儀僀僘摑寁偭偰側偵? 戞5夞 乽儀僀僘傪棟夝偡傞偨傔偺擄強乿
2011擭02寧18擔
僞僌:忋揷杚恖 儀僀僘摑寁 MCMC朄
姅幃夛幮僕儍僷儞丒儅乕働僥傿儞僌丒僄乕僕僃儞僔乕
婇夋晹 戝嶃帠柋強 儅僱乕僕儍乕 忋揷 杚恖
儀僀僘偺擄強
儀僀僘偺掕棟偼亀帠屻妋棪佸栟搙(備偆偳)×帠慜妋棪亁偲偄偆僔儞僾儖側宍偱帵偝傟傑偟偨丅
儀僀僘偺墳梡斖埻偑偲偰傕峀偔丄懡婒偵傢偨偭偰婛偵棙梡偝傟偰偄傞偙偲傕暘偐傝傑偟偨丅儀僀僘偺擄偟偝偼丄偦偺娫傪寢傇庤懕偒偑斚嶨側揰偵偁傝傑偡丅
悽偺拞偵儀僀僘摑寁偺擖栧彂偑悢懡偔弌偰偄傑偡偑丄弶妛幰偑彂愋偩偗偱儀僀僘傪棟夝偡傞偺偼懡擄偱偡丅崱夞偼丄儀僀僘悇應偵昁梫側庤懕偒傪偍偍傑偐偵岎捠惍棟偟偰傒偨偄偲巚偄傑偡丅
栟搙娭悢偺寛掕
栟搙偼丄娤應抣偑摼傜傟偨偲偒偵丄曣悢兤(僔乕僞)偺傕偲偱偦偺娤應抣偑弌尰偡傞妋棪偱偡丅兤偑屌掕偝傟偰偄傟偽1屄偺抣偵側傝傑偡偑丄曣悢兤偼枹抦側偺偱丄兤傪曄検偲偟偨娭悢偲偟偰埖偄傑偡丅
椺偊偽丄帋尡栤戣偱10恖偺偆偪4恖惓夝偩偭偨応崌丄栟搙偼10C4兤4(1-兤)6.jpg偺擇崁暘晍偵側傞丄偲偄偭偨嬶崌偱偡丅
擇崁暘晍偑椙偄偺偐丄惓婯暘晍偵偡傋偒偐丄億傾僜儞暘晍傪巊偆偐摍偺敾抐偼丄娤應抣偑敪惗偡傞巇慻傒傪敾抐偟偰偁側偨偑寛傔側偗傟偽側傝傑偣傫丅暋悢偺梫場偵嵍塃偝傟傞応崌偼丄夞婣儌僨儖傗僾儘價僢僩儌僨儖丄儘僕僢僩儌僨儖側偳崅搙側娭悢偺揔梡傕昁梫偵側傞偐傕偟傟傑偣傫丅偙偆偟偨亂摑寁儌僨儖亃偺慖戰偑埾偹傜傟傞嶌嬈偺傂偲偮偵側傝傑偡丅
帠慜暘晍偺寛掕
帠慜偵壗傕忣曬偑側偄偲偒偼丄偁傞斖埻撪偱兤偺偳偺妋棪傕摍偟偄偲偡傞乽嬊強堦條帠慜暘晍乿偑悇彠偝傟偰偒傑偟偨丅偟偐偟偦傟偱偼弉楙幰偺亀埫栙抦亁偵摓掙偐側傢側偄偺偱丄嵟嬤偱偼夁嫀偺娤應僨乕僞傪惗偐偡偙偲偑懡偔側傝傑偟偨丅亀埫栙抦亁傪亀宍幃抦亁偵抲偒姺偊傛偆偲偄偆傢偗偱偡丅
宱尡儀僀僘朄(EB)偲屇偽傟丄夁嫀偺娤應僨乕僞傪峔憿壔偟偰偦偺傑傑巊偆応崌偲丄僴僀僷乕僷儔儊乕僞乕傪愝掕偟偰奒憌儀僀僘朄偵帩偪崬傓応崌偲偑偁傝傑偡丅
(仸(拲婰)奒憌儀僀僘朄偵偮偄偰偼暿搑僩僺僢僋偲偟偰怗傟傞梊掕偱偡)
帠慜妋棪偵傕暘晍偺宍傪愝掕偡傞偙偲偑昁梫偱偡丅偦偺嵺丄栟搙娭悢偲憡惈偺椙偄儌僨儖傪慖傇偙偲偑偱偒傟偽岾塣偱偡丅壓庤側寛傔曽傪偡傞偲丄帠屻暘晍偑暋嶨側宍偵側偭偰丄偪傚偭偲嬯楯偡傞偙偲偵側傝傑偡丅
壓婰偺傛偆側慻傒崌傢偣傪亂帺慠嫟栶帠慜暘晍亃偲尵偄丄帠屻暘晍偲帠慜暘晍偑摨偠僞僀僾偵側傞丄憡惈偺椙偄偲偄偆偺偼偦偆偄偆堄枴偱偡丅
暘晍偺宍.gif
帠屻暘晍偺昡壙
儀僀僘悇應偱摼傜傟傞寢壥偼丄帠屻暘晍偺慡懱偱偡丅偦偙偐傜昁梫偵墳偠偰婜懸抣(=暯嬒)傗儌乕僪(嵟昿抣)側偳偺戙昞抣偱婰弎偝傟偨傝丄嬶懱揑側梊應抣偺桪楎偑斾妑偝傟偨傝偟傑偡丅
亂帺慠嫟栶帠慜暘晍亃偱偁傟偽夝愅揑偵摎偊傪弌偡偙偲偑偱偒傑偡丅1990擭戙傑偱偺擖栧彂偱偼丄偦偺偁偨傝偺夝愅庤弴偺愢柧偑庡偱偟偨丅偦偺峔憿偼崱偱傕桳岠偱偡偑丄堦曽偱嶐崱偱偼亂帺慠嫟栶帠慜暘晍亃偺敍傝傪挻偊偨丄傛傝帺桼側儌僨儕儞僌偑側偝傟傞傛偆偵側偭偰偒偰偄傑偡丅
帺桼側儌僨儕儞僌傪峴偭偨応崌崲傞偺偼丄帠屻暘晍偺峔憿偑暋嶨偵側傞偙偲偱偡丅帠屻暘晍傪昡壙偡傞偨傔偵偼愊暘偲傛偽傟傞張棟偑昁梫偵側傝傑偡偑丄寁嶼偑傢偢傜傢偟偐偭偨傝丄夝偗側偄働乕僗偑弌偰偒偨傝傕偟傑偡丅
偦偙偱偙偆偟偨栤戣傪夝寛偡傞偨傔偵搊応偟偨偺偑亂MCMC朄亃(儅儖僐僼僠僃乕儞丒儌儞僥僇儖儘朄)偱偡丅
儌儞僥僇儖儘朄偼丄梌偊傜傟偨娭悢傪嵞尰偡傞傛偆偵僒儞僾儕儞僌枾搙傪挷惍偟側偑傜懡悢偺僒儞僾儖傪拪弌偡傞媄朄偱偡丅偙傟傪巊偊偽帠屻暘晍偺婜懸抣(=暯嬒)傪僒儞僾儖偺扨弮暯嬒偱嬤帡偡傞偙偲偑偱偒傑偡丅
儅儖僐僼僠僃乕儞偼丄儔儞僟儉僂僅乕僋(悓偭暐偄偺愮捁懌)傪堦斒壔偟偨妋棪夁掱偱偡丅尰嵼偺抧揰傪婎弨偵偟偰師偺堦曕偑儔儞僟儉偵寛傑傞曕偒曽偵側傝傑偡丅
亂MCMC朄亃偼椉幰傪庢傝擖傟丄暋嶨側帠屻暘晍偵懳偟偰傕暘愅壜擻偵偟傑偡丅MCMC朄偼丄帺慠嫟栶帠慜暘晍偑壖掕偱偒傞儌僨儖偺応崌偼僊僽僗朄偲屇偽傟傞斾妑揑岠棪揑側傾儖僑儕僘儉傪丄偦傟偑壖掕偱偒側偄堦斒揑側応崌偼儊僩儘億儕僗亅傊乕僗僥傿儞僌朄偲傛偽傟傞枩擻側庤朄傪梡偄傑偡丅
幚柋偵岦偗偰
MCMC朄偵傛偭偰儀僀僘偼暘愅偺奯崻偑庢傝暐傢傟丄偝傑偞傑側栤戣偵廮擃偵懳墳偱偒傞傛偆偵側傝傑偟偨丅
偟偐偟丄偄偐偵儀僀僘夝愅偺偨傔偺僜僼僩僂僃傾偑惍偄偮偮偁傞偲偼尵偊丄暘愅嶌嬈偦偺傕偺偼戝曄偱偡丅
僷儔儊乕僞悢偑偦傟傎偳懡偔側偗傟偽丄夁嫀偵側偝傟偨尋媶偺惉壥傪梡偄傞偙偲偵傛偭偰丄斾妑揑娙扨偵儌僨儖偺悇掕偑峴偊傑偡丅(仸(拲婰)偨偩丄崱擔揑偵偼偦傟偩偗偱偼傛傝怺偄抦尒傪摼傞偙偲偵尷奅偑偁傞偺傕帠幚偱偡偑...)
師夞偼丄偦偺娙扨側曽偵増偭偰丄EXCEL偺庤寁嶼儗儀儖偱儀僀僘傪巊偭偰偄偔偙偲偼偱偒側偄偐丄偲偄偆偙偲傪峫偊偰傒偨偄偲巚偄傑偡丅
MCMC朄偵偮偄偰偺曗懌
恎撪偐傜乽MCMC朄偵偮偄偰傕偭偲愢柧傪乿偲偄偆惡偑偁傝傑偟偨偺偱丄彮偟偩偗丅
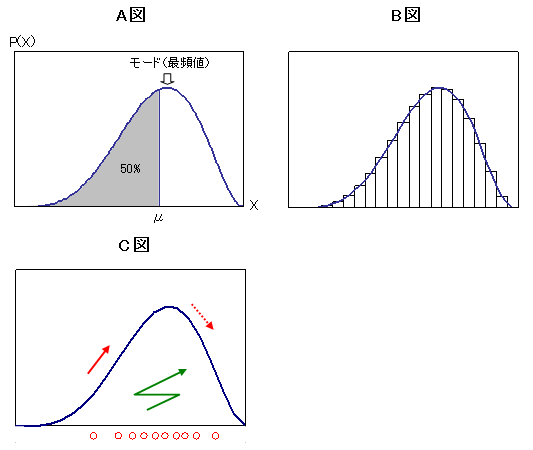
帠屻妋棪暘晍偑壓偺A恾偺傛偆偵梌偊傜傟偨偲偟傑偡丅儌乕僪(嵟昿抣)偼嶳偺偰偭傌傫偲偄偆偙偲偱暘偐傝傑偡偑丄暯嬒抣傗擟堄偺X偺妋棪傪弌偡偵偼丄愊暘偱柺愊寁嶼偟側偗傟偽側傝傑偣傫丅偙傟丄偗偭偙偆戝曄側傫偱偡偹丅
B恾偺傛偆偵丄抁嶜偵暘偗傞偲扨弮偵懌偟嶼偱嬤帡偡傞偙偲偑偱偒傑偡丅(嬫暘媮愊朄)
儔儞僟儉偵X偺僒儞僾儖傪偨偔偝傫拪弌偟偰傕丄懌偟嶼偵抲偒姺偊傞偙偲偑偱偒傑偡丅(儌儞僥僇儖儘朄)
偦傟偱傕僷儔儊乕僞乕偺悢(師尦偺悢)偑懡偔側偭偰偔傞偲丄寁嶼検偑朿戝側傕偺偵側偭偰偒傑偡丅
MCMC朄偼丄儌儞僥僇儖儘朄傪岠棪揑偵峴偆偨傔偺庤朄偱偡丅擟堄偺僗僞乕僩抧揰傪寛傔丄儖乕儖偵偺偭偲偭偰曕偒夞傝僒儞僾儖傪廤傔偰偙傛偆偲偄偆傢偗偱偡丅
C恾丄椢怓偺慄偺傛偆偵丄曽岦傪掕傔偰(1曄検偢偮拝栚偟偰)僕僌僓僌偵曕偙偆偲偄偆偺偑僊僽僗朄偱偡丅
愒怓偱帵偟傑偟偨偑丄忋傞偲偒偼昁偢恑傒丄壓傞偲偒偼棊嵎偵墳偠偰妋棪揑偵棫偪巭傑傞偙偲偵偡傟偽丄崅偄強傎偳枾側僒儞僾儕儞僌偑偱偒傞偩傠偆丄偲偄偆偺偑儊僩儘億儕僗亅傊乕僗僥傿儞僌朄偱偡丅
MCMC朄偺愢柧.gif
偟偐偟丄偙偆偟偨傾儖僑儕僘儉偵娭偡傞抦幆偼丄幚柋偵偼偁傑傝娭學偟偰偙側偄偲巚偄傑偡丅
尰帪揰偱偼R偐WinBUGS偔傜偄偟偐僣乕儖偑偁傝傑偣傫偑丄偄偢傟惍偆偩傠偆斈梡揑側僜僼僩僂僃傾偵丄偙偺偁偨傝偼擟偣偰偍偗偽偄偄偙偲偱偟傚偆丅
儀僀僘摑寁偭偰側偵?偺傎偐偺婰帠傪撉傓
姅幃夛幮僕儍僷儞丒儅乕働僥傿儞僌丒僄乕僕僃儞僔乕
婇夋晹 戝嶃帠柋強 儅僱乕僕儍乕 忋揷 杚恖
婇夋晹 戝嶃帠柋強 儅僱乕僕儍乕 忋揷 杚恖
儀僀僘偺擄強
儀僀僘偺掕棟偼亀帠屻妋棪佸栟搙(備偆偳)×帠慜妋棪亁偲偄偆僔儞僾儖側宍偱帵偝傟傑偟偨丅
儀僀僘偺墳梡斖埻偑偲偰傕峀偔丄懡婒偵傢偨偭偰婛偵棙梡偝傟偰偄傞偙偲傕暘偐傝傑偟偨丅儀僀僘偺擄偟偝偼丄偦偺娫傪寢傇庤懕偒偑斚嶨側揰偵偁傝傑偡丅
悽偺拞偵儀僀僘摑寁偺擖栧彂偑悢懡偔弌偰偄傑偡偑丄弶妛幰偑彂愋偩偗偱儀僀僘傪棟夝偡傞偺偼懡擄偱偡丅崱夞偼丄儀僀僘悇應偵昁梫側庤懕偒傪偍偍傑偐偵岎捠惍棟偟偰傒偨偄偲巚偄傑偡丅
栟搙娭悢偺寛掕
栟搙偼丄娤應抣偑摼傜傟偨偲偒偵丄曣悢兤(僔乕僞)偺傕偲偱偦偺娤應抣偑弌尰偡傞妋棪偱偡丅兤偑屌掕偝傟偰偄傟偽1屄偺抣偵側傝傑偡偑丄曣悢兤偼枹抦側偺偱丄兤傪曄検偲偟偨娭悢偲偟偰埖偄傑偡丅
椺偊偽丄帋尡栤戣偱10恖偺偆偪4恖惓夝偩偭偨応崌丄栟搙偼10C4兤4(1-兤)6.jpg偺擇崁暘晍偵側傞丄偲偄偭偨嬶崌偱偡丅
{kind=link}
擇崁暘晍偑椙偄偺偐丄惓婯暘晍偵偡傋偒偐丄億傾僜儞暘晍傪巊偆偐摍偺敾抐偼丄娤應抣偑敪惗偡傞巇慻傒傪敾抐偟偰偁側偨偑寛傔側偗傟偽側傝傑偣傫丅暋悢偺梫場偵嵍塃偝傟傞応崌偼丄夞婣儌僨儖傗僾儘價僢僩儌僨儖丄儘僕僢僩儌僨儖側偳崅搙側娭悢偺揔梡傕昁梫偵側傞偐傕偟傟傑偣傫丅偙偆偟偨亂摑寁儌僨儖亃偺慖戰偑埾偹傜傟傞嶌嬈偺傂偲偮偵側傝傑偡丅
帠慜暘晍偺寛掕
帠慜偵壗傕忣曬偑側偄偲偒偼丄偁傞斖埻撪偱兤偺偳偺妋棪傕摍偟偄偲偡傞乽嬊強堦條帠慜暘晍乿偑悇彠偝傟偰偒傑偟偨丅偟偐偟偦傟偱偼弉楙幰偺亀埫栙抦亁偵摓掙偐側傢側偄偺偱丄嵟嬤偱偼夁嫀偺娤應僨乕僞傪惗偐偡偙偲偑懡偔側傝傑偟偨丅亀埫栙抦亁傪亀宍幃抦亁偵抲偒姺偊傛偆偲偄偆傢偗偱偡丅
宱尡儀僀僘朄(EB)偲屇偽傟丄夁嫀偺娤應僨乕僞傪峔憿壔偟偰偦偺傑傑巊偆応崌偲丄僴僀僷乕僷儔儊乕僞乕傪愝掕偟偰奒憌儀僀僘朄偵帩偪崬傓応崌偲偑偁傝傑偡丅
(仸(拲婰)奒憌儀僀僘朄偵偮偄偰偼暿搑僩僺僢僋偲偟偰怗傟傞梊掕偱偡)
帠慜妋棪偵傕暘晍偺宍傪愝掕偡傞偙偲偑昁梫偱偡丅偦偺嵺丄栟搙娭悢偲憡惈偺椙偄儌僨儖傪慖傇偙偲偑偱偒傟偽岾塣偱偡丅壓庤側寛傔曽傪偡傞偲丄帠屻暘晍偑暋嶨側宍偵側偭偰丄偪傚偭偲嬯楯偡傞偙偲偵側傝傑偡丅
壓婰偺傛偆側慻傒崌傢偣傪亂帺慠嫟栶帠慜暘晍亃偲尵偄丄帠屻暘晍偲帠慜暘晍偑摨偠僞僀僾偵側傞丄憡惈偺椙偄偲偄偆偺偼偦偆偄偆堄枴偱偡丅
{kind=link}
暘晍偺宍.gif
帠屻暘晍偺昡壙
儀僀僘悇應偱摼傜傟傞寢壥偼丄帠屻暘晍偺慡懱偱偡丅偦偙偐傜昁梫偵墳偠偰婜懸抣(=暯嬒)傗儌乕僪(嵟昿抣)側偳偺戙昞抣偱婰弎偝傟偨傝丄嬶懱揑側梊應抣偺桪楎偑斾妑偝傟偨傝偟傑偡丅
亂帺慠嫟栶帠慜暘晍亃偱偁傟偽夝愅揑偵摎偊傪弌偡偙偲偑偱偒傑偡丅1990擭戙傑偱偺擖栧彂偱偼丄偦偺偁偨傝偺夝愅庤弴偺愢柧偑庡偱偟偨丅偦偺峔憿偼崱偱傕桳岠偱偡偑丄堦曽偱嶐崱偱偼亂帺慠嫟栶帠慜暘晍亃偺敍傝傪挻偊偨丄傛傝帺桼側儌僨儕儞僌偑側偝傟傞傛偆偵側偭偰偒偰偄傑偡丅
帺桼側儌僨儕儞僌傪峴偭偨応崌崲傞偺偼丄帠屻暘晍偺峔憿偑暋嶨偵側傞偙偲偱偡丅帠屻暘晍傪昡壙偡傞偨傔偵偼愊暘偲傛偽傟傞張棟偑昁梫偵側傝傑偡偑丄寁嶼偑傢偢傜傢偟偐偭偨傝丄夝偗側偄働乕僗偑弌偰偒偨傝傕偟傑偡丅
偦偙偱偙偆偟偨栤戣傪夝寛偡傞偨傔偵搊応偟偨偺偑亂MCMC朄亃(儅儖僐僼僠僃乕儞丒儌儞僥僇儖儘朄)偱偡丅
儌儞僥僇儖儘朄偼丄梌偊傜傟偨娭悢傪嵞尰偡傞傛偆偵僒儞僾儕儞僌枾搙傪挷惍偟側偑傜懡悢偺僒儞僾儖傪拪弌偡傞媄朄偱偡丅偙傟傪巊偊偽帠屻暘晍偺婜懸抣(=暯嬒)傪僒儞僾儖偺扨弮暯嬒偱嬤帡偡傞偙偲偑偱偒傑偡丅
儅儖僐僼僠僃乕儞偼丄儔儞僟儉僂僅乕僋(悓偭暐偄偺愮捁懌)傪堦斒壔偟偨妋棪夁掱偱偡丅尰嵼偺抧揰傪婎弨偵偟偰師偺堦曕偑儔儞僟儉偵寛傑傞曕偒曽偵側傝傑偡丅
亂MCMC朄亃偼椉幰傪庢傝擖傟丄暋嶨側帠屻暘晍偵懳偟偰傕暘愅壜擻偵偟傑偡丅MCMC朄偼丄帺慠嫟栶帠慜暘晍偑壖掕偱偒傞儌僨儖偺応崌偼僊僽僗朄偲屇偽傟傞斾妑揑岠棪揑側傾儖僑儕僘儉傪丄偦傟偑壖掕偱偒側偄堦斒揑側応崌偼儊僩儘億儕僗亅傊乕僗僥傿儞僌朄偲傛偽傟傞枩擻側庤朄傪梡偄傑偡丅
幚柋偵岦偗偰
MCMC朄偵傛偭偰儀僀僘偼暘愅偺奯崻偑庢傝暐傢傟丄偝傑偞傑側栤戣偵廮擃偵懳墳偱偒傞傛偆偵側傝傑偟偨丅
偟偐偟丄偄偐偵儀僀僘夝愅偺偨傔偺僜僼僩僂僃傾偑惍偄偮偮偁傞偲偼尵偊丄暘愅嶌嬈偦偺傕偺偼戝曄偱偡丅
僷儔儊乕僞悢偑偦傟傎偳懡偔側偗傟偽丄夁嫀偵側偝傟偨尋媶偺惉壥傪梡偄傞偙偲偵傛偭偰丄斾妑揑娙扨偵儌僨儖偺悇掕偑峴偊傑偡丅(仸(拲婰)偨偩丄崱擔揑偵偼偦傟偩偗偱偼傛傝怺偄抦尒傪摼傞偙偲偵尷奅偑偁傞偺傕帠幚偱偡偑...)
師夞偼丄偦偺娙扨側曽偵増偭偰丄EXCEL偺庤寁嶼儗儀儖偱儀僀僘傪巊偭偰偄偔偙偲偼偱偒側偄偐丄偲偄偆偙偲傪峫偊偰傒偨偄偲巚偄傑偡丅
MCMC朄偵偮偄偰偺曗懌
恎撪偐傜乽MCMC朄偵偮偄偰傕偭偲愢柧傪乿偲偄偆惡偑偁傝傑偟偨偺偱丄彮偟偩偗丅
帠屻妋棪暘晍偑壓偺A恾偺傛偆偵梌偊傜傟偨偲偟傑偡丅儌乕僪(嵟昿抣)偼嶳偺偰偭傌傫偲偄偆偙偲偱暘偐傝傑偡偑丄暯嬒抣傗擟堄偺X偺妋棪傪弌偡偵偼丄愊暘偱柺愊寁嶼偟側偗傟偽側傝傑偣傫丅偙傟丄偗偭偙偆戝曄側傫偱偡偹丅
B恾偺傛偆偵丄抁嶜偵暘偗傞偲扨弮偵懌偟嶼偱嬤帡偡傞偙偲偑偱偒傑偡丅(嬫暘媮愊朄)
儔儞僟儉偵X偺僒儞僾儖傪偨偔偝傫拪弌偟偰傕丄懌偟嶼偵抲偒姺偊傞偙偲偑偱偒傑偡丅(儌儞僥僇儖儘朄)
偦傟偱傕僷儔儊乕僞乕偺悢(師尦偺悢)偑懡偔側偭偰偔傞偲丄寁嶼検偑朿戝側傕偺偵側偭偰偒傑偡丅
MCMC朄偼丄儌儞僥僇儖儘朄傪岠棪揑偵峴偆偨傔偺庤朄偱偡丅擟堄偺僗僞乕僩抧揰傪寛傔丄儖乕儖偵偺偭偲偭偰曕偒夞傝僒儞僾儖傪廤傔偰偙傛偆偲偄偆傢偗偱偡丅
C恾丄椢怓偺慄偺傛偆偵丄曽岦傪掕傔偰(1曄検偢偮拝栚偟偰)僕僌僓僌偵曕偙偆偲偄偆偺偑僊僽僗朄偱偡丅
愒怓偱帵偟傑偟偨偑丄忋傞偲偒偼昁偢恑傒丄壓傞偲偒偼棊嵎偵墳偠偰妋棪揑偵棫偪巭傑傞偙偲偵偡傟偽丄崅偄強傎偳枾側僒儞僾儕儞僌偑偱偒傞偩傠偆丄偲偄偆偺偑儊僩儘億儕僗亅傊乕僗僥傿儞僌朄偱偡丅
{kind=link}
MCMC朄偺愢柧.gif
偟偐偟丄偙偆偟偨傾儖僑儕僘儉偵娭偡傞抦幆偼丄幚柋偵偼偁傑傝娭學偟偰偙側偄偲巚偄傑偡丅
尰帪揰偱偼R偐WinBUGS偔傜偄偟偐僣乕儖偑偁傝傑偣傫偑丄偄偢傟惍偆偩傠偆斈梡揑側僜僼僩僂僃傾偵丄偙偺偁偨傝偼擟偣偰偍偗偽偄偄偙偲偱偟傚偆丅