(inspired by this challenge over on Puzzling -- SPOILERS for that puzzle are below, so stop reading here if you want to solve that puzzle on your own!)
If a letter in a word occurs alphabetically later than the previous letter in the word, we call that a rise between the two letters. Otherwise, including if it's the same letter, it's called a fall.
For example, the word ACE has two rises (A to C and C to E) and no falls, while THE has two falls (T to H and H to E) and no rises.
We call a word Bumpy if the sequence of rises and falls alternates. For example, BUMP goes rise (B to U), fall (U to M), rise (M to P). Note that the first sequence need not be a rise -- BALD goes fall-rise-fall and is also Bumpy.
The challenge
Given a word, output whether or not it's Bumpy.
Input
- A word (not necessarily a dictionary word) consisting of ASCII alphabet (
[A-Z]or[a-z]) letters only, in any suitable format. - Your choice if the input is all uppercase or all lowercase, but it must be consistent.
- The word will be at least 3 characters in length.
Output
A truthy/falsey value for whether the input word is Bumpy (truthy) or not Bumpy (falsey).
The Rules
- Either a full program or a function are acceptable.
- Standard loopholes are forbidden.
- This is code-golf so all usual golfing rules apply, and the shortest code (in bytes) wins.
Examples
Truthy:
ABA
ABB
BAB
BUMP
BALD
BALDY
UPWARD
EXAMINATION
AZBYCXDWEVFUGTHSIRJQKPLOMN
Falsey:
AAA
BBA
ACE
THE
BUMPY
BALDING
ABCDEFGHIJKLMNOPQRSTUVWXYZ
Leaderboards
Here is a Stack Snippet to generate both a regular leaderboard and an overview of winners by language.
To make sure that your answer shows up, please start your answer with a headline, using the following Markdown template:
# Language Name, N bytes
where N is the size of your submission. If you improve your score, you can keep old scores in the headline, by striking them through. For instance:
# Ruby, <s>104</s> <s>101</s> 96 bytes
If there you want to include multiple numbers in your header (e.g. because your score is the sum of two files or you want to list interpreter flag penalties separately), make sure that the actual score is the last number in the header:
# Perl, 43 + 2 (-p flag) = 45 bytes
You can also make the language name a link which will then show up in the leaderboard snippet:
# [><>](http://esolangs.org/wiki/Fish), 121 bytes
var QUESTION_ID=93005,OVERRIDE_USER=42963;function answersUrl(e){return"https://api.stackexchange.com/2.2/questions/"+QUESTION_ID+"/answers?page="+e+"&pagesize=100&order=desc&sort=creation&site=codegolf&filter="+ANSWER_FILTER}function commentUrl(e,s){return"https://api.stackexchange.com/2.2/answers/"+s.join(";")+"/comments?page="+e+"&pagesize=100&order=desc&sort=creation&site=codegolf&filter="+COMMENT_FILTER}function getAnswers(){jQuery.ajax({url:answersUrl(answer_page++),method:"get",dataType:"jsonp",crossDomain:!0,success:function(e){answers.push.apply(answers,e.items),answers_hash=[],answer_ids=[],e.items.forEach(function(e){e.comments=[];var s=+e.share_link.match(/\d+/);answer_ids.push(s),answers_hash[s]=e}),e.has_more||(more_answers=!1),comment_page=1,getComments()}})}function getComments(){jQuery.ajax({url:commentUrl(comment_page++,answer_ids),method:"get",dataType:"jsonp",crossDomain:!0,success:function(e){e.items.forEach(function(e){e.owner.user_id===OVERRIDE_USER&&answers_hash[e.post_id].comments.push(e)}),e.has_more?getComments():more_answers?getAnswers():process()}})}function getAuthorName(e){return e.owner.display_name}function process(){var e=[];answers.forEach(function(s){var r=s.body;s.comments.forEach(function(e){OVERRIDE_REG.test(e.body)&&(r="<h1>"+e.body.replace(OVERRIDE_REG,"")+"</h1>")});var a=r.match(SCORE_REG);a&&e.push({user:getAuthorName(s),size:+a[2],language:a[1],link:s.share_link})}),e.sort(function(e,s){var r=e.size,a=s.size;return r-a});var s={},r=1,a=null,n=1;e.forEach(function(e){e.size!=a&&(n=r),a=e.size,++r;var t=jQuery("#answer-template").html();t=t.replace("{{PLACE}}",n+".").replace("{{NAME}}",e.user).replace("{{LANGUAGE}}",e.language).replace("{{SIZE}}",e.size).replace("{{LINK}}",e.link),t=jQuery(t),jQuery("#answers").append(t);var o=e.language;/<a/.test(o)&&(o=jQuery(o).text()),s[o]=s[o]||{lang:e.language,user:e.user,size:e.size,link:e.link}});var t=[];for(var o in s)s.hasOwnProperty(o)&&t.push(s[o]);t.sort(function(e,s){return e.lang>s.lang?1:e.lang<s.lang?-1:0});for(var c=0;c<t.length;++c){var i=jQuery("#language-template").html(),o=t[c];i=i.replace("{{LANGUAGE}}",o.lang).replace("{{NAME}}",o.user).replace("{{SIZE}}",o.size).replace("{{LINK}}",o.link),i=jQuery(i),jQuery("#languages").append(i)}}var ANSWER_FILTER="!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe",COMMENT_FILTER="!)Q2B_A2kjfAiU78X(md6BoYk",answers=[],answers_hash,answer_ids,answer_page=1,more_answers=!0,comment_page;getAnswers();var SCORE_REG=/<h\d>\s*([^\n,]*[^\s,]),.*?(\d+)(?=[^\n\d<>]*(?:<(?:s>[^\n<>]*<\/s>|[^\n<>]+>)[^\n\d<>]*)*<\/h\d>)/,OVERRIDE_REG=/^Override\s*header:\s*/i;body{text-align:left!important}#answer-list,#language-list{padding:10px;width:290px;float:left}table thead{font-weight:700}table td{padding:5px}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script> <link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b"> <div id="answer-list"> <h2>Leaderboard</h2> <table class="answer-list"> <thead> <tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr></thead> <tbody id="answers"> </tbody> </table> </div><div id="language-list"> <h2>Winners by Language</h2> <table class="language-list"> <thead> <tr><td>Language</td><td>User</td><td>Score</td></tr></thead> <tbody id="languages"> </tbody> </table> </div><table style="display: none"> <tbody id="answer-template"> <tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr></tbody> </table> <table style="display: none"> <tbody id="language-template"> <tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr></tbody> </table>30 Answers 30
MATL, 4 bytes
d0>d
Explanation:
d % Implicitly take input. Take difference between each element
0> % Check whether diff's are positive. Should result in [0 1 0 1 ...] pattern.
d % Again take the difference. Any consecutive rises or falls results in a
% difference of 0, which is a falsy value in MATL
This is my first MATL entry, so I wonder how much improvement there can be from this naive port from my MATLAB/Octave attempt (which would be @(a)all(diff(diff(a)>0))). Note that the all is not necessary because any zero makes an array false, so there's no A in the MATL port.
-
\$\begingroup\$ See the corrected challenge. There was a typo in a test case. Your approach was correct. In fact,
d0>dshould work (you don't need theAas per our definition of truthy/falsey) \$\endgroup\$Luis Mendo– Luis Mendo2016年09月12日 15:00:41 +00:00Commented Sep 12, 2016 at 15:00 -
1\$\begingroup\$ Nice work, outgolfing Luis in his own language! I've tried before, and that's no easy task. ;) \$\endgroup\$DJMcMayhem– DJMcMayhem2016年09月12日 15:06:38 +00:00Commented Sep 12, 2016 at 15:06
-
\$\begingroup\$ @DJMcMayhem Haha. That's what I get for reading the challenge too quickly. In my defense, it's counter-intuitive that two equal letters are a fall. And the (now corrected) misleading test cases didn't help either :-) \$\endgroup\$Luis Mendo– Luis Mendo2016年09月12日 15:08:32 +00:00Commented Sep 12, 2016 at 15:08
-
1\$\begingroup\$ @DJMcMayhem Thanks - although maybe I just got lucky, because I didn't actually think about consecutive equal letters, but that turned out to be exactly what was asked... \$\endgroup\$Sanchises– Sanchises2016年09月12日 15:14:19 +00:00Commented Sep 12, 2016 at 15:14
-
1
JavaScript (ES6), (削除) 75 (削除ここまで) (削除) 69 (削除ここまで) (削除) 63 (削除ここまで) (削除) 46 (削除ここまで) 43 bytes
Saved 3 bytes thanks to Neil:
f=([c,...s])=>s[1]?c<s[0]^s[0]<s[1]&&f(s):1
Destructuring the string parameter instead of s.slice(1).
Previous solution:
Saved 17 bytes thanks to ETHproductions:
f=s=>s[2]?s[0]<s[1]^s[1]<s[2]&&f(s.slice(1)):1
What happened from the previous solution step by step:
f=(s,i=0,a=s[i++]<s[i])=>s[i+1]&&(b=a^(a=s[i]<s[i+1]))?f(s,i):b // (63) Original
f=(s,i=0,a=s[i++]<s[i])=>s[i+1]&&(b=a^(s[i]<s[i+1]))?f(s,i):b // (61) No point in reassigning `a`, it's not used again
f=(s,i=0,a=s[i++]<s[i])=>s[i+1]&&(b=a^s[i]<s[i+1])?f(s,i):b // (59) Remove unnecessary parentheses
f=(s,i=0)=>s[i+2]&&(b=s[i++]<s[i]^s[i]<s[i+1])?f(s,i):b // (55) `a` is now just a waste of bytes
f=(s,i=0)=>s[i+2]?(b=s[i++]<s[i]^s[i]<s[i+1])?f(s,i):b:1 // (56) Rearrange conditional expressions to allow for more golfing
f=(s,i=0)=>s[i+2]?(b=s[i++]<s[i]^s[i]<s[i+1])&&f(s,i):1 // (55) Rearrange conditional expression
f=(s,i=0)=>s[i+2]?(s[i++]<s[i]^s[i]<s[i+1])&&f(s,i):1 // (53) `b` is now also a waste of bytes
f=(s,i=0)=>s[i+2]?s[i++]<s[i]^s[i]<s[i+1]&&f(s,i):1 // (51) Remove unnecessary parentheses
f=s=>s[2]?s[0]<s[1]^s[1]<s[2]&&f(s.slice(1)):1 // (46) Use `s.slice(1)` instead of `i`
Previous solutions:
63 bytes thanks to ETHproductions:
f=(s,i=0,a=s[i++]<s[i])=>s[i+1]&&(b=a^(a=s[i]<s[i+1]))?f(s,i):b
69 bytes:
f=(s,i=0,a=s[i++]<s[i])=>i+1<s.length&&(b=a^(a=s[i]<s[i+1]))?f(s,i):b
75 bytes:
f=(s,a=s[0]<s[1])=>{for(i=1;i+1<s.length&&(b=a^(a=s[i++]<s[i])););return b}
All letters in a word must have the same case.
-
2\$\begingroup\$ You can golf it down quite a bit further: github.com/ETHproductions/golf/blob/gh-pages/misc/93014.js \$\endgroup\$ETHproductions– ETHproductions2016年09月12日 15:36:12 +00:00Commented Sep 12, 2016 at 15:36
-
\$\begingroup\$ @ETHproductions Should I post the content of your link ? \$\endgroup\$Hedi– Hedi2016年09月12日 16:10:56 +00:00Commented Sep 12, 2016 at 16:10
-
\$\begingroup\$ You can if you'd like :-) \$\endgroup\$ETHproductions– ETHproductions2016年09月12日 16:18:39 +00:00Commented Sep 12, 2016 at 16:18
-
\$\begingroup\$ Can
!s[2]|...do the same ass[2]?...:1? \$\endgroup\$Titus– Titus2016年09月12日 18:20:24 +00:00Commented Sep 12, 2016 at 18:20 -
1\$\begingroup\$ Sorry for being late to the party, but for 43 bytes I give you:
f=([c,...s])=>s[1]?c<s[0]^s[0]<s[1]&&f(s):1\$\endgroup\$Neil– Neil2016年09月16日 08:51:06 +00:00Commented Sep 16, 2016 at 8:51
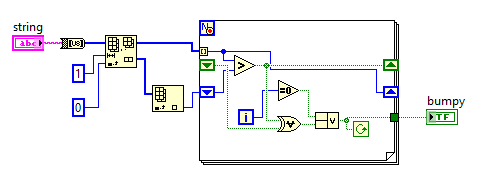
LabVIEW, 36 equivalent bytes
Golfed down using logical equivalences:
{kind=link}
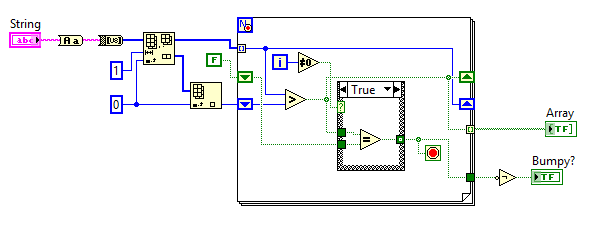
Ungolfed:
{kind=link}
First we convert to lowercase, then to byte array. Trim off the first element of the byte array as it has no precedent. Then, for each element in the array, check if it's greater than the previous one (U8 char maps to ASCII as you expect) and store the result for the next iteration, as well as in an array for viewing overall bumpiness. If the current and prior boolean check are equal, we terminate the loop and it's not bumpy. Else, it's bumpy!
-
1\$\begingroup\$ What a cool language! Welcome to PPCG! \$\endgroup\$DJMcMayhem– DJMcMayhem2016年09月13日 01:31:44 +00:00Commented Sep 13, 2016 at 1:31
-
1\$\begingroup\$ Thanks! I'll never compete with the 4 byte answers, but it's a nice way to improve my skills :) \$\endgroup\$ijustlovemath– ijustlovemath2016年09月13日 01:34:18 +00:00Commented Sep 13, 2016 at 1:34
-
\$\begingroup\$ See here. Your scoring is definitely wrong and overly excessive. I don't think your answer is really 246450 - 246549 bytes. \$\endgroup\$Erik the Outgolfer– Erik the Outgolfer2016年09月13日 12:20:57 +00:00Commented Sep 13, 2016 at 12:20
-
\$\begingroup\$ I was going off the Memory tab, as I didn't know there was a concept of equivalent bytes for LabVIEW. Will count them up and edit answer later today. \$\endgroup\$ijustlovemath– ijustlovemath2016年09月13日 12:23:35 +00:00Commented Sep 13, 2016 at 12:23
-
1\$\begingroup\$ @Erik I'm on Firefox on Windows, but opening it on mobile also breaks things. Just meta.ppcg.lol works. Anyway, this is out of scope for comments. \$\endgroup\$anon– anon2016年09月14日 14:19:12 +00:00Commented Sep 14, 2016 at 14:19
Python, 56 bytes
lambda s:all((x<y)^(y<z)for x,y,z in zip(s,s[1:],s[2:]))
All test cases are at ideone
Zips through triples of characters in s and tests that all such triples have left and right pairs with different rise/fall properties.
Works for either all uppercase or all lowercase.
Ruby, (削除) 57 (削除ここまで) 48 bytes
Expects input to be all uppercase.
->s{!s.gsub(/.(?=(.)(.))/){($&<1ドル)^(1ドル<2ドル)}[?f]}
See it on repl.it: https://repl.it/D7SB
Explanation
The regular expression /.(?=(.)(.))/ matches each character that's followed by two more characters. (?=...) is a positive lookahead, meaning we match the subsequent two characters but don't "consume" them as part of the match. Inside the curly braces, $& is the matched text—the first character of the three—and 1ドル and 2ドル are the captured characters inside the lookahead. In other words, if the string is "BUMPY", it will first match "B" (and put it in $&) and capture "U" and "M" (and put them in 1ドル and 2ドル). Next it will match "U" and capture "M" and "P", and so on.
Inside the block we check if the first pair of characters ($& and 1ドル) is a rise and the second (1ドル and 2ドル) is a fall or vice versa, much like most of the other answers. This ^ expression returns true or false, which gets converted to a string and inserted in place of the match. As a result, our example "BUMPY" becomes this:
"truetruefalsePY"
Since we know the input is all uppercase, we know "f" will only occur as part of "false" and !result[?f] gives us our answer.
-
\$\begingroup\$ How does it work? \$\endgroup\$GreenAsJade– GreenAsJade2016年09月13日 08:44:01 +00:00Commented Sep 13, 2016 at 8:44
-
1\$\begingroup\$ @GreenAsJade I've added an explanation to my answer. \$\endgroup\$Jordan– Jordan2016年09月13日 12:45:04 +00:00Commented Sep 13, 2016 at 12:45
C#, (削除) 64 (削除ここまで) (削除) 63 (削除ここまで) 55 bytes
unsafe bool B(char*s)=>1>s[2]||*s<s[1]!=*++s<s[1]&B(s);
-8 bytes from Scepheo's suggestions
This is a port of Hedi's solution to C#. I also came up with a recursive solution, but the recursion wasn't as good. My original solution is below.
My Original C#, (削除) 96 (削除ここまで) (削除) 94 (削除ここまで) 91 bytes
unsafe bool B(char*s,bool f=1>0,int i=0)=>1>s[1]||(s[0]<s[1]?f:1>i?!(f=!f):!f)&B(s+1,!f,1);
-2 bytes by using 1>0 instead of true.
-3 bytes from Scepheo's suggestions for the port solution above
Calls itself recursively checking that the rising/falling alternates each time.
Ungolfed:
// unsafe in order to golf some bytes from string operations.
// f alternates with each recursive call
// i is 0 for the first call, 1 for all subsequent calls
unsafe bool B(char* s, bool f = 1 > 0, int i = 0) =>
1 > s[1] ? 1 > 0// (instead of 1 == s.Length) check if s[1] = NULL, and return true.
: (
s[0] < s[1] ? f // Rising, so use f...
: // Else falling
1 > i ? !(f=!f) // But this is the first call, so use true (but flip f)...
: !f // Not first call, so use !f...
)
& B(s+1, !f, 1) // ...AND the previous value with a recursive call
// s+1 instead of s.Substring(1)
;
-
\$\begingroup\$ Seems like the last one can do without the
?:operator or parentheses:unsafe bool B(char*s)=>1>s[2]|s[0]<s[1]!=s[1]<s[2]&B(s+1);\$\endgroup\$Scepheo– Scepheo2016年09月13日 13:19:01 +00:00Commented Sep 13, 2016 at 13:19 -
\$\begingroup\$ Actually, although I can't test this, manipulating the pointer itself seems even terser:
unsafe bool B(char*s)=>1>s[2]|*s<s[1]!=*++s<s[1]&B(s);\$\endgroup\$Scepheo– Scepheo2016年09月13日 13:36:38 +00:00Commented Sep 13, 2016 at 13:36 -
\$\begingroup\$ @Scepheo I got StackOverflowExceptions with those suggestions, but they work using boolean OR
||instead of bitwise OR|. Updated the post, thanks. \$\endgroup\$milk– milk2016年09月13日 19:26:19 +00:00Commented Sep 13, 2016 at 19:26
C 59 Bytes
r;f(s)char*s;{for(r=0;r=*s?~r&1<<(*s>=*++s):0;);return!*s;}
-
\$\begingroup\$ The solution in 70 bytes returns 1 (True) for case
AAA- the first "Falsey" in the examples \$\endgroup\$VolAnd– VolAnd2016年09月13日 05:31:38 +00:00Commented Sep 13, 2016 at 5:31 -
\$\begingroup\$ I'm testing using
gcc (GCC) 3.4.4 (cygming special, gdc 0.12, using dmd 0.125)and I get false for aaa and excited. In this version non-zero is falsey, and zero is truthy. Actually wondering now if this is allowed. \$\endgroup\$cleblanc– cleblanc2016年09月13日 13:44:31 +00:00Commented Sep 13, 2016 at 13:44 -
\$\begingroup\$ Call
f("ABCDEFGHIJKLMNOPQRSTUVWXYZ")compiled in Visual Studio 2012 returns value23that can be treated asTruebut in the question this value is in section "Falsey", so value0expected. \$\endgroup\$VolAnd– VolAnd2016年09月13日 14:01:50 +00:00Commented Sep 13, 2016 at 14:01 -
\$\begingroup\$ I misunderstood what was allowed for True and Falsey. Now I've read the that post and it seems clear what the values must be for "C". \$\endgroup\$cleblanc– cleblanc2016年09月13日 14:20:13 +00:00Commented Sep 13, 2016 at 14:20
-
\$\begingroup\$ Here's our standard definitions for truthy and falsey, based on Meta consensus. \$\endgroup\$AdmBorkBork– AdmBorkBork2016年09月13日 19:04:50 +00:00Commented Sep 13, 2016 at 19:04
Jelly, 6 bytes
OI>0IẠ
Based on @sanchises' answer.
Explanation
OI>0IẠ Input: string S
O Convert each char in S to an ordinal
I Get the increments between each pair
>0 Test if each is positive, 1 if true else 0
I Get the increments between each pair
Ạ Test if the list doesn't contain a zero, 1 if true else 0
JavaScript (ES6), 65 bytes
s=>[...s].map(C=>(c?(R=c<C,i++?t&=r^R:0,r=R):t=1,c=C),c=r=i="")|t
.map is definitely not the best solution.
Python 2, 88 bytes
Simple solution.
s=input()
m=map(lambda x,y:y>x,s[:-1],s[1:])
print all(x-y for x,y in zip(m[:-1],m[1:]))
If same letters in a row were neither a rise nor a fall, the solution would be 79 bytes:
s=input()
m=map(cmp,s[:-1],s[1:])
print all(x-y for x,y in zip(m[:-1],m[1:]))
Perl, 34 bytes
Includes +3 for -p (code contains ' so -e can't be used)
Give uppercase input on STDIN:
bump.pl <<< AAA
bump.pl
#!/usr/bin/perl -p
s%.%$&.z lt$'|0%eg;$_=!/(.)1円./
Python, 51 bytes
g=lambda a,b,c,*s:((a<b)^(b<c))*(s==()or g(b,c,*s))
Takes input like g('B','U','M','P') and outputs 1 or 0.
Uses argument unpacking to take the first three letters and check if the first two compare differently from the second two. Then, recurses on the remainder, using multiplication for and.
-
\$\begingroup\$ Nice input golf. ;-) \$\endgroup\$AdmBorkBork– AdmBorkBork2016年09月13日 12:53:59 +00:00Commented Sep 13, 2016 at 12:53
Jelly, (削除) 6 (削除ここまで) 5 bytes
-1 byte thanks to @Dennis (use a cumulative reduction)
<2\IẠ
All test cases are at TryItOnline
How?
<2\IẠ - main link takes an argument, s, e.g. "BUMP" or "BUMPY"
< - less than comparison (a dyad)
2 - literal 2 (a nilad)
\ - n-wise overlapping reduction when preceded by a dyad-nilad chain
(i.e. reduce the list by pairs with less than)
e.g. [1,0,1] or [1,0,1,1]
I - consecutive differences, e.g. [-1,1] or [-1,1,0]
Ạ - All, 0 if any values are 0 else 1, e.g. 1 or 0
Works for either all uppercase or all lowercase.
Japt, 8 bytes
Uä> ä- e
How it works
Uä> ä- e // Implicit: U = input string
Uä> // Map each pair of chars X, Y in U to X > Y.
ä- // Map each pair of items in the result to X - Y.
// If there are two consecutive rises or falls, the result contains a zero.
e // Check that every item is truthy (non-zero).
// Implicit: output last expression
-
\$\begingroup\$ Same as my solution. Except 11x shorter. :P \$\endgroup\$mbomb007– mbomb0072016年09月12日 15:18:19 +00:00Commented Sep 12, 2016 at 15:18
C# (削除) 105 (削除ここまで) 104 Bytes
bool f(char[]x){int t=1;for(int i=2,p=x[1],f=x[0]-p>>7;i<x.Length;)f^=t&=p<(p=x[i++])?1-f:f;return t>0;}
105 bytes Solution:
bool f(char[]x){bool t=1>0,f=x[0]<x[1];for(int i=2,p=x[1];i<x.Length;)f^=t&=p<(p=x[i++])?!f:f;return t;}
Using an array of chars saved one byte since the space can be omitted after the brackets. f(string x) vs f(char[]x)
It is 101 bytes if I can return an int 1/0 instead of bool true/false
int f(char[]x){int t=1;for(int i=2,p=x[1],f=x[0]-p>>7;i<x.Length;)f^=t&=p<(p=x[i++])?1-f:f;return t;}
Haskell, 52 bytes
f x=and$g(/=)$g(>)x
where g h y=zipWith h(tail y)y
I suspect I could get this a chunk smaller if I managed to get rid of the "where" construct, but I'm probably stuck with zipWith.
This works by making a list of the rises (True) and falls (False), then making a list of if the ajacent entries in this list are different
This is my first attempt at one of these, so I'll go through my thought process in case I've gone horribly wrong somewhere.
Ungolfed Version (168 bytes)
isBumpy :: [Char] -> Bool
isBumpy input = and $ areBumps $ riseFall input
where
riseFall ax@(x:xs) = zipWith (>) xs ax
areBumps ax@(x:xs) = zipWith (/=) xs ax
Shorten names, remove type information (100 bytes)
f x = and $ g $ h x
where
h ax@(x:xs) = zipWith (>) xs ax
g ax@(x:xs) = zipWith (/=) xs ax
Move h into the main function as it is only used once (86 bytes)
f ax@(x:xs) = and $ g $ zipWith (>) xs ax
where
g ax@(x:xs) = zipWith (/=) xs ax
Realise that areBumps and riseFall are similar enough to abstract (73 bytes)
f x = and $ g (/=) $ g (>) x
where
g h ya@(y:ys) = zipWith h ys ya
Note that (tail y) is shorter than ya@(y:ys) (70 bytes)
f x = and $ g (/=) $ g (>) x
where
g h y = zipWith h (tail y) y
Tidy up; remove unneeded spaces (52 bytes)
f x=and$g(/=)$g(>)x
where g h y=zipWith h(tail y)y
-
\$\begingroup\$ ... and I've just noticed a shorter Haskell answer that was posted before mine that does basically the same thing. I am terrible at spotting things. \$\endgroup\$Teron– Teron2016年09月14日 17:12:09 +00:00Commented Sep 14, 2016 at 17:12
-
\$\begingroup\$ You mean the one that doesn't work? ;-) You may use
g h=tail>>=zipWith hand make it a global function to avoid thewherekeyword. \$\endgroup\$Christian Sievers– Christian Sievers2016年09月19日 13:28:06 +00:00Commented Sep 19, 2016 at 13:28 -
\$\begingroup\$ @ChristianSievers Fixed it, and I just noticed this answer which now does exactly the same thing as mine, rendering my answer better suited as a comment to this one. \$\endgroup\$BlackCap– BlackCap2016年09月19日 15:47:32 +00:00Commented Sep 19, 2016 at 15:47
Java 7, (削除) 157 (削除ここまで) (削除) 153 (削除ここまで) (削除) 150 (削除ここまで) (削除) 125 (削除ここまで) 117 bytes
int c(char[]z){for(int i=2,a,b,c;i<z.length;i++)if(((a=z[i-1])<(c=z[i])&(b=z[i-2])<a)|(a>=c&b>=a))return 0;return 1;}
Ungolfed & test cases:
class M{
static int c(char[] z){
for(int i = 2, a, b, c; i < z.length; i++){
if(((a = z[i-1]) < (c = z[i]) & (b = z[i-2]) < a) | (a >= c & b >= a)){
return 0; //false
}
}
return 1; //true
}
public static void main(String[] a){
System.out.print(c("ABA".toCharArray()) + ", ");
System.out.print(c("ABB".toCharArray()) + ", ");
System.out.print(c("BAB".toCharArray()) + ", ");
System.out.print(c("BUMP".toCharArray()) + ", ");
System.out.print(c("BALD".toCharArray()) + ", ");
System.out.print(c("BALDY".toCharArray()) + ", ");
System.out.print(c("UPWARD".toCharArray()) + ", ");
System.out.print(c("EXAMINATION".toCharArray()) + ", ");
System.out.print(c("AZBYCXDWEVFUGTHSIRJQKPLOMN".toCharArray()) + ", ");
System.out.print(c("AAA".toCharArray()) + ", ");
System.out.print(c("ACE".toCharArray()) + ", ");
System.out.print(c("THE".toCharArray()) + ", ");
System.out.print(c("BUMPY".toCharArray()) + ", ");
System.out.print(c("BALDING".toCharArray()) + ", ");
System.out.print(c("ABCDEFGHIJKLMNOPQRSTUVWXYZ".toCharArray()) + ", ");
}
}
Output:
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0
-
\$\begingroup\$ @TimmyD Hmm, so it's rise when
a > b, but fall whena <= b, instead of>and<? \$\endgroup\$Kevin Cruijssen– Kevin Cruijssen2016年09月12日 14:51:48 +00:00Commented Sep 12, 2016 at 14:51 -
\$\begingroup\$ @TimmyD Ok, it's fixed, and even saves 3 bytes. :) \$\endgroup\$Kevin Cruijssen– Kevin Cruijssen2016年09月12日 14:58:44 +00:00Commented Sep 12, 2016 at 14:58
-
1\$\begingroup\$ you can redefine your method to accept
char[]so you dont have to transform your input string to char array. that should save a few bytes. PS: java ftw! \$\endgroup\$peech– peech2016年09月12日 15:01:04 +00:00Commented Sep 12, 2016 at 15:01 -
1\$\begingroup\$ Did you perhaps means to change
String s-->char[]z? \$\endgroup\$user18932– user189322016年09月13日 13:54:29 +00:00Commented Sep 13, 2016 at 13:54 -
1\$\begingroup\$ You can return a
truthyorfalseyvalue, so make your method an int and return 1 or 0 :).. Puts you down to 117 bytes \$\endgroup\$Shaun Wild– Shaun Wild2016年09月14日 08:46:24 +00:00Commented Sep 14, 2016 at 8:46
PowerShell v2+, 83 bytes
param($n)($a=-join(1..($n.Length-1)|%{+($n[$_-1]-lt$n[$_])}))-eq($a-replace'00|11')
A little bit of a different approach. This loops through the input $n, each iteration seeing whether the previous character $n[$_-1] is -lessthan the current character $n[$_], then casting the result of that Boolean operator to an int with +. Those are -joined together into a string, stored into $a. We then check whether $a is -equal to $a with any substrings of 00 or 11 removed.
Python 2.7, 84 bytes
s=input()
b=s[0]<s[1]
o=1
for i in range(len(s)-1):o&=(s[i]<s[i+1])==b;b^=1
print o
Returns 1 for bumpy, 0 for otherwise
Learned some cool stuff with bitwise & and ^.
Starts with boolean b defining first pair as up/down, then tests and flips b for each following pair.
o flips to false if test fails and sticks.
Requires quotes around input (+4 bytes for raw_input() if that breaks some rule)
Python 2.7 (again, (削除) 84 (削除ここまで) 83 bytes)
def a(s):x=s[1:];return[cmp(s[0],x)]+a(x) if x else []
print len(set(a(input())))>1
Or, (削除) 78 (削除ここまで) 77 bytes without the print.
(削除) By the way, the above 56 byte Python 2.7 example breaks on, for example, Never mind, didn't read instructions. Revising."abbab" or any other input with repeated characters. (削除ここまで)
Okay, down to 83. The triples one is nicer though.
-
\$\begingroup\$ Here's some tips for ya. 1. Remove some whitespace
a(x)if x else[]. 2. Use a lambda insteada=lambda s:[cmp(s[0],s[1:])]+a(s[1:])if s[1:]else[]3. Use a lambda at the end instead of printing.lambda s:len(set(a(s)))>14. iflen(set(a(s)))isn't greater than 1, than it's already falsy, so you can take off>1\$\endgroup\$DJMcMayhem– DJMcMayhem2016年09月13日 02:12:16 +00:00Commented Sep 13, 2016 at 2:12
05AB1E, 9 bytes
SÇ0円›\_O_
Explanation
SÇ # convert to list of ascii values
\ # take delta's
0› # check if positive, giving a list of 1's and 0's
# if they alternate, the word is bumpy
\ # take delta's again, if we have any 0's in the list the word is not bumpy
_ # logical negation, turning 0 into 1 and everything else to 0
O # sum, producing 0 for a bumpy word and 1 for a non-bumpy word
_ # logical negation, inverting the previous 1 into 0 and vice versa
CJam, 15 bytes
l2ew::<2ew::^:*
Try it online! (As a linefeed-separated test-suite.)
Explanation
l e# Read input.
2ew e# Get all (overlapping) pairs.
::< e# Check whether each pair is strictly ascending (1) or not (0).
2ew e# Get all (overlapping) pairs.
::^ e# Take the bitwise XOR of each pair, giving 1 if a rise and a fall alternate,
e# and zero if there are two rises or two falls in succession.
:* e# Product. Gives 1 only if the previous step yielded a list of 1s, meaning
e# that any two consecutive rises/falls will turn this into a zero.
PHP, 80 bytes
$s=$argv[1];for($c=$s[0];$n=$s[++$i];$c=$n,$d=$e)if($d===$e=$n>$c)break;echo!$n;
or
for($c=$argv[1][0];$n=$argv[1][++$i];$c=$n,$d=$e)if($d===$e=$n>$c)break;echo!$n;
empty output for false, 1 for true
or Hedi ́s recursive approach ported and a little golfed for 70 bytes:
function f($s){return!$s[2]|$s[0]<$s[1]^$s[1]<$s[2]&&f(substr($s,1));}
Actually, this should recurse infinitely for bumpy words, but it does not!
Haskell, (削除) 30 (削除ここまで) 37 bytes
q f=tail>>=zipWith f;k=and.q(/=).q(>)
Usage:
Prelude> k <$> words "ABA ABB BAB BUMP BALD BALDY UPWARD EXAMINATION AZBYCXDWEVFUGTHSIRJQKPLOMN"
[True,True,True,True,True,True,True,True,True]
Prelude> k <$> words "AAA BBA ACE THE BUMPY BALDING ABCDEFGHIJKLMNOPQRSTUVWXYZ"
[False,False,False,False,False,False,False]
-
\$\begingroup\$ That doesn't accept "bald",
foldl1(/=)doesn't do what you think it does. \$\endgroup\$Christian Sievers– Christian Sievers2016年09月19日 13:18:17 +00:00Commented Sep 19, 2016 at 13:18 -
\$\begingroup\$ @ChristianSievers Auch, you're right. Thanks for the heads up \$\endgroup\$BlackCap– BlackCap2016年09月19日 15:33:22 +00:00Commented Sep 19, 2016 at 15:33
PHP 7, (削除) 137 (削除ここまで) 118 bytes
for($i=0;$i<strlen($argv[1])-2;$i++)if(((($s[$i]<=>$s[$i+1])<0)?1:0)==((($s[$i+1]<=>$s[$i+2])<0)?1:0)){echo"0";break;}
Empty output for Bumpy, 0 for Not Bumpy.
This is my first attempt at code golfing and I have to improve a lot, but it was a wonderful method to learn new things for me. I also wanted to challenge myself on that task by using the new PHP 7 Spaceship Operator which seems very interesting.
(削除) Anyway I'm not satisfied about it, first of all for the fact that I had to add an extra (Note: I fixed that simply by changing if(isset($s[$i+2])) to check if the variable exist because I did not find another workaround to the problem, but this is it for now. (削除ここまで)strlen($s)-1 to strlen($s)-2, I couldn't really see that before...).
Testing code:
$as = array("ABA", "ABB", "BAB", "BUMP", "BALD", "BALDY", "UPWARD",
"EXAMINATION", "AZBYCXDWEVFUGTHSIRJQKPLOMN", "AAA", "BBA",
"ACE", "THE", "BUMPY", "BALDING", "ABCDEFGHIJKLMNOPQRSTUVWXYZ");
foreach ($as as $s) {
for($i=0;$i<strlen($s)-2;$i++)if(((($s[$i]<=>$s[$i+1])<0)?1:0)==((($s[$i+1]<=>$s[$i+2])<0)?1:0)){echo"0";break;}
}
-
\$\begingroup\$ Hello, and welcome to PPCG! Great first post! \$\endgroup\$NoOneIsHere– NoOneIsHere2016年09月16日 16:13:20 +00:00Commented Sep 16, 2016 at 16:13
-
\$\begingroup\$ Welcome to PPCG! Nice first post. Check out Tips for PHP for some additional golfing suggestions. \$\endgroup\$AdmBorkBork– AdmBorkBork2016年09月16日 16:29:23 +00:00Commented Sep 16, 2016 at 16:29
Javascript ES6, 100 bytes
d="charCodeAt";a=b=>{f=r=0;for(i=1;i<b.length;i++){if(b[d](i)<=b[d](i-1)){f=1}else{r=1}}return f&&r}
Try it here:
d="charCodeAt";a=b=>{f=r=0;for(i=1;i<b.length;i++){if(b[d](i)<=b[d](i-1)){f=1}else{r=1}}return f&&r}
alert(a(prompt()));Oh come on two people already beat me to it by 40 bytes... whatever
-
\$\begingroup\$ Hint:
"A"<"B", so you don't need to get the chars' charcodes. \$\endgroup\$ETHproductions– ETHproductions2016年09月12日 15:42:39 +00:00Commented Sep 12, 2016 at 15:42 -
\$\begingroup\$ Also, this returns
1forBUMPY(or anything else that contains both a rise and a fall). \$\endgroup\$ETHproductions– ETHproductions2016年09月12日 15:57:40 +00:00Commented Sep 12, 2016 at 15:57 -
\$\begingroup\$ This doesn't seem to quite work right. \$\endgroup\$AdmBorkBork– AdmBorkBork2016年09月13日 12:39:09 +00:00Commented Sep 13, 2016 at 12:39
Python 3, (削除) 148 139 (削除ここまで) 127 bytes
def _(w):*r,=map(lambda a,b:0>ord(a)-ord(b)and-1or 1,w,w[1:]);s=len(r)%2==0and r+[r[0]]or r;return sum(s)in(-1,1)and s==s[::-1]
testing code
positives = ('ABA', 'ABB', 'BAB', 'BUMP', 'BALD', 'BALDY', 'UPWARD', 'EXAMINATION', 'AZBYCXDWEVFUGTHSIRJQKPLOMN')
negatives = ('AAA', 'BBA', 'ACE', 'THE', 'BUMPY', 'BALDING', 'ABCDEFGHIJKLMNOPQRSTUVWXYZ')
for w in positives:
print(_(w), w)
assert _(w)
for w in negatives:
print(_(w), w)
assert not _(w)
-
\$\begingroup\$ i really suck at this #facepalm \$\endgroup\$Jeffrey04– Jeffrey042016年09月13日 02:33:24 +00:00Commented Sep 13, 2016 at 2:33
-
\$\begingroup\$ Welcome to PPCG! Check out Tips for Golfing in Python, and take inspiration from the other answers. \$\endgroup\$AdmBorkBork– AdmBorkBork2016年09月13日 12:55:24 +00:00Commented Sep 13, 2016 at 12:55
C, (削除) 65 (削除ここまで) (削除) 57 (削除ここまで) 60 bytes
r;f(char*s){for(r=0;*++s&&(r=~r&1<<(*s>*(s-1))););return r;}
is fix of
r;f(char*s){for(;*++s&&(r=~r&1<<(*s>*(s-1))););return r;}
that works correctly with any data only at single function call (when the global variable r is initialized to zero).
But in any case this is shorter than previous solution (65 bytes) due to use of for instead of while. But previous (the following) is a little easier to understand:
r;f(char*s){while(*++s)if(!(r=~r&1<<(*s>*(s-1))))break;return r;}
My solution is based on bitwise & with inverted previous and current direction code, where direction code can be 2 (1<<1) for character code increase (*s > *(s-1)) or 1 (1<<0) otherwise. Result of this operation became 0 if we use the same direction code as previous and current, i.e. when word is not Bumpy.
UPDATE:
Code for testing:
#include <stdio.h>
#include <string.h>
r;f(char*s){for(;*++s&&(r=~r&1<<(*s>*(s-1))););return r;}
int main(void)
{
char * Truthy[] = { "ABA",
"ABB",
"BAB",
"BUMP",
"BALD",
"BALDY",
"UPWARD",
"EXAMINATION",
"AZBYCXDWEVFUGTHSIRJQKPLOMN" };
char * Falsey[] = { "AAA",
"BBA",
"ACE",
"THE",
"BUMPY",
"BALDING",
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"};
int posTestNum = sizeof(Truthy) / sizeof(char *);
int negTestNum = sizeof(Falsey) / sizeof(char *);
int i;
int rate = 0;
int tests = 0;
int res = 0;
printf("Truthy (%d tests):\n", posTestNum);
for (i = 0; i < posTestNum; i++)
{
tests++;
printf("%s - %s\n", Truthy[i], f(Truthy[i]) ? (rate++, "OK") : "Fail");
r = 0;
}
printf("\nFalsey (%d tests):\n", negTestNum);
for (i = 0; i < negTestNum; i++)
{
tests++;
printf("%s - %s\n", Falsey[i], f(Falsey[i]) ? "Fail" : (rate++, "OK"));
r = 0;
}
printf("\n%d of %d tests passed\n", rate, tests);
return 0;
}
-
\$\begingroup\$ Per meta consensus, functions have to be reusable. That means you cannot reset
rto0for free, but must do so from within the function. \$\endgroup\$Dennis– Dennis2016年09月15日 20:00:35 +00:00Commented Sep 15, 2016 at 20:00 -
\$\begingroup\$ @Dennis You're right, initialization is required, but only for repeated calls. Let's assume that for a single call that works with any data because compiler provide initialisation for global variables \$\endgroup\$VolAnd– VolAnd2016年09月16日 04:28:23 +00:00Commented Sep 16, 2016 at 4:28
-
\$\begingroup\$ I think you should make the 60 byte solution your main one, since the 57 byte version isn't valid by that meta post I cited. \$\endgroup\$Dennis– Dennis2016年09月16日 04:49:03 +00:00Commented Sep 16, 2016 at 4:49
-
\$\begingroup\$ @Dennis Done! +3 bytes \$\endgroup\$VolAnd– VolAnd2016年09月16日 07:47:38 +00:00Commented Sep 16, 2016 at 7:47
PHP, 100 bytes
for($s=$argv[1];$i<strlen($s)-1;$i++)$s[$i]=$s[$i+1]>$s[$i]?r:f;echo str_replace([rr,ff],'',$s)==$s;
Replaces every char of the string (except the last one obviously) with an r for rise or an f for fall and then checks whether rr or ff occur in the string. To avoid that the last remaining character interfers with that, input must be all uppercase.
I'm very unsatisfied with the loop, for example I have a feeling that there must be a way to combine the $i++ into one of the several $is used in the loop, but I failed to find that way. Maybe someone else sees it.
(That's also why I posted my code, despite it being 20 (!) bytes longer than Titus' nice solution.)
Java 8, (削除) 114 (削除ここまで) 90 bytes
(c,b)->{b=c[0]<c[1];for(int i=2;i<c.length;i++)if(c[i]>c[i-1]!=(b=!b))return 0;return 1;};
Ungolfed test program
public static void main(String[] args) {
BiFunction<char[], Boolean, Integer> func = (c, b) -> {
b = c[0] < c[1];
for (int i = 2; i < c.length; i++) {
if (c[i] > c[i - 1] != (b = !b)) {
return 0;
}
}
return 1;
};
System.out.println(func.apply("ABCDEFG".toCharArray(), false));
System.out.println(func.apply("AZBYCXDGEF".toCharArray(), false));
System.out.println(func.apply("ZXZXZX".toCharArray(), false));
System.out.println(func.apply("ZXCYZ".toCharArray(), false));
System.out.println(func.apply("AAA".toCharArray(), false));
}
BUMPis listed in Truthy (i.e. Bumpy), whyBUMPYis in the Falsey list? What does "rises and falls alternates" means? Two rise s cannot be successively? \$\endgroup\$BUMPYis falsy becauseMPYgives two consecutive rises. In other words, no substring of length 3 must be sorted ascendingly or descendingly for a word to be bumpy (apart from the special case where two consecutive letters are identical). \$\endgroup\$