Thursday, October 05, 2017
Data types storage differences
Char vs NChar
- What happens to your backup and restore process, will it be faster or slower, will the files be bigger if not compressed?
- What about when transferring the results to and from your database server, are the packets able to store the same number of characters.
- What about the amount of data on a page, what does this do to indexes and index lookups, how does it affect index maintenance?
Some examples of what I have seen stored in nchar and nvarchar when realy you shouldn't:
US addresses
Social Security Numbers (which were stored in plain text none the less)
Integer data (enforced by constraints or the app layer to make sure these were only digits)
CREATE TABLE TestChar (SomeCol char(10))
GO
CREATE TABLE TestNChar (SomeCol nchar(10))
GO
CREATE index ix_test on TestChar(SomeCol)
GO
CREATE index ix_test on TestNChar(SomeCol)
GO
INSERT TestChar
SELECT TOP 1000000 '1234567890'
FROM sys.sysobjects c1
CROSS JOIN sys.sysobjects c2
CROSS JOIN sys.sysobjects c3
CROSS JOIN sys.sysobjects c4
GO
INSERT TestNChar
SELECT TOP 1000000 '1234567890'
FROM sys.sysobjects c1
CROSS JOIN sys.sysobjects c2
CROSS JOIN sys.sysobjects c3
CROSS JOIN sys.sysobjects c4
GO
EXEC sp_spaceused 'TestChar'
EXEC sp_spaceused 'TestNChar'
62736 KB
Implicit conversions
SET SHOWPLAN_TEXT ON
GO
DECLARE @v varchar(10) = '0123456789'SELECT * FROM TestChar WHERE SomeCol LIKE @v +'%'GOSET SHOWPLAN_TEXT OFFGO
|--Nested Loops(Inner Join, OUTER REFERENCES:([Expr1008], [Expr1009], [Expr1010]))
|--Compute Scalar(DEFINE:([Expr1008]=LikeRangeStart([@v]+'%'), [Expr1009]=LikeRangeEnd([@v]+'%'), [Expr1010]=LikeRangeInfo([@v]+'%')))
| |--Constant Scan
|--Index Seek(OBJECT:([Performance].[dbo].[TestChar].[ix_test]), SEEK:([Performance].[dbo].[TestChar].[SomeCol] > [Expr1008] AND [Performance].[dbo].[TestChar].[SomeCol] < [Expr1009]), WHERE:([Performance].[dbo].[TestChar].[SomeCol] like [@v]+'%') ORDERED FORWARD)
DROP INDEX TestChar.ix_test
GO
ALTER TABLE TestChar ALTER COLUMN SomeCol nchar(10)
GO
CREATE INDEX ix_test on TestChar(SomeCol)
GO
SET SHOWPLAN_TEXT ON
GO
DECLARE @v varchar(10) = '0123456789'
SELECT * FROM TestChar WHERE SomeCol LIKE @v +'%'
GO
SET SHOWPLAN_TEXT OFF
GO
|--Nested Loops(Inner Join, OUTER REFERENCES:([Expr1008], [Expr1009], [Expr1010]))
|--Compute Scalar(DEFINE:([Expr1008]=LikeRangeStart(CONVERT_IMPLICIT(nvarchar(11),[@v]+'%',0)), [Expr1009]=LikeRangeEnd(CONVERT_IMPLICIT(nvarchar(11),[@v]+'%',0)), [Expr1010]=LikeRangeInfo(CONVERT_IMPLICIT(nvarchar(11),[@v]+'%',0))))
| |--Constant Scan
|--Index Seek(OBJECT:([Performance].[dbo].[TestChar].[ix_test]), SEEK:([Performance].[dbo].[TestChar].[SomeCol] > [Expr1008] AND [Performance].[dbo].[TestChar].[SomeCol] < [Expr1009]), WHERE:([Performance].[dbo].[TestChar].[SomeCol] like CONVERT_IMPLICIT(nvarchar(11),[@v]+'%',0)) ORDERED FORWARD)
SET SHOWPLAN_TEXT ON
GO
DECLARE @v nvarchar(10) = '0123456789'
SELECT * FROM TestChar WHERE SomeCol LIKE @v +'%'
GO
SET SHOWPLAN_TEXT OFF
GO
|--Compute Scalar(DEFINE:([Expr1008]=LikeRangeStart([@v]+N'%'), [Expr1009]=LikeRangeEnd([@v]+N'%'), [Expr1010]=LikeRangeInfo([@v]+N'%')))
| |--Constant Scan
|--Index Seek(OBJECT:([Performance].[dbo].[TestChar].[ix_test]), SEEK:([Performance].[dbo].[TestChar].[SomeCol] > [Expr1008] AND [Performance].[dbo].[TestChar].[SomeCol] < [Expr1009]), WHERE:([Performance].[dbo].[TestChar].[SomeCol] like [@v]+N'%') ORDERED FORWARD)
Using larger datatypes when it is not needed
Storage size is 1 byte. Integer data from 0 through 255.
Storage size is 2 bytes. Integer data from -2^15 (-32,768) through 2^15 - 1 (32,767).
Storage size is 4 bytes. Integer data from -2^31 (-2,147,483,648) through 2^31 - 1 (2,147,483,647).
Storage size is 8 bytes. Integer data from -2^63 (-9,223,372,036,854,775,808) through 2^63-1 (9,223,372,036,854,775,807).
Now imagine facebook with a billion users decided to use bigint as CountryID in their Country table, this key is then uses as a foreign key in the user demographics table. This is wasteful,either use a smallint since we won't go through 32 thousand countries in the foreseeable feature or use the 2 or 3 character ISO code.
The problem is even worse if you have a compound 6 column key and it is used as a foreign key in tons of other tables...that was real fun to clean up....use a surrogate 1 column key in that case...but be sure to test....normalize till it hurts then denormalize till it works....I will cover normalization in another post...just wanted to mention it
Friday, November 04, 2016
Are your foreign keys indexed? If not, you might have problems
{kind=link}
When you add a primary key constraint to a table in SQL Server, an index will be created automatically. When you add a foreign key constraint no index will be created. This might cause issues if you don't know that this is the behavior in SQL Server. Maybe there should be an option to automatically index the foreign keys in SQL Server, what do you think?
The other day some deletes on a newer table in the test environment became really slow. We had a primary table with a couple of hundred rows, we loaded up between 200 and 300 million rows into the child table. Then we deleted the child rows, this was fast. After this, we deleted one row from the primary table and this took several seconds.
When I looked at this I noticed something interesting, the most time during the delete was spent doing a lookup at the child table. Then I noticed that the foreign key was not indexed. After we added the index the delete became thousands of times faster
Let's try to replicate that behavior here
First create these primary table, we will add 2048 rows to this table
--Table that will have 2048 rows CREATE TABLE Store(StoreID int not null, DateCreated datetime not null, StoreName varchar(500), constraint pk_store primary key (StoreID)) GO --insert 2048 rows INSERT Store SELECT ROW_NUMBER() OVER(ORDER BY t1.number) AS StoreID,DATEADD(dd,t1.number,'20161101')
AS datecreated, NEWID() FROM master..spt_values t1 WHERE t1.type = 'p'
Now create the child table and add 500K rows, this might take up to 1 minute to run since the rows are pretty wide.
-- table that will also have 500000 rows, fk will be indexed CREATE TABLE GoodsSold (TransactionID int not null, StoreID int not null, DateCreated datetime not null, SomeValue char(5000), constraint pk_transaction primary key (TransactionID)) INSERT GoodsSold SELECT top 500000 ROW_NUMBER() OVER(ORDER BY t1.number) AS TransactionID, t2.StoreID,
DATEADD(dd,t1.number,'20161101') AS datecreated, REPLICATE('A',5000) FROM master..spt_values t1 CROSS JOIN Store t2 WHERE t1.type = 'p'
Now it is time to add the foreign key constraint and index this foreign key constraint
-- adding the foreign key ALTER TABLE GoodsSold WITH CHECK ADD CONSTRAINT FK_StoreID FOREIGN KEY(StoreID) REFERENCES Store(StoreID) GO ALTER TABLE GoodsSold CHECK CONSTRAINT FK_StoreID GO -- index the foreign key CREATE index ix_StoreID on GoodsSold(StoreID) GO
We will create another set of tables, let's start with the primary table, we will just insert into this table all the rows from the primary table we created earlier
-- create another primary table CREATE TABLE StoreFK(StoreID int not null, DateCreated datetime not null, StoreName varchar(500), constraint pk_storefk primary key (StoreID)) GO -- add the same 2048 rows from the primary table with indexed FK INSERT StoreFK SELECT * FROM Store GO
For the child table, it is the same deal, we will add all the rows from the child table we created earlier into this table
-- Add another FK table CREATE TABLE GoodsSoldFKNoIndex (TransactionID int not null, StoreID int not null, DateCreated datetime not null, SomeValue char(5000), constraint pk_transactionfk primary key (TransactionID)) -- add same 500K rows from table with FK index INSERT GoodsSoldFKNoIndex SELECT * FROM GoodsSold
Let's add the foreign key constraint, but this time we are not indexing the foreign key constraint
-- add the FK but do not index this ALTER TABLE GoodsSoldFKNoIndex WITH CHECK ADD CONSTRAINT FK_StoreID_FK
FOREIGN KEY(StoreID) REFERENCES StoreFK(StoreID) GO ALTER TABLE GoodsSoldFKNoIndex CHECK CONSTRAINT FK_StoreID_FK GO
Let make sure that the tables have the same number of rows
-- check that the tables have the same rows exec sp_spaceused 'GoodsSold' exec sp_spaceused 'GoodsSoldFKNoIndex'
| name | rows | reserved | data | index_size | unused |
|---|---|---|---|---|---|
| GoodsSold | 500000 | 4024976 KB | 4000000 KB | 22520 KB | 2456 KB |
| GoodsSoldFKNoIndex | 500000 | 4015440 KB | 4000000 KB | 14936 KB | 504 KB |
Now that we are setup, let's wipe out all the rows from the child table for a specific StoreID, the SELECT statements should return 0 rows
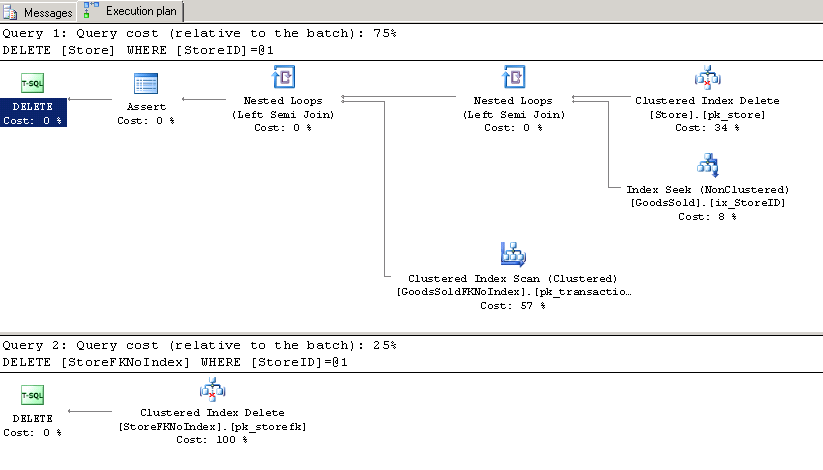
DELETE GoodsSoldFKNoIndex WHERE StoreID = 507 DELETE GoodsSold WHERE StoreID = 507 SELECT * FROM GoodsSoldFKNoIndex WHERE StoreID = 507 SELECT * FROM GoodsSold WHERE StoreID = 507
Now we are getting to the interesting part, turn on Include Actual Execution Plan, run statistics IO or run this in Plan Explorer
DELETE Store WHERE StoreID = 507 DELETE StoreFK WHERE StoreID = 507
You will see something like this
So 75% compared to 25%, not good but doesn't look catastrophic, if you have statistics time on, you will see the following
{kind=link}
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 16 ms.
SQL Server Execution Times:
CPU time = 561 ms, elapsed time = 575 ms.
Now it looks much worse
What about statistics io?
Table 'GoodsSold'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Store'. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'GoodsSoldFKNoIndex'. Scan count 1, logical reads 501373, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'StoreFK'. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
{kind=link}
There you have it, not indexing foreign keys can have a big impact even though the child table might not have any data at all
See also When did SQL Server stop putting indexes on Foreign Key columns? by Kimberly Tripp
Sunday, December 16, 2007
EXISTS or COUNT(*)
IF (SELECT COUNT(*) FROM SomeTable
WHERE SomeColumn = SomeValue )> 0
Or do you use this
IF EXISTS (SELECT * FROM SomeTable WHERE SomeColumn = SomeValue )
If you answered COUNT(*) then maybe you should take a look these two articles
Andrew Kelly has a nice post on SQLBlog
http://sqlblog.com/blogs/andrew_kelly/archive/2007/12/15/exists-vs-count-the-battle-never-ends.aspx
Matija Lah has a good post on his snaps & snippets blog
http://milambda.blogspot.com/2006/10/exists-or-not-exists-that-is-question.html
Monday, October 15, 2007
Interview With Kalen Delaney About Inside Microsoft SQL Server 2005 Query Tuning and Optimization
{kind=link}
The question-and-answer session with Kalen that follows was conducted via email.
What is the audience for this book, is it the enterprise user or can a small department benefit from the tips in this book?
Because this book deals with query tuning, anyone who writes SQL queries for SQL Server can benefit. Very little in the book is geared towards system tuning, so the size of the machine doesn’t really matter. Now of course, if you have a very small system with very small tables, you won’t get as much benefit out of tuning your queries. However, if you have any tables of more than a few thousand rows, and you do any joins, you will need to tune your queries. In addition, the issues of blocking and concurrency control can impact any system, no matter how small.
What new technologies in SQL Server 2005 do you think are the most beneficial for performance?
For very large databases, the best new technology is partitioning. For any size system, if you have had serious performance problems due to blocking, you might find a big performance benefit by using one of the snapshot-based isolation levels, but you really need to understand the resource costs that come along with the improved performance. For your individual queries, I think the new optimizer hints and query level recompiles can make a big difference. For indexes, the ability to add included columns to nonclustered indexes can give some of your hard-to-tune queries a major performance boost.
What will a person who reads this book gain in terms of understanding how to performance tune a server?
The focus of this book is not so much on tuning the server, but on tuning queries. There is more in Inside SQL Server 2005: The Storage Engine on server issues such as memory and processor management. The biggest server wide issues are covered in Chapter 5, when I talk about managing the plan cache, and how and when query plans are reused.
Is the book geared towards a beginner/intermediate level user or do you have to be an advanced user to really utilize the information in this book?
The book is not geared towards beginners, but everyone should be able to get something out of it. It’s primarily geared to SQL Server developers and DBA’s who have been working with SQL Server for a while, and have encountered performance problems that they are trying to find solutions for.
With all the changes in SQL Server 2005, how critical has the tempdb become in regards to performance?
Tempdb has always been important. In SQL Server 2005, if you are using one of the snapshot-based isolation levels, you are going to have to be more aware of the demands placed on tempdb, both in the sizing requirements and the additional I/O resources needed. Fortunately, SQL Server 2005 provides tools to monitor tempdb, including a dozen new performance monitor counters, and a dynamic management view, sys.dm_db_file_space_usage, that keeps track of how much space in tempdb is being used for each of the different kind of object stored in tempdb.
I understand that this is the first time you wrote with a team of other writers; can you tell us something about that experience?
I initially thought that not having to write the whole volume by myself meant that I could get it done sooner, but that was not the case. Everyone had their own schedule and their own way of writing. The personal aspect of working with the other authors was great. I deeply respect all of the others and it was an honor to be working so closely with them. I had some concerns about the depth of coverage and I wondered whether all the chapters would end up being as deep as I hoped for, but that turned out not to be a major problem. The only real issues were agreeing on a common terminology and coding style, and even that wasn’t that big of an issue, because I got to do a final editing pass on everyone’s chapters.
What SQL Server books are on your bookshelf?
All of the Inside SQL Server books are there, of course, and all of Ken Henderson’s books. Bob Beauchemin’s book is in my car, to read while I am waiting for the ferryboat, and while on the ferry. I also have technical books that aren’t SQL Server specific, such as Jim Gray’s Transaction Processing, Russinovich’s and Solomon’s Windows Internals, Chris Date’s Introduction to Database Systems and Mike Stonebraker’s Readings in Database Systems.
Why do you write technical books?
I love working with SQL Server and trying to find out all I can about it. When I found that I could explain difficult concepts in a training environment, I thought I could do the same thing in a written format, and reach more people that way. I have always loved explaining things, ever since I was a teaching assistant for High School Math.
Will you be updating your books for SQL Server 2008?
I have just started meeting with my editors at Microsoft Press about SQL Server 2008, and it looks like a revision is in the plans. We’re really looking at it as just a revision, with the same structures as the current books, with straightforward changes and the inclusion of new features.
Name three things that are new in SQL Server 2005 that you find are the most valuable?
Dynamic Management Views, Dynamic Management Views, and Dynamic Management Views!
Oh, you wanted three different things? ;-) How about XML query plans and optimization hints. (I’m also very fond of many of the new TSQL constructs, but I was only talking about things that I cover in my new book.)
Name three things which are coming in SQL Server 2008 that you are most excited about?
You’ll have to ask me this next time. I have actually been avoiding SQL Server 2008 while I was getting my Query Tuning and Optimization book finished, because I didn’t want to get distracted.
Can you list any third party tools that you find useful to have as a SQL Server developer/admin?
I’ve tried a few other products, but usefully I find that it is much easier to just stick with the Microsoft line and use the tools provided with the product.
Name some of your favorite non-technical books.
Oh, I love to read. It would be impossible to list my favorite books, but I can tell you my favorite authors, most of whom write science fiction: Lois McMaster Bujold, Ursula LeGuin, Sheri Tepper, Orson Scott Card, Octavia Butler, Elizabeth Moon. I also love to read historical fiction like Leon Uris.
Wednesday, May 30, 2007
Speed Up Performance And Slash Your Table Size By 90% By Using Bitwise Logic
You have all seen websites where you can pick a bunch of categories by selection a bunch of check boxes. usually what you do is store those in a lookup table and then you create another table where you store all the categories for each customer.
What if I tell you that you can store all that info in 1 row instead of 10 rows if a customer picked 10 categories.
Take a look at this
1 Classic Rock
2 Hard Rock
4 Speed/Trash Metal
You will store a value of 1 + 2 + 4 = 7(you just sum the values)
Now run this to check, the result will be 7 for a match and some other value otherwise
select 7 | 1,
7 | 2,
7 |3,
7 |4,
7 |5,
7 |6,
7 |7,
7 |8,
7 |20
What is this |(pipe symbol)?
From Books on line
The bitwise operator performs a bitwise logical OR between the two expressions, taking each corresponding bit for both expressions. The bits in the result are set to 1 if either or both bits (for the current bit being resolved) in the input expressions have a value of 1; if neither bit in the input expressions is 1, the bit in the result is set to 0.
The bitwise operator requires two expressions, and it can be used on expressions of only the integer data type category.
Here is how you would typically use this, first create this table
CREATE TABLE NumbersTable (Num int)
INSERT NumbersTable VALUES(1)
INSERT NumbersTable VALUES(2)
INSERT NumbersTable VALUES(3)
INSERT NumbersTable VALUES(4)
INSERT NumbersTable VALUES(5)
INSERT NumbersTable VALUES(6)
INSERT NumbersTable VALUES(7)
INSERT NumbersTable VALUES(8)
INSERT NumbersTable VALUES(9)
INSERT NumbersTable VALUES(10)
INSERT NumbersTable VALUES(11)
INSERT NumbersTable VALUES(12)
GO
Now run this
SELECT Num,
CASE 7 |Num WHEN 7 THEN'Yes'ELSE'No'ENDAS COL
FROM NumbersTable
Here is the output
Num COL
---- ---
1 Yes
2 Yes
3 Yes
4 Yes
5 Yes
6 Yes
7 Yes
8 No
9 No
10 No
11 No
12 No
Okay enough theory let's start with some SQL code. First create this table which will hold all the categories
CREATETABLE MusicChoice (ID INTPRIMARYKEY,
ChoiceDescription VARCHAR(100))
INSERT MusicChoice VALUES(2,'Hard Rock')
INSERT MusicChoice VALUES(3,'Speed/Trash Metal')
INSERT MusicChoice VALUES(4,'Classical')
INSERT MusicChoice VALUES(5,'Rap')
INSERT MusicChoice VALUES(6,'Blues')
INSERT MusicChoice VALUES(7,'Jazz')
INSERT MusicChoice VALUES(8,'Alternative Rock')
INSERT MusicChoice VALUES(9,'Easy Listening')
INSERT MusicChoice VALUES(10,'Progressive Rock')
INSERT MusicChoice VALUES(11,'Punk Rock')
INSERT MusicChoice VALUES(12,'Swing')
INSERT MusicChoice VALUES(13,'Techno')
INSERT MusicChoice VALUES(14,'Pop')
INSERT MusicChoice VALUES(15,'Disco')
INSERT MusicChoice VALUES(16,'Big Band')
INSERT MusicChoice VALUES(17,'Gospel')
INSERT MusicChoice VALUES(18,'Heavy Metal')
INSERT MusicChoice VALUES(19,'House')
INSERT MusicChoice VALUES(20,'Celtic')
Now create the Bitwise table
CREATETABLE BitwiseMusicChoice (ID INTPRIMARYKEY,
ChoiceDescription VARCHAR(100))
We will use the POWER function to create the correct values
run this
SELECT id,POWER(2,id-1)BitID,ChoiceDescription
FROM MusicChoice
id BitID ChoiceDescription
1 1 Classic Rock
2 2 Hard Rock
3 4 Speed/Trash Metal
4 8 Classical
5 16 Rap
6 32 Blues
7 64 Jazz
8 128 Alternative Rock
9 256 Easy Listening
10 512 Progressive Rock
11 1024 Punk Rock
12 2048 Swing
13 4096 Techno
14 8192 Pop
15 16384 Disco
16 32768 Big Band
17 65536 Gospel
18 131072 Heavy Metal
19 262144 House
20 524288 Celtic
Now insert it into the BitwiseMusicChoice table
INSERT BitwiseMusicChoice
SELECTPOWER(2,id-1)BitID,ChoiceDescription
FROM MusicChoice
Now create this customer table
CREATETABLE Customer (CustomerID intidentity, CustomerCode uniqueidentifiernotnull)
INSERT Customer VALUES('1DAB5C03-BC23-4FB5-AC3D-A46489459FE9')
INSERT Customer VALUES('F7DDCDBC-F646-493A-B872-4E2E82EA8E14')
INSERT Customer VALUES('E8A4C3D2-AEB0-4821-A49D-3BF085354448')
INSERT Customer VALUES('52581088-C427-4D2F-A782-250564D44D8C')
INSERT Customer VALUES('1B2622C4-6C17-4E74-99D6-336197FBBCFF')
Now we will insert a total of 10000 customers
SETNOCOUNTON
BEGINTRAN
DECLARE @LoopCounter INT
SET @LoopCounter = 6
WHILE @LoopCounter <= 10000
BEGIN
INSERT Customer VALUES(NEWID())
SET @LoopCounter = @LoopCounter + 1
END
COMMIT WORK
GO
ALTERTABLE Customer ADDCONSTRAINT pk_Customer PRIMARYKEY(CustomerCode)
Create another table to hold the choices
CREATETABLE CustomerMusicChoice (id INTidentity, MusicChoiceID int, CustomerCode uniqueidentifier)
SETNOCOUNTON
BEGINTRAN
DECLARE @LoopCounter INT
DECLARE @CustID uniqueidentifier
SET @LoopCounter = 1
WHILE @LoopCounter <= 10000
BEGIN
SELECT @CustID = CustomerCode
FROM Customer
WHERE CustomerID = @LoopCounter
INSERT Customer VALUES(NEWID())
INSERT CustomerMusicChoice(MusicChoiceID,CustomerCode)
SELECTTOP 10 id,@CustID
FROM MusicChoice
ORDERBYNEWID()
SET @LoopCounter = @LoopCounter + 1
END
COMMIT WORK
GO
Now add these indexes
CREATEINDEX ix_CustomerMusicChoice_Cust On CustomerMusicChoice(CustomerCode)
CREATE
INDEX ix_CustomerMusicChoice_ID On CustomerMusicChoice(MusicChoiceID)Create the BitwiseCustomerMusicChoice which will hold the Bitwise values
CREATETABLE BitwiseCustomerMusicChoice (id INTidentity, MusicChoiceID int, CustomerCode uniqueidentifiernotnull)
INSERTINTO BitwiseCustomerMusicChoice
SELECTSUM(POWER(2,MusicChoiceID-1))as MusicChoiceID,CustomerCode
FROM CustomerMusicChoice
GROUPBY CustomerCode
ALTER
Now let's test performance. Hit CTRL + K (SQL 2000) or CTRL + M (SQL 2005)
These 2 queries will return something like this
ID ChoiceDescription Picked
8 Alternative Rock No
16 Big Band No
6 Blues No
20 Celtic No
1 Classic Rock No
4 Classical Yes
15 Disco Yes
9 Easy Listening Yes
17 Gospel No
2 Hard Rock No
18 Heavy Metal Yes
19 House Yes
7 Jazz Yes
14 Pop Yes
10 Progressive Rock Yes
11 Punk Rock No
5 Rap No
3 Speed/Trash Metal Yes
12 Swing Yes
13 Techno No
SELECT mc.ID,ChoiceDescription,CASEWHEN CustomerCode ISNULLTHEN'No'ELSE'Yes'END Picked
FROM CustomerMusicChoice cmc
RIGHTJOIN MusicChoice mc on cmc.MusicChoiceID = mc.id
AND CustomerCode ='1DAB5C03-BC23-4FB5-AC3D-A46489459FE9'
ORDERBY ChoiceDescription
SELECT bmc.ID,ChoiceDescription,
CASEWHEN bmc.ID |MusicChoiceID =MusicChoiceID THEN'Yes'
ELSE'No'
ENDAS Picked
FROM BitwiseCustomerMusicChoice cmc
CROSSJOIN BitwiseMusicChoice bmc
WHERE CustomerCode ='1DAB5C03-BC23-4FB5-AC3D-A46489459FE9'
ORDERBY ChoiceDescription
67.60% against 32.40% not bad right?
[画像:Plan1]
{kind=link}
Now run this, we will add AND bmc.ID > 0 to both queries. This will change an index scan to an index seek in the bottom query
SELECT mc.ID,ChoiceDescription,CASEWHEN CustomerCode ISNULLTHEN'No'ELSE'Yes'END Picked
FROM CustomerMusicChoice cmc
RIGHTJOIN MusicChoice mc on cmc.MusicChoiceID = mc.id
AND CustomerCode ='1DAB5C03-BC23-4FB5-AC3D-A46489459FE9'
AND mc.ID > 0
ORDERBY ChoiceDescription
SELECT bmc.ID,ChoiceDescription,
CASEWHEN bmc.ID |MusicChoiceID =MusicChoiceID THEN'Yes'
ELSE'No'
ENDAS Picked
FROM BitwiseCustomerMusicChoice cmc
CROSSJOIN BitwiseMusicChoice bmc
WHERE CustomerCode ='1DAB5C03-BC23-4FB5-AC3D-A46489459FE9'
AND bmc.ID > 0
ORDERBY ChoiceDescription
That improved the performance a little. 82.75% against 17.25%
[画像:Plan2]
{kind=link}
Now look at the tables, after running dbcc showcontig you can see that the BitwiseCustomerMusicChoice is about 1/10th the size of the CustomerMusicChoice table which is as expected.
dbcc showcontig ('BitwiseCustomerMusicChoice')
---------------------------------------------------------------------------
DBCC SHOWCONTIG scanning 'BitwiseCustomerMusicChoice' table...
Table: 'BitwiseCustomerMusicChoice' (772197801); index ID: 1, database ID: 26
TABLE level scan performed.
- Pages Scanned................................: 41
- Extents Scanned..............................: 6
- Extent Switches..............................: 5
- Avg. Pages per Extent........................: 6.8
- Scan Density [Best Count:Actual Count].......: 100.00% [6:6]
- Logical Scan Fragmentation ..................: 0.00%
- Extent Scan Fragmentation ...................: 0.00%
- Avg. Bytes Free per Page.....................: 48.0
- Avg. Page Density (full).....................: 99.41%
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
dbcc showcontig ('CustomerMusicChoice')
---------------------------------------------------------------------------
DBCC SHOWCONTIG scanning 'CustomerMusicChoice' table...
Table: 'CustomerMusicChoice' (724197630); index ID: 0, database ID: 26
TABLE level scan performed.
- Pages Scanned................................: 428
- Extents Scanned..............................: 55
- Extent Switches..............................: 54
- Avg. Pages per Extent........................: 7.8
- Scan Density [Best Count:Actual Count].......: 98.18% [54:55]
- Extent Scan Fragmentation ...................: 40.00%
- Avg. Bytes Free per Page.....................: 386.5
- Avg. Page Density (full).....................: 95.22%
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
What happens if you want to get the total count of for example Classical?
SELECTCOUNT(*)
FROM CustomerMusicChoice cmc
JOIN MusicChoice mc on cmc.MusicChoiceID = mc.id
WHERE mc.ChoiceDescription ='Classical'
SELECTCOUNT(*)
FROM BitwiseCustomerMusicChoice cmc
JOIN BitwiseMusicChoice bmc ON bmc.ID |MusicChoiceID =MusicChoiceID
WHERE bmc.ChoiceDescription ='Classical'
Here are execution plans for SQl Server 2000 and 2005
{kind=link}
{kind=link}
As you can see SQL Server 2005 has a bigger difference than SQL Server 2000
Now let's look at the overal picture, on a busy system you will have the customer queries running many times an hour/day. The report queries will run maybe a couple a times a day. I think this trade off is perfectly acceptable because overall your system will perform better. Another thing to keep in mind is that instead of 10 inserts you only have to do 1, same with updates, all these little things add up to a lot eventualy.
So as you can see using bitwise logic is a great way to accomplish a couple of things
Reduce table size
Speed up backup and recovery because your table is much smaller
Improve performance
Of course you have to do some testing for yourself because it might not be appropriate for your design. If your system is more of an OLAP than OLTP type of system then don't bother implementing this since it won't help you.
Cross-posted from SQLBlog! - http://www.sqlblog.com