." It is named after Ian Betteridge, a British technology journalist who wrote about it in 2009
In this case as you can plainly see...this is not true :-) The answer to "Can adding an index make a non SARGable query SARGable?" is clearly yes
Wednesday, April 24, 2019
How to count NULLS without using IS NULL in a WHERE clause
This came up the other day, someone wanted to know the percentage of NULL values in a column
Then I said "I bet you I can run that query without using a NULL in the WHERE clause, as a matter of fact, I can run that query without a WHERE clause at all!!"
The person then wanted to know more, so you know what that means.. it becomes a blog post :-)
BTW, the PostgreSQL version of this blog post can be found here: A quick and easy way to count the percentage of nulls without a where clause in PostgreSQL
To get started, first create this table and verify you have 9 rows
CREATE TABLE foo(bar int) INSERT foo values(1),(null),(2),(3),(4), (null),(5),(6),(7) SELECT * FROM foo
Here is what the output should be
bar
1
NULL
2
3
4
NULL
5
6
7
To get the NULL values and NON NULL values, you can do something like this
SELECT COUNT(*) as CountAll FROM foo WHERE bar IS NOT NULL SELECT COUNT(*) as CountAll FROM foo WHERE bar IS NULL
However, there is another way
Did you know that COUNT behaves differently if you use a column name compared to when you use *
Take a look
SELECT COUNT(*) as CountAll, COUNT(bar) as CountColumn FROM foo
If you ran that query, the result is the following
CountAll CountColumn
----------- -----------
9 7
Warning: Null value is eliminated by an aggregate or other SET operation.
And did you notice the warning? That came from the count against the column
Let's see what Books On Line has to say
COUNT(*) returns the number of items in a group. This includes NULL values and duplicates.
COUNT(ALL expression) evaluates expression for each row in a group, and returns the number of nonnull values.
COUNT(DISTINCT expression) evaluates expression for each row in a group, and returns the number of unique, nonnull values.
This is indeed documented behavior
So now, lets change our query to return the percentage of non null values in the column
SELECT COUNT(*) as CountAll, COUNT(bar) as CountColumn, (COUNT(bar)*1.0/COUNT(*))*100 as PercentageOfNonNullValues FROM foo
Here is the output
CountAll CountColumn percentageOfNonNullValues
----------- ----------- ---------------------------------------
9 7 77.777777777700
I just want to point out one thing, the reason I have this * 1.0 in the query
(COUNT(bar)*1.0/COUNT(*))*100
I am doing * 1.0 here because count returns an integer, so you will end up with integer math and the PercentageOfNonNullValues would be 0 instead of 77.7777...
That's it for this short post.. hopefully you knew this, if not, then you know it now :-)
Thursday, February 14, 2019
Finding rows where the column starts or ends with a 'bad' character
Aha... I have plenty of war stories with Excel so I said, it's probably some non printable character that is in the column.. either a tab (char(9)) or a non breaking space (char(160))..especially if the value was copied from the internet
He said isnumeric was returning 0 for rows that looked valid, I then told him to run this query on those rows
SELECT ASCII(LEFT(SomeColumn,1)), ASCII(RIGHT(SomeColumn,1)),* FROM StagingData s
That would give them the ascii numerical value. For example a tab is 9, linefeed = 10....
Here is a chart for the characters between 0 and 32
| Binary | Oct | Dec | Hex | Abbreviation | [b] | [c] | [d] | Name (1967) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1963 | 1965 | 1967 | ||||||||
| 000 0000 | 000 | 0 | 00 | NULL | NUL | ␀ | ^@ | 0円 | Null | |
| 000 0001 | 001 | 1 | 01 | SOM | SOH | ␁ | ^A | Start of Heading | ||
| 000 0010 | 002 | 2 | 02 | EOA | STX | ␂ | ^B | Start of Text | ||
| 000 0011 | 003 | 3 | 03 | EOM | ETX | ␃ | ^C | End of Text | ||
| 000 0100 | 004 | 4 | 04 | EOT | ␄ | ^D | End of Transmission | |||
| 000 0101 | 005 | 5 | 05 | WRU | ENQ | ␅ | ^E | Enquiry | ||
| 000 0110 | 006 | 6 | 06 | RU | ACK | ␆ | ^F | Acknowledgement | ||
| 000 0111 | 007 | 7 | 07 | BELL | BEL | ␇ | ^G | \a | Bell | |
| 000 1000 | 010 | 8 | 08 | FE0 | BS | ␈ | ^H | \b | Backspace [e] [f] | |
| 000 1001 | 011 | 9 | 09 | HT/SK | HT | ␉ | ^I | \t | Horizontal Tab [g] | |
| 000 1010 | 012 | 10 | 0A | LF | ␊ | ^J | \n | Line Feed | ||
| 000 1011 | 013 | 11 | 0B | VTAB | VT | ␋ | ^K | \v | Vertical Tab | |
| 000 1100 | 014 | 12 | 0C | FF | ␌ | ^L | \f | Form Feed | ||
| 000 1101 | 015 | 13 | 0D | CR | ␍ | ^M | \r | Carriage Return [h] | ||
| 000 1110 | 016 | 14 | 0E | SO | ␎ | ^N | Shift Out | |||
| 000 1111 | 017 | 15 | 0F | SI | ␏ | ^O | Shift In | |||
| 001 0000 | 020 | 16 | 10 | DC0 | DLE | ␐ | ^P | Data Link Escape | ||
| 001 0001 | 021 | 17 | 11 | DC1 | ␑ | ^Q | Device Control 1 (often XON) | |||
| 001 0010 | 022 | 18 | 12 | DC2 | ␒ | ^R | Device Control 2 | |||
| 001 0011 | 023 | 19 | 13 | DC3 | ␓ | ^S | Device Control 3 (often XOFF) | |||
| 001 0100 | 024 | 20 | 14 | DC4 | ␔ | ^T | Device Control 4 | |||
| 001 0101 | 025 | 21 | 15 | ERR | NAK | ␕ | ^U | Negative Acknowledgement | ||
| 001 0110 | 026 | 22 | 16 | SYNC | SYN | ␖ | ^V | Synchronous Idle | ||
| 001 0111 | 027 | 23 | 17 | LEM | ETB | ␗ | ^W | End of Transmission Block | ||
| 001 1000 | 030 | 24 | 18 | S0 | CAN | ␘ | ^X | Cancel | ||
| 001 1001 | 031 | 25 | 19 | S1 | EM | ␙ | ^Y | End of Medium | ||
| 001 1010 | 032 | 26 | 1A | S2 | SS | SUB | ␚ | ^Z | Substitute | |
| 001 1011 | 033 | 27 | 1B | S3 | ESC | ␛ | ^[ | \e [i] | Escape [j] | |
| 001 1100 | 034 | 28 | 1C | S4 | FS | ␜ | ^\ | File Separator | ||
| 001 1101 | 035 | 29 | 1D | S5 | GS | ␝ | ^] | Group Separator | ||
| 001 1110 | 036 | 30 | 1E | S6 | RS | ␞ | ^^[k] | Record Separator | ||
| 001 1111 | 037 | 31 | 1F | S7 | US | ␟ | ^_ | Unit Separator | ||
Source: https://en.wikipedia.org/wiki/ASCII
He then ran the following to grab all the rows that ended or started with tabs
SELECT * FROM StagingData s WHERE LEFT(SomeColumn,1) = char(9) OR RIGHT(SomeColumn,1) = char(9)
So let's take another look at this to see how we can make this a little better
Let's create a table that will hold these bad characters that we don't want, in my case ACII values 1 untill 32
Here is what we will do to create and populate the table
CREATE TABLE BadCharacters( BadChar char(1) NOT NULL, ASCIINumber int NOT NULL, CONSTRAINT pk_BadCharacters PRIMARY KEY CLUSTERED( BadChar ) ) GO INSERT BadCharacters SELECT char(number),number FROM master..SPT_VALUES WHERE type = 'P' AND number BETWEEN 1 AND 32 OR number = 160A quick look at the data looks like this
SELECT * FROM BadCharacters
{kind=link}
Now let's create our staging table and insert some data so that we can do some tests
CREATE TABLE StagingData (SomeColumn varchar(255) ) INSERT StagingData SELECT CONVERT(VARCHAR(10),s1.number) + '.' + CONVERT(VARCHAR(10),s2.number) FROM master..SPT_VALUES s1 CROSS JOIN master..SPT_VALUES s2 WHERE s1.type = 'P' AND s2.type = 'P'
That inserted 4194304 rows on my machine
Time to insert some of that bad data
Here is what some of the data inserted will look like
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
And this is the query to generated and insert those bad rows, on my machine it generated 1089 such rows
;WITH cte as(SELECT CONVERT(VARCHAR(10),number) as num FROM master..SPT_VALUES WHERE type = 'P' AND number BETWEEN 1 AND 1000) --INSERT StagingData SELECT b.BadChar + c1.num + '.' + c2.num + b2.BadChar FROM cte c1 CROSS JOIN cte c2 JOIN BadCharacters b on c1.num = b.ASCIINumber JOIN BadCharacters b2 on c2.num = b2.ASCIINumberThe query create a value by using a bad value, a number a dot a number and a bad value, you can see those values above
Now it's time to find these bad rows, but before we do that, let's add an index
CREATE INDEX ix_StagingData on StagingData(SomeColumn)
OK, we are ready...
Of course I here you saying, why don't we just do this
SELECT * FROM StagingData WHERE TRY_CONVERT(numeric(20,10),SomeColumn) IS NULL
Before we start, let's set statistics io on so that we can look at some performance
SET STATISTICS IO ON GO
Here are the queries to find the bad characters at the start
SELECT * FROM StagingData s JOIN BadCharacters b on b.BadChar = LEFT(s.SomeColumn,1) SELECT * FROM StagingData s JOIN BadCharacters b on s.SomeColumn like b.BadChar +'%'
Here is what the reads look like
(1089 row(s) affected)
Table 'BadCharacters'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'StagingData'. Scan count 9, logical reads 10851, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1089 row(s) affected)
Table 'BadCharacters'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'StagingData'. Scan count 33, logical reads 135, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
As you can see from the stats, the top query is non-SARGable and generates a lot more reads, the bottom query can use the index. Always make sure to write your queries in a way so that SQL Server can you an index
What about the last character, how can we find those
SELECT * FROM StagingData s JOIN BadCharacters b on b.BadChar = RIGHT(s.SomeColumn,1) SELECT * FROM StagingData s JOIN BadCharacters b on s.SomeColumn like +'%' + b.BadChar
Here are the stats again
(1089 row(s) affected)
Table 'BadCharacters'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'StagingData'. Scan count 9, logical reads 10851, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1089 row(s) affected)
Table 'BadCharacters'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'StagingData'. Scan count 33, logical reads 445863, physical reads 0, read-ahead reads 13, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
So both of these queries suck the life out of your SQL Server instance, so what can be done?
One thing we can do is add a computed column to the table that will hold just the last character of the column, then we can index the computed column
Here are the commands to do that
ALTER TABLE StagingData ADD RightChar as RIGHT(SomeColumn,1) GO CREATE INDEX ix_RightChar on StagingData(RightChar) GO
And now we can just run the same queries again
SELECT * FROM StagingData s JOIN BadCharacters b on b.BadChar = RIGHT(s.SomeColumn,1) SELECT * FROM StagingData s JOIN BadCharacters b on s.SomeColumn like +'%' + b.BadChar
Here are the stats
(1089 row(s) affected)
Table 'StagingData'. Scan count 33, logical reads 1223, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'BadCharacters'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1089 row(s) affected)
Table 'StagingData'. Scan count 33, logical reads 1223, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'BadCharacters'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Did you expect to get the same exact reads for both queries?
So what is going on? Well lets take a look
{kind=link}
In both cases, the optimizer was smart enough to use the index on the computed column
Hopefully this will make someone's life easier and you can expand the table to add other character you consider bad. You can also add constraint to reject values or you can add triggers and then move those bad rows to a bad rows table
Finally if you need to worry about unicode you might want to change the table to be nvarchar
Enjoy.. importing that data..... we all know..it's only getting bigger and bigger