Showing posts with label Indexing. Show all posts
Showing posts with label Indexing. Show all posts
Wednesday, October 30, 2019
SQLSTATE 4200 Error 666 and what to do.
{kind=link}
This morning I was greeted by the following message from a job email
The maximum system-generated unique value for a duplicate group was exceeded for index with partition ID 72059165481762816. Dropping and re-creating the index may resolve this; otherwise, use another clustering key. [SQLSTATE 42000] (Error 666)
Almost Halloween? check!
Error 666? check!
Ever seen this error before? no!
The job has a step that inserts into a bunch of tables...
The table in question had a clustered index that was created without the UNIQUE property. When you create such an index, SQL Server will create a uniqueifier internally
This part is from the CSS SQL Server Engineers blog post
A uniqueifier (or uniquifier as reported by SQL Server internal tools) has been used in the engine for a long time (since SQL Server 7.0), and even being known to many, referenced in books and blogs, The SQL Server documentation clearly states that you will not see it exposed externally in the engine (https://docs.microsoft.com/en-us/sql/relational-databases/sql-server-index-design-guide).
"If the clustered index is not created with the UNIQUE property, the Database Engine automatically adds a 4-byte uniqueifier column to the table. When it is required, the Database Engine automatically adds a uniqueifier value to a row to make each key unique. This column and its values are used internally and cannot be seen or accessed by users."
While it´s unlikely that you will face an issue related with uniqueifiers, the SQL Server team has seen rare cases where customer reaches the uniqueifier limit of 2,147,483,648, generating error 666.
Msg 666, Level 16, State 2, Line 1
The maximum system-generated unique value for a duplicate group was exceeded for index with partition ID <PARTITIONID>. Dropping and re-creating the index may resolve this; otherwise, use another clustering key.
So I ran into this rare case :-(
How can you quickly find out what table and index name the error is complaining about?
You can use the following query, just change the partitionid to match the one from your error message
SELECT SCHEMA_NAME(o.schema_id) as SchemaName, o.name as ObjectName, i.name as IndexName, p.partition_id as PartitionID FROM sys.partitions p JOIN sys.objects o on p.object_id = o.object_id JOIN sys.indexes i on p.object_id = i.object_id WHERE p.partition_id = 72059165481762816
After running the query, you will now have the schema name, the table name and the index name. That is all you need to find the index, you can now drop and recreate it
In my case this table was not big at all... 5 million rows or so, but we do delete and insert a lot of data into this table many times a day.
Also we have rebuild jobs running, rebuild jobs do not reset the uniqifier (see also below about a change from the CSS SQL Server Engineers)
To fix this, all I had to do was drop the index and recreate the index (after filling out tickets and testing it on a lower environment first).
DROP INDEX [IX_IndexName] ON [SchemaName].TableName] GO CREATE CLUSTERED INDEX [IX_IndexName] ON [SchemaName].[TableName] ( Col1 ASC, Col2 ASC, Col3 ASC ) ON [PRIMARY] GO
After dropping and recreating the index.. the code that threw an error earlier did not throw an error anymore
Since my table only had 5 million rows or so.. this was not a big deal and completed in seconds. If you have a large table you might have to wait or think of a different approach
If you want to know more, check out this post by the CSS SQL Server Engineers Uniqueifier considerations and error 666
The interesting part is
As of February 2018, the design goal for the storage engine is to not reset uniqueifiers during REBUILDs. As such, rebuild of the index ideally would not reset uniquifiers and issue would continue to occur, while inserting new data with a key value for which the uniquifiers were exhausted. But current engine behavior is different for one specific case, if you use the statement ALTER INDEX ALL ON <TABLE> REBUILD WITH (ONLINE = ON), it will reset the uniqueifiers (across all version starting SQL Server 2005 to SQL Server 2017).
Important: This is something that is not documented and can change in future versions, so our recommendation is that you should review table design to avoid relying on it.
Edit.. it turns out I have seen this before and have even blogged about it http://sqlservercode.blogspot.com/2017/06/having-fun-with-maxed-out-uniqifiers-on.html
Tuesday, June 11, 2019
Can adding an index make a non SARGable query SARGable?
This question came up the other day from a co-worker, he said he couldn't change a query but was there a way of making the same query produce a better plan by doing something else perhaps (magic?)
He said his query had a WHERE clause that looked like the following
WHERE RIGHT(SomeColumn,3) = '333'
I then asked if he could change the table, his answer was that he couldn't mess around with the current columns but he could add a column
Ok, that got me thinking about a solution, let's see what I came up with
First create the following table
USE tempdb GO CREATE TABLE StagingData (SomeColumn varchar(255) NOT NULL ) ALTER TABLE dbo.StagingData ADD CONSTRAINT PK_StagingData PRIMARY KEY CLUSTERED ( SomeColumn ) ON [PRIMARY] GOWe will create some fake data by appending a dot and a number between 100 and 999 to a GUID
Let's insert one row so that you can see what the data will look like
DECLARE @guid uniqueidentifier SELECT @guid = 'DEADBEEF-DEAD-BEEF-DEAD-BEEF00000075' INSERT StagingData SELECT CONVERT(varchar(200),@guid) + '.100' SELECT * FROM StagingDataOutput
SomeColumn
--------------------------------
DEADBEEF-DEAD-BEEF-DEAD-BEEF00000075.100
Time to insert 999,999 rows
Here is what the code looks like
INSERT StagingData SELECT top 999999 CONVERT(varchar(200),NEWID()) + '.' + CONVERT(VARCHAR(10),s2.number) FROM master..SPT_VALUES s1 CROSS JOIN master..SPT_VALUES s2 WHERE s1.type = 'P' AND s2.type = 'P' and s1.number between 100 and 999 and s2.number between 100 and 999
With that completed we should now have one million rows
If we run our query to look for rows where the last 3 characters are 333 we can see that we get a scan
SET STATISTICS IO ON GO SELECT SomeColumn FROM StagingData WHERE RIGHT(SomeColumn,3) = '333' SET STATISTICS IO OFF GO
(900 rows affected)
Table 'StagingData'. Scan count 1, logical reads 5404, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We get 900 rows back and 5404 reads
Here is what the execution plan looks like
{kind=link}
If we always query for the last 3 characters, what we can do is add a computed column to the table that just contains the last 3 characters and then add a nonclustered index to that column
That code looks like this
ALTER TABLE StagingData ADD RightChar as RIGHT(SomeColumn,3) GO CREATE INDEX ix_RightChar on StagingData(RightChar) GO
Now let's check what we get when we use this new column
SET STATISTICS IO ON GO SELECT SomeColumn FROM StagingData WHERE RightChar = '333' SET STATISTICS IO OFF GO
(900 rows affected)
Table 'StagingData'. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The reads went from 5404 to 10, that is a massive improvement, here is what the execution plan looks like
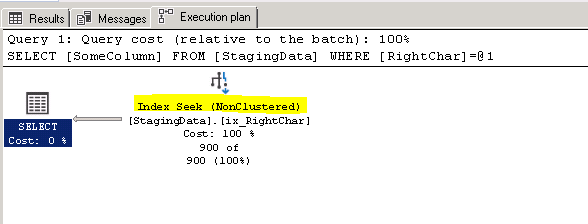{kind=link}
However there is a small problem.....
We said we would not modify the query...
What happens if we execute the same query from before? Can the SQL Server optimizer recognize that our new column and index is pretty much the same as the WHERE clause?
SET STATISTICS IO ON GO SELECT SomeColumn FROM StagingData WHERE RIGHT(SomeColumn,3) = '333' SET STATISTICS IO OFF GO
(900 rows affected)Table 'StagingData'. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Damn right, the optimizer can, , there it is, it uses the new index and column although we specify the original column..... (must be all that AI built in... (just kidding))If you look at the execution plan, you can see it is indeed a seek
{kind=link}
So there you have it.. sometimes, you can't change the query, you can't mess around with existing column but you can add a column to the table, in this case a technique like the following can be beneficial
PS
Betteridge's law of headlines is an adage that states: "Any headline that ends in a question mark can be answered by the word no." It is named after Ian Betteridge, a British technology journalist who wrote about it in 2009
In this case as you can plainly see...this is not true :-) The answer to "Can adding an index make a non SARGable query SARGable?" is clearly yes
Friday, November 04, 2016
Are your foreign keys indexed? If not, you might have problems
When you add a primary key constraint to a table in SQL Server, an index will be created automatically. When you add a foreign key constraint no index will be created. This might cause issues if you don't know that this is the behavior in SQL Server. Maybe there should be an option to automatically index the foreign keys in SQL Server, what do you think?
The other day some deletes on a newer table in the test environment became really slow. We had a primary table with a couple of hundred rows, we loaded up between 200 and 300 million rows into the child table. Then we deleted the child rows, this was fast. After this, we deleted one row from the primary table and this took several seconds.
When I looked at this I noticed something interesting, the most time during the delete was spent doing a lookup at the child table. Then I noticed that the foreign key was not indexed. After we added the index the delete became thousands of times faster
Let's try to replicate that behavior here
First create these primary table, we will add 2048 rows to this table
--Table that will have 2048 rows CREATE TABLE Store(StoreID int not null, DateCreated datetime not null, StoreName varchar(500), constraint pk_store primary key (StoreID)) GO --insert 2048 rows INSERT Store SELECT ROW_NUMBER() OVER(ORDER BY t1.number) AS StoreID,DATEADD(dd,t1.number,'20161101')
AS datecreated, NEWID() FROM master..spt_values t1 WHERE t1.type = 'p'
Now create the child table and add 500K rows, this might take up to 1 minute to run since the rows are pretty wide.
-- table that will also have 500000 rows, fk will be indexed CREATE TABLE GoodsSold (TransactionID int not null, StoreID int not null, DateCreated datetime not null, SomeValue char(5000), constraint pk_transaction primary key (TransactionID)) INSERT GoodsSold SELECT top 500000 ROW_NUMBER() OVER(ORDER BY t1.number) AS TransactionID, t2.StoreID,
DATEADD(dd,t1.number,'20161101') AS datecreated, REPLICATE('A',5000) FROM master..spt_values t1 CROSS JOIN Store t2 WHERE t1.type = 'p'
Now it is time to add the foreign key constraint and index this foreign key constraint
-- adding the foreign key ALTER TABLE GoodsSold WITH CHECK ADD CONSTRAINT FK_StoreID FOREIGN KEY(StoreID) REFERENCES Store(StoreID) GO ALTER TABLE GoodsSold CHECK CONSTRAINT FK_StoreID GO -- index the foreign key CREATE index ix_StoreID on GoodsSold(StoreID) GO
We will create another set of tables, let's start with the primary table, we will just insert into this table all the rows from the primary table we created earlier
-- create another primary table CREATE TABLE StoreFK(StoreID int not null, DateCreated datetime not null, StoreName varchar(500), constraint pk_storefk primary key (StoreID)) GO -- add the same 2048 rows from the primary table with indexed FK INSERT StoreFK SELECT * FROM Store GO
For the child table, it is the same deal, we will add all the rows from the child table we created earlier into this table
-- Add another FK table CREATE TABLE GoodsSoldFKNoIndex (TransactionID int not null, StoreID int not null, DateCreated datetime not null, SomeValue char(5000), constraint pk_transactionfk primary key (TransactionID)) -- add same 500K rows from table with FK index INSERT GoodsSoldFKNoIndex SELECT * FROM GoodsSold
Let's add the foreign key constraint, but this time we are not indexing the foreign key constraint
-- add the FK but do not index this ALTER TABLE GoodsSoldFKNoIndex WITH CHECK ADD CONSTRAINT FK_StoreID_FK
FOREIGN KEY(StoreID) REFERENCES StoreFK(StoreID) GO ALTER TABLE GoodsSoldFKNoIndex CHECK CONSTRAINT FK_StoreID_FK GO
Let make sure that the tables have the same number of rows
-- check that the tables have the same rows exec sp_spaceused 'GoodsSold' exec sp_spaceused 'GoodsSoldFKNoIndex'
| name | rows | reserved | data | index_size | unused |
|---|---|---|---|---|---|
| GoodsSold | 500000 | 4024976 KB | 4000000 KB | 22520 KB | 2456 KB |
| GoodsSoldFKNoIndex | 500000 | 4015440 KB | 4000000 KB | 14936 KB | 504 KB |
Now that we are setup, let's wipe out all the rows from the child table for a specific StoreID, the SELECT statements should return 0 rows
DELETE GoodsSoldFKNoIndex WHERE StoreID = 507 DELETE GoodsSold WHERE StoreID = 507 SELECT * FROM GoodsSoldFKNoIndex WHERE StoreID = 507 SELECT * FROM GoodsSold WHERE StoreID = 507
Now we are getting to the interesting part, turn on Include Actual Execution Plan, run statistics IO or run this in Plan Explorer
DELETE Store WHERE StoreID = 507 DELETE StoreFK WHERE StoreID = 507
You will see something like this
So 75% compared to 25%, not good but doesn't look catastrophic, if you have statistics time on, you will see the following
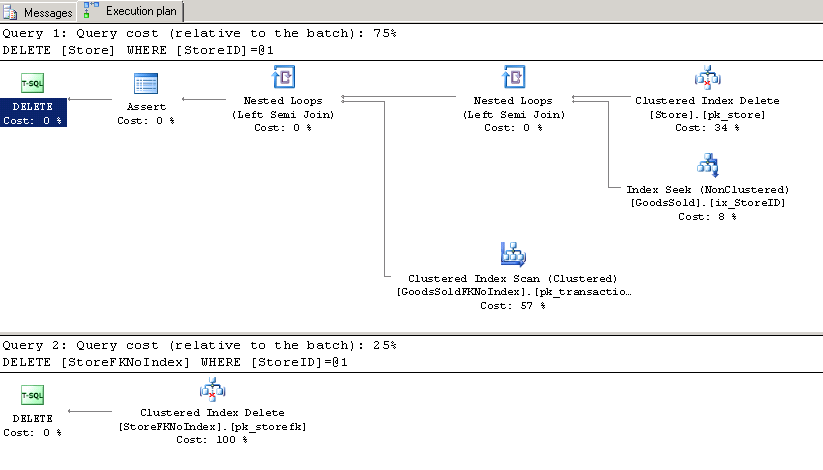{kind=link}
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 16 ms.
SQL Server Execution Times:
CPU time = 561 ms, elapsed time = 575 ms.
Now it looks much worse
What about statistics io?
Table 'GoodsSold'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Store'. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'GoodsSoldFKNoIndex'. Scan count 1, logical reads 501373, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'StoreFK'. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
That is terrible....
Here is also the view from Plan Explorer, look at Est. CPU Cost and Reads
{kind=link}
There you have it, not indexing foreign keys can have a big impact even though the child table might not have any data at all
See also When did SQL Server stop putting indexes on Foreign Key columns? by Kimberly Tripp
Labels:
foreign keys,
Indexing,
Performance,
Performance Tuning
Sunday, August 17, 2008
Only In A Database Can You Get 1000% + Improvement By Changing A Few Lines Of Code
Take a look at this query.
SELECT * FROM
(
SELECT customer_id, ‘MTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table
WHERE YEAR(payment_dt) = YEAR(GETDATE())
and MONTH(payment_dt) = MONTH(GETDATE())
GROUP BY customer_id) MTD_payments
UNION ALL
(
SELECT customer_id, ‘YTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table
WHERE
WHERE YEAR(payment_dt) = YEAR(GETDATE())
GROUP BY customer_id) YTD_payments
UNION ALL
(
SELECT customer_id, ‘LTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table) LTD_payments
) payments_report
ORDER BY customer_id, record_type
Can you see the problem?
A person had this query, it would run for over 24 hours. Wow, that is pretty bad, I don't think I had ever written something that ran over an hour, and the ones I did were mostly defragmentation and update statistics jobs.
The problem is that the following piece of code
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
is not sargable. First what does it mean to be sargable? A query is said to be sargable if the DBMS engine can take advantage of an index to speed up the execution of the query (using index seeks, not covering indexes). The term is derived from a contraction of Search ARGument Able.
This query is not sargable because there is a function on the column, whenever you use a function on the column you will not get an index seek but an index scan. The difference between an index seek and an index scan can be explained like this: when searching for something in a book, you go to the index in the back find the page number and go to the page, that is an index seek. When looking for something in a book you go from page one until the last page, read all the words on all the ages and get what you need, that was an index scan. Do you see how much more expensive in terms of performance that was?
Let's get back to the query, what can we do to make this piece of code use an index seek?
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
You would change it to this:
where payment_dt>= dateadd(mm, datediff(mm, 0, getdate())+0, 0)
and payment_dt < dateadd(mm, datediff(mm, 0, getdate())+1, 0)
You can see the complete question on the MSDN forum site here:
http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3746751&SiteID=1
The Person said that his query went from over 24 hours to 36 seconds. Wow!! That is very significant. hardware cannot help you out if you have bad queries like that.
The same exact day I answered a very similar question, take a look here: http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3752248&SiteID=1
The person had this
If you are interested in some blogposts about dates, take a look at these two which I wrote earlier
How Are Dates Stored In SQL Server?
Do You Know How Between Works With Dates?
SELECT * FROM
Can you see the problem?
A person had this query, it would run for over 24 hours. Wow, that is pretty bad, I don't think I had ever written something that ran over an hour, and the ones I did were mostly defragmentation and update statistics jobs.
The problem is that the following piece of code
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
is not sargable. First what does it mean to be sargable? A query is said to be sargable if the DBMS engine can take advantage of an index to speed up the execution of the query (using index seeks, not covering indexes). The term is derived from a contraction of Search ARGument Able.
This query is not sargable because there is a function on the column, whenever you use a function on the column you will not get an index seek but an index scan. The difference between an index seek and an index scan can be explained like this: when searching for something in a book, you go to the index in the back find the page number and go to the page, that is an index seek. When looking for something in a book you go from page one until the last page, read all the words on all the ages and get what you need, that was an index scan. Do you see how much more expensive in terms of performance that was?
Let's get back to the query, what can we do to make this piece of code use an index seek?
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
You would change it to this:
where payment_dt>= dateadd(mm, datediff(mm, 0, getdate())+0, 0)
and payment_dt < dateadd(mm, datediff(mm, 0, getdate())+1, 0)
You can see the complete question on the MSDN forum site here:
http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3746751&SiteID=1
The Person said that his query went from over 24 hours to 36 seconds. Wow!! That is very significant. hardware cannot help you out if you have bad queries like that.
The same exact day I answered a very similar question, take a look here: http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3752248&SiteID=1
The person had this
ANDDATEDIFF(d,'08/10/2008', DateCreated)>= 0
ANDDATEDIFF(d, DateCreated,'08/15/2008')>= 0
I told him to change it to this
AND DateCreated>= '08/10/2008'
and DateCreated <= '08/15/2008'
And that solved that query. If you are interested in some more performance, I have written some Query Optimization items on the LessThanDot Wiki. Below are some direct links
Case Sensitive Search
No Functions on Left Side of Operator
Query Optimizations With Dates
Optimization: Set Nocount On
No Math In Where Clause
Don't Use (select *), but List Columns
If you are interested in some blogposts about dates, take a look at these two which I wrote earlier
How Are Dates Stored In SQL Server?
Do You Know How Between Works With Dates?
Labels:
database,
Dates,
Indexing,
Performance Tuning,
rdbms,
SQL,
T-SQL,
temporal data
Friday, May 23, 2008
Interview With Craig Freedman About Indexing, Query Plans And Performance
I interviewed Craig Freedman about Indexing, Query Plans And Performance and more. You can find that interview here: Interview With Craig Freedman About Indexing, Query Plans And Performance
Enjoy
Enjoy
Subscribe to:
Posts (Atom)