In this question at Code Review they tried to find the fastest way to return the unique element in an array where all the elements are the same except one. But what is the shortest code that accomplish the same thing?
Goal
Find the unique element in an array and return it.
Rules
- The input array will contain only integer, strictly positive numbers, so you can use 0 as the end of the input if your language needs it.
- The size of the array will be at least 3 and will have a finite size. You can limit the size of the array to any limit your language has.
- Every element in the array will be the same, except for one which will be different.
- You must output the value (not the position) of the unique element in any standard format. You can output leading or trailing spaces or newlines.
- You can take the input array in any accepted format.
Examples
Input Output
------------------------------
[ 1, 1, 1, 2, 1, 1 ] 2
[ 3, 5, 5, 5, 5 ] 3
[ 9, 2, 9, 9, 9, 9, 9 ] 2
[ 4, 4, 4, 6 ] 6
[ 5, 8, 8 ] 5
[ 8, 5, 8 ] 5
[ 8, 8, 5 ] 5
Winner
This is code-golf, so may the shortest code for each language win!
92 Answers 92
JavaScript (ES6), (削除) 32 (削除ここまで) 27 bytes
Saved 5 bytes thanks to @xnor
a=>a.sort()[0]+a.pop()-a[1]
How?
a.sort() sorts the input array in lexicographical order. We know for sure that this is going to put the unique element either at the first or the last position, but we don't know which one:
[ x, ..., y, ..., x ].sort() -> [ y, x, ..., x ] or [ x, x, ..., y ]
Either way, the sum of the first and the last elements minus the 2nd one gives the expected result:
[ y, x, ..., x ] -> y + x - x = y
[ x, x, ..., y ] -> x + y - x = y
We could also XOR all of them:
a=>a.sort()[0]^a.pop()^a[1]
-
1
-
\$\begingroup\$ @xnor This is much better indeed! \$\endgroup\$Arnauld– Arnauld2020年07月28日 15:21:26 +00:00Commented Jul 28, 2020 at 15:21
x86-16 machine code, 14 bytes
Binary:
00000000: 498d 7c01 f3a6 e305 4ea6 7401 4ec3 I.|.....N.t.N.
Listing:
49 DEC CX ; only do length-1 compares
8D 7C 01 LEA DI, [SI+1] ; DI pointer to next value
F3 A6 REPE CMPSB ; while( [SI++] == [DI++] );
E3 05 JCXZ DONE ; if end of array, result is second value
4E DEC SI ; SI back to first value
A6 CMPSB ; [SI++] == [DI++]?
74 01 JE DONE ; if so, result is second value
4E DEC SI ; otherwise, result is first value
DONE:
C3 RET ; return to caller
Callable function, input array in [SI], length in CX. Result in [SI].
Explanation:
Loop through the array until two different adjacent values are found. Compare the first to the third value. If they are the same, the "odd value out" must be the second, otherwise it is the first.
Example:
Input [ 1, 1, 1, 2, 1, 1 ], reduce until different adjacent values are found a = [ 1, 2, 1, 1 ]. If a[0] == a[2] then result is a[1], otherwise result is a[0].
Tests using DOS DEBUG:
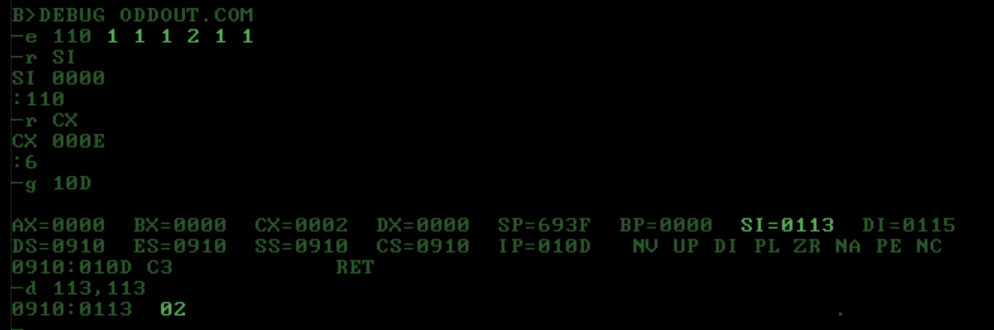{kind=link}
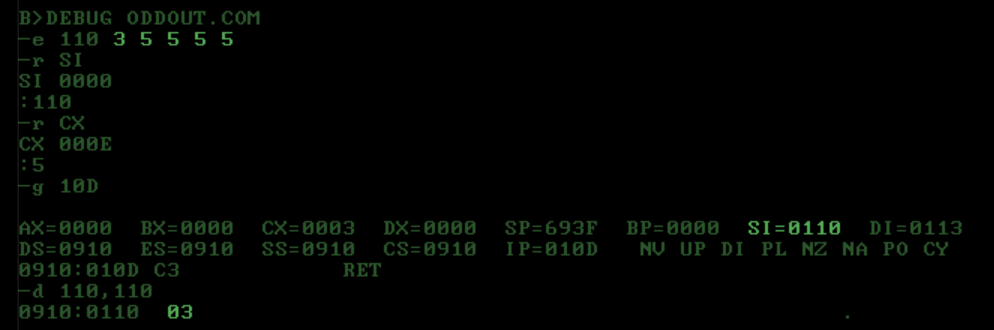{kind=link}
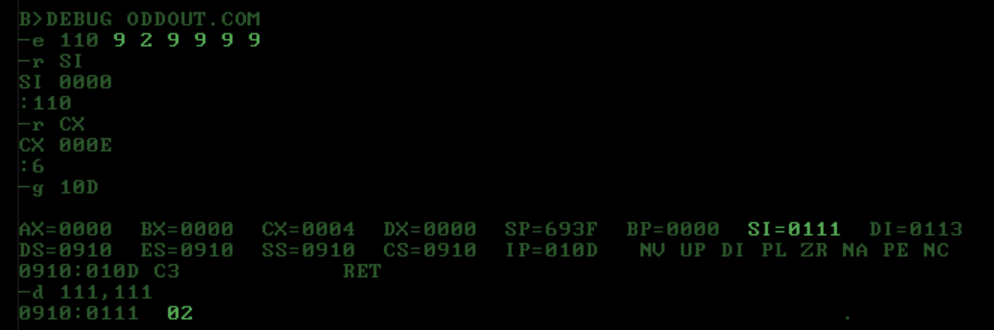{kind=link}
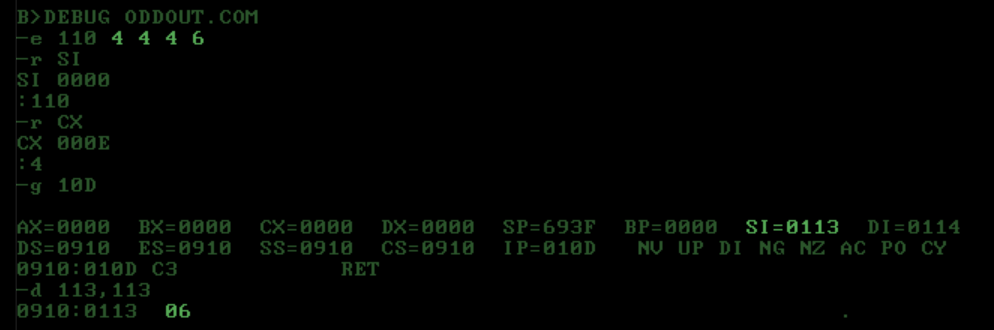{kind=link}
-
1\$\begingroup\$
lea di, [si+1]is the same size but saves instructions. IDK if we could justify taking the array length as "max index", avoiding thedec cx. It's not an "interesting" saving, just calling-convention wanking, so not worth updating your test-result images. And hard to justify; it's so standard to do pointer+length even in asm. Nice idea overall to userep cmpsbthis way. \$\endgroup\$Peter Cordes– Peter Cordes2020年07月31日 03:40:25 +00:00Commented Jul 31, 2020 at 3:40
05AB1E, 2 bytes
ʒ¢
Since 1 is the only truthy integer in 05AB1E, we can just filter (ʒ) on the ¢ount.
There is also the Counter-Mode builtin, which returns the least frequent element in a list at the same bytecount:
.m
-
\$\begingroup\$ Stax also has a built-in, but it outputs a code point... \$\endgroup\$the default.– the default.2020年07月28日 15:04:58 +00:00Commented Jul 28, 2020 at 15:04
-
\$\begingroup\$ When I read the challenge just yet I had
¢Ïin mind, which is basically the same approach as your first. Didn't think about the least frequent builtin, but that's indeed a nice alternative. :) \$\endgroup\$Kevin Cruijssen– Kevin Cruijssen2020年08月04日 07:01:26 +00:00Commented Aug 4, 2020 at 7:01 -
\$\begingroup\$ @KevinCruijssen thats neat, I had the same idea, but couldn't find
Ïin the documentation. Maybe I just need to read all commands descriptions at some point ;). \$\endgroup\$ovs– ovs2020年08月04日 07:27:30 +00:00Commented Aug 4, 2020 at 7:27
APL (Dyalog Extended), 5 bytes
⍸1= ̄⍸
Regular Dyalog APL 18.0 has ⍸⍣ ̄1, but it doesn't work here because it requires the input array to be sorted, unlike Extended's ̄⍸ which allows unsorted input arrays.
How it works
⍸1= ̄⍸ ⍝ Input: a vector N of positive integers
⍝ (Example: 4 4 6 4)
̄⍸ ⍝ Whence; generate a vector V where V[i] is the count of i in N
⍝ ( ̄⍸ 4 4 6 4 → 0 0 0 3 0 1)
1= ⍝ Keep 1s intact and change anything else to zero (V1)
⍝ (1= 0 0 0 3 0 1 → 0 0 0 0 0 1)
⍸ ⍝ Where; generate a vector W from V1, where i appears V1[i] times in W
⍝ (⍸ 0 0 0 0 0 1 → 6)
Haskell, 32 bytes
f(x:y)|[e]<-filter(/=x)y=e|1<3=x
Explanation
The code, expanded with variables renamed to be more descriptive.
f (first:rest)
| [unique] <- filter (/=first) rest = unique
| 1 < 3 = first
(first:rest) is a pattern match on a list that destructures it into its first element (first) and the list without the first element (rest).
Each line with a | at the front is a case in the function (known as "guards" in Haskell). The syntax looks like functionName args | condition1 = result1 | condition2 = result2 .... There are two cases:
[unique] <- filter (/=first) rest. This asserts thatfilter (/=first) restproduces a list containing only one element, which we nameunique.filter (/=first) restfilters out all elements inrestnot equal tofirst. If we are in this case, then we know thatuniqueis the unique element, and we return it.1 < 3. This asserts that 1 is less than 3. Since it's always true, this is a "fallthrough" case. If we reach it, we know that there are at least 2 elements not equal to the first element, so we returnfirst.
Jelly, 3 bytes
ḟÆṃ
Explanation: ḟ (probably) removes all elements that are not the most common element (returned by Æṃ). I don't know why isn't the result a single-element list (perhaps it's a feature I didn't know about?), but that makes this even better.
-
3\$\begingroup\$ The result of the Link
ḟÆṃis a single-element-list, it's just that when a full-program is run which results in a single-element-list the printed output is what would be printed if that single-element were the result. (i.e.2RWWWjust prints[1,2]rather than[[[[1,2]]]]. \$\endgroup\$Jonathan Allan– Jonathan Allan2020年07月28日 17:41:41 +00:00Commented Jul 28, 2020 at 17:41
Octave / MATLAB, 19 bytes
@(x)x(sum(x==x')<2)
How it works
@(x) % Define a function of x
x==x' % Square matrix of all pairwise comparisons (non-complex x)
sum( ) % Sum of each column
<2 % Less than 2? This will be true for only one column
x( ) % Take that entry from x
-
\$\begingroup\$ this is the same byte count if you were to port the R answer
@(x)x(x!=median(x))\$\endgroup\$Giuseppe– Giuseppe2020年07月28日 15:32:43 +00:00Commented Jul 28, 2020 at 15:32 -
2\$\begingroup\$ @Giuseppe Good idea! And then
@(x)x(x~=mode(x))is two bytes shorter. You should post that yourself \$\endgroup\$Luis Mendo– Luis Mendo2020年07月28日 15:36:47 +00:00Commented Jul 28, 2020 at 15:36 -
1\$\begingroup\$ I can't believe I didn't think of that myself!! Thanks! \$\endgroup\$Giuseppe– Giuseppe2020年07月28日 15:44:37 +00:00Commented Jul 28, 2020 at 15:44
Wolfram Language (Mathematica), (削除) 21 (削除ここまで) (削除) 19 (削除ここまで) 17 bytes
f[c=a_...,b_,c]=b
-
\$\begingroup\$ also
Tally[#][[1, 1]] &for 18 \$\endgroup\$Kai– Kai2020年07月30日 20:27:05 +00:00Commented Jul 30, 2020 at 20:27 -
\$\begingroup\$ @Kai
Tallylists elements in order of first appearance. That function is equivalent to#[[1]]&. (besides that, it also contains redundant whitespace) \$\endgroup\$att– att2020年07月30日 20:41:12 +00:00Commented Jul 30, 2020 at 20:41 -
\$\begingroup\$ oops you're right, didn't test enough, I thought it would sort them by the number of times they appear. White space was inserted when I copied it out of mma \$\endgroup\$Kai– Kai2020年07月30日 20:54:44 +00:00Commented Jul 30, 2020 at 20:54
R, 25 bytes
a=sort(scan());a[a!=a[2]]
Sort the input, giving a. Now a[2] is one of the repeated values. Keep only the element not equal to a[2].
This ends up 4 bytes shorter than my best shot with a contingency table:
names(which(table(scan())<2))
-
\$\begingroup\$ How do you know that a[2] is one of the repeated values and not the unique value? After sorting, the unique value must be either the first or last element. But couldn't a[2] be the last element? \$\endgroup\$Stef– Stef2020年07月29日 12:05:55 +00:00Commented Jul 29, 2020 at 12:05
-
3\$\begingroup\$ @Stef
a[2]is the second element (R uses 1-based indexing), and the array of guaranteed to have at least 3 elements. \$\endgroup\$Giuseppe– Giuseppe2020年07月29日 12:40:14 +00:00Commented Jul 29, 2020 at 12:40 -
\$\begingroup\$ Thanks! I didn't know that R used 1-indexing. \$\endgroup\$Stef– Stef2020年07月29日 12:46:54 +00:00Commented Jul 29, 2020 at 12:46
Pyth, 4 bytes
-1 byte thanks to @FryAmTheEggman
ho/Q
Explanation
o : Order implicit input
/Q : by count of the element
h : then take the first element
PowerShell, 23 bytes
$args-ne($args|sort)[1]
Takes input by splatting. We apply a filter to the original array getting rid of the dupes by sorting it and taking the 2nd element.
-
1\$\begingroup\$ omg -
($args|group|where count -eq 1).namedoesn't even come close :( \$\endgroup\$Lieven Keersmaekers– Lieven Keersmaekers2020年07月29日 09:38:24 +00:00Commented Jul 29, 2020 at 9:38 -
2\$\begingroup\$ and
$args|group|? c* -eq 1|% n*too \$\endgroup\$mazzy– mazzy2020年07月29日 10:45:15 +00:00Commented Jul 29, 2020 at 10:45
T-SQL, 40 bytes
Input is a table variable
DECLARE @ table(v int)
INSERT @ values(1),(1),(2),(1)
SELECT*FROM @
GROUP BY v
HAVING SUM(1)=1
Another variation
T-SQL, 54 bytes
DECLARE @ table(v real)
INSERT @ values(1),(1),(2),(1)
SELECT iif(max(v)+min(v)<avg(v)*2,min(v),max(v))FROM @
-
1\$\begingroup\$ This is so straightforward and logical in SQL. Nice! \$\endgroup\$640KB– 640KB2020年08月02日 13:07:55 +00:00Commented Aug 2, 2020 at 13:07
-
\$\begingroup\$ @640KB thanks for your comment. I added a more obscure solution as well, it is a bit longer unfortunately . However this syntax could be converted to other languages and hopefully allow short answers \$\endgroup\$t-clausen.dk– t-clausen.dk2020年08月03日 11:10:07 +00:00Commented Aug 3, 2020 at 11:10
Brachylog, 4 bytes
oḅ∋≠
Takes a list and returns a singleton list.
Explanation
oḅ∋≠ Input is a list, say [4,4,3,4].
o Sort: [3,4,4,4]
ḅ Blocks of equal elements: [[3],[4,4,4]]
∋ Pick a block: [3]
≠ This block must have distinct elements (in this case, must have just one).
Output it implicitly.
RAD, 13 bytes
⍵[1⍳⍨+/⍵∘= ̈⍵]
The lack of a need for {} in this language really helps.
Explanation
⍵[1⍳⍨+/⍵∘= ̈⍵]
+/⍵∘= ̈⍵ count of each element's # of occurrences
1⍳⍨ first occurrence of a 1
⍵[ ] the argument at that index
Haskell, 30 bytes
f(x:y)|elem x y=f$y++[x]|1>0=x
Try it online! Footer stolen from coles answer.
If the first element is not in the remaining list, return it, otherwise rotate it to the end and try again.
K (ngn/k), (削除) 8 (削除ここまで) 6 bytes
Solution:
*<#'=:
Explanation:
*<#'=: / the solution
=: / group the input
#' / count length of each
< / sort ascending
* / take the first
Extra:
- -2 bytes thanks to
ngnby dropping the lambda
Wolfram Language (Mathematica), 19 bytes
Tr[#/.Median@#->0]&
Inspired by Kirill L.'s R submission
Finds the median, replaces its occurrences in the list with 0, and sums the list.
-
1
Vyxal, 3 bytes
Ċ↓h
Explained
Ċ↓h
Ċ # Get the counts of all items
↓ # Get the smallest item based on last item
h # Output the head of that list
Also, according to code-golf's statistics, only a small percentage of people who view my answers actually upvote them. So if you enjoy this answer, consider upvoting, it's free, and you can change your mind at any time (given you have ≥2k rep). Enjoy the answer.
Thunno 2, 2 bytes
Ṁo
Note that output as a singleton list is a default.
Explanation
Ṁo # Implicit input
o # Remove all instances of from the input
Ṁ # the mode of the input
# Implicit output
Screenshot
{kind=link}
ATOM, 15 chars, 18 bytes
Code:
*🔍2>🧵(1ドル🔍1ドル==*)
Usage:
[1,1,1,2,1,1] INTO *🔍2>🧵(1ドル🔍1ドル==*)
Try it live here
Explanation:
The ATOM language implicitly treats the expression as a function, where * is the parameter.
Therefore, it interprets the expression as
[1,1,1,2,1,1] 🔍2>🧵(1ドル🔍1ドル==*)
The 🔍 operator is an array filter, which takes an array on the left, and a function on the right. The expression to the right is implicitly parsed into a function. Therefore, it is searching the values in the input array for all values where the following returns true
2>🧵(1ドル🔍1ドル==*)
The 🧵 operator is array length, so it is searching for elements in the original input where (1ドル🔍1ドル==*) evaluates to an array of length 1 i.e. the unique element.
The first 1ドル looks for the variable on the stack at index 1, which is the original array (index 0 is the element in the array that is being iterated through, since we are inside the where operator).
Another 🔍 operator is performed on the array. 1ドル==* is now parsed to a new function, and 1ドル refers to the variable on the stack at index 1, which is the number being iterated through in the outer 🔍. The * refers to the immediate stack variable, which is the number being iterated through in the inner 🔍. Matches are returned, so if there are multiple instances of a number in the original array, the resulting array will be of length greater than or equal to 2. As such, only the unique element in the array will satisfy the 2>🧵(1ドル🔍1ドル==*) clause.
-
\$\begingroup\$ Welcome to CGCC! And excellent answer! It can even detect multiple unique values! \$\endgroup\$The Empty String Photographer– The Empty String Photographer2023年05月31日 09:30:49 +00:00Commented May 31, 2023 at 9:30
AWK, 34 bytes
{a[0ドル]++?c=0ドル:b+=0ドル}END{print b-c}
Takes positive integers separated by newlines. Let's call the unique number u and duplicates d.
{a[0ドル]++?c=0ドル:b+=0ドル}: Executed for each line.0ドルcontains the number on the line.ais used as a dict that counts the occurrences of each number.a[0ドル]++increments the count, and evaluates to falsy if it was encountered the first time, truthy otherwise.b+=0ドルis run exactly twice, when each ofuanddis read the first time. Therefore,bis equal tou+dat the end.c=0ドルis run for the rest of the time, and0ドルin this case is alwaysd.
END{print b-c}is run after all inputs are processed.b-cisu, and it is printed.
-
\$\begingroup\$ 33 bytes:
a[0ドル]++?0ドル=b-0ドル:b+=0ドル{}END{print}\$\endgroup\$Marius_Couet– Marius_Couet2024年02月02日 14:38:25 +00:00Commented Feb 2, 2024 at 14:38
[8, 8, 5]and[5, 8, 8]since there isn't one were the last element is unique and 3 element arrays are a corner cases in themselves. \$\endgroup\$