Showing posts with label Binary Tree. Show all posts
Showing posts with label Binary Tree. Show all posts
Monday, January 28, 2013
No. 35 - Depth of Binary Trees
Question 1: How do you get the depth of a binary tree? Nodes from the root to a leaf form a path. Depth of a binary tree is the maximum length of all paths. For example, the depth of the binary tree in Figure 1 is 4, with the longest path through nodes 1, 2, 5, and 7.
{kind=link}
Figure 1: A binary Tree with depth 4
Analysis: We have discussed how to store nodes of a path in a stack while traversing a binary tree in the blog "Paths with Specified Sum in Binary Tree ". The depth of a binary tree is the length of the longest path. This solution works, but it is not the most concise one.
The depth of a binary tree can be gotten in another way. If a binary tree has only one node, its depth is 1. If the root node of a binary tree has only a left subtree, its depth is the depth of the left subtree plus 1. Similarly, its depth is the depth of the right subtree plus 1 if the root node has only a right subtree. What is the depth if the root node has both left subtree and right subtree? It is the greater value of the depth of the left and right subtrees plus 1.
For example, the root node of the binary tree in Figure 1 has both left and right subtrees. The depth of the left subtree rooted at node 2 is 3, and the depth of the right subtree rooted at node 3 is 2, so the depth of the whole binary tree is 4; 1 plus the greater value of 3 and 2.
It is easy to implement this solution recursively, with little modification on the post-order traversal
algorithm, as shown below:
algorithm, as shown below:
int TreeDepth(BinaryTreeNode* pRoot)
{
if(pRoot == NULL)
return 0;
int nLeft = TreeDepth(pRoot->m_pLeft);
int nRight = TreeDepth(pRoot->m_pRight);
return (nLeft > nRight) ? (nLeft + 1) : (nRight +
1);
}
Question 2: How do you verify whether a binary tree is balanced? If the depth difference between a left subtree and right subtree of any node in a binary tree is not greater than 1, it is balanced. For instance, the binary tree in Figure 1 is balanced.
Analysis:
Solution 1: Visiting Nodes for Multiple Times
According to the definition of balanced binary trees, this problem can be solved by getting the depth difference between the left and right subtrees of every node. When a node is visited, the function depth is invoked to get the depth of its left and right subtrees. If the depth different is 1 at most for all nodes in a binary tree, it is balanced. This solution can be implemented based on the TreeDepth discussed in the preceding problem, as shown below:
bool IsBalanced_Solution1(BinaryTreeNode* pRoot)
{
if(pRoot == NULL)
return true;
int left = TreeDepth(pRoot->m_pLeft);
int right = TreeDepth(pRoot->m_pRight);
int diff = left - right;
if(diff > 1 || diff < -1)
return false;
return IsBalanced_Solution1(pRoot->m_pLeft)
&& IsBalanced_Solution1(pRoot->m_pRight);
}
This solution looks concise, but it is inefficient because it visits some nodes for multiple times. Take the binary tree in Figure 1 as an example. When the function TreeDepth takes the node 2 as a parameter, it visits nodes 4, 5, and 7. When it verifies whether the binary tree rooted at node 2 is balanced, it visits nodes 4, 5, and 7 again. Obviously, we could improve performance if nodes are visited only once.
Solution 2: Visiting Every Node Only Once
If a binary tree is scanned with the post-order algorithm, its left and right subtrees are traversed before the root node. If we record the depth of the currently visited node (the depth of a node is the maximum length of paths from the node to its leaf nodes), we can verify whether the subtree rooted at the currently visited node is balanced. If any subtree is unbalanced, the whole tree is unbalanced.
This new solution can be implemented as shown in below:
bool IsBalanced_Solution2(BinaryTreeNode* pRoot)
{
int depth = 0;
return IsBalanced(pRoot, &depth);
}
bool IsBalanced(BinaryTreeNode* pRoot, int* pDepth)
{
if(pRoot == NULL)
{
*pDepth = 0;
return true;
}
int left, right;
if(IsBalanced(pRoot->m_pLeft, &left) && IsBalanced(pRoot->m_pRight, &right))
{
int diff = left - right;
if(diff <= 1 && diff >= -1)
{
*pDepth = 1 + (left > right ? left : right);
return true;
}
}
return false;
}
After verifying left and right subtrees of a node, the solution verifies the subtree rooted at the current visited node and passes the depth to verify its parent node. When the recursive process returns to the root node finally, the whole binary tree is verified.
The discussion about this problem is included in my book <Coding Interviews:
Questions, Analysis & Solutions>, with some revisions. You may find the
details of this book on Amazon.com ,
or Apress .
The author Harry He owns all the rights of this post. If you are going to use part of or the whole of this ariticle in your blog or webpages, please add a reference to http://codercareer.blogspot.com/ . If you are going to use it in your books, please contact him via zhedahht@gmail.com . Thanks.
The author Harry He owns all the rights of this post. If you are going to use part of or the whole of this ariticle in your blog or webpages, please add a reference to http://codercareer.blogspot.com/ . If you are going to use it in your books, please contact him via zhedahht@gmail.com . Thanks.
Labels:
Algorithm,
Amazon,
Binary Tree,
C++,
Data Structure,
Google,
Microsoft
Sunday, October 23, 2011
No. 12 - Mirror of Binary Trees
Problem: Please implement a function which returns mirror of a binary tree.
Binary tree nodes are defined as:
struct BinaryTreeNode
{
int m_nValue;
BinaryTreeNode* m_pLeft;
BinaryTreeNode* m_pRight;
};
Analysis: Mirror of binary trees may be a new concept for many candidates, so they may not find a solution in short time during interviews. In order to get some visual ideas about mirrors, we may draw a binary tree and its mirror according to our daily experience. For example, the binary tree on the right of Figure 1 is the mirror of the left one.
{kind=link}
Figure 1: Two binary trees which are mirrors of each other
Let us analyze these two trees in Figure 1 carefully to get the steps of mirrors. Their root nodes are identical, but their left and right children are swapped. Firstly we may swap two nodes under the root of the original binary tree, and it becomes the second tree in Figure 2.
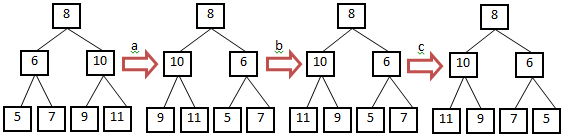{kind=link}
Figure 2: Process to get mirror of a binary tree. (a) Swap children of the root node; (b) Swap children of the node 10; (c) Swap the children of node 6.
Now we can summarize the process for mirror: We visit all nodes in a binary tree with pre-order traversal, and swap the children of current visited node if it has. We will get mirror of a binary tree after we visit all of its nodes.
Let us begin to write code after we get clear ideas about the process. The following is the sample code:
void Mirror(BinaryTreeNode *pNode)
{
if((pNode == NULL) || (pNode->m_pLeft == NULL && pNode->m_pRight))
return;
BinaryTreeNode *pTemp = pNode->m_pLeft;
pNode->m_pLeft = pNode->m_pRight;
pNode->m_pRight = pTemp;
if(pNode->m_pLeft)
MirrorRecursively(pNode->m_pLeft);
if(pNode->m_pRight)
MirrorRecursively(pNode->m_pRight);
}The discussion about this problem is included in my book <Coding Interviews: Questions, Analysis & Solutions>, with some revisions. You may find the details of this book on Amazon.com, or Apress.
The author Harry He owns all the rights of this post. If you are going to use part of or the whole of this ariticle in your blog or webpages, please add a referenced to http://codercareer.blogspot.com/. If you are going to use it in your books, please contact me (zhedahht@gmail.com) . Thanks.
Saturday, October 22, 2011
No. 11 - Print Binary Trees from Top to Bottom
Problem: Please print a binary tree from its top level to bottom level, and print nodes from left to right if they are in same level.
For example, it prints the binary tree in Figure 1 in order of 8, 6, 10, 5, 7, 9, 11.
A binary tree node is defined as below:
struct BinaryTreeNode
{
int m_nValue;
BinaryTreeNode* m_pLeft;
BinaryTreeNode* m_pRight;
};
{kind=link}
Figure 1: A binary tree sample. If it is printed from top to bottom, it prints 8, 6, 10, 5, 7, 9, 11 sequentially.
Analysis: It examines candidates’ understanding of tree traverse algorithms, but the traverse here is not the traditional pre-order, in-order or post-order traverses. If we are not familiar with it, we may analyze the printing process with some examples during interview. Let us take the binary tree in Figure 1 as an example.
Since we begin to print from the top level of the tree in Figure 1, we can start our analysis from its root node. Firstly we print the value in its root node, which is 8. We need to store the children nodes with value 6 and 10 in a data container in order to print them after we print the root. There are two nodes in our container at this time.
Secondly we retrieve the node 6 from the container, since nodes 6 and 10 are in same level and we need to print them from left to right. We also need to store the nodes 5 and 7 after we print the node 6. There are three nodes in the container now, which are node 10, 5 and 7.
Thirdly we retrieve the node 10 from the container. It is noticeable that node 10 is stored into the container before nodes 5 and 7 are stored, and it is also retrieved ahead of nodes 5 and 7. It is typically “First in first out”, so the container is essentially a queue. After print the node 10, we store its two children nodes 9 and 11 into the container too.
Since nodes 5, 7, 9, 11 do not have children, we print them in order.
The printing process can be summarized in the following Table 1:
Step
Operation
Nodes in queue
1
Print Node 8
Node 6, Node 10
2
Print Node 6
Node 10, Node 5, Node 7
3
Print Node 10
Node 5, Node 7, Node 9, Node 11
4
Print Node 5
Node 7, Node 9, Node 11
5
Print Node 7
Node 9, Node 11
6
Print Node 9
Node 11
7
Print Node 11
Table 1: The process to print the binary tree in Figure 1 from top to bottom
We can summarize the rules to print a binary tree from top level to bottom level: Once we print a node, we store its children nodes into a queue if it has. We continue to print the head of the queue, pop it from the queue and store its children until there are no nodes left in the queue.
The following sample code is based on the deque class of STL:
void PrintFromTopToBottom(BinaryTreeNode* pTreeRoot)
{
if(!pTreeRoot)
return;
std::deque<BinaryTreeNode *> dequeTreeNode;
dequeTreeNode.push_back(pTreeRoot);
while(dequeTreeNode.size())
{
BinaryTreeNode *pNode = dequeTreeNode.front();
dequeTreeNode.pop_front();
printf("%d ", pNode->m_nValue);
if(pNode->m_pLeft)
dequeTreeNode.push_back(pNode->m_pLeft);
if(pNode->m_pRight)
dequeTreeNode.push_back(pNode->m_pRight);
}
}The discussion about this problem is included in my book <Coding Interviews: Questions, Analysis & Solutions>, with some revisions. You may find the details of this book on Amazon.com, or Apress.
The author Harry He owns all the rights of this post. If you are going to use part of or the whole of this ariticle in your blog or webpages, please add a reference to http://codercareer.blogspot.com/. If you are going to use it in your books, please contact me (zhedahht@gmail.com) . Thanks.
Labels:
Algorithm,
Binary Tree,
C++,
Data Structure,
Interview Question,
Microsoft,
Queue
Saturday, September 17, 2011
No. 05 - The Least k Numbers
Question: Please find out the least k numbers out of n numbers. For example, if given the 8 numbers 4, 5, 1, 6, 2, 7, 3 and 8, please return the least 4 numbers 1, 2, 3 and 4.
Analysis: The naïve solution is sort the n input numbers increasingly, and the least k numbers should be the first k numbers. Since it needs to sort, its time complexity is O(nlogn). Interviewers will ask us explore more efficient solutions.
Solution 1: O(nlogk) time efficiency, be suitable for data with huge size
A data container with capacity k is firstly created to store the least k numbers, and then a number is read out of the n input numbers at each time. If the container has less than k numbers, the number read at current round (denoted as num) is inserted into container directly. If it contains k numbers already, num cannot be inserted directly any more. However, it may replace an existing number in the container. We get the maximum number of the k numbers in the container, and compare it with num. If num is less than the maximum number, we replace the maximum number with num. Otherwise we discard num, since we already have k numbers in the container which are all less than num and it cannot be one of the least k numbers.
Three steps may be required when a number is read and the container is full: The first step is to find the maximum number, secondly we may delete the maximum number, and at last we may insert a new number. The second and third steps are optional, which depend on whether the number read at current round is greater than the maximum number in container or not. If we implement the data container as a binary tree, it costs O(logk)time for these three steps. Therefore, the overall time complexity is O(nlogk)for n input numbers.
We have different choices for the data container. Since we need to get the maximum number out of k numbers, it intuitively might a maximum heap. In a maximum heap, its root is always greater than its children, so it costs O(1) time to get the maximum number. However, it takes O(logk)time to insert and delete a number.
We have to write a lot of code for a maximum heap, and it is too difficult in the dozens-of-minute interview. We can also implement it as a red-black tree. A red-black tree classifies its nodes into red and black categories, and assure that it is somewhat balanced based on a set of rules. Therefore, it costs O(logk) time to find, insert and delete a number. The classes set and multiset in STL are all based on red-black trees. We may use data containers in STL directly if our interviewers are not against it. The following sample code is based on the multiset in STL:
typedef multiset<int, greater<int> > intSet;
typedef multiset<int, greater<int> >::iterator setIterator;
void GetLeastNumbers(const vector<int>& data, intSet& leastNumbers, int k)
{
leastNumbers.clear();
if(k < 1 || data.size() < k)
return;
vector<int>::const_iterator iter = data.begin();
for(; iter != data.end(); ++ iter)
{
if((leastNumbers.size()) < k)
leastNumbers.insert(*iter);
else
{
setIterator iterGreatest = leastNumbers.begin();
if(*iter < *(leastNumbers.begin()))
{
leastNumbers.erase(iterGreatest);
leastNumbers.insert(*iter);
}
}
}
}
Solution 2: O(n) time efficiency, be suitable only when we can reorder the input
We can also utilize the function Partition in quick sort to solve this problem with a hypothesis. It assumes that n input numbers are contained in an array. If it takes the k-th number as a pilot to partition the input array, all of numbers less than the k-th number should be at the left side and other greater ones should be at the right side. The k numbers at the left side are the least k numbers after the partition. We can develop the following code according to this solution:
void GetLeastNumbers(int* input, int n, int* output, int k)
{
if(input == NULL || output == NULL || k > n || n <= 0 || k <= 0)
return;
int start = 0;
int end = n - 1;
int index = Partition(input, n, start, end);
while(index != k - 1)
{
if(index > k - 1)
{
end = index - 1;
index = Partition(input, n, start, end);
}
else
{
start = index + 1;
index = Partition(input, n, start, end);
}
}
for(int i = 0; i < k; ++i)
output[i] = input[i];
}
Comparison between two solutions
The second solution based on the function Partition costs only O(n) time, so it is more efficient than the first one. However, it has two obvious limitations: One limitation is that it needs to load all input numbers into an array, and the other is that we have to reorder the input numbers.
Even though the first takes more time, the second solution does have the two limitations as the first one. It is not required to reorder the input numbers (data in the code above). We read a number from data at each round, and all write operations are taken in the container leastNumbers. It does not require loading all input number into memory at one time, so it is suitable for huge-size data. Supposing our interview asks us get the least k numbers from a huge-size input. Obviously we cannot load all data with huge size into limited memory at one time. We can read a number from auxiliary space (such as disk) at each round with the first solution, and determine whether we need to insert it into the container leastNumbers. It works once memory can accommodate leastNumbers, so it is especially works when n is huge and k is small.
The characters of these two solutions can be summarized in Table 1:
First Solution
Second Solution
Time complexity
O(n*logk)
O(n)
Reorder input numbers?
No
Yes
Suitable for huge-size data?
Yes
No
Table 1: Pros and cons of two solutions
Since each solution has its own pros and cons, candidates had better to ask interviews for more requirements and details to choose the most suitable solution, including the input data size and whether it is allowed to reorder the input numbers.
The discussion about this problem is included in my book <Coding Interviews: Questions, Analysis & Solutions>, with some revisions. You may find the details of this book on Amazon.com, or Apress.
The author Harry He owns all the rights of this post. If you are going to use part of or the whole of this ariticle in your blog or webpages, please add a reference to http://codercareer.blogspot.com/. If you are going to use it in your books, please contact me (zhedahht@gmail.com) . Thanks.
The discussion about this problem is included in my book <Coding Interviews: Questions, Analysis & Solutions>, with some revisions. You may find the details of this book on Amazon.com, or Apress.
The author Harry He owns all the rights of this post. If you are going to use part of or the whole of this ariticle in your blog or webpages, please add a reference to http://codercareer.blogspot.com/. If you are going to use it in your books, please contact me (zhedahht@gmail.com) . Thanks.
Friday, September 16, 2011
No. 04 - Paths with Specified Sum in Binary Tree
Question: All nodes along children pointers from root to leaf nodes form a path in a binary tree. Given a binary tree and a number, please print out all of paths where the sum of all nodes value is same as the given number. The node of binary tree is defined as:
struct BinaryTreeNode
{
int m_nValue;
BinaryTreeNode* m_pLeft;
BinaryTreeNode* m_pRight;
};
For instance, if inputs are the binary tree in Figure 1 and a number 22, two paths with be printed: One is the path contains node 10 and 12, and the other contains 10, 5 and 7.
{kind=link}
Figure 1: A binary tree with two paths where the sum of all nodes value is 22: One is the path contains node 10 and 12, and the other contains node 10, 5 and 7
Analysis: Path in a binary tree is a new concept for many candidates, so it is not a simple question for them. We may try to find the hidden rules with concrete examples. Let us take the binary tree in Figure 1 as an example.
Since paths always start from a root node, we traverse from a root node in a binary tree. We have three traversal orders, pre-order, in-order and post-order, and we firstly visit a root node with pre-order traversal.
According to the pre-order traversal process on the binary tree in Figure 1, we visit the node 5 after visiting the root node 10. Since a binary tree node does not have a pointer to its parent node, we do not know what nodes have been visited when we reach the node 5 if we do not save the visited node on the path. Therefore, we could insert the current node into a path when we reach it during traversal. The path contains two nodes with value 10 and 5 when we are visiting the node 5. Then we insert the node 4 into the path too when we reach it. We have reached a leaf node, and the sum of three nodes in the path is 19. Since it is not same as the input number 22, current path is not a qualified one.
We should continue to traverse other nodes. Before visiting other nodes, we should return back to the node 5, and then reach the node 7. It can be noticed that node 4 is no longer in the path from node 10 to node 7, so we should remove it from the path. When we are visiting node 7, we insert it into the path, which contains three nodes now. Since the sum of value of these three nodes is 22, the path is qualified.
Lastly we are going to visit the node 12. We should return back to node 5 then back to node 10 before we visit node 12. When we return back from a child node to its parent node, we remove the child node from the path. When we reach the node 12 eventually, the path contains two nodes, one is node 10 and the other is node 12. Since the sum of value of these two nodes is 22, the path is qualified too.
We can summarize the whole process above with the Table 1:
Step
Operation
Is it a leaf?
Path
Sum of nodes value
1
Visit node 10
No
node 10
10
2
Visit node 5
No
node 10, node 5
15
3
Visit node 4
Yes
node 10, node 5, node 4
19
4
Return to node 5
node 10, node 5
15
5
Visit node 7
Yes
node 10, node 5, node 7
22
6
Return to node 5
node 10, node 5
15
7
Return to node 10
node 10
10
8
Visit node 12
Yes
node 10, node 12
22
Table 1: The process to traverse the binary tree in Figure 1
It is time to summarize some rules with the example above. When we visit a node with pre-order traversal order, we insert it into the path, and accumulate its value to sum. When the node is a leaf and sum is same as the input number, the path is qualified and we need to print it. We continue to visit its children if the current node is not a leaf. After we finish visiting the current node, a recursive function will return back to its parent node automatically, so we should remove the current node from the path before a function returns to make sure the nodes in the path is same as the path from root node to its parent node. The data structure to save paths should be a stack, because paths should be consistent to the recursion status and recursion is essentially pushing and popping in a call stack.
Here is some sample code for this problem:
void FindPath(BinaryTreeNode* pRoot, int expectedSum)
{
if(pRoot == NULL)
return;
std::vector<int> path;
int currentSum = 0;
FindPath(pRoot, expectedSum, path, currentSum);
}
void FindPath
(
BinaryTreeNode* pRoot,
int expectedSum,
std::vector<int>& path,
int currentSum
)
{
currentSum += pRoot->m_nValue;
path.push_back(pRoot->m_nValue);
// Print the path is the current node is a leaf
// and the sum of all nodes value is same as expectedSum
bool isLeaf = pRoot->m_pLeft == NULL && pRoot->m_pRight == NULL;
if(currentSum == expectedSum && isLeaf)
{
printf("A path is found: ");
std::vector<int>::iterator iter = path.begin();
for(; iter != path.end(); ++ iter)
printf("%d\t", *iter);
printf("\n");
}
// If it is not a leaf, continue visition its children
if(pRoot->m_pLeft != NULL)
FindPath(pRoot->m_pLeft, expectedSum, path, currentSum);
if(pRoot->m_pRight != NULL)
FindPath(pRoot->m_pRight, expectedSum, path, currentSum);
// Before returning back to its parent, remove it from path,
path.pop_back();
}
In the code above, we save path with a vector in STL actually. We use function push_back to insert a node and pop_back to remove a node to assure it is “First in Last out” in a path. The reason we don’t utilize a stack in STL is that we can only get an element at the top of a stack, but we need to get all nodes when we print a path. Therefore, std::stack is not the best choice for us.
The discussion about this problem is included in my book <Coding Interviews: Questions, Analysis & Solutions>, with some revisions. You may find the details of this book on Amazon.com, or Apress.
The author Harry He owns all the rights of this post. If you are going to use part of or the whole of this ariticle in your blog or webpages, please add a reference to http://codercareer.blogspot.com/. If you are going to use it in your books, please contact me (zhedahht@gmail.com) . Thanks.
Labels:
Algorithm,
Binary Tree,
Data Structure,
Interview Question,
Stack
Subscribe to:
Posts (Atom)