neděle 2. listopadu 2014
Events visualization with EvenDrops and KoExtensions (D3 and Knockout)
I have recently needed to visualize a set of events which occurred within a certain interval. Each event would have couple parameters and there would be multiple event lines. Let's say that you want to visualize the occurences of car sales in couple countries. For each sale you would also want to visualize the price and the mark of the sold car. Before writing everything from scratch, I have found EventDrops project which responded to the majority of my requirements. It had just one flaw and that is that there is no way to chart another characteristics for each event.
I have decided to add such possibility and since I am using KnockoutJS and binding to create all of my charts I have also decided to add EventDrops to my KoExtensions project - in order to make it's usage simplier. The resulting chart looks like this:
{kind=link}
This example is available on GitHub as part of KoExtensions.
What I have added to the original event drops are the following possibilities:
- The chart now accepts generic collection instead of just a collection of dates. The developer in turn has to specify a function to get the date for each item
- The size of the event is dynamic
- The color of the event is dynamic
- Better possibility to provide a however action
- The size of the event can use logarithmic or linear scale
- Everything is available as KnockoutJS binding
<div data-bind="eventDrops: carSales, chartOptions: carSalesOptions"></div>The javascript behind this page contains a bit more to generate the data:
require(['knockout-3.2.0.debug', 'KoExtensions/koextbindings', 'KoExtensions/Charts/linechart', 'KoExtensions/Charts/piechart', 'KoExtensions/Charts/barchart'], function(ko) {
function createRundomSales(country) {
var event = {};
var marks = ['Audi', 'BMW', 'Peugot', 'Skoda'];
event.name = country;
event.dates = [];
var endTime = Date.now();
var oneMonth = 30 * 24 * 60 * 60 * 1000;
var startTime = endTime - oneMonth;
var max = Math.floor(Math.random() * 80);
for (var j = 0; j < max; j++) { var time = Math.floor((Math.random() * oneMonth)) + startTime; event.dates.push({ timestamp: new Date(time), carMark: marks[Math.floor(Math.random() * 100) % 4], price: Math.random() * 100000 }); } return event; } function createSales() { var sales = []; var countries = ['France', 'Germany', 'Czech Republic', 'Spain']; countries.forEach(function(country) { var countrySales = createRundomSales(country); sales.push(countrySales); }); return sales; } function TestViewModels() { var self = this; self.carSales = ko.observableArray([]); self.carSales(createSales()); self.carSalesOptions = { eventColor: function (d) { return d.carMark; }, eventSize: function (d) { return d.price; }, eventDate: function (d) { return d.timestamp; }, start: new Date(2014, 8, 1) }; } var vm = new TestViewModels(); ko.applyBindings(vm); });
In this example the createSales and createRandomSales methods are just use to get testing data. Once the testing data is generated it is stored to the carSales observable collection. Any time this collection is changed the chart would be updated.
The sales collection looks a bit like this:
{kind=link}
The carSalesOptions object contains the charting options. These tell to the event drops chart the necessary information to specify how big and which color should be used for the given event.
čtvrtek 17. července 2014
Unit testing Knockout applications
In ideal case any View Model in Knockout based application should be completely unit-testable. The View Model ofcourse interacts with other code but in majority of cases this would be either some UI code or the server side code, probably over REST API. The UI interaction should be minimal. If possible, the binding capabilities of Knockout should be leveraged. The REST API is not available while unit testing and thus has to be mocked or hidden by an abstraction layer. I went for the first option and this blog describes how to mock the AJAX calls while unit testing Knockout View Models. At the end I also provide information about the ChutzPah test runner and the way that the tests can be run from within Visual Studio.
The typical view model that I am using looks like the following one.
function AssetViewModel(){
var self = this;
self.city = ko.observable();
self.country = ko.observable();
self.size = ko.observable();
self.load = function(){
$.ajax("/api/assets/" + self.city(), {
data: dto,
type: "GET", contentType: "application/json",
success: function (result) {
self.updateData(data);
}
});
}
self.save = function () {
var dto = self.toDto();
self.isBusy(true);
self.message("Saving...");
$.ajax("/api/assets/", {
data: dto,
type: "POST", contentType: "application/json",
success: function (result) {
self.edit(false);
self.isBusy(false);
self.message(result.message);
self.update(result.data);
}
});
};
self.update = function(updateData){
self.city(updateData.City);
self.country(updateData.Country);
}
self.toDto = function () {
var model = new Object();
model.City = self.city();
model.Country = self.country();
return JSON.stringify(model);
};
}
You might thing that the toDto method is useless if one uses the Knockout Mapping plug-in, however in many cases the view models get much more complex and they can't be directly mapped to any kind of data transfer objects or domain objects. Other than that, nothing should be surprising here. The save method sends the dto over the wire and than treats the response.
The unit test
Nowadays one has a choice between multiple JavaScript testing frameworks, QUnit, Jasmine or Mocha being probably the most common choices - I am staying with QUnit. Testing the updateData with QUnit might look like this.
var vm;
function initTest() {
var vm = new AssetViewModel();
}
$(function () {
QUnit.module("ViewModels/AssetViewModel", {
setup: initTest
});
QUnit.test("updateData sets correctly the city", function () {
var data = {
City: "Prague",
Country:"Czech Republic"
};
vm.updateData(data);
equal(vm.city(), "Prague");
});
}
QUnit module function takes 2 parameters - name and a sort of configuration object. Configuration object can contain a setup and tearDown methods. Their usage and intend should be clear.
This test case is very simple for 2 reasons: it does not depend on any external resources and it executes synchronously.
QUnit has 3 assert methods which can be used in the tests:
- ok - One single argument which has to evaluate to true
- equal - Compare two values
- deepEqual - Recursively compare a objects properties
Asynchronous testing
Here is the test for the save method which calls the REST server interface.
function initTest() {
$.mockjax({
url: '/api/assets/Prague',
type: 'GET',
responseTime: 30,
responseText: JSON.stringify({
Name: "Prague",
Country: "Czech Republic",
Size: 20
})
});
}
$(function () {
QUnit.module("ViewModels/AssetViewModel", {
setup: initTest
});
QUnit.asyncTest("testing the load method", function () {
setTimeout(function () {
ok(true, "Passed and ready to resume!");
start();
vm.load();
QUnit.equal(vm.size(),20);
}, 100);
});
}
I am using MockJax library to mock the results of the REST calls. The initTest method setups the desired behavior of the REST service call, the test is executed after 100ms of waiting time. In this case the call is a GET and we define the response simply as JSON data. QUnit has a method for asynchronous tests called asyncTest .
Currently there is a small issue in MockJax regarding the way that incoming JSON values are handled. That might get fixed in future versions.
Mocking the server interface
Returning a simple JSON data may be sufficient for some case, for others however we would maybe like to verify the integrity of the data sent to the server, just like when testing the save method
var storedAssets = [];
function initTest() {
$.mockjax({
url: '/api/assets',
type: 'POST',
responseTime: 30,
response: function (data) {
storedAssets.push(JSON.parse(data.data));
}
});
}
$(function () {
QUnit.module("ViewModels/AssetViewModel", {
setup: initTest
});
QUnit.asyncTest("save asset - check the update of the size", function () {
vm.size(10);
vm.save();
setTimeout(function () {
ok(true, "Passed and ready to resume!");
start();
equal(storedAssets.length, 1);
var storedAssets = storedCharges[0];
equal(storedAssets.Size, vm.size());
}, 100);
});
}
In this case the save method passes the JSON data to the server side. The server is mocked by MockJax which only adds the data to a dump array, which can be then used to verify the integrity of the data.
Running Unit Tests in Visual Studio
There are 3 reasons for which I am using Visual Studion even for JavaScript project:
- Usually the application has some backend written in .NET and I don't want to use 2 IDEs for one single application.
- I can easily debug JS application from within VS. Of course Chrome's debugger is very useful as well - but if I can do everything from 1 IDE, why should I use other.
- ReSharper has really good static analysis of JavaScript and HTML files. That saves me a lot of time - typos, unknown references and other issue are catched before I run the application.
- I can run JavaScript unit tests right from the IDE.
To run the Unit Tests I am using ChutzPah test runner. ChutzPah internally uses the PhantomJS in-memory browser, and interprets the tests. While using this framework, one does not need the QUnit wrapper HTML page and the Unit Tests can be run as they are.
Note that ChutzPah already contains QUnit and you will obtain TimeOutException, if you try to add a reference to QUnit explicitly (http://chutzpah.codeplex.com/workitem/72).
Since your tests are just JavaScript files, without the HTML wrapper page, ChutzPah needs to know what libraries do your View Models reference and load them. This is handled using a configuration file chutzpah.json which has to be placed alongside the unit tests. The following is an example of configuration file that I am using for my tests.
{
"Framework": "qunit",
"References" : [
{ "Path": "../Scripts/jquery-2.1.0.js"},
{ "Path": "../Scripts/knockout-3.1.0.js"},
{ "Path": "../Scripts/jquery.mockjax.js"},
{ "Path": "../Scripts/tech", "Include": "*.js"},
{ "Path": "../ViewModels", "Include": "*.js"}
]
}
{kind=link}
JSON DateTime serialization
This is more a side note. Dates in JSON are serialized into ISO format. That is good, the problems is that if you try to deserialize an object which contains a date, the date comes out as a string. The reason of course is that since there is no type, the de-serializer does not know that given property is a date - and keeps the value as a string. You can read more on dates serialization in JSON here. Any time that you are mocking backend which handles dates you have to be aware of this fact. Remember the mock of the back-end which inserts the object to a dummy array that I have used above:
function initTest() {
$.mockjax({
url: '/api/assets',
type: 'POST',
responseTime: 30,
response: function (data) {
storedAssets.push(JSON.parse(data.data));
}
});
}
JSON.parse call we handle the dates as strings. If the ViewModel has a date property, you will have to convert it into string before testing the equality.
sobota 31. května 2014
Detecting extreme values in SQL
In a set of data points, outliers are such values that theoretically should not appear in the dataset. Typically these can be measurement errors or values caused by human mistakes. In some cases outliers are not caused by errors. These values affect the way that the data is treated and any statistics or report based on data containing outliers are erroneaus.
Detecting these values might be very hard or even impossible and a whole field of statistics called Robust Statistics covers this subject. If you are further interested into the subject please read Quantitative Data Cleaning For Large Databases written by Joseph M. Hellerstein from UC Barkeley. Everything that I have implemented here is taken from this paper. The only thing that I have added to that are two aggregates for SQL Server which help efficiently get the outliers and extreme values from the data stored in SQL Server and a simple tool to chart data and distribution of data using JavaScript
Theory
Any dataset can be characterized by the way the data is distributed over the whole range. The probability that a single point has given value in the dataset is defined using the probability distribution function. The Gaussian standard distribution is only one among many distribution functions, I won't go into statistics basics here, but let's consider only the standard distribution for our case.
In the Gaussian distribution the data points are somehow gathered around the "center", and most values fall not far. Rare are the values really far away from the center. Intuitively the ouliers are points very far from the center. Consider the following set of numbers which represent in minutes the length of a popular song:
3.9,3.8,3.9,2.7,2.8,1.9,2.7,3.5, 4.4, 2.8, 3.4, 8.6, 4.5, 3.5, 3.6, 3.8, 4.3, 4.5, 3.5,30,33,31
You have probably spotted the values 30,33 and 31 and you immediately identify them as outliers. Even if the Doors would double the length of their keyboard solo we would not get this far.
The standard distribution can be described using the probability density function. This function defines the probability that the point will have given value. The function is defined with two parameters: the center and the dispersion. The center is the most common value, the one around which all others are gathered. The dispersion describes how far the values are scattered from the center.
The probability that a point has a given value, provided that the data has the Gaussian distribution is given by this equation:
{kind=link}
We can visualize both the theoretical and the real distribution of data. The distribution probability density function is continuous and thus can be charted as simple line. The distribution of the real data in turn can be visualized like a histogram.
The following graphics were created using KoExtensions project, which is a small mediator project making Knockout and D3 work nicely together.
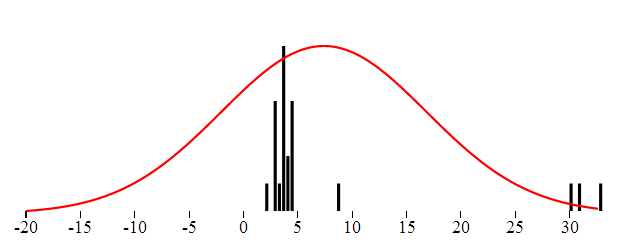{kind=link}
In perfect world the center is the mean value. That value is probably not a part of a data set but represents the typical value. The seconds measure which describes how far from the center the data is dispersed is called standard deviation. If we want to obtain the standard deviation from data we take the distance of each point from the center, square these values add them together and take square root. So we actually have all we need to get the distribution parameters from the data.
This approach of course has one main flaw. The mean value is affected by the outliers. And since the dispersion is deduced using the mean and outliers affect the mean value, the dispersion as well will be affected by them. In order to get a description of the dataset not affected by the extreme values one needs to find robust replacements for the mean and the dispersion.
Robust Center
The simplest and very efficient replacement for the mean as the center of the data is the median. Median is such value that half of the points in the dataset are smaller are bellow. That is if the data set consists of even number of samples, we just need to order the values and take mean of the two values in the middle of the ordered array. If the data consist of odd number of values then we take the element exactly in the middle of the ordered data. The before mentioned paper describes two more alternatives: trimmed mean, winsorized mean. Both of these are based on the exclusion of marginal values and I did not used them in my implementation.
Let's take the median of the given dataset and see if the distribution function based on it fits better the data. Even though the center is now in correct place the shape of the function does not fit completely the data from the histogram. That is because the variance is still affected by the outliers.
{kind=link}
Robust Dispertion
Standard variance takes into account the the distance of all the numbers from the center. To rule out the extreme values, we can just use the median of distances. The outlier's distance from the center is much bigger than other distance and by taking the median of all distances we can get rid of outlier's influence over the dispersion. Here is the distribution function using this Robust type of dispersion. This characteristic is called MAD - Median Absolute Deviation.
{kind=link}
Detecting the outliers
Now that we have the value of "real" center and "real spread" or dispersion we can state that the outlier is a value which differs "too much" from the center, taking into account the dispersion. Typically we could say that the outliers are such values that have a distance from center greater or equal to 10 * dispersion. The question is how to specify the multiplication coefficient. There is a statistics method called Hampel Indetifier which gives a formula to obtain the coefficient. Hampel identifier labels as outliers any points that are more than 5.2 away from the MAD. More details can be found here.
{kind=link}
The overall reliability of this method
A question which might arise is up to which kind of messy data this method can be used. A common intuition would say that definitely more than the half of the data has to be "correct", in order to be able to detect the incorrect ones. To be able to measure the robustness of each method of detecting outliers, statisticians have introduced a term called Breakdown point. This point states which percentage of the data can be corrupted in order for given method to work. Using the Median as the center with the MAD (Median Absolute Deviation) has a breakdown point of 1/2. That is this method works if more than half of the data is correct. The standard arithmetic mean has a BP = 0. It is directly affected by all the numbers and one single outlier can completely move the data.
SQL implementation
In order to implement detection of outliers in SQL, one needs to first have the necessary functions to compute the mean, median and dispersion. All these functions are aggregates. Mean (avg) and Dispersion (var) are already implemented in SQL Server. If you are lucky enough to use SQL Server 2012 you can use the built-in median aggregate as well. The robust dispersion however has to be implemented manually even on SQL Server 2012.
Implementing aggregates for SQL Server is very easy, thanks to the predefined Visual Studio template. This templates will create a class for you which implements the IBinarySerializable interface and is decorate with couple attributes defined in the Microsoft.SqlServer namespace.
{kind=link}
This class has 4 important methods:
- Init - anything needed before starting the aggregation
- Accumulate - adding one single value to the aggregate
- Merge - merging two aggregates
- Terminate - work to be done before returning the result of the aggregate
Here is the example of the Median aggregate
private Listld; public void Init() { ld = new List (); } public void Accumulate(SqlDouble value) { if (!value.IsNull) { ld.Add(value.Value); } } public void Merge(Median group) { ld.AddRange(group.ld.ToArray()); } public SqlDouble Terminate() { return Tools.Median(ld); }
Note that some aggregates can be computed iteratively. In that case all the necessary logic is in the Accumulate method and the Terminate method can be empty. With Median this is not the case (even though some iterative estimation methods exist. For the sake of the completeness, here is the implementation of median that I am using. It is the standard way: sorting the array and taking the middle element or average of the two middle elements. I am returning directly SqlDouble value, which is the result of the aggregate.
public static SqlDouble Median(Listld) { if (ld.Count == 0) return SqlDouble.Null; ld.Sort(); int index = ld.Count / 2; if (ld.Count % 2 == 0) { return (ld[index] + ld[index - 1]) / 2; } return ld[index]; }
Implementing the Robust variance using the MAD method is very similar, everything happens inside the Terminate method.
public SqlDouble Terminate()
{
var distances = new List();
var median = Tools.Median(ld);
foreach (var item in ld)
{
var distance = Math.Abs(item - median.Value);
distances.Add(distance);
}
var distMedian = Tools.Median(distances);
return distMedian;
}
That implementation is directly the one described above: we take the distance of each element from the center (median) and than we take the median of the distances.
Outliers detection with the SQL aggregates
Having implemented both aggregates, detecting the outlier is just a matter of a SQL query - giving all the elements which are further away from the center than the variance multiplied by a coefficient.
select * from tbUsers where Height> ( Median(Height) + c*RobustVar(Height)) or Height < (Median(Height) - c*RobustVar(Height))
You will have to play with the coefficient value c to determine which multiplication gives you the best results.
JavaScript implementation
The same can be implemented in JavaScript. If you are interested in a JavaScript implementation you can check out the histogram chart from KoExtensions. This charting tool draws the histogram and the data distribution function. You can than configure it to use either Median or Mean as the center of the data as well as to use MAD, or standard variance to describe the dispersion.
KoExtensions is based on Knockout.JS and adds several useful bindings and the majority of them to simplify charting. Behind the scenes the data is charted using D3.
To draw a histogram chart with the distribution and detecting the outliers at the same time one needs just few lines of code
<div id="histogram" data-bind="histogram: data, chartOptions : {
tolerance : 10,
showProbabilityDistribution: true,min : -20,
expected: 'median',
useMAD: true,
showOutliers: true}">
var exData = [3.9,3.8,3.9,2.7,2.8,1.9,2.7,3.5, 4.4, 2.8, 3.4, 8.6, 4.5, 3.5, 3.6, 3.8, 4.3, 4.5, 3.5,30,33,31];
function TestViewModel() {
var self = this;
self.data = ko.observableArray(exData);
}
var vm = new TestViewModel();
ko.applyBindings(vm);
initializeCharts();
Knockout.JS is a JavaScript MVVM framework tool which gives you all you need to create bi-directional binding between the view and the view model, where you can encapsulate and unit test all your logic. KoExtensions adds a binding call "histogram", which takes simple array and draws a histogram. In order to show the probability function and the outliers one has to set the options of the chart as shown in the example above.