Full width text is text that has a space after every character, including the last one. For instance, the first sentence of this question becomes:
F u l l w i d t h t e x t i s t e x t t h a t h a s a s p a c e a f t e r e v e r y c h a r a c t e r , i n c l u d i n g t h e l a s t o n e .
Write a program that takes a line in text from standard input and outputs it as full-width text to standard out.
Leaderboard
var QUESTION_ID=75979,OVERRIDE_USER=52353;function answersUrl(e){return"https://api.stackexchange.com/2.2/questions/"+QUESTION_ID+"/answers?page="+e+"&pagesize=100&order=desc&sort=creation&site=codegolf&filter="+ANSWER_FILTER}function commentUrl(e,s){return"https://api.stackexchange.com/2.2/answers/"+s.join(";")+"/comments?page="+e+"&pagesize=100&order=desc&sort=creation&site=codegolf&filter="+COMMENT_FILTER}function getAnswers(){jQuery.ajax({url:answersUrl(answer_page++),method:"get",dataType:"jsonp",crossDomain:!0,success:function(e){answers.push.apply(answers,e.items),answers_hash=[],answer_ids=[],e.items.forEach(function(e){e.comments=[];var s=+e.share_link.match(/\d+/);answer_ids.push(s),answers_hash[s]=e}),e.has_more||(more_answers=!1),comment_page=1,getComments()}})}function getComments(){jQuery.ajax({url:commentUrl(comment_page++,answer_ids),method:"get",dataType:"jsonp",crossDomain:!0,success:function(e){e.items.forEach(function(e){e.owner.user_id===OVERRIDE_USER&&answers_hash[e.post_id].comments.push(e)}),e.has_more?getComments():more_answers?getAnswers():process()}})}function getAuthorName(e){return e.owner.display_name}function process(){var e=[];answers.forEach(function(s){var r=s.body;s.comments.forEach(function(e){OVERRIDE_REG.test(e.body)&&(r="<h1>"+e.body.replace(OVERRIDE_REG,"")+"</h1>")});var a=r.match(SCORE_REG);a&&e.push({user:getAuthorName(s),size:+a[2],language:a[1],link:s.share_link})}),e.sort(function(e,s){var r=e.size,a=s.size;return r-a});var s={},r=1,a=null,n=1;e.forEach(function(e){e.size!=a&&(n=r),a=e.size,++r;var t=jQuery("#answer-template").html();t=t.replace("{{PLACE}}",n+".").replace("{{NAME}}",e.user).replace("{{LANGUAGE}}",e.language).replace("{{SIZE}}",e.size).replace("{{LINK}}",e.link),t=jQuery(t),jQuery("#answers").append(t);var o=e.language;/<a/.test(o)&&(o=jQuery(o).text()),s[o]=s[o]||{lang:e.language,user:e.user,size:e.size,link:e.link}});var t=[];for(var o in s)s.hasOwnProperty(o)&&t.push(s[o]);t.sort(function(e,s){return e.lang>s.lang?1:e.lang<s.lang?-1:0});for(var c=0;c<t.length;++c){var i=jQuery("#language-template").html(),o=t[c];i=i.replace("{{LANGUAGE}}",o.lang).replace("{{NAME}}",o.user).replace("{{SIZE}}",o.size).replace("{{LINK}}",o.link),i=jQuery(i),jQuery("#languages").append(i)}}var ANSWER_FILTER="!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe",COMMENT_FILTER="!)Q2B_A2kjfAiU78X(md6BoYk",answers=[],answers_hash,answer_ids,answer_page=1,more_answers=!0,comment_page;getAnswers();var SCORE_REG=/<h\d>\s*([^\n,]*[^\s,]),.*?(\d+)(?=[^\n\d<>]*(?:<(?:s>[^\n<>]*<\/s>|[^\n<>]+>)[^\n\d<>]*)*<\/h\d>)/,OVERRIDE_REG=/^Override\s*header:\s*/i;body{text-align:left!important}#answer-list,#language-list{padding:10px;width:290px;float:left}table thead{font-weight:700}table td{padding:5px}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script> <link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b"> <div id="answer-list"> <h2>Leaderboard</h2> <table class="answer-list"> <thead> <tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr></thead> <tbody id="answers"> </tbody> </table> </div><div id="language-list"> <h2>Winners by Language</h2> <table class="language-list"> <thead> <tr><td>Language</td><td>User</td><td>Score</td></tr></thead> <tbody id="languages"> </tbody> </table> </div><table style="display: none"> <tbody id="answer-template"> <tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr></tbody> </table> <table style="display: none"> <tbody id="language-template"> <tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr></tbody> </table>-
8\$\begingroup\$ Usually you should allow functions too, or you exclude a lot of languages (e.g. JavaScript). \$\endgroup\$wizzwizz4– wizzwizz42016年03月22日 18:00:20 +00:00Commented Mar 22, 2016 at 18:00
-
10\$\begingroup\$ We have a few defaults for I/O that are based on community consensus. While you are entitled to override them, insisting on STDIN/STDOUT for I/O invalidates a bunch of answers (which assumed that the defaults apply) and make the task downright impossible in other languages (they don't have standard streams). \$\endgroup\$Dennis– Dennis2016年03月22日 21:22:58 +00:00Commented Mar 22, 2016 at 21:22
-
65\$\begingroup\$ That is not what fullwidth text is. \$\endgroup\$BlueRaja - Danny Pflughoeft– BlueRaja - Danny Pflughoeft2016年03月22日 21:53:15 +00:00Commented Mar 22, 2016 at 21:53
-
4\$\begingroup\$ @BlueRaja-DannyPflughoeft is right. Full Width text is about underlying character encoding ( 2 bytes encoded ) required by some language ( i.e. ideograms ). In Unicode the notion of half and full size is called Unicode block \$\endgroup\$Ludovic Frérot– Ludovic Frérot2016年03月23日 09:27:15 +00:00Commented Mar 23, 2016 at 9:27
-
3\$\begingroup\$ @LudovicFrérot Actually, these are not ideograms, these are chinese english letters. \$\endgroup\$Erik the Outgolfer– Erik the Outgolfer2016年07月01日 08:29:17 +00:00Commented Jul 1, 2016 at 8:29
151 Answers 151
Jelly, (削除) 5 (削除ここまで) (削除) 3 (削除ここまで) 2 bytes
Thanks to Dennis for saving 2 bytes. Also thanks to FryAmTheEggman for saving 1 byte. Code:
p6
Explanation:
p6 # Cartesian product with the input and the space character.
Uses the Jelly encoding.
-
1\$\begingroup\$ 6 takes up three bytes in UTF-8. \$\endgroup\$Jess Smith– Jess Smith2016年03月22日 18:02:25 +00:00Commented Mar 22, 2016 at 18:02
-
13\$\begingroup\$ @JessSmith Jelly uses its own code page: github.com/DennisMitchell/jelly/blob/master/docs/code-page.md \$\endgroup\$a spaghetto– a spaghetto2016年03月22日 18:02:56 +00:00Commented Mar 22, 2016 at 18:02
-
1\$\begingroup\$ @AandN Put it in the answer, not a comment. \$\endgroup\$mbomb007– mbomb0072016年03月22日 20:08:53 +00:00Commented Mar 22, 2016 at 20:08
-
3\$\begingroup\$ @mbomb007 It's right in the header. \$\endgroup\$Adnan– Adnan2016年03月22日 20:09:18 +00:00Commented Mar 22, 2016 at 20:09
-
5\$\begingroup\$ @AandN No, you should say in your answer that it has its own code page. Especially since it's a newer language, so people don't know yet. \$\endgroup\$mbomb007– mbomb0072016年03月22日 20:10:59 +00:00Commented Mar 22, 2016 at 20:10
Python 3.5, 18 bytes
print(*input(),'')
This works because print's default separator is single space.
-
3\$\begingroup\$
print(*input(),end=' ')would be portable, but it's not very golfy... \$\endgroup\$Dennis– Dennis2016年03月22日 20:35:36 +00:00Commented Mar 22, 2016 at 20:35 -
9\$\begingroup\$ MFW the first use of my PEP I see in the wild is on Code Golf. \$\endgroup\$Veedrac– Veedrac2016年03月23日 08:15:54 +00:00Commented Mar 23, 2016 at 8:15
-
\$\begingroup\$ Does this have a space after the last character? \$\endgroup\$Esolanging Fruit– Esolanging Fruit2017年06月04日 16:15:14 +00:00Commented Jun 4, 2017 at 16:15
Hexagony, (削除) 21 (削除ここまで) (削除) 13 (削除ここまで) (削除) 12 (削除ここまで) 10 bytes
Code:
Saved a lot of bytes thanks to FryAmTheEggman. Code:
P,<0/*;@.>
Or in a more readable form:
P , <
0 / * ;
@ . > . .
. . . .
. . .
Explanation:
The Hexagony program starts at the top-left corner, immediately setting the memory edge to the ASCII value of P, which is 80. After that, we can see that the following path is taken:
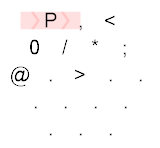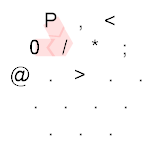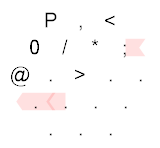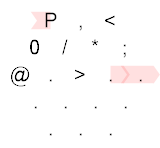{kind=link}
We can see that the path taken is: P,<;.P/0....;*/>. After the P, we take a byte of user input. If this is empty, the following branch (<) would direct us to the North East. If the input is non-empty, the branch directs us to the South East. After that, we output the user input using ;. We set the memory edge back to P, which is 80. The zero followed by the mirror is then concatenated to our number, resulting into 800. This is then outputted using the ; command, but first it is taken modulo 256, resulting into 32, which is the space character. After that, we reset the memory edge using the * command and return to loop over the rest of the user input. When we're done with the user input, the path is directed to the North East:
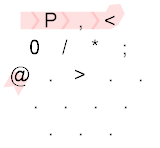{kind=link}
This basically goes to the @ command, which terminates the program.
Using Timwi's amazing HexagonyColorer for making the diagrams.
-
\$\begingroup\$ Uh, I was golfing while you edited. Oops. 10:
P,<0/*;@.>\$\endgroup\$FryAmTheEggman– FryAmTheEggman2016年03月22日 19:33:39 +00:00Commented Mar 22, 2016 at 19:33 -
\$\begingroup\$ @FryAmTheEggman Hahaha, let's make a new explanation then :p. \$\endgroup\$Adnan– Adnan2016年03月22日 19:39:20 +00:00Commented Mar 22, 2016 at 19:39
-
\$\begingroup\$
P,<<>0;@>*is also 10, but unfortunately I don't think it helps in shaving off another byte. \$\endgroup\$Martin Ender– Martin Ender2016年03月23日 06:54:12 +00:00Commented Mar 23, 2016 at 6:54 -
\$\begingroup\$ @MartinBüttner Oh, that's a shame. I doubt if it's possible to shave off another byte, but it seems unlikely. \$\endgroup\$Adnan– Adnan2016年03月24日 16:03:51 +00:00Commented Mar 24, 2016 at 16:03
-
\$\begingroup\$ Is HexagonyColorer now animated? \$\endgroup\$Esolanging Fruit– Esolanging Fruit2017年06月04日 16:15:38 +00:00Commented Jun 4, 2017 at 16:15
Haskell, 11 bytes
((:" ")=<<)
Usage example: ((:" ")=<<) "Code Golf" -> "C o d e G o l f ".
Map each character c to a two element list [c, space] and concatenate everything into a single list.
-
\$\begingroup\$ Interesting that Haskell and Jelly are kind of doing the same thing here, since the list monad acts similarly to a Cartesian product. \$\endgroup\$ballesta25– ballesta252016年03月24日 05:43:42 +00:00Commented Mar 24, 2016 at 5:43
Retina, 5
.
$&
Note the space at the end of the second line.
$& is equivalent to 0ドル. Thanks to @mbomb007 for this link.
-
\$\begingroup\$ @FryAmTheEggman I prefer to use
0ドル. It's the same thing, but more common. \$\endgroup\$mbomb007– mbomb0072016年03月22日 19:42:44 +00:00Commented Mar 22, 2016 at 19:42 -
\$\begingroup\$ Here's a useful reference to go along with Retina's wiki: msdn.microsoft.com/en-us/library/… \$\endgroup\$mbomb007– mbomb0072016年03月22日 19:45:09 +00:00Commented Mar 22, 2016 at 19:45
JavaScript, 20 Bytes
Simple, I just wish that Array.join added the space to the end so I could save 3 bytes.
s=>[...s,``].join` `
-
5\$\begingroup\$
[...s,``].join` `perhaps? \$\endgroup\$Neil– Neil2016年03月22日 18:39:30 +00:00Commented Mar 22, 2016 at 18:39 -
4\$\begingroup\$ Even better
[...s,,].join... \$\endgroup\$edc65– edc652016年07月01日 13:27:21 +00:00Commented Jul 1, 2016 at 13:27 -
\$\begingroup\$ @edc65 Doesn't work in latest Firefox or Chrome? I just get the
joinfunction as the return, as I would expect. \$\endgroup\$Mwr247– Mwr2472016年07月01日 15:55:42 +00:00Commented Jul 1, 2016 at 15:55 -
\$\begingroup\$ @Mwr247 after the join you must put the rest of your code, that's why I put ellipsis (...). It's just 1 byte saving \$\endgroup\$edc65– edc652016年07月01日 23:45:40 +00:00Commented Jul 1, 2016 at 23:45
-
\$\begingroup\$ @edc65 may have been too lazy to work out how to type the
` `in a comment. \$\endgroup\$Neil– Neil2016年07月09日 21:11:57 +00:00Commented Jul 9, 2016 at 21:11
Awk, 7 bytes
(4 characters code + 3 characters command line option.)
NF++
Sample run:
bash-4.3$ awk -F '' 'NF++' <<< 'Full width text.'
F u l l w i d t h t e x t .
(There is some disagreement on what should be included in the command line option count. I included what is actually passed to the awk interpreter: "-", "F" and a separator between "F" and the empty string parameter. See below what I mean.)
bash-4.3$ od -tax1 /proc/`pidof awk`/cmdline
0000000 a w k nul - F nul nul N F + + nul
61 77 6b 00 2d 46 00 00 4e 46 2b 2b 00
╰────────╯
><>, (削除) 13 (削除ここまで) 10 bytes
3 bytes saved thanks to @Sp3000
i:0(?;o 'o
Try it here. Click the link, then Submit, then type some input and press Give, and finally run the program with Start or Run without animation.
Explanation
i read a character
: duplicate
0( is it less than 0?
?; if so: end program. Else:
o output read character
' push all chars until matching (same) quote. Top character is a space
o output that character, which is a space. Go back to the beginning
-
\$\begingroup\$
i:0(?;o 'ofor 10 \$\endgroup\$Sp3000– Sp30002016年03月23日 01:51:13 +00:00Commented Mar 23, 2016 at 1:51 -
\$\begingroup\$ In fact,
io 'oworks too, erroring out. \$\endgroup\$Sp3000– Sp30002016年03月23日 01:52:36 +00:00Commented Mar 23, 2016 at 1:52 -
\$\begingroup\$ @Sp3000 Thanks! I'll go for the no-error version (maybe you want to submit yours?). I forgot you can input chars directly. How does the unmatched quote work? Does it always pick the preceding char? \$\endgroup\$Luis Mendo– Luis Mendo2016年03月23日 01:56:08 +00:00Commented Mar 23, 2016 at 1:56
-
1\$\begingroup\$
'just wraps around, pushing chars until it finds another'to close it. In this case the opening and closing's are the same char and most of the source code is pushed, but the top char would just be space since it was pushed last. \$\endgroup\$Sp3000– Sp30002016年03月23日 01:57:34 +00:00Commented Mar 23, 2016 at 1:57 -
\$\begingroup\$ @Sp3000 Got it. So that's also cyclical. Thanks a lot for the suggestion and explanation! \$\endgroup\$Luis Mendo– Luis Mendo2016年03月23日 01:58:27 +00:00Commented Mar 23, 2016 at 1:58
Java, 132 (System.in) or 99 (Program argument) bytes
Can you feel the overhead tonight?
class F{public static void main(String[]a){System.out.print(new java.util.Scanner(System.in).nextLine().replaceAll("(.)", "0ドル "));}}
class W{public static void main(String[]a){for(char c:a[0].toCharArray())System.out.print(c+" ");}}
shooqie figured out a 6 byte shorter way to do this but I won't steal their approach. I've used it with the STDIN and lambda versions, however.
28 characters for a lambda but that doesn't meet the program requirement.
s->s.replaceAll("(.)","0ドル ")
-
\$\begingroup\$ The question specified that the input must be from STDIN. \$\endgroup\$EMBLEM– EMBLEM2016年03月22日 20:17:02 +00:00Commented Mar 22, 2016 at 20:17
-
\$\begingroup\$ I could add one for you, if that's ok. \$\endgroup\$Blue– Blue2016年03月22日 21:26:50 +00:00Commented Mar 22, 2016 at 21:26
-
\$\begingroup\$ I've added a STDIN version now (and used the clever regexplace shooqie figured out). \$\endgroup\$CAD97– CAD972016年03月23日 01:47:07 +00:00Commented Mar 23, 2016 at 1:47
-
1\$\begingroup\$ No need for parentheses in your regex. Also removed an extra space between arguments to
replaceAll. \$\endgroup\$Khuldraeseth na'Barya– Khuldraeseth na'Barya2019年08月19日 15:53:11 +00:00Commented Aug 19, 2019 at 15:53
Java, 92
class T{public static void main(String[]A){System.out.print(A[0].replaceAll("(.)","0ドル "));}}
APL, 5 bytes
∊2∘↑ ̈
This takes 2 items for each character in the string, with the effect of adding a space
To make it a program that takes stdin, it's the same number of bytes:
∊2↑ ̈⎕
Try it here.
Cubix, 10 bytes
Cubix is a 2 dimensional language developed by @ETHproductions where the commands are wrapped onto a cube. Try it online
@.?wi^\oSo
This maps onto a cube with edge length 2
@ .
? w
i ^ \ o S o . .
. . . . . . . .
. .
. .
Starts with a input i. The flow is redirected north ^ to the top face. ? If the value is negative turn left to finish @, zero carries on into shift right w or positive turn right then reflect left \. Output character with a trailing space oSo.
Cubix, 9 bytes
@./.i?>So
Cubix is a language in which the instructions are mapped out onto the face of a cube. This program forms the following cube net:
@ .
/ .
i ? > S o . . .
. . . . . . . .
. .
. .
The instruction pointer begins at i, which takes another character-code from input and pushes it to the stack. If there is no more input left to be taken, the ? turns the IP left, where it hits /, and is reflected upwards to @, which terminates the program.
However, if there is input left, the value will be a character code. As all1 character codes are positive, the ? makes the IP turn right, where it wraps all the way around the cube, passing o on the way which outputs the char. It then hits / which makes it loop back around to >So, which pushes and prints a space. The IP carries on west until wrapping around back to the i, back to the start of the main loop.
1 If the character is a null byte, it will ignore the ? and carry on straight ahead, simply outputting a single space.
Of course, there's only so much a written explanation can do, so I highly recommend you view this in the online interpreter. There's a "speed" option, which allows you to view the execution as slow or fast as you like.
-
1\$\begingroup\$ you can save a byte with
@.Uoi?So\$\endgroup\$MickyT– MickyT2017年07月03日 22:07:49 +00:00Commented Jul 3, 2017 at 22:07
Stax, 2 bytes
Ties Jelly!
0\
All this does is push 0 to the stack and zip the string from standard input with it, repeating the 0 as necessary. In Stax, code point 0 in a string is usually converted to 32 (space).
This is short enough that packing it into ûT does nothing but reduce readability.
Seriously, 7 bytes
' ;,@j+
Man, that required ending space added 3 additional bytes. Without it, ,' j would work for 4.
Explanation:
' ;,@j+
' ; push two copies of a single space
,@ push input, swap
j+ join on spaces, append a space
05AB1E, 4 bytes
Sð«J
Explanation
Sð«J
S split string into a list
ð« append a space to each element
J join
-
1\$\begingroup\$
ðâJnon-competing. \$\endgroup\$Magic Octopus Urn– Magic Octopus Urn2017年01月12日 16:03:00 +00:00Commented Jan 12, 2017 at 16:03 -
\$\begingroup\$ @Kevin That doesn't output the trailing space. \$\endgroup\$Makonede– Makonede2021年02月02日 18:43:46 +00:00Commented Feb 2, 2021 at 18:43
CJam, (削除) 5 (削除ここまで) 4 bytes
1 byte fewer thanks to @FryAmTheEggman
lSf+
Explanation
l e# read line
Sf+ e# map "concatenation" (+) with a space (S) as extra parameter
e# implicitly display characters in the stack
PHP, 39 bytes
echo join(' ',str_split($argv[1])).' ';
Run it from the command line
php fullwidth.php "Full width text is text that has a space after every character, including the last one."
-
\$\begingroup\$ Jesus hecking christ how the heck \$\endgroup\$Tornado547– Tornado5472017年12月14日 19:53:39 +00:00Commented Dec 14, 2017 at 19:53
-
\$\begingroup\$ Alternative 4-byter:
s+R;\$\endgroup\$Sok– Sok2019年02月14日 13:56:56 +00:00Commented Feb 14, 2019 at 13:56
WhoScript 38 bytes
1v;pr;e;#0 1;-;i;t=;ti;o;tl;" ";d;>;pf
Works best when the string is given at the command line, but it can be done one character at a time in real time as well.
Ungolfed:
time_vortex
psychic_paper read
duplicate
# 0 1
-
integer
TARDIS =
TARDIS if
opening
TARDIS landing
# 20
paradox
pop
psychic_paper flush
Labyrinth, 10 bytes
<.23.%):,>
This terminates with an error, but the error messages goes to STDERR.
Explanation
This is one of the rare cases where a completely linear program is feasible. The loop is achieved via the source code modification commands < and >, which works because after each iteration we know that the stack is empty again.
< cyclically shifts the entire line one cell to the left, so we end up with:
.23.%):,><
This takes the instruction pointer (IP) with it so the IP is now at the right end of the code and has to move left. Next, the > does the opposite modification so it shifts the source code back to
<.23.%):,>
Now we execute a single iteration (from right to left), before everything starts over:
, Read a character code from STDIN, or -1 at EOF.
:) Duplicate and increment.
% Modulo. At EOF this will attempt a division by zero and terminate. Otherwise, we
have n % (n+1) = n, so we're left with the input character again.
. Print it back to STDOUT.
32 Turn the top of the stack into a 32.
. Print it as well (a space).
Gema, 5 bytes
?=?\
Sample run:
bash-4.3$ gema '?=?\ ' <<< 'Full width text.'
F u l l w i d t h t e x t .
-
\$\begingroup\$ I haven't seen this language before. Link to the interpreter? \$\endgroup\$a spaghetto– a spaghetto2016年03月26日 04:57:55 +00:00Commented Mar 26, 2016 at 4:57
-
1\$\begingroup\$ Sorry. Added hyperlink to the post title. Quite old, but sadly, Google can efficiently help finding it only if you know that the name comes from "general purpose macro processor". \$\endgroup\$manatwork– manatwork2016年03月26日 13:52:44 +00:00Commented Mar 26, 2016 at 13:52
MATL, 7 bytes
tnZ"v1e
Explanation
t % implicitly take input string and duplicate it
n % number of elements
Z" % string with that many spaces
v % concatenate vertically (2xN array, where N is input length)
1e % reshape into 1 row. Implicitly display
brainfuck, (削除) 24 (削除ここまで) 22 bytes
Simple example using the shortest known 32 for the space character(s).
,[.>>-[-[-<]>>+<]>-.,]
-
\$\begingroup\$
,[.>>-[-[-<]>>+<]>-.,]saves two bytes. \$\endgroup\$Dennis– Dennis2016年07月01日 22:15:56 +00:00Commented Jul 1, 2016 at 22:15
PHP, 31 bytes
<?=chunk_split($argv[1],1," ");
takes input from command line argument.
Threead, (削除) 45 (削除ここまで) 16 Bytes non-competing.
B[coB]
32c o
Takes input via STDIN.
The first Line/Tape simply reads bytes from STDIN, and writes them. The second line, initially stores a space via 32c, then at the same time that the next character is being read, outputs that space.
Python 2, (削除) 27 (削除ここまで) (削除) 25 (削除ここまで) 24 bytes
lambda x:' '.join(x)+' '
Shorter than Raffi's answer...
-1 thanks to 60919 (FlipTack).
-
\$\begingroup\$ If functions are allowed then
lambda x:' '.join(x)+' 'is 1 byte shorter. \$\endgroup\$FlipTack– FlipTack2017年01月12日 20:06:15 +00:00Commented Jan 12, 2017 at 20:06
C, 50 bytes
Little bit of main() recursion :)
main(c){~(c=getchar())?printf("%c ",c),main():0;}
Try it online! - If using this on your own machine, use Ctrl+D to signify EOF.
C, 56 Bytes (as program argument), 46 Bytes (from stdin)
main(int a,char**b){while(*b[1])printf("%c ",*b[1]++);}
Plain old C answer. Once compiled, the program needs to be called with a string as it's first parameter, a string with spaces needs to be enclosed in quotes. For the example in the start post:
./prog "Full width text is text that has a space after every character, including the last one."
Which will output
F u l l w i d t h t e x t i s t e x t t h a t h a s a s p a c e a f t e r e v e r y c h a r a c t e r , i n c l u d i n g t h e l a s t o n e .
Solution that reads directly from stdin.
main(c){while(c=~getchar())printf("%c ",~c);}
One byte less thanks to @FryAmTheEggman
-
\$\begingroup\$ The requirements are a little murky, but I believe you have to read the input from
stdinrather than taking it as an argument. Also, here is a page with some useful tips for further golfing in C: codegolf.stackexchange.com/q/2203/13877 \$\endgroup\$Josh– Josh2016年03月22日 19:59:40 +00:00Commented Mar 22, 2016 at 19:59 -
\$\begingroup\$ @Josh Does it count as a parameter to main? Because otherwise, the Java answer will be just as wrong, and not so sure about the Haskell one either. \$\endgroup\$SBI– SBI2016年03月22日 20:04:08 +00:00Commented Mar 22, 2016 at 20:04
-
\$\begingroup\$ Either is fine we like our I/O to be friendly :) But I do believe using
getchar()is shorter. Also you don't need the include for most C compilers. \$\endgroup\$FryAmTheEggman– FryAmTheEggman2016年03月22日 20:06:31 +00:00Commented Mar 22, 2016 at 20:06 -
\$\begingroup\$ @FryAmTheEggman I left the include in to be completely compliant, I can only test with gcc. As long as gcc-only is fine, yeah, shaving the include is alright. \$\endgroup\$SBI– SBI2016年03月22日 20:10:14 +00:00Commented Mar 22, 2016 at 20:10
-
\$\begingroup\$ Generally, if it works with Ideone it's ok :) \$\endgroup\$FryAmTheEggman– FryAmTheEggman2016年03月22日 20:12:38 +00:00Commented Mar 22, 2016 at 20:12