Showing posts with label SQL. Show all posts
Showing posts with label SQL. Show all posts
Friday, November 23, 2018
Happy Fibonacci day, here is how to generate a Fibonacci sequence in SQL
{kind=link}
Image by Jahobr - Own work, CC0, Link
Since today is Fibonacci day I decided to to a short post about how to do generate a Fibonacci sequence in T-SQL. But first let's take a look at what a Fibonacci sequence actually is.
In mathematics, the Fibonacci numbers are the numbers in the following integer sequence, called the Fibonacci sequence, and characterized by the fact that every number after the first two is the sum of the two preceding ones:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
Often, especially in modern usage, the sequence is extended by one more initial term:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
November 23 is celebrated as Fibonacci day because when the date is written in the mm/dd format (11/23), the digits in the date form a Fibonacci sequence: 1,1,2,3.
So here is how you can generate a Fibonacci sequence in SQL, you can do it by using s recursive table expression. Here is what it looks like if you wanted to generate the Fibonacci sequence to up to a value of 1 million
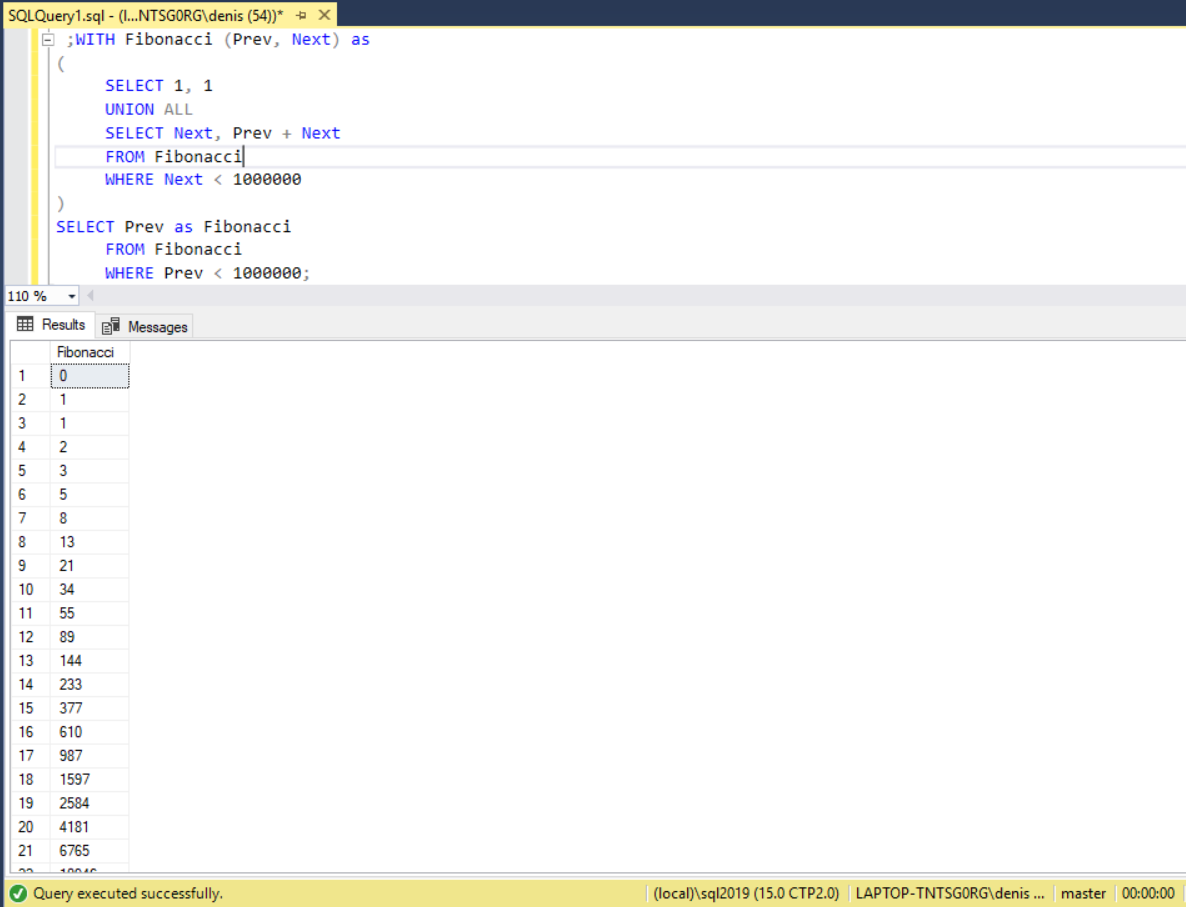
;WITH Fibonacci (Prev, Next) as ( SELECT 1, 1 UNION ALL SELECT Next, Prev + Next FROM Fibonacci WHERE Next < 1000000 ) SELECT Prev as Fibonacci FROM Fibonacci WHERE Prev < 1000000
That will generate a Fibonacci sequence that starts with 1, if you need a Fibonacci sequence that start with 0, all you have to do is replace the 1 to 0 in the first select statement
;WITH Fibonacci (Prev, Next) as ( SELECT 1, 1 UNION ALL SELECT Next, Prev + Next FROM Fibonacci WHERE Next < 1000000 ) SELECT Prev as Fibonacci FROM Fibonacci WHERE Prev < 1000000
Here is what it looks like in SSMS
{kind=link}
Happy Fibonacci day!!
I created the same for PostgreSQL, the only difference is that you need to add the keyword RECURSIVE in the CTE, here is that post Happy Fibonacci day, here is how to generate a Fibonacci sequence in PostgreSQL
I created the same for PostgreSQL, the only difference is that you need to add the keyword RECURSIVE in the CTE, here is that post Happy Fibonacci day, here is how to generate a Fibonacci sequence in PostgreSQL
Sunday, August 17, 2008
Only In A Database Can You Get 1000% + Improvement By Changing A Few Lines Of Code
Take a look at this query.
SELECT * FROM
(
SELECT customer_id, ‘MTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table
WHERE YEAR(payment_dt) = YEAR(GETDATE())
and MONTH(payment_dt) = MONTH(GETDATE())
GROUP BY customer_id) MTD_payments
UNION ALL
(
SELECT customer_id, ‘YTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table
WHERE
WHERE YEAR(payment_dt) = YEAR(GETDATE())
GROUP BY customer_id) YTD_payments
UNION ALL
(
SELECT customer_id, ‘LTD’ AS record_type, COUNT(*), SUM(…), AVG(…)
FROM payment_table) LTD_payments
) payments_report
ORDER BY customer_id, record_type
Can you see the problem?
A person had this query, it would run for over 24 hours. Wow, that is pretty bad, I don't think I had ever written something that ran over an hour, and the ones I did were mostly defragmentation and update statistics jobs.
The problem is that the following piece of code
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
is not sargable. First what does it mean to be sargable? A query is said to be sargable if the DBMS engine can take advantage of an index to speed up the execution of the query (using index seeks, not covering indexes). The term is derived from a contraction of Search ARGument Able.
This query is not sargable because there is a function on the column, whenever you use a function on the column you will not get an index seek but an index scan. The difference between an index seek and an index scan can be explained like this: when searching for something in a book, you go to the index in the back find the page number and go to the page, that is an index seek. When looking for something in a book you go from page one until the last page, read all the words on all the ages and get what you need, that was an index scan. Do you see how much more expensive in terms of performance that was?
Let's get back to the query, what can we do to make this piece of code use an index seek?
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
You would change it to this:
where payment_dt>= dateadd(mm, datediff(mm, 0, getdate())+0, 0)
and payment_dt < dateadd(mm, datediff(mm, 0, getdate())+1, 0)
You can see the complete question on the MSDN forum site here:
http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3746751&SiteID=1
The Person said that his query went from over 24 hours to 36 seconds. Wow!! That is very significant. hardware cannot help you out if you have bad queries like that.
The same exact day I answered a very similar question, take a look here: http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3752248&SiteID=1
The person had this
If you are interested in some blogposts about dates, take a look at these two which I wrote earlier
How Are Dates Stored In SQL Server?
Do You Know How Between Works With Dates?
SELECT * FROM
Can you see the problem?
A person had this query, it would run for over 24 hours. Wow, that is pretty bad, I don't think I had ever written something that ran over an hour, and the ones I did were mostly defragmentation and update statistics jobs.
The problem is that the following piece of code
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
is not sargable. First what does it mean to be sargable? A query is said to be sargable if the DBMS engine can take advantage of an index to speed up the execution of the query (using index seeks, not covering indexes). The term is derived from a contraction of Search ARGument Able.
This query is not sargable because there is a function on the column, whenever you use a function on the column you will not get an index seek but an index scan. The difference between an index seek and an index scan can be explained like this: when searching for something in a book, you go to the index in the back find the page number and go to the page, that is an index seek. When looking for something in a book you go from page one until the last page, read all the words on all the ages and get what you need, that was an index scan. Do you see how much more expensive in terms of performance that was?
Let's get back to the query, what can we do to make this piece of code use an index seek?
where year(payment_dt) = year(getDate())
and month(payment_dt) = month(getDate())
You would change it to this:
where payment_dt>= dateadd(mm, datediff(mm, 0, getdate())+0, 0)
and payment_dt < dateadd(mm, datediff(mm, 0, getdate())+1, 0)
You can see the complete question on the MSDN forum site here:
http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3746751&SiteID=1
The Person said that his query went from over 24 hours to 36 seconds. Wow!! That is very significant. hardware cannot help you out if you have bad queries like that.
The same exact day I answered a very similar question, take a look here: http://forums.microsoft.com/msdn/ShowPost.aspx?PostID=3752248&SiteID=1
The person had this
ANDDATEDIFF(d,'08/10/2008', DateCreated)>= 0
ANDDATEDIFF(d, DateCreated,'08/15/2008')>= 0
I told him to change it to this
AND DateCreated>= '08/10/2008'
and DateCreated <= '08/15/2008'
And that solved that query. If you are interested in some more performance, I have written some Query Optimization items on the LessThanDot Wiki. Below are some direct links
Case Sensitive Search
No Functions on Left Side of Operator
Query Optimizations With Dates
Optimization: Set Nocount On
No Math In Where Clause
Don't Use (select *), but List Columns
If you are interested in some blogposts about dates, take a look at these two which I wrote earlier
How Are Dates Stored In SQL Server?
Do You Know How Between Works With Dates?
Labels:
database,
Dates,
Indexing,
Performance Tuning,
rdbms,
SQL,
T-SQL,
temporal data
Sunday, June 01, 2008
Less Than Dot A New community Site Has Been Launched
Myself and a bunch of friends have been working on Less Than Dot for a while now. The site has a forum, blogs and a wiki. More info why we started Less Than Dot and who we are can be found here: http://www.lessthandot.com/aboutus.php
Since I am mostly a SQL guy, I wrote a collection of SQL Server hacks. This collection of SQL hacks is available on the Wiki, right now we have 8 sections and between 70 and 80 hacks. Ideally we will have more hacks and we will also have a SQL admin hacks page in the future.
SQL Server Hacks Sections
* 1 NULLS
* 2 Dates
* 3 Sorting, Limiting Ranking, Transposing and Pivoting
* 4 Handy tricks
* 5 Pitfalls
* 6 Query Optimization
* 7 Undocumented but handy
* 8 Usefull Admin stuff For The Developer
Below are some direct links to a couple hacks, you can also get a list of all the hacks on the wiki itself here: SQL Server Programming Hacks
Since I am mostly a SQL guy, I wrote a collection of SQL Server hacks. This collection of SQL hacks is available on the Wiki, right now we have 8 sections and between 70 and 80 hacks. Ideally we will have more hacks and we will also have a SQL admin hacks page in the future.
SQL Server Hacks Sections
* 1 NULLS
* 2 Dates
* 3 Sorting, Limiting Ranking, Transposing and Pivoting
* 4 Handy tricks
* 5 Pitfalls
* 6 Query Optimization
* 7 Undocumented but handy
* 8 Usefull Admin stuff For The Developer
Below are some direct links to a couple hacks, you can also get a list of all the hacks on the wiki itself here: SQL Server Programming Hacks
- Trouble With ISDATE And Converting To SMALLDATETIME
Row To Column (PIVOT)
Column To Row (UNPIVOT)
Five ways to return all rows from one table which are not in another table
Order IP Addresses
Use XACT_STATE() To Check For Doomed Transactions
Three differences between COALESCE and ISNULL
Case sensitive search
Use the sys.dm_db_index_usage_stats dmv to check if indexes are being used
Hopefully you will like the site and find some good content, if you have a question then don't hesitate to ask it in a forum.
Subscribe to:
Posts (Atom)