I am trying to generate sequences containing only 0's and 1's. I have written the following code, and it works.
import numpy as np
batch = 1000
dim = 32
while 1:
is_same = False
seq = np.random.randint(0, 2, [batch, dim])
for i in range(batch):
for j in range(i + 1, batch):
if np.array_equal(seq[i], seq[j]):
is_same = True
if is_same:
continue
else:
break
My batch variable is in the thousands. This loop above takes about 30 seconds to complete. This is a data generation part of another for loop that runs for about 500 iterations and is therefore extremely slow. Is there a faster way to generate this list of sequences without repetition? Thanks.
The desired result is a collection of batch_size number of sequences each of length dim containing only 0s and 1s such that no two sequences in the collection are the same.
2 Answers 2
Generating all sequences and then checking if they are unique can be quite expensive, as you noticed. Consider this alternative approach:
- Generate one sequence
- Convert it to a tuple and add it to a set
- If the set is of size
batch_sizereturn it, else go to step 1
This approach can be implemented like this:
def unique_01_sequences(dim, batch_size):
sequences = set()
while len(sequences) != batch_size:
sequences.add(tuple(np.random.randint(0, 2, dim)))
return sequences
Running the two solutions for dim=32 and batch_size=1000:
Original: 2.296s
Improved: 0.017s
Note: the result of the function I suggested is a set of tuples, but it can be converted to the format you prefer.
A few other suggestions and considerations:
- Functions: consider to encapsulate the code in a function, it is easier to reuse and test.
- Exit condition: this part:
Can be simplified to:if is_same: continue else: breakif not is_same: break - binary vs integer sequence: probably you know it, but the result is a "sequence" of integers, not a binary sequence as the title says.
- Collisions: the suggested approach can become very slow for some configurations of
dimandbatch_size. For example, if the input isdim=10andbatch_size=1024the result contains all configurations of 10 "bits", which are the binary representations of the numbers from 0 to 1023. During the generation, as the size of the setsequencesgrows close to 1024, the number of collisions increases, slowing down the function. In these cases, generating all configurations (as numbers) and shuffling them would be more efficient. - Edge case: for
dim=10andbatch_size=1025the function never ends. Consider to validate the input.
-
1\$\begingroup\$ Set! I totally forgot about set. Thanks! +1. \$\endgroup\$learner– learner2021年01月12日 11:12:23 +00:00Commented Jan 12, 2021 at 11:12
-
1\$\begingroup\$ @learner I am glad I could help. FYI I added a couple of considerations regarding collisions and edge cases. \$\endgroup\$Marc– Marc2021年01月12日 14:09:01 +00:00Commented Jan 12, 2021 at 14:09
As noted in the other answer by @Marc, generating a random sample and then throwing all of it away if there are any duplicates is very wasteful and slow. Instead, you can either use the built-in set, or use np.unique. I would also use the slightly faster algorithm of generating multiple tuples at once and then deduplicating, checking how many are missing and then generating enough tuples to have enough assuming there are now duplicates and then repeating it.
def random_bytes_numpy(dim, n):
nums = np.unique(np.random.randint(0, 2, [n, dim]), axis=1)
while len(nums) < n:
nums = np.unique(
np.stack([nums, np.random.randint(0, 2, [n - len(nums), dim])]),
axis=1
)
return nums
Here is an alternative way using a set but the same algorithm, generating always exactly as many samples as are needed assuming no duplicates:
def random_bytes_set(dim, n):
nums = set()
while len(nums) < n:
nums.update(map(tuple, np.random.randint(0, 2, [n - len(nums), dim])))
return nums
And here is a comparison of the time they take for increasing batch_sizeat fixed dim=32, including the function by @Marc and yours:
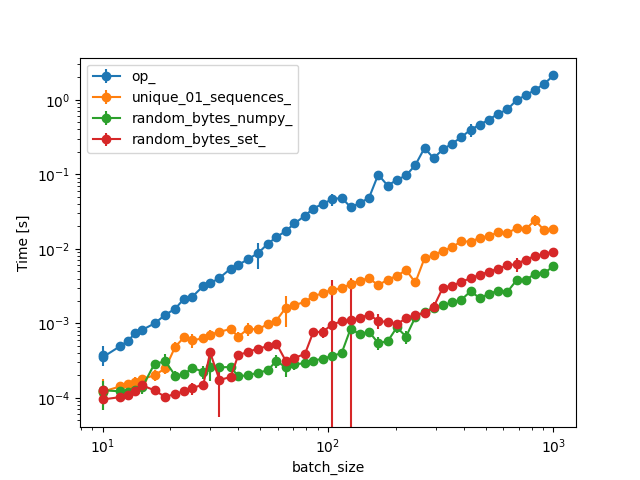{kind=link}
And for larger values of batch_size, without your algorithm, since it takes too long:
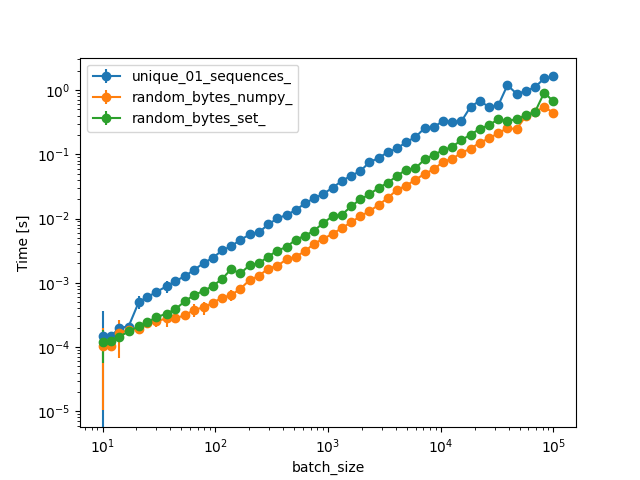{kind=link}
-
\$\begingroup\$ Thank you so much. I guess my method was the worst way to achieve what I wanted to achieve. \$\endgroup\$learner– learner2021年01月12日 16:41:13 +00:00Commented Jan 12, 2021 at 16:41
-
1\$\begingroup\$ @learner Well, I'm sure there are worse ways to solve this problem ;) But look at the bright side, your code at least solved the problem, and you now learned how to solve it in other (faster) ways. And to use functions. \$\endgroup\$Graipher– Graipher2021年01月13日 11:57:17 +00:00Commented Jan 13, 2021 at 11:57