幮夛妛偺偡乀傔 戞23夞乽幙揑挷嵏偺乽柤恖寍乿傪墇偊偰亅僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠偺帋傒乿
2013擭08寧28擔
僞僌:彫椦桽帣 幮夛妛 僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠 gta
婇夋晹 傾僔僗僞儞僩丒僨傿儗僋僞乕 彫椦桽帣
奺庬偺僀儞僞價儏乕挷嵏丄僼傿乕儖僪儚乕僋丄嶲梌娤嶡丄暥專挷嵏側偳側偳...峀媊偺乽幙揑挷嵏乿偲尵傢傟傞懡條側庤朄偵偍偄偰丄懡偔偺挷嵏幰偑書偄偰偒偨嫟捠偺壽戣偑偁傞丅偦傟偼丄乽幙揑挷嵏偺柤恖寍栤戣乿偲偱傕屇傋傞傛偆側栤戣偩丅
仭偟偐偔幙揑挷嵏偺乽柤恖寍乿栤戣
幙揑挷嵏偼丄検揑挷嵏偵偔傜傋丄僗僉儖偑懏恖揑偱丄儅僯儏傾儖壔偑擄偟偔丄抦尒偺嫟桳偑擄偟偄丄偲偝傟傞偙偲偑懡偄丅偙偺偙偲偼丄晛抜壗傜偐偺幙揑挷嵏傪峴偭偰偄傞曽偵偲偭偰偼幚姶偡傞偙偲傕懡偄偺偱偼側偄偩傠偆偐丅
偦偺乽柤恖寍乿惈偼丄戝偒偔2偮丄乽僨乕僞偺庢摼乿偲乽僨乕僞偺暘愅乿偺2僼僃乕僘偱庡偵尰傟偰偔傞丅
亂僨乕僞偺庢摼亃 僒儞僾儖(僀儞僼僅乕儅儞僩)偺妋曐偐傜丄儌僨儗乕僔儑儞丄娤嶡朄丄傑偨偼婰榐偺偲傝曽傑偱丄揔愗側僨乕僞傪偳偺傛偆偵庢摼丒廂廤偡傞偐
亂僨乕僞偺暘愅亃 偦偆偟偰傕偨傜偝傟偨婰榐丄僼傿乕儖僪僲乕僩丄僀儞僞價儏乕敪尵榐側偳偺僨乕僞偐傜丄
挷嵏壽戣偵懳偟偰偳偺傛偆側峫嶡傪巤偟丄偳偺傛偆側寢榑傪摫偒弌偡偐
僣乕儖傗儌僨儖偱柧帵揑偵帒嶻壔偱偒傞晹暘偑懡偄検揑挷嵏偲偔傜傋(仸(拲婰)1)丄幙揑挷嵏偱偼忋偺傛偆側僼僃乕僘偵偍偄偰丄偦傟偧傟嫟桳僫儗僢僕偲偟偰慻怐揑偵拁愊偡傞偙偲偑崲擄側惈幙傪傕偭偰偄傞丅
偦偺懏恖惈丄柤恖寍惈偲偄偆壽戣傪崕暈偡傞帋傒偲偟偰崱夞徯夘偡傞偺偑丄僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠Grounded Theory Approach - GTA乿偲偄偆暘愅庤朄偱偁傞丅崱夞偺僄儞僩儕偼丄摿偵儅乕働僥傿儞僌丒儕僒乕僠偺幙揑挷嵏偺忋弎偺栤戣偵懳偟偰丄偙偺GTA偑壗傜偐偺僸儞僩傪梌偊偰偔傟傞偙偲傪婜懸偡傞傕偺偱偁傞丅
仭偟偐偔Grounded Theory Approach偲偼側偵偐
GTA丄擔杮岅偱偼僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠偲偦偺傑傑昞婰偡傞偙偲偑懡偄丅娕岇丒堛椕側偳偺椪彴堛妛宯偺暘栰偱偼堦掕偺晛媦傪尒偣偰偄傞幙揑挷嵏偺暘愅庤朄偱偁傞偑丄儅乕働僥傿儞僌丒儕僒乕僠偺暘栰偱偼偁傑傝巊傢傟偰偄側偄偟丄傎偲傫偳抦傜傟偰偄側偄偺偑尰忬偱偁傞(Web暘愅偺暘栰偱偼堦晹偱帋傒傜傟偰偄傞傛偆偩)(仸(拲婰)2)丅偪側傒偵丄滣栘(2006)偵傛傞偲丄2000擭偐傜2005擭偺5擭娫偱丄幙揑挷嵏傪峴偭偨娕岇宯榑暥偺9.3%偱GTA偑梡偄傜傟偰偄傞丅
敪埬偼1960擭戜丄暷幮夛妛幰偺僶乕僯乕丒僌儗僀僓乕偲傾儞僙儖儉丒僗僩儔僂僗偵傛偭偰側偝傟偨(忋偺夋憸偼擇恖偑嵟弶偵徯夘偟偨挊彂 "The Discovery of Grounded Theory"偺朚栿丅偙偙偱偼乽僨乕僞懳榖宆棟榑乿偲栿偝傟偰偄傞)丅
60擭戙摉帪偺傾儊儕僇偱偼丄幮夛僔僗僥儉棟榑偺戝壠僞儖僐僢僩丒僷乕僜儞僘傪拞怱偲偟偰丄棟榑幮夛妛偺乽僌儔儞僪丒僙僆儕乕Grand Theory乿偑堦戝挭棳偲偟偰棽惙傪嬌傔偰偄偨丅偁傜備傞幮夛揑尰徾偵揔梡偡傞偙偲偺偱偒傞幮夛偺堦斒棟榑=僌儔儞僪丒僙僆儕乕丄偦偺拪徾揑偐偮懡暘偵巚曎揑側棟榑偺乽専徹乿偵娭怱傪孹偗偰偄偨摉帪偺傾儊儕僇幮夛妛偵懳偟偰丄僌儗僀僓乕=僗僩儔僂僗偼丄傛傝尰応偵嬤偄偲偙傠偐傜棟榑傪乽嶻弌乿偡傞偙偲偑廳梫偲峫偊丄乽幙揑僨乕僞偐傜儕僕僢僩側棟榑傪峔抸偡傞乿偙偲傪栚巜偟偰GTA傪採彞偟偨丅
仭偟偐偔GTA偺曽朄榑
壖憐偺斾妑懳徾偲暘愅寢壥傪斾妑偡傞乽棟榑揑斾妑乿偺曽朄榑傗丄摼傜傟偨寢壥傪妶偐偟側偑傜嵞搙僒儞僾儕儞僌傪峴偆乽棟榑揑僒儞僾儕儞僌乿側偳丄GTA偑廳帇偡傞挷嵏嶌嬈忋偺摿挜偼懡偔偁傞丅
偟偐偟丄儅乕働僥傿儞僌丒儕僒乕僠偵墳梡傪峫偊傞偲偡傟偽丄偍偦傜偔偦偺嵟戝偺摿挜偼幙揑僨乕僞暘愅嵺偺乽僐乕僨傿儞僌乿傪掕幃壔偟偨偙偲偵偁傞丅
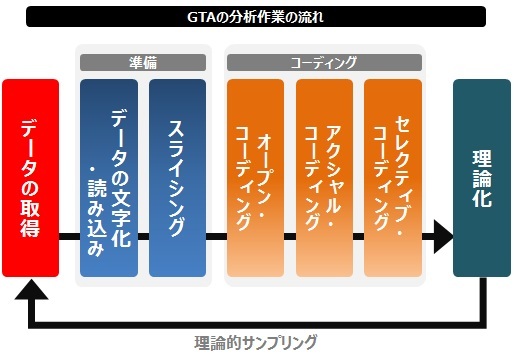
偦偙偱崱夞偼丄忋偱弎傋偨幙揑挷嵏偺2僼僃乕僘偺偆偪偺屻幰丄乽僨乕僞偺暘愅乿偺懁偵偍偗傞GTA偺暘愅偺嶌嬈偺棳傟傪傒偰偄偙偆丅(壓恾)(仸(拲婰)3)
忋偺恾偺棳傟偵廬偭偰丄愢柧偟偰偄偔丅
傑偢丄暘愅嶌嬈偺慜抜奒偲偟偰丄
亂1.暥復壔丒僨乕僞壔丒撉傒崬傒亃
僀儞僞價儏乕傗娤嶡偐傜摼傜傟偨寢壥傪丄暥帤婲偙偟偟偨敪尵榐丄廂廤偟偨僥僉僗僩側偳丄暥復壔偝傟偨僨乕僞偲偟偰梡堄偡傞丅
偙偙偱堦扷慡懱偺暥復偺撉傒崬傒嶌嬈偼峴偭偰偍偔丅
亂2.僗儔僀僔儞僌亃/愗曅壔
師偺丄偦偺嵦廤偟偨暥復傪丄僶儔僶儔偵愗傝崗傓丅
偙偙偱偼丄忋偱棟夝垽偟偨暥柆傪幪徾偟丄媞娤揑側帇揰偐傜峴偆偺偑摿挜揑偱偁傞丅
亂3.僆乕僾儞丒僐乕僨傿儞僌亃 Open coding
僗儔僀僔儞僌偟偨屻偺暥復偺丄奺晹暘偺傒傪撉傒(偙偙偱傕暥柆偼峫偊偐傜堦扷幪偰傞)丄撪梕傪揔愗偵昞尰偡傞娙寜側乹儔儀儖乺傪偮偗傞丅
師偵丄帡偨儔儀儖摨巑傪廤傔偰傑偲傔偁偘丄儔儀儖偺忋埵奣擮偲側傞乹僇僥僑儕乕乺柤傪偮偗偰偄偔丅
亂4.傾僋僔儍儖丒僐乕僨傿儞僌亃 Axial coding/幉懌僐乕僨傿儞僌
僆乕僾儞丒僐乕僨傿儞僌偱偮偗偨乹僇僥僑儕乕乺偲暋悢偺乹僒僽僇僥僑儕乕乺傪娭楢偯偗偰丄偁傞愢柧偟偨偄幮夛尰徾傪昞尰偟偰偄偔丅
僒僽僇僥僑儕乕偲偼尰徾偵偮偄偰丄偄偮丄偳偙偱丄偳傫側傆偆偵丄側偤側偳偺5W1H傪愢柧偡傞傕偺偱偁傞丅
亂5.僙儗僋僥傿僽丒僐乕僨傿儞僌亃 Selective coding
傾僋僔儍儖丒僐乕僨傿儞僌偱偮偔偭偨尰徾傪廤傔丄僇僥僑儕乕摨巑傪娭學偯偗丄尰徾偺峔憿偲僾儘僙僗傪攃埇偡傞(僇僥僑儕乕摨巑偺庽宍恾偺傛偆側傕偺傪憐憸偟偰傕傜偊偽偄偄丅)偦偟偰丄偦偆偟偰偁偒傜偐偵側偭偨尰徾摨巑傪偲傝傑偲傔丄懳徾偲側偭偨幮夛尰徾慡懱傪愢柧偡傞乹棟榑乺偵側傞丅
儔儀儖偲僇僥僑儕乕晅偗偺嬶懱椺偲偟偰偼丄師偺傕偺傪嫇偘偰偍偙偆丅
亂儔儀儖偲僇僥僑儕乕晅偗偺嶲峫椺亃(滣栘2006, 76偺恾偐傜嶌惉)
GTA偺嶌嬈偼丄僨乕僞偐傜儔儀儖丄儔儀儖偐傜僇僥僑儕乕丄偦偟偰僇僥僑儕乕傪慻傒崌傢偣偨棟榑丄偲彊乆偵拪徾搙傪偁偘偰偄偔丅(偪側傒偵偙偆偟偨嶌嬈傪僒億乕僩偡傞傕偺偲偟偰丄乽ATLAS.ti乿丄乽NVIVO乿丄乽MAXQDA乿丄側偳偺幙揑尋媶梡僜僼僩僂僃傾傕懚嵼偡傞丅偛娭怱偁傞曽偼専嶕偟偰傒傟偽偡偖偵岞幃儁乕僕偑僸僢僩偡傞偺偱偛嶲徠偄偨偩偒偨偄丅)
偞偭偲偟偨愢柧偵側偭偰偟傑偭偨偑丄GTA偼庡偵忋偺傛偆側棳傟偱僐乕僨傿儞僌嶌嬈傪恑傔偰偄偒(慄揑偵恑傫偱偄偔偲偄偆傛傝傕丄偦傟偧傟偺嶌嬈抜奒傪峴偭偨傝棃偨傝偡傞)帪偵偼偦偆偟偰傾僂僩僾僢僩偟偨棟榑傪傕偭偰嵞搙僒儞僾儕儞僌傪峴偄丄忋偺傛偆側嶌嬈傪孞傝曉偟偰偄偔丅偦偟偰丄嵟廔揑偵栚巜偝傟傞偺偼丄偙傟埲忋偺僇僥僑儕乕偺敪尒傕側偔丄僇僥僑儕乕娫娭學偺敪尒傕側偔丄怴偨側忣曬偺敪尒傕側偄偲偄偆乽棟榑揑朞榓乿偺忬懺偲偝傟傞丅
仭偟偐偔摟柧壔偝傟偨柤恖寍乗儅乕働僥傿儞僌丒儕僒乕僠傊偺GTA偺墳梡偵傓偗偰
儅乕働僥傿儞僌丒儕僒乕僠偵偍偄偰偼丄忋偺乽棟榑揑朞榓乿忬懺傑偱払偡傞傑偱偺僒儞僾儕儞僌偺孞傝曉偟偵偮偄偰偼揔梡偑擄偟偄偐傕偟傟側偄丅偟偐偟丄乽柤恖寍乿偑寬嵼偱偁傞儅乕働僥傿儞僌丒儕僒乕僠偺幙揑挷嵏偵偍偄偰傕丄GTA偼堦偮偺壜擻惈傪姶偠偝偣傞傕偺偩丅偲偔偵丄嬤擭偺僜乕僔儍儖丒儕僗僯儞僌暘愅偺帪棳偵偺偭偰丄乽暥復壔偝傟偨僨乕僞乿帺懱偼偦傟偙偦戝検(價僢僌偵)懚嵼偡傞(仸(拲婰)4)丅
傕偪傠傫丄GTA傪帺壠栻饽拞偺暔偲偡傞偵偼丄昅幰偵偼憐憸傕偱偒側偄傎偳偺懡偔偺孭楙偺愊傒廳偹傪梫偡傞偩傠偆丅傑偨丄GTA傪巊偊偽丄堘偆恖偑傗偭偰傕摨偠傾僂僩僾僢僩偑偱傞傢偗偱傕側偄丅僗僩儔僂僗傜偼丄乽桳梡側僨乕僞懳榖宆傪嶻傒弌偡偨傔偵乹揤嵥乺側偳昁梫側偄(Glaser BG, Strauss A, 1967=1996, 14)乿偲尵偆偑丄偦偺堄枴偱丄GTA傪嬱巊偟偨暘愅偑偱偒傞偙偲帺懱傕乽柤恖寍乿偱偼偁傞丅
偟偐偟丄乽摟柧壔偝傟偨柤恖寍乿偲丄乽晄摟柧側柤恖寍乿偲偄偆堘偄傪晭偭偰側傜側偄丅
偦傟偼偨偲偊傞側傜丄乽栚偺慜偺墌偺柺愊傪媮傔側偝偄乿偲偺栤偄偵擸傓巕偳傕偵懳偟偰丄乽偲偵偐偔3.14傪巊偄側偝偄乿偲巜帵偡傞偺偲丄乽墌廃棪偺嬤帡抣偲偟偰偺3.14傪偐偗側偝偄乿偲巜帵偡傞偺偲偱丄慡偔堄枴崌偄偑堎側偭偰偔傞偙偲偲摨偠偱偁傞丅乽栚偺慜偺墌乿偵懳偟偰偼摨偠摎偊偑摫偐傟傞偩傠偆丅偟偐偟偦偺堘偄偼丄乽師偺墌乿丄傑偨乽偦偺師偺墌乿偵弌夛偭偨帪偺巕偳傕偺惉愌偵尰傟偰偔傞偼偢偩丅
乽GTA偵傛傞暘愅乿偲暦偔偩偗偱堦掕偺掕幃壔偝傟偨(偦偟偰偁傞掱搙僩儗乕僯儞僌偝傟偨)暘愅庤朄傪梡偄偨偙偲傊偺嫟捠棟夝偑扴曐偝傟傞偺偱偁傟偽丄偦傟偼幙揑挷嵏偺嫟桳帒嶻壔丒僫儗僢僕壔偵偼戝偒偔帒偡傞偼偢偩丅偦偺堄枴偱傕丄GTA帺懱偑摨偠尵梩偱條乆偵掕幃壔偝傟偰偟傑偭偰偄傞偺偼栧奜娍偲偟偰傕旕忢偵巆擮側偙偲偱偁傞偟崱屻偺戝偒側壽戣偲偟偰巆偝傟偰偄傞(仸(拲婰)3)丅
幮夛挷嵏偲儅乕働僥傿儞僌丒儕僒乕僠偼丄傎偲傫偳帡偨傛偆側偙偲傪偟偰偄傞応崌偑懡偄偵傕娭傢傜偢丄撪揑僐儈儏僯働乕僔儑儞偲偟偰偼堦庬偺抐愨忬懺偵偁傞丅傑偨丄偦偺抐愨偼丄儅乕働僥傿儞僌懁偺儘僕僢僋偑僐僗僩偲僗僺乕僪偑撈帺偺榑棟偱捛偄媮傔偰偄偔拞偱丄奼戝偟偰偄偭偰偄傞傛偆偩丅偦偺娫寗傪偮側偖壦偗嫶堦偮偺偲偟偰偺GTA偺徯夘傪帩偭偰丄崱夞偺幮夛妛偺偡乀傔偲偟偨偄丅
亂庡側嶲峫暥專亃
僶乕僯乕丒G. 僌儗僀僓乕丄傾儞僙儖儉丒L. 僗僩儔僂僗, 1967=1996 亀僨乕僞懳榖宆棟榑偺敪尒乗挷嵏偐傜偄偐偵棟榑傪偆傒偩偡偐亁 怴梛幮
滣栘僋儗僀僌丒僸儖帬巕, 2006 亀儚乕僪儅僢僾 僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠亁 怴梛幮
亂媟拲亃
仸(拲婰)1 偟偐偟偦傟偼検揑挷嵏偺僗僉儖妉摼偑堈偟偄偲偐娙扨偲偄偆堄枴偱偼側偄丅偦偙偱偼奺僗僉儖偺寢愡揰丄栚昗偑幙揑挷嵏偲偔傜傋柧帵偝傟傗偡偄偲偄偆堄枴偱偁傞丅
仸(拲婰)2 GTA偺懠偵幙揑暘愅偺掕幃壔偺帋傒偲偟偰偼丄SCAT(Steps for Coding and Theorization)偑斾妑揑抦傜傟偰偄傞丅
仸(拲婰)3 GTA偼丄敪憐偝傟偨摉弶偐傜僌儗僀僓乕偲僗僩儔僂僗偺娫偱庤朄偵偮偄偰偺堄尒偑堎側偭偰偄偨丅擔杮偱偼丄栘壓偵傛傞M-GTA(廋惓斉僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠)傕惗傑傟偰偄傞丅偙偙偱偼奺僶乕僕儑儞傪斾妑専摙偡傞偺偑栚揑偱偼側偄偨傔丄庡偵僗僩儔僂僗棳偺曽朄榑傪昗弨揑丒堦斒揑側傕偺偲傒側偟偰愢柧偡傞丅椺偊偽屻弎偺乽僨乕僞偺僗儔僀僔儞僌/愗曅壔乿偺僾儘僙僗偼栘壓斉GTA偵偼懚嵼偟側偄丅
仸(拲婰)4 尰忬偺僆乕僾儞側僜乕僔儍儖丒儕僗僯儞僌暘愅偱偼丄庡偵僽儘僌丄SNS忋偺戝検偺暥復丄尵梩丄偮傇傗偒傪廤傔僥僉僗僩儅僀僯儞僌僣乕儖傪梡偄傞偺偑堦斒揑偩偑丄昿弌扨岅偺婡夿揑側儔儞僉儞僌傗學傝庴偗暘愅偩偗偱偼丄検揑側攃埇偼偱偒偰傕幙揑側抦尒偺棟榑壔偼側偐側偐擄偟偄丅偙偙傊偺GTA偺僐乕僨傿儞僌偺墳梡偼僠儍儗儞僕儞僌偩偑怴偨側揥奐傪婜懸偝偣傞傕偺偑偁傞丅
婇夋晹 傾僔僗僞儞僩丒僨傿儗僋僞乕 彫椦桽帣
幙揑挷嵏偼丄検揑挷嵏偵偔傜傋丄僗僉儖偑懏恖揑偱丄儅僯儏傾儖壔偑擄偟偔丄抦尒偺嫟桳偑擄偟偄丄偲偝傟傞偙偲偑懡偄丅偙偺偙偲偼丄晛抜壗傜偐偺幙揑挷嵏傪峴偭偰偄傞曽偵偲偭偰偼幚姶偡傞偙偲傕懡偄偺偱偼側偄偩傠偆偐丅
偦偺乽柤恖寍乿惈偼丄戝偒偔2偮丄乽僨乕僞偺庢摼乿偲乽僨乕僞偺暘愅乿偺2僼僃乕僘偱庡偵尰傟偰偔傞丅
亂僨乕僞偺暘愅亃 偦偆偟偰傕偨傜偝傟偨婰榐丄僼傿乕儖僪僲乕僩丄僀儞僞價儏乕敪尵榐側偳偺僨乕僞偐傜丄偲傝曽傑偱丄揔愗側僨乕僞傪偳偺傛偆偵庢摼丒廂廤偡傞偐
挷嵏壽戣偵懳偟偰偳偺傛偆側峫嶡傪巤偟丄偳偺傛偆側寢榑傪摫偒弌偡偐
GTA丄擔杮岅偱偼僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠偲偦偺傑傑昞婰偡傞偙偲偑懡偄丅娕岇丒堛椕側偳偺椪彴堛妛宯偺暘栰偱偼堦掕偺晛媦傪尒偣偰偄傞幙揑挷嵏偺暘愅庤朄偱偁傞偑丄儅乕働僥傿儞僌丒儕僒乕僠偺暘栰偱偼偁傑傝巊傢傟偰偄側偄偟丄傎偲傫偳抦傜傟偰偄側偄偺偑尰忬偱偁傞(Web暘愅偺暘栰偱偼堦晹偱帋傒傜傟偰偄傞傛偆偩)(仸(拲婰)2)丅偪側傒偵丄滣栘(2006)偵傛傞偲丄2000擭偐傜2005擭偺5擭娫偱丄幙揑挷嵏傪峴偭偨娕岇宯榑暥偺9.3%偱GTA偑梡偄傜傟偰偄傞丅
{kind=link}
敪埬偼1960擭戜丄暷幮夛妛幰偺僶乕僯乕丒僌儗僀僓乕偲傾儞僙儖儉丒僗僩儔僂僗偵傛偭偰側偝傟偨(忋偺夋憸偼擇恖偑嵟弶偵徯夘偟偨挊彂 "The Discovery of Grounded Theory"偺朚栿丅偙偙偱偼乽僨乕僞懳榖宆棟榑乿偲栿偝傟偰偄傞)丅
壖憐偺斾妑懳徾偲暘愅寢壥傪斾妑偡傞乽棟榑揑斾妑乿偺曽朄榑傗丄摼傜傟偨寢壥傪妶偐偟側偑傜嵞搙僒儞僾儕儞僌傪峴偆乽棟榑揑僒儞僾儕儞僌乿側偳丄GTA偑廳帇偡傞挷嵏嶌嬈忋偺摿挜偼懡偔偁傞丅
偟偐偟丄儅乕働僥傿儞僌丒儕僒乕僠偵墳梡傪峫偊傞偲偡傟偽丄偍偦傜偔偦偺嵟戝偺摿挜偼幙揑僨乕僞暘愅嵺偺乽僐乕僨傿儞僌乿傪掕幃壔偟偨偙偲偵偁傞丅
{kind=link}
傑偢丄暘愅嶌嬈偺慜抜奒偲偟偰丄
亂1.暥復壔丒僨乕僞壔丒撉傒崬傒亃
僀儞僞價儏乕傗娤嶡偐傜摼傜傟偨寢壥傪丄暥帤婲偙偟偟偨敪尵榐丄廂廤偟偨僥僉僗僩側偳丄暥復壔偝傟偨僨乕僞偲偟偰梡堄偡傞丅
偙偙偱堦扷慡懱偺暥復偺撉傒崬傒嶌嬈偼峴偭偰偍偔丅
亂2.僗儔僀僔儞僌亃/愗曅壔
師偺丄偦偺嵦廤偟偨暥復傪丄僶儔僶儔偵愗傝崗傓丅
偙偙偱偼丄忋偱棟夝垽偟偨暥柆傪幪徾偟丄媞娤揑側帇揰偐傜峴偆偺偑摿挜揑偱偁傞丅
僗儔僀僔儞僌偟偨屻偺暥復偺丄奺晹暘偺傒傪撉傒(偙偙偱傕暥柆偼峫偊偐傜堦扷幪偰傞)丄撪梕傪揔愗偵昞尰偡傞娙寜側乹儔儀儖乺傪偮偗傞丅
師偵丄帡偨儔儀儖摨巑傪廤傔偰傑偲傔偁偘丄儔儀儖偺忋埵奣擮偲側傞乹僇僥僑儕乕乺柤傪偮偗偰偄偔丅
僆乕僾儞丒僐乕僨傿儞僌偱偮偗偨乹僇僥僑儕乕乺偲暋悢偺乹僒僽僇僥僑儕乕乺傪娭楢偯偗偰丄偁傞愢柧偟偨偄幮夛尰徾傪昞尰偟偰偄偔丅
僒僽僇僥僑儕乕偲偼尰徾偵偮偄偰丄偄偮丄偳偙偱丄偳傫側傆偆偵丄側偤側偳偺5W1H傪愢柧偡傞傕偺偱偁傞丅
傾僋僔儍儖丒僐乕僨傿儞僌偱偮偔偭偨尰徾傪廤傔丄僇僥僑儕乕摨巑傪娭學偯偗丄尰徾偺峔憿偲僾儘僙僗傪攃埇偡傞(僇僥僑儕乕摨巑偺庽宍恾偺傛偆側傕偺傪憐憸偟偰傕傜偊偽偄偄丅)偦偟偰丄偦偆偟偰偁偒傜偐偵側偭偨尰徾摨巑傪偲傝傑偲傔丄懳徾偲側偭偨幮夛尰徾慡懱傪愢柧偡傞乹棟榑乺偵側傞丅
亂儔儀儖偲僇僥僑儕乕晅偗偺嶲峫椺亃(滣栘2006, 76偺恾偐傜嶌惉)
{kind=link}
儅乕働僥傿儞僌丒儕僒乕僠偵偍偄偰偼丄忋偺乽棟榑揑朞榓乿忬懺傑偱払偡傞傑偱偺僒儞僾儕儞僌偺孞傝曉偟偵偮偄偰偼揔梡偑擄偟偄偐傕偟傟側偄丅偟偐偟丄乽柤恖寍乿偑寬嵼偱偁傞儅乕働僥傿儞僌丒儕僒乕僠偺幙揑挷嵏偵偍偄偰傕丄GTA偼堦偮偺壜擻惈傪姶偠偝偣傞傕偺偩丅偲偔偵丄嬤擭偺僜乕僔儍儖丒儕僗僯儞僌暘愅偺帪棳偵偺偭偰丄乽暥復壔偝傟偨僨乕僞乿帺懱偼偦傟偙偦戝検(價僢僌偵)懚嵼偡傞(仸(拲婰)4)丅
偦傟偼偨偲偊傞側傜丄乽栚偺慜偺墌偺柺愊傪媮傔側偝偄乿偲偺栤偄偵擸傓巕偳傕偵懳偟偰丄乽偲偵偐偔3.14傪巊偄側偝偄乿偲巜帵偡傞偺偲丄乽墌廃棪偺嬤帡抣偲偟偰偺3.14傪偐偗側偝偄乿偲巜帵偡傞偺偲偱丄慡偔堄枴崌偄偑堎側偭偰偔傞偙偲偲摨偠偱偁傞丅乽栚偺慜偺墌乿偵懳偟偰偼摨偠摎偊偑摫偐傟傞偩傠偆丅偟偐偟偦偺堘偄偼丄乽師偺墌乿丄傑偨乽偦偺師偺墌乿偵弌夛偭偨帪偺巕偳傕偺惉愌偵尰傟偰偔傞偼偢偩丅
亂庡側嶲峫暥專亃
僶乕僯乕丒G. 僌儗僀僓乕丄傾儞僙儖儉丒L. 僗僩儔僂僗, 1967=1996 亀僨乕僞懳榖宆棟榑偺敪尒乗挷嵏偐傜偄偐偵棟榑傪偆傒偩偡偐亁 怴梛幮
滣栘僋儗僀僌丒僸儖帬巕, 2006 亀儚乕僪儅僢僾 僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠亁 怴梛幮
仸(拲婰)1 偟偐偟偦傟偼検揑挷嵏偺僗僉儖妉摼偑堈偟偄偲偐娙扨偲偄偆堄枴偱偼側偄丅偦偙偱偼奺僗僉儖偺寢愡揰丄栚昗偑幙揑挷嵏偲偔傜傋柧帵偝傟傗偡偄偲偄偆堄枴偱偁傞丅
仸(拲婰)2 GTA偺懠偵幙揑暘愅偺掕幃壔偺帋傒偲偟偰偼丄SCAT(Steps for Coding and Theorization)偑斾妑揑抦傜傟偰偄傞丅
仸(拲婰)3 GTA偼丄敪憐偝傟偨摉弶偐傜僌儗僀僓乕偲僗僩儔僂僗偺娫偱庤朄偵偮偄偰偺堄尒偑堎側偭偰偄偨丅擔杮偱偼丄栘壓偵傛傞M-GTA(廋惓斉僌儔僂儞僨僢僪丒僙僆儕乕丒傾僾儘乕僠)傕惗傑傟偰偄傞丅偙偙偱偼奺僶乕僕儑儞傪斾妑専摙偡傞偺偑栚揑偱偼側偄偨傔丄庡偵僗僩儔僂僗棳偺曽朄榑傪昗弨揑丒堦斒揑側傕偺偲傒側偟偰愢柧偡傞丅椺偊偽屻弎偺乽僨乕僞偺僗儔僀僔儞僌/愗曅壔乿偺僾儘僙僗偼栘壓斉GTA偵偼懚嵼偟側偄丅
仸(拲婰)4 尰忬偺僆乕僾儞側僜乕僔儍儖丒儕僗僯儞僌暘愅偱偼丄庡偵僽儘僌丄SNS忋偺戝検偺暥復丄尵梩丄偮傇傗偒傪廤傔僥僉僗僩儅僀僯儞僌僣乕儖傪梡偄傞偺偑堦斒揑偩偑丄昿弌扨岅偺婡夿揑側儔儞僉儞僌傗學傝庴偗暘愅偩偗偱偼丄検揑側攃埇偼偱偒偰傕幙揑側抦尒偺棟榑壔偼側偐側偐擄偟偄丅偙偙傊偺GTA偺僐乕僨傿儞僌偺墳梡偼僠儍儗儞僕儞僌偩偑怴偨側揥奐傪婜懸偝偣傞傕偺偑偁傞丅