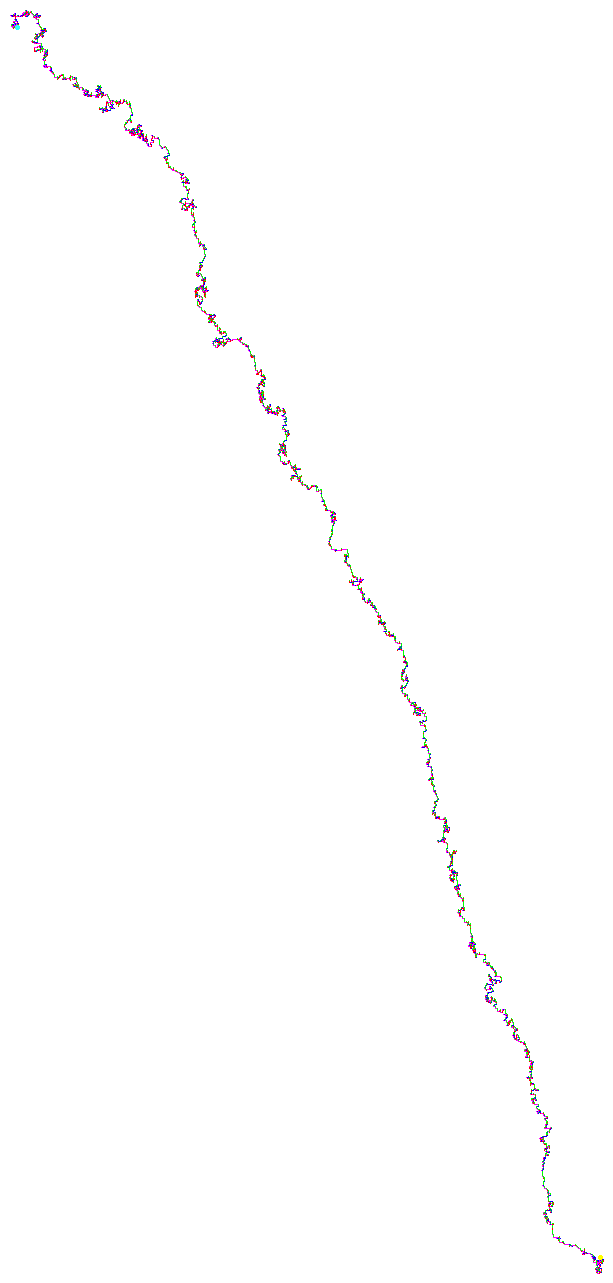
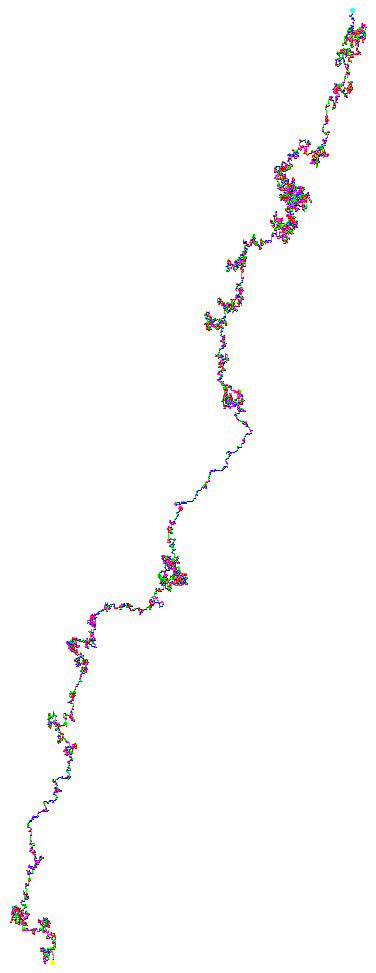
Inspired by this reddit post, I have written a program that accepts a DNA sequence (in a FASTA file format) and generates a graphical representation. HIV virus Ebola virus
{kind=link}
{kind=link}
HIV virus and Ebola virus
My program works like this:
- Accept and parse input file
- Break input file into array (using custom array class
largearray.Array()) - Iterate through and parse that to construct a path, which is stored in another
largearray.Arraythat contains the coordinates and colour for each pixel on the path - Create an image and draw the path onto it
- Save the image
I have posted here previously, asking for help with optimizing steps 1-4. Graipher helped me with his optimized version of my array class. I'm now able to handle very large input files, but I've hit another bottleneck in regards to how large an image PIL can create. (Step 4)
An input file that is larger than roughly 450 MB creates images that are apparently too large to handle. PIL runs into a MemoryError in the PIL.Image.new() function. That isn't surprising considering that the program attempts to create images with dimensions in excess of 100,000 pixels with larger files.
Traceback (most recent call last):
File ".\genome-imager.py", line 113, in <module>
with Image.new("RGBA", dim, None) as img:
File "C:\Program Files\Python3\lib\site-packages\PIL\Image.py", line 2291, in new
return Image()._new(core.new(mode, size))
MemoryError
I've spent a lot of time thinking of a solution, and the one I've come up with is splitting the output image into chunks/quadrants, drawing the path onto each chunk individually and then stitching them together. I've spent some time attempting to do this, but I can't find something that works and my lack of experience is a hindrance.
If anyone has any tips or solutions on how I could overcome this bottleneck I'd greatly appreciate it. My goal is to overcome the 400 mb barrier and move on to genomes larger than a GB. Perhaps the human genome sometime in the future.
Usage (RUN WITH PYTHON x64!):
python3 genome-imager.py path/to/file
Several example input files and their results can be found here. Read contents.txt for more information and which genomes run into the error.
Important:
This program creates very large temp files (~100mb each) and may dump up to 15 GB (or more) per run. The image files also end up being quite large (~100-200 MB). Make sure you have enough space. These temp files are cleaned up at the end of the program if it progresses to completion, but some of them aren't deleted if the program halts mid way. Remember to delete them!
This program also quite intensive
Code:
genome-imager.py
#!/usr/bin/env python3
# Python3
#
# Run from command line
#
import logging
from argparse import ArgumentParser
from copy import deepcopy, copy
from datetime import timedelta
from math import ceil
from os import remove, makedirs
from os.path import exists
from re import sub
from time import time
from PIL import Image, ImageDraw
from largearray import Array
uuid = id(time())
parser = ArgumentParser()
parser.add_argument("file", help="Location of input file. path/to/file (FASTA file formats supported)")
parser.add_argument("-i", "--image-name",
help="Where to save finished image file. path/to/file (Default: Name_of_input_file.png)")
parser.add_argument("-s", "--dump-size", help="The size of temp files to dump to disk. (Default & Max: 5)", type=int)
parser.add_argument("-t", "--temp", help="Where to dump temp files. path/to/directory/ (Default: .cache/)", type=str)
parser.add_argument("-d", "--debug-file", help="Where to store debug file. path/to/file (Default ./cache/debug.log")
args = parser.parse_args()
filepath = args.file
ipath = ".".join(filepath.split(".")[:-1]) + ".png"
if args.image_name:
ipath = args.image_name
print(ipath)
dsize = 5
if args.dump_size:
dsize = args.dump_size
cachedir = ".cache/"
if args.temp:
cachedir = args.temp
debugpath = '.cache/debug%d.log' % uuid
if args.debug_file:
debugpath = args.debug_file
if not exists(filepath):
raise Exception("Path of input file does not exist")
print("Debug at %s" % debugpath)
if exists(debugpath):
remove(debugpath)
if not exists(cachedir):
makedirs(cachedir)
logging.basicConfig(filename=debugpath, level=logging.DEBUG)
logging.info("Init: %d" % uuid)
del parser, ArgumentParser, remove, exists,
print("Generating vizualization of %s" % filepath)
starttime = time()
file = open(filepath, 'r')
logging.info("File opened")
logging.info("Serializing %s ..." % filepath)
raw = ''.join([n for n in file.readlines() if not n.startswith('>')]).replace('\n', "").lower()
logging.info("Replaced FASTA info")
file.close()
del file
raw = sub(r'[rykmswbdhv-]', "n", raw) # Handles miscellaneous FASTA characters
raw = sub(r'[^atgcn]', "", raw) # Handles 4 bases and not-known
sequence = Array(name="sequence", cachedirectory=cachedir, a=list(raw), maxitems=(dsize * 10))
sequence.trim()
logging.info("Parsed characters (%d items)" % len(sequence))
del sub, raw
endtime = [time()]
print("The input file has been serialized. %s (%d items) Calculating path..." % (
str(timedelta(seconds=(endtime[0] - starttime))), len(sequence)))
action = { # The different bases and their respective colours and movements
"a": ((0, 255, 0), 0, -1), # green - Moves up
"t": ((255, 0, 0), 0, 1), # red - Moves Down
"g": ((255, 0, 255), -1, 0), # hot pink - Moves Left
"c": ((0, 0, 255), 1, 0), # blue - Moves Right
"n": ((0, 0, 0), 0, 0), # black - Stays on spot
}
maxp = [[0, 0], [0, 0]] # Top left and bottom right corners of completed path
curr = [0, 0]
pendingactions = Array(name="pendingactions", cachedirectory=cachedir, maxitems=dsize)
logging.info("%d temp files will be created [pendingactions]" % ceil(len(sequence) / pendingactions.maxitems))
for i in sequence:
# get the actions associated from dict
curr[0] += action[i][1]
curr[1] += action[i][2]
if curr[0] > maxp[0][0]:
maxp[0][0] = curr[0]
elif curr[0] < maxp[1][0]:
maxp[1][0] = curr[0]
if curr[1] > maxp[0][1]:
maxp[0][1] = curr[1]
elif curr[1] < maxp[1][1]:
maxp[1][1] = curr[1]
pendingactions.append((copy(curr), action[i][0]))
pendingactions.trim()
del sequence.a
del sequence, copy, deepcopy
# Final dimensions of image + 10px border
dim = (abs(maxp[0][0] - maxp[1][0]) + 20, abs(maxp[0][1] - maxp[1][1]) + 20)
endtime.append(time())
print("The path has been calculated. %s Rendering image... %s" % (
str(timedelta(seconds=(endtime[1] - starttime))), "(" + str(dim[0]) + "x" + str(dim[1]) + ")"))
with Image.new("RGBA", dim, None) as img:
logging.info("Initial image created. (%d x %d)" % (dim[0], dim[1]))
draw = ImageDraw.Draw(img)
logging.info("Draw object created")
for i in pendingactions:
draw.point((i[0][0] + abs(maxp[1][0]) + 10, i[0][1] + abs(maxp[1][1]) + 10), fill=i[1])
logging.info("Path Drawn")
def mean(n): # I couldn't find an average function in base python
s = float(n[0] + n[1]) / 2
return s
# Start and End points are dynamically sized to the dimensions of the final image
draw.ellipse([((abs(maxp[1][0]) + 10) - ceil(mean(dim) / 500), (abs(maxp[1][1]) + 10) - ceil(mean(dim) / 500)),
((abs(maxp[1][0]) + 10) + ceil(mean(dim) / 500), (abs(maxp[1][1]) + 10) + ceil(mean(dim) / 500))],
fill=(255, 255, 0), outline=(255, 255, 0)) # yellow
draw.ellipse([((curr[0] + abs(maxp[1][0]) + 10) - ceil(mean(dim) / 500),
(curr[1] + abs(maxp[1][1]) + 10) - ceil(mean(dim) / 500)), (
(curr[0] + abs(maxp[1][0]) + 10) + ceil(mean(dim) / 500),
(curr[1] + abs(maxp[1][1]) + 10) + ceil(mean(dim) / 500))], fill=(51, 255, 255),
outline=(51, 255, 255)) # neon blue
logging.info("Start and End points drawn")
del pendingactions.a
del maxp, curr, mean, dim, draw, ImageDraw, pendingactions
endtime.append(time())
print("The image has been rendered. %s Saving..." % str(timedelta(seconds=(endtime[2] - endtime[1]))))
img.save(ipath, "PNG", optimize=True)
logging.info("Image saved at %s" % ipath)
endtime.append(time())
del img, Image
print("Done! %s Image is saved as: %s" % (str(timedelta(seconds=(endtime[3] - endtime[2]))), ipath))
print("Program took %s to run" % str(timedelta(seconds=(endtime[3] - starttime))))
logging.info("%s | %s | %s | %s # Parsing File | Computing Path | Rendering | Saving" % (
str(timedelta(seconds=(endtime[0] - starttime))), str(timedelta(seconds=(endtime[1] - starttime))),
str(timedelta(seconds=(endtime[2] - starttime))), str(timedelta(seconds=(endtime[3] - starttime)))))
largearray.py
#!/usr/bin/env python3
# Python3
#
# Simple array class that dynamically saves temp files to disk to conserve memory
#
import logging
import pickle
from datetime import timedelta
from itertools import islice
from os import makedirs, remove
from os.path import exists
from shutil import rmtree
from time import time
startime = time()
logging.getLogger(__name__).addHandler(logging.NullHandler())
class Array():
"""1D Array class
Dynamically saves temp files to disk to conserve memory"""
def __init__(self, name="Array", cachedirectory=".cache/", a=None, maxitems=1):
# How much data to keep in memory before dumping to disk
self.maxitems = int(maxitems*1e6)
self.fc = 0 # file counter
self.uuid = id(self)
self.name = name
logging.debug("[largearray.Array] Instance %d %s created | %s" % (self.uuid, self.name, str(timedelta(seconds=time()-startime))))
self.dir = cachedirectory + str(self.uuid) # make a unique subfolder (unique as long as the array exists)
if exists(self.dir):
rmtree(self.dir)
makedirs(self.dir)
logging.debug("[largearray.Array] Instance %d caches in %s with %d items per file" % (self.uuid, self.dir, self.maxitems))
self.path = self.dir + "/temp%d.dat" # Name of temp files
self.hastrim = False
self.a = []
if a is not None:
self.extend(a)
def append(self, n):
"""Append n to the array.
If size exceeds self.maxitems, dump to disk
"""
if self.hastrim:
raise Exception("ERROR: Class [array] methods append() and extend() cannot be called after method trim()")
else:
self.a.append(n)
if len(self.a) >= self.maxitems:
logging.debug("[largearray.Array] Instance %d dumps temp %d | %s" % (self.uuid, self.fc, str(timedelta(seconds=time()-startime))))
with open(self.path % self.fc, 'wb') as pfile:
pickle.dump(self.a, pfile) # Dump the data
self.a = []
self.fc += 1
def trim(self):
"""If there are remaining values in the array stored in memory, dump them to disk (even if there is less than maxitems.
NOTE: Only run this after all possible appends and extends have been done
WARNING: This cannot be called more than once, and if this has been called, append() and extend() cannot be called again"""
if len(self.a) > 0:
if self.hastrim:
raise Exception("ERROR: Class [array] method trim() can only be called once")
else:
self.hastrim = True
self.trimlen = len(self.a)
logging.debug("[largearray.Array] Instance %d trims temp %d | %s" % (self.uuid, self.fc, str(timedelta(seconds=time()-startime))))
with open(self.path % self.fc, 'wb') as pfile:
pickle.dump(self.a, pfile) # Dump the data
self.a = []
self.fc += 1
def extend(self, values):
"""Convenience method to append multiple values"""
for n in values:
self.append(n)
def __iter__(self):
"""Allows iterating over the values in the array.
Loads the values from disk as necessary."""
for fc in range(self.fc):
logging.debug("[largearray.Array] Instance %d iterates temp %d | %s" % (self.uuid, fc, str(timedelta(seconds=time()-startime))))
with open(self.path % fc, 'rb') as pfile:
yield from pickle.load(pfile)
yield from self.a
def __repr__(self):
"""The values currently in memory"""
s = "[..., " if self.fc else "["
return s + ", ".join(map(str, self.a)) + "]"
def __getitem__(self, index):
"""Get the item at index or the items in slice.
Loads all dumps from disk until start of slice for the latter."""
if isinstance(index, slice):
return list(islice(self, index.start, index.stop, index.step))
else:
fc, i = divmod(index, self.maxitems)
with open(self.path % fc, 'rb') as pfile:
return pickle.load(pfile)[i]
def __len__(self):
"""Length of the array (including values on disk)"""
if self.hastrim:
return (self.fc-1) * self.maxitems + self.trimlen
return self.fc * self.maxitems + len(self.a)
def __delattr__(self, item):
"""Calling del <object name>.a
will delete entire array"""
if item == 'a':
super().__delattr__('a')
rmtree(self.dir)
logging.debug("[largearray.Array] Instance %d deletes all array data | %s" % (self.uuid, str(timedelta(seconds=time()-startime))))
else:
super(Array, self).__delattr__(item)
def __setitem__(self, key, value):
if isinstance(key, slice):
l = list(islice(self, key.start, key.stop, key.step))
for i in l:
l[i].__setitem__(value)
set()
else:
fc, i = divmod(key, self.maxitems)
with open(self.path % fc, 'rb') as pfile:
l = pickle.load(pfile)
l[i] = value
remove(self.path % fc)
with open(self.path % fc, 'wb') as pfile:
pickle.dump(l, pfile)
def __delitem__(self, key):
fc, i = divmod(key, self.maxitems)
with open(self.path % fc, 'rb') as pfile:
l = pickle.load(pfile)
del l[i]
remove(self.path % fc)
with open(self.path % fc, 'wb') as pfile:
pickle.dump(l, pfile)
2 Answers 2
Parser
Your parser has a bug in line 62:
raw = ''.join([n for n in file.readlines() if not n.startswith('>')]).replace('\n', "").lower()
will concatenate all sequences, despite them potentially belonging to different DNA Sequences. Here is Wikipedia (the best source to cite xD):
A multiple sequence FASTA format would be obtained by concatenating several single sequence FASTA files. This does not imply a contradiction [...] hence forcing all subsequent sequences to start with a ">" [...].
You also don't respect the header (;) either. Further
Sequences may be protein sequences or nucleic acid sequences
Now my biology is lacking at best. I assume you are not respecting that because you can make the assumption to only ever deal with nucleic acids in DNA? Hence you ignore checking for that?
You seem to further seem to be able to reduce this to only A C G N T which I guess also has some very sound biological reason that I don't know.
This will probably blow up if you aren't careful what files you put in.
Large Array
There is multiple optimizations you could do, but only 1 that really makes sense here: Bin it. You don't need it.
You pre-compute a lot of information that you reuse exactly once and that you can compute on-the-fly. There is no benefit in having this. In fact, you are making it worse by reading the .fna once and then reading the array version of it, which is 40+ times bigger. Not cool :D
The short version of it is that largearray is wrapping python list()s which store 5-tupels (x,y,r,g,b) worth 40 byte per entry. strawberry.fna takes ~8.5 GB to represent in this format, whereas you can instead stick to a single character worth 1 byte and look-up the (r,g,b) value as well as compute (x,y) using the predecesor (which you know). This will save 40(!) times the disk/memory space (down to200 MB after optimization).
Here is a version that uses largearray, but saves only a character (worth 1 byte) instead of the tupel (40 byte): https://gist.github.com/FirefoxMetzger/9cfdf91f9b838f755d8ae68ab2a52ac8
I've also added numpy as dependency and refactored your code (a lot) because I couldn't make heads and tails of it.
Here is an even shorter version that no longer needs largearray:
https://gist.github.com/FirefoxMetzger/95b4f30fee91a21ab376cd4db9ccce42
I also removed the timing comments, because that can be done more efficiently with cProfile or another profiler of your choice. In this scenario, I felt like the prints obstructed the code a lot; now it's easier to read. If a blinking cursor with no output irritates you, feel free to add more prints (at the cost of readability and a tiny bit of runtime).
Output
I've ran the strawberry.fna and it tried to create a 94980x100286 image. That's ~9.5 Gpx (Gigapixel)! 29.5 GB as an uncompressed image is no fun. At least on my machine it doesn't fit into memory uncompressed. Similarly, if I look at your strawberry.png it doesn't seem to open correctly; I only get a reddish shadow.
On your machine (assuming you have a bigger one, since you can apparently fit 30+GB into memory without issues) you might get more out of this.
Fortunately most of these pixels are empty / transparent. In fact for strawberry.fna only 2.2% of the pixels are not transparent. Potentially even less, because I've noticed that they sometimes overlap, e.g. a "GC" sequence would only be visible as "C" sticking out to the side.
My attempt would be to use matplotlib, however that is still fairly slow and known to not cope too well with big data. It runs slightly faster then your initial version and the memory requirements are better; still its not enough for strawberries.fna on my machine. Yet, you get an interactive figure that you can zoom around in and "take screenshots". I like this way to explore the sequence better.
Another advantage is that you can specify file format and viewport, legends, axis and so forth.
Here is the code for that:
#!/usr/bin/env python3
# Python3
import logging
from argparse import ArgumentParser
from os import remove
from os.path import exists
from re import sub
from time import time
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.collections import LineCollection
uuid = id(time())
parser = ArgumentParser()
parser.add_argument("file", help="Location of input file. path/to/file (FASTA file formats supported)")
parser.add_argument("-d", "--debug-file", help="Where to store debug file. path/to/file (Default ./cache/debug.log")
args = parser.parse_args()
filepath = args.file
if not exists(filepath):
raise Exception("Path of input file does not exist")
debugpath = '.cache/debug%d.log' % uuid
if args.debug_file:
debugpath = args.debug_file
if exists(debugpath):
remove(debugpath)
logging.basicConfig(filename=debugpath, level=logging.DEBUG)
logging.info("Init: %d" % uuid)
with open(filepath, 'r') as file:
logging.info("Serializing %s ..." % filepath)
raw = ''.join([n for n in file.readlines() if not n.startswith('>')]).replace('\n', "").lower()
raw = sub(r'[rykmswbdhv-]', "n", raw) # Handles miscellaneous FASTA characters
raw = sub(r'[^atgcn]', "", raw) # Remove everything except 4 bases and not-known
test_length = min(5e6, len(raw))
print("Processing %d elements. Have fun waiting! I'll go grab a coffee"
% test_length)
action_lookup = {
"a": np.array((0, -1)),
"t": np.array((0, 1)),
"g": np.array((-1, 0)),
"c": np.array((1, 0)),
"n": np.array((0, 0))
}
color_lookup = {
"a": (0, 1, 0),
"t": (1, 0, 0),
"g": (1, 0, 1),
"c": (0, 0, 1),
"n": (0, 0, 0)
}
fig, ax = plt.subplots()
lines = np.zeros((int(test_length), 2, 2), dtype=np.int16)
colors = list()
cursor = np.array((0, 0))
old_cursor = cursor.copy()
for idx, base in enumerate(raw):
if idx >= test_length:
break
# get the actions associated from dict
cursor += action_lookup[base]
lines[idx, 0, :] = old_cursor
lines[idx, 1, :] = cursor
colors.append(color_lookup[base])
old_cursor = cursor.copy()
print("Done gathering data - plotting now")
linesegments = LineCollection(
lines,
colors=colors
)
ax.add_collection(linesegments)
plt.plot()
plt.show()
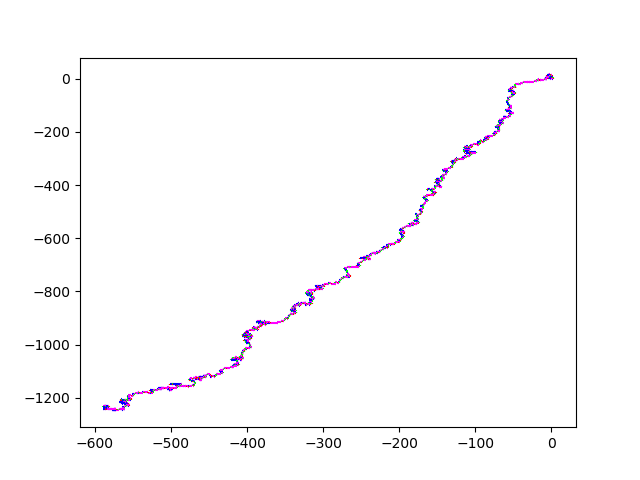
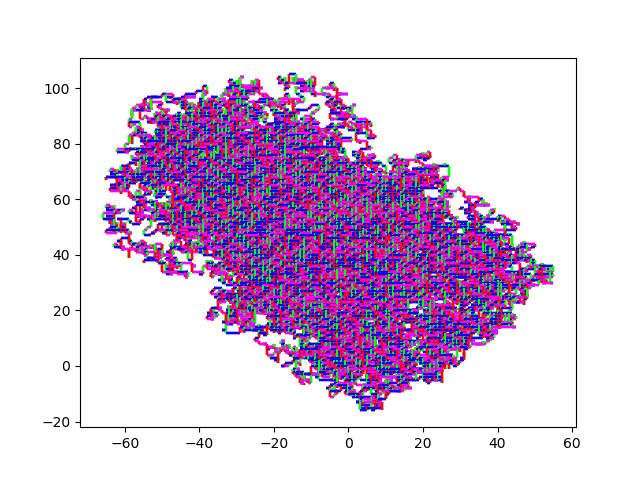
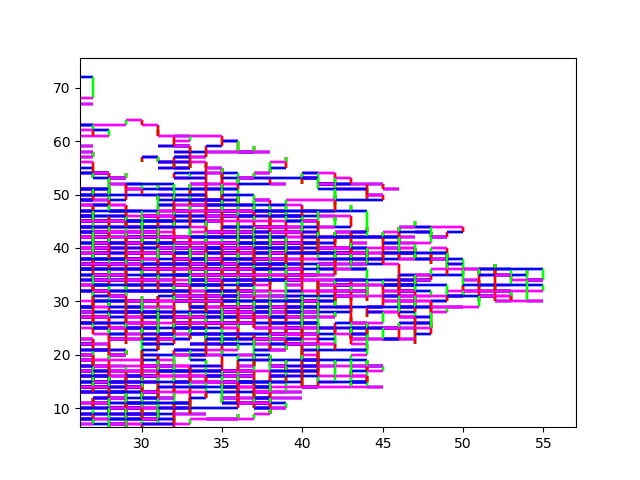
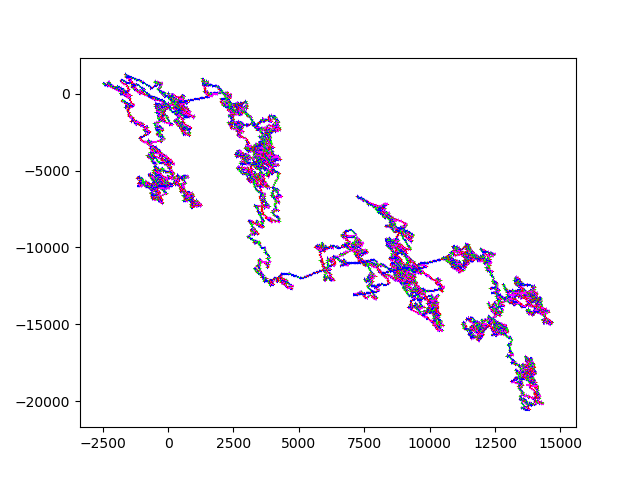
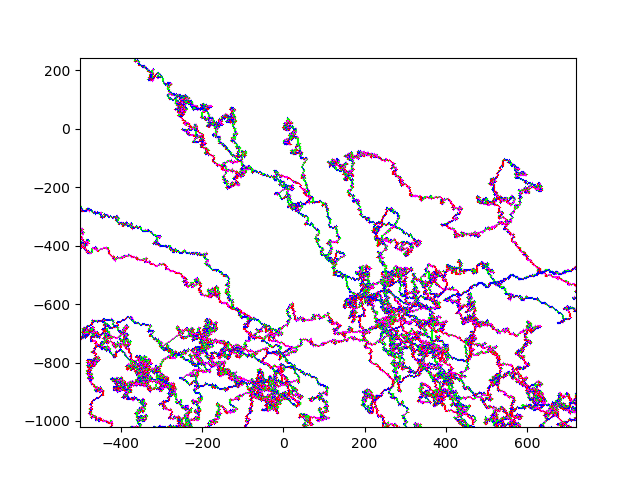
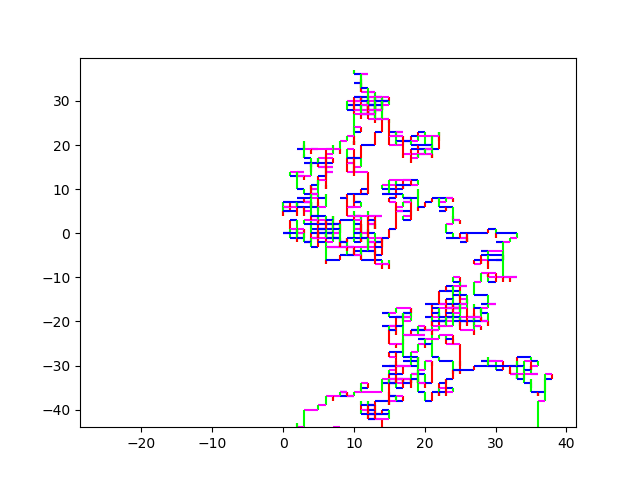
And here some sexy images. (They always start at (0,0)). HIV.fna: hiv.fna random2.fna: random2.fna Demonstrating the crop/zoom-ability on random2: Crop of Random2.fna
{kind=link}
{kind=link}
{kind=link}
I can also limit the amount of elements processed. That way I can visualize the first 10 million elements of strawberry.fna. I find this visualization to be of limited use, but I guess it makes more sense to you?
10M Strawberry.fna A zoom in on (0,0): Strawberry zoom And an even more useful / useless zoom onto (0,0): Even more Zoom
{kind=link}
{kind=link}
{kind=link}
-
\$\begingroup\$ Firstly thanks for your really detailed and well thought out answer. I've taken many of the things you've suggested on board and I'm working on rewriting my code inline with them. Your suggestions about switching from raster images to matplotlib are especially useful because they've given me some great ideas for displaying my data more efficiently and in a more readable format. Instead of using matplotlib, however, I'm attempting to see if I can adapt my program for plotly.py because of it's interactivity I'll get back to you if I succeed. Again, thanks for your help, I really appreciate it. \$\endgroup\$logwet– logwet2018年04月16日 07:13:03 +00:00Commented Apr 16, 2018 at 7:13
More beautiful loop
In the for i in sequence loop, you could get rid of many accesses with []:
color, dx, dy = action[i]to accessaction[i]only once and use tuple unpacking to avoid the access of elements 1 and 2- use
cur_xandcur_yinstead ofcurr(this also removes the need forcopy) - use
max/minbuiltin - define 4 variables instead of
maxp
You get something like:
max_x, max_y, min_x, min_y = 0, 0, 0, 0
cur_x, cur_y = [0, 0]
pendingactions = []
for i in sequence:
color, dx, dy = action[i]
cur_x += dx
cur_y += dy
max_x = max(cur_x, max_x)
min_x = min(cur_x, min_x)
max_y = max(cur_x, max_y)
min_y = min(cur_x, min_y)
pendingactions.append(([cur_x, cur_y], color))
Alternatively, you could get the min/max values by calling min/max on the final array.
The same logic applies in many places in your code.
Times measures
Instead of having:
starttime = time()
...
endtime = [time()]
...str(timedelta(seconds=(endtime[0] - starttime)))
...
endtime.append(time())
...str(timedelta(seconds=(endtime[3] - endtime[2]))
...str(timedelta(seconds=(endtime[3] - starttime)))
Which needs indices to be updated if you add a partial time, you could:
- save all the time measures including the first one in the array
- rely on the
[-1]access to get the last element.
The fake snipper above becomes (/!\untested)
times = [time()]
...
times.append(time())
...str(timedelta(seconds=(times[-1] - times[0])))
...
times.append(time())
...str(timedelta(seconds=(times[-1] - times[-2])))
...str(timedelta(seconds=(times[-1] - times[0])))
Use the translation tools from Python instead of regexp
Instead of regexp, maybe you could use [maketrans] to handle the character conversions. It may be faster, it may be slower, I'm haven't performed any benchmark...
Magic numbers
You have many magic numbers in your code: using "constants" for this would help to make your code easier to read by having a meaningful name but also easier to maintain by changing values in a single place if need be.
You must log in to answer this question.
Explore related questions
See similar questions with these tags.
94980x100286pixel image for thestrawberry.fna. That's 2862 8K screens worth of information. I guess your idea is to be able to "zoom out" and see the entire structure while still knowing the details? \$\endgroup\$rice.fnaandred_rice.fna. Red rice is an ancestor of rice. By zooming in and looking at particular sections, I can observe similarities and shared patterns that hint to their shared evolutionary history. \$\endgroup\$