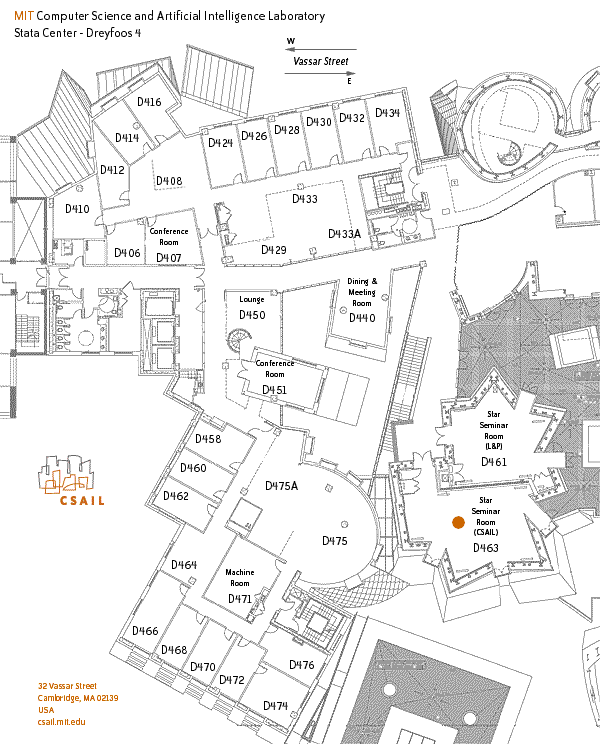
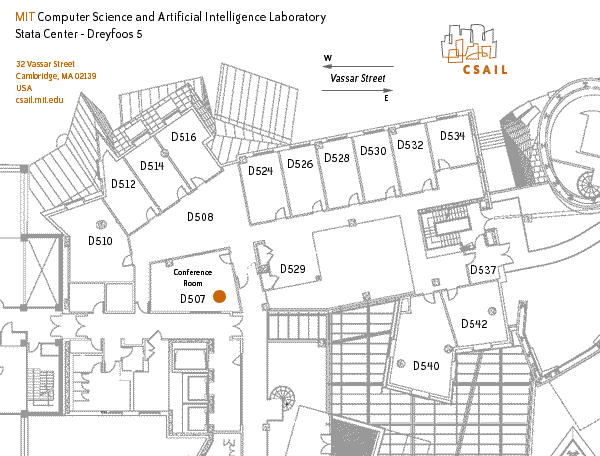
Visual Computing Seminar: 3D Symmetric Tensor Field Topology
Oregon State University
12:00P
- 1:00P
{kind=link}
Add to Calendar
2025年10月14日 12:00:00
2025年10月14日 13:00:00
America/New_York
Visual Computing Seminar: 3D Symmetric Tensor Field Topology
Abstract:3D symmetric tensor fields are the central object of study in many scientific, engineering, and medical domains. The topological structures in a 3D symmetric tensor field such as the stress and strain tensors in solid mechanics, the rate of deformation tensor in fluid dynamics, and the diffusion tensor from medical imagining have the potential of providing complementary information regarding the underlying physics than the point-based analysis. In this talk, I will cover the research on 3D symmetric tensor field topology by our research group during the last decade years, including robust extraction of topological features in such a field as well as the interaction among various topological features which leads to a graph-based representation that captures the global topology of our tensor fields.
TBD
{kind=link}
{kind=link}
{kind=link}
{kind=link}