Inspired by a meme I saw earlier today.
{kind=link}
Challenge description
Consider an infinite alphabet grid:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
ABCDEFGHIJKLMNOPQRSTUVWXYZ
ABCDEFGHIJKLMNOPQRSTUVWXYZ
ABCDEFGHIJKLMNOPQRSTUVWXYZ
ABCDEFGHIJKLMNOPQRSTUVWXYZ
...
Take a word (CODEGOLF in this example) and make it a subsequence of the grid, replacing unused letters by a space and removing letters at the end of the infinite grid altogether:
C O
DE G O
L
F
Examples
STACKEXCHANGE
ST
A C K
E X
C H
A N
G
E
ZYXWVUTSRQPONMLKJIHGFEDCBA
Z
Y
X
W
V
U
T
S
R
Q
P
O
N
M
L
K
J
I
H
G
F
E
D
C
B
A
F
F
ANTIDISESTABLISHMENTARIANISM
A N T
I
D I S
E ST
AB L
I S
H M
E N T
A R
I
A N
I S
M
Notes
- Trailing whitespaces are allowed.
- You don't need to pad
(削除) the last (削除ここまで)any line with spaces. For example, if the input isABC, you may output justABCwithout 23 trailing spaces. - You may assume input will match
[A-Z]+regex. - Alternatively, you may use lower-case alphabet, in which case output will match
[a-z]+. - You must use a newline (
\n,\r\nor equivalent) to separate lines, that is a list of strings is not a proper output format. - This is a code-golf challenge, so make your code as short as possible!
60 Answers 60
Husk, 15 bytes
TṪS`?' €..."AZ"ġ>
Explanation
TṪS`?' €..."AZ"ġ> Implicit input, e.g. "HELLO"
ġ> Split into strictly increasing substrings: x = ["H","EL","LO"]
..."AZ" The uppercase alphabet (technically, the string "AZ" rangified).
Ṫ Outer product of the alphabet and x
S`?' € using this function:
Arguments: character, say c = 'L', and string, say s = "EL".
€ 1-based index of c in s, or 0 if not found: 2
S`?' If this is truthy, then c, else a space: 'L'
This gives, for each letter c of the alphabet,
a string of the same length as x,
containing c for those substrings that contain c,
and a space for others.
T Transpose, implicitly print separated by newlines.
C (gcc), 69 bytes
i;f(char*s){for(i=64;*s;putchar(*s^i?32:*s++))i+=i^90?1:puts("")-26;}
Java 10, (削除) 161 (削除ここまで) (削除) 159 (削除ここまで) 152 bytes
s->{var x="";int p=0;for(var c:s)x+=p<(p=c)?c:";"+c;for(var y:x.split(";"))System.out.println("ABCDEFGHIJKLMNOPQRSTUVWXYZ".replaceAll("[^"+y+"]"," "));}
-2 bytes thanks to @Nevay.
-7 byte printing directly instead of returning a String, and converting to Java 10.
Explanation:"
s->{ // Method with String parameter and no return-type
var x=""; // Temp-String
int p=0; // Previous character (as integer), starting at 0
for(var c:s) // Loop (1) over the characters of the input
x+=p<(p=c)? // If the current character is later in the alphabet
// (replace previous `p` with current `c` afterwards)
c // Append the current character to Temp-String `x`
: // Else:
";"+c; // Append a delimiter ";" + this character to Temp-String `x`
for(var y:x.split(";")) // Loop (2) over the String-parts
System.out.println( // Print, with trailing new-line:
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
// Take the alphabet,
.replaceAll("[^"+y+"]"," "));}
// and replace all letters not in the String-part with a space
The first part of the method splits the input-word into parts with a delimiter.
For example: CODEGOLF → CO;DEGO;L;F or BALLOON → B;AL;LO;O;N.
The second part loops over these parts, and uses the regex [^...] to replace everything that isn't matched with a space.
For example .replaceAll("[^CO]"," ") leaves the C, and O, and replaces everything else with a space.
MATL, (削除) 24 (削除ここまで) 23 bytes
''jt8+t1)wdh26X\Ys(26e!
Uses lowercase letters.
Try it at MATL Online!
Explanation
'' % Push empty string
jt % Push input string. Duplicate
8+ % Add 8 to each char (ASCII code). This transforms 'a' 105,
% 'b' into 106, which modulo 26 correspond to 1, 2 etc
t1) % Duplicate. Get first entry
wd % Swap. COnsecutive differences.
h % Concatenate horizontally
26X\ % 1-based modulo 26. This gives a result from 1 to 26
Ys % Cumulative sum
( % Write values (converted into chars) at specified positions
% of the initially empty string
26e % Reshape into a 26-row char matrix, padding with char 0
! % Transpose. Implicitly display. Char 0 is shown as space
-
\$\begingroup\$ The link you've posted is for 46 bytes version. \$\endgroup\$user72349– user723492017年09月02日 14:03:45 +00:00Commented Sep 2, 2017 at 14:03
-
\$\begingroup\$ @ThePirateBay Thanks!! I knew I hadn't updated something! \$\endgroup\$Dom Hastings– Dom Hastings2017年09月02日 14:06:07 +00:00Commented Sep 2, 2017 at 14:06
Python 2, 92 bytes
f=lambda x,y=65:x and(y<=ord(x[0])and" "*(ord(x[0])-y)+x[0]+f(x[1:],-~ord(x[0]))or"\n"+f(x))
-
3
JavaScript (ES6), 79
Edit As a leading newline is accepted, I can save 2 bytes
s=>eval("for(o='',v=i=0;c=s.charCodeAt(i);v%=27)o+=v++?c-63-v?' ':s[i++]:`\n`")
For 1 byte more, I can accept lowercase or uppercase input:
s=>eval("for(o='',v=i=0;c=s[i];v%=27)o+=v++?parseInt(c,36)-8-v?' ':s[i++]:`\n`")
Less golfed
s=>{
var i,o,c,v
for(o = '', v = 1, i = 0; c = s.charCodeAt(i); v %= 27)
o += v++ ? c-63-v ? ' ' : s[i++] : '\n'
return o
}
Test
f=s=>eval("for(o='',v=i=0;c=s.charCodeAt(i);v%=27)o+=v++?c-63-v?' ':s[i++]:`\n`")
function update() {
var i=I.value
i=i.replace(/[^A-Z]/gi,'').toUpperCase()
O.textContent=f(i)
}
update()<input id=I value='BALLOON' oninput='update()' >
<pre id=O></pre>-
\$\begingroup\$ You can replace the
\nwith a literal newline inside backticks for -1 byte. \$\endgroup\$Justin Mariner– Justin Mariner2017年09月02日 20:41:29 +00:00Commented Sep 2, 2017 at 20:41 -
\$\begingroup\$ @JustinMariner no I can't, not inside the double quote in eval \$\endgroup\$edc65– edc652017年09月02日 20:48:17 +00:00Commented Sep 2, 2017 at 20:48
-
\$\begingroup\$ Oh right, that's a shame. My bad. \$\endgroup\$Justin Mariner– Justin Mariner2017年09月02日 20:49:11 +00:00Commented Sep 2, 2017 at 20:49
-
\$\begingroup\$
OI<1®;->>20円;to save one byte (I actually did>20円;œṗµØAf€ȯ6ドルµ€Yfor 18 too, which I personally find easier to parse) \$\endgroup\$Jonathan Allan– Jonathan Allan2017年09月03日 00:32:13 +00:00Commented Sep 3, 2017 at 0:32 -
\$\begingroup\$ @JonathanAllan I think that would fail for
BALLOONor something. \$\endgroup\$Erik the Outgolfer– Erik the Outgolfer2017年09月03日 12:07:44 +00:00Commented Sep 3, 2017 at 12:07 -
\$\begingroup\$ You are correct, yes - so it would required another byte with something like
<21円;¬; oh well. \$\endgroup\$Jonathan Allan– Jonathan Allan2017年09月03日 13:47:04 +00:00Commented Sep 3, 2017 at 13:47 -
\$\begingroup\$ @JonathanAllan Anyways, I'll implement your idea in my answer...done. \$\endgroup\$Erik the Outgolfer– Erik the Outgolfer2017年09月03日 13:53:19 +00:00Commented Sep 3, 2017 at 13:53
Japt, (削除) 18 (削除ここまで) 16 bytes
-2 bytes thanks to @Shaggy
;ò ̈ £B®kX ?S:Z
·
Uppercase input only.
Explanation
;
Switch to alternate variables, where B is the uppercase alphabet.
ò ̈
Split the input string between characters where the first is greater than or equal to ( ̈) the second.
£
Map each partition by the function, where X is the current partition.
B®
Map each character in the uppercase alphabet to the following, with Z being the current letter.
kX
Remove all letters in the current partition from the current letter. If the current letter is contained in the current partition, this results in an empty string.
?S:Z
If that is truthy (not an empty string), return a space (S), otherwise return the current letter.
·
Join the result of the previous line with newlines and print the result.
-
\$\begingroup\$ 10 bytes for
r"[^{Z}]"Sseems a bit ridiculous, but I can't find any better way either... \$\endgroup\$ETHproductions– ETHproductions2017年09月02日 20:34:55 +00:00Commented Sep 2, 2017 at 20:34 -
-
-
\$\begingroup\$ @Shaggy Good thinking with
kX! \$\endgroup\$Justin Mariner– Justin Mariner2017年09月03日 20:01:44 +00:00Commented Sep 3, 2017 at 20:01 -
\$\begingroup\$ Actually I think you can change
kX ?S:ZtooX ªSto save two bytes \$\endgroup\$ETHproductions– ETHproductions2017年09月05日 03:10:36 +00:00Commented Sep 5, 2017 at 3:10
C (gcc), (削除) 91 (削除ここまで) 63 bytes
-28 thanks to ASCII-only
_;f(char*s){for(_=64;*s;)putchar(++_>90?_=64,10:*s^_?32:*s++);}
Previous:
i,j;f(char*s){while(s[i]){for(j=65;j<91;j++)s[i]==j?putchar(s[i++]):printf(" ");puts("");}}
Yes, there's a shorter solution, but I noticed after I wrote this one... Try it online!
-
\$\begingroup\$ 82 bytes, 80 if leading newline is allowed \$\endgroup\$ASCII-only– ASCII-only2017年09月05日 22:24:41 +00:00Commented Sep 5, 2017 at 22:24
-
\$\begingroup\$ 73 \$\endgroup\$ASCII-only– ASCII-only2017年09月05日 22:30:20 +00:00Commented Sep 5, 2017 at 22:30
-
\$\begingroup\$ 63 \$\endgroup\$ASCII-only– ASCII-only2017年09月05日 23:08:10 +00:00Commented Sep 5, 2017 at 23:08
Retina, 80 bytes
^
;¶
{`;.*
¶;ABCDEFGHIJKLMNOPQRSTUVWXYZ
¶¶
¶
)+`;(.*)(.)(.*¶)2円
$.1$* 2ドル;3ドル
;.*
There is always exactly one leading newline. The code somewhat clunkily prepends the word with the alphabet along with a marker (semicolon). It then moves the marker up to the first letter of the word, while changing all other letters it passes into spaces. It also removes the first letter of the word. It repeats this until the first letter of the word isn't after the marker anymore. Then it clears that marker and the rest of the alphabet, and replaces it with a new line and the alphabet with a marker again. It keeps repeating this until the input word is empty, then it cleans up the last alphabet and marker, leaving the desired output.
05AB1E, 18 bytes
ćIgμ¶?AvDyÊið?ë1⁄4?ć
Got trouble with 05AB1E ć (extract 1) leaving an empty string/list on the stack after the last element is extracted. This solution would be 1-2 bytes shorter if it weren't for that.
ćIgμ¶?AvDyÊið?ë1⁄4?ć Implicit input
ć Extract the 1st char from the string
Igμ While counter != length of the string
¶? Print a newline
Av For each letter of the lowercased alphabet
DyÊ Is the examined character different from the current letter?
ið? If true, then print a space
ë1⁄4?ć Else increment the counter, print the letter and push
the next character of the string on the stack
-
\$\begingroup\$ Actually,
ð,means "print a space and a newline". \$\endgroup\$Erik the Outgolfer– Erik the Outgolfer2017年09月04日 13:56:24 +00:00Commented Sep 4, 2017 at 13:56 -
\$\begingroup\$ You're right. Fixed the code to actually print a newline. \$\endgroup\$scottinet– scottinet2017年09月04日 14:00:54 +00:00Commented Sep 4, 2017 at 14:00
Mathematica, 101 bytes
StringRiffle[
Alphabet[]/.#->" "&/@
(Except[#|##,_String]&@@@
Split[Characters@#,#==1&@*Order]),"
",""]&
Split the input into strictly increasing letter sequences, comparing adjacent letters with Order. If Order[x,y] == 1, then x precedes y in the alphabet and thus can appear on the same line.
For each sequence of letters, create a pattern to match strings Except for those letters; #|## is a shorthand for Alternatives. Replace letters of the Alphabet that match the pattern with spaces.
Illustration of the intermediate steps:
"codegolf";
Split[Characters@#,#==1&@*Order] &@%
Except[#|##,_String]&@@@ #&@%
Alphabet[]/.#->" "&/@ %
{{"c", "o"}, {"d", "e", "g", "o"}, {"l"}, {"f"}}
{Except["c" | "c" | "o", _String],
Except["d" | "d" | "e" | "g" | "o", _String],
Except["l" | "l", _String],
Except["f" | "f", _String]}
{{" "," ","c"," "," "," "," "," "," "," "," "," "," "," ","o"," "," "," "," "," "," "," "," "," "," "," "},
{" "," "," ","d","e"," ","g"," "," "," "," "," "," "," ","o"," "," "," "," "," "," "," "," "," "," "," "},
{" "," "," "," "," "," "," "," "," "," "," ","l"," "," "," "," "," "," "," "," "," "," "," "," "," "," "},
{" "," "," "," "," ","f"," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "}}
K (ngn/k), (削除) 29 (削除ここまで) 28 bytes
{{x@x?`c65ドル+!26}'(&~>':x)_x}
{ } function with argument x
>':x for each char, is it greater than the previous char?
~ negate
& where (at which indices) do we have true
( )_x cut x at those indices, return a list of strings
{ }' for each of those strings
`c65ドル+!26
the English alphabet
x? find the index of the first occurrence of each letter in x, use 0N (a special "null" value) if not found
x@ index x with that; indexing with 0N returns " ", so we get a length-26 string in which the letters from x are at their alphabetical positions and everything else is spaces
05AB1E, (削除) 21 (削除ここまで) (削除) 19 (削除ここまで) 17 bytes
×ばつyAykǝ,
Ç push a list of ascii values of the input [84, 69, 83, 84]
ü@ determine which letter is >= the next letter [1, 0, 0]
0š prepend a 0 (false) to that list [0, 1, 0, 0]
Å¡ split input on true values [["T"], ["E", "S", "T"]]
v for each list entry
×ばつ push 26 spaces
y push list entry (letters)
Ayk push the positions of that letters in the alphabet
ǝ replace characters c in string a with letters b
, print the resulting string
implicitly close for-loop
Hexagony, 91 bytes
A"$>}\$<>~,<.'~<\.';<.>$${}\../<..>=<...-/.$/=*=32;.>~<>"){-\}.>_{A}\\../010<$..>;=~<$@{{Z'
More readably:
A " $ > } \
$ < > ~ , < .
' ~ < \ . ' ; <
. > $ $ { } \ . .
/ < . . > = < . . .
- / . $ / = * = 3 2 ;
. > ~ < > " ) { - \
} . > _ { A } \ \
. . / 0 1 0 < $
. . > ; = ~ <
$ @ { { Z '
And with color paths: enter image description here
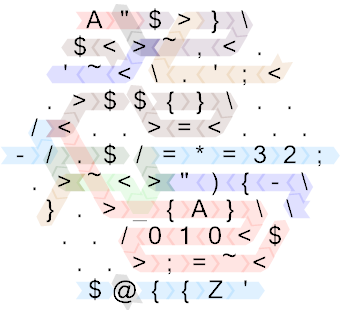{kind=link}
Zsh, 65 bytes
-4 bytes thanks to @pxeger, -2 bytes thanks to @roblogic
repeat $#1;echo&&for y ({A-Z})printf ${(Ml:1:)1[1]%$y}&&1=${1#$y}
(削除) Try it online!
Try it online!
(削除ここまで)
Try it online!
Append to $s a (M) matched letter, (l:1:) left-padded to one character, then remove the letter if it matches the start of 1ドル.
-
1\$\begingroup\$ -4 on the second solution: Try it online! \$\endgroup\$pxeger– pxeger2021年05月11日 12:29:59 +00:00Commented May 11, 2021 at 12:29
-
\$\begingroup\$ Rules don't permit leading spaces, but nice 3 byte save \$\endgroup\$GammaFunction– GammaFunction2021年05月11日 19:34:15 +00:00Commented May 11, 2021 at 19:34
-
\$\begingroup\$ It is allowed: "Are leading newlines allowed?" -- "Sure, as long as it doesn't mess up grid structure." \$\endgroup\$pxeger– pxeger2021年05月12日 06:51:38 +00:00Commented May 12, 2021 at 6:51
-
\$\begingroup\$ Ah, I didn't read the comments, just the main post. \$\endgroup\$GammaFunction– GammaFunction2021年05月12日 11:37:24 +00:00Commented May 12, 2021 at 11:37
-
1\$\begingroup\$ Save another byte using
setopt braceccl:) try it online \$\endgroup\$roblogic– roblogic2023年01月26日 08:10:00 +00:00Commented Jan 26, 2023 at 8:10
Retina, (削除) 130 (削除ここまで) (削除) 126 (削除ここまで) 123 bytes
$
¶Z
{T`L`_o`.+$
}`$
Z
+`(?<=(.)*)((.).*¶(?<-1>.)*(?(1)(?!)).+3円.*$)
2ドル
(?<=(.)*)((.).*¶(?<-1>.)*(?<-1>3円.*$))
¶2ドル
}`¶.*$
Try it online! Edit: Saved (削除) 4 (削除ここまで) 7 bytes by using a better alphabet generator. Explanation:
$
¶Z
{T`L`_o`.+$
}`$
Z
Append the alphabet.
+`(?<=(.)*)((.).*¶(?<-1>.)*(?(1)(?!)).+3円.*$)
2ドル
Align as many letters as possible with their position in the alphabet.
(?<=(.)*)((.).*¶(?<-1>.)*(?<-1>3円.*$))
¶2ドル
Start a new line before the first letter that could not be aligned.
}`¶.*$
Delete the alphabet, but then do everything over again until there are no misaligned letters.
-
\$\begingroup\$ This seems to print only one line, not aligning letters on subsequent lines. \$\endgroup\$Justin Mariner– Justin Mariner2017年09月02日 18:23:52 +00:00Commented Sep 2, 2017 at 18:23
-
\$\begingroup\$ @JustinMariner My bad, I made a typo in my last golf and failed to check it properly. \$\endgroup\$Neil– Neil2017年09月02日 19:29:12 +00:00Commented Sep 2, 2017 at 19:29
Bespoke, 412 bytes
GRID:A-B-C
letters forming words go in grid
to show examples for it:o,pelican,crested so smooth.god,oh,of breeze
blackout poetry utilizes letters of actual text to do words that go in words
but if you do blackout poetry alphabet grids,it gets simpler to see
it all is spelled somewhere here in my grids
looping all values of ABC to do check when char is equal
spacings or letters go out,as a repetition renews it
O, pelican, crested so smooth. God, oh, of breeze!
This program keeps track of an index from 1 to 26, representing the current letter. Thanks to ASCII being designed with the alphabet in mind, the 1-based index of an uppercase (or lowercase) letter can be found by taking its ASCII code modulo 32; this is what the index is compared to.
Golfscript, (削除) 22 (削除ここまで) 21 bytes
-1 byte thanks to careful final redefining of the n built-in.
{.n>{}{'
'\}if:n}%:n;
Explanation (with a slightly different version):
{.n>{}{"\n"\}if:n}%:n; # Full program
{ }% # Go through every character in the string
.n> if # If ASCII code is greater than previous...
# (n means newline by default, so 1st char guaranteed to fit)
{} # Do nothing
{"\n"\} # Else, put newline before character
:n # Redefine n as the last used character
:n; # The stack contents are printed at end of execution
# Literally followed by the variable n, usually newline
# So because n is by now an ASCII code...
# ...redefine n as the new string, and empty the stack
Python 3, (削除) 87 (削除ここまで) 85 bytes
def f(s,l=65):c,*t=s;o=ord(c)-l;return o<0and'\n'+f(s)or' '*o+c+(t and f(t,o-~l)or'')
q/kdb+, (削除) 48 (削除ここまで) 45 bytes
Solution:
-1{@[26#" ";.Q.A?x;:;x]}@/:(0,(&)(<=':)x)_x:;
Note: Link is to a K (oK) port of this solution as there is no TIO for q/kdb+.
Examples:
q)-1{@[26#" ";.Q.A?x;:;x]}@/:(0,(&)(<=':)x)_x:"STACKEXCHANGE";
ST
A C K
E X
C H
A N
G
E
q)-1{@[26#" ";.Q.A?x;:;x]}@/:(0,(&)(<=':)x)_x:"BALLOON";
B
A L
L O
O
N
Explanation:
Q is interpreted right-to-left. The solution is split into two parts. First split the string where the next character is less than or equal to the current:
"STACKEXCHANGE" -> "ST","ACK","EX","CH","AN","G","E"
Then take a string of 26 blanks, and apply the input to it at the indices where the input appears in the alphabet, and print to stdout.
"__________________________" -> __________________ST______
Breakdown:
-1{@[26#" ";.Q.A?x;:;x]}each(0,where (<=':)x) cut x:; / ungolfed solution
-1 ; / print to stdout, swallow return value
x: / store input as variable x
cut / cut slices x at these indices
( ) / do this together
(<=':)x / is current char less-or-equal (<=) than each previous (':)?
where / indices where this is true
0, / prepended with 0
each / take each item and apply function to it
{ } / lambda function with x as implicit input
@[ ; ; ; ] / apply[variable;indices;function;arguments]
26#" " / 26 take " " is " "...
.Q.A?x / lookup x in the uppercase alphabet, returns indice(s)
: / assignment
x / the input to apply to these indices
Notes:
- -3 bytes by replacing prev with the K4 version
Charcoal, 15 bytes
Fθ«J⌕αι+j‹⌕αιiι
Try it online! Link is to verbose version of code. Explanation:
θ Input string
F « Loop over characters
α α Uppercase letters predefined variable
ι ι Current character
⌕ ⌕ Find index
i Current X co-ordinate
‹ Compare
j Current Y co-ordinate
+ Sum
J Jump to aboslute position
ι Print current character
R, (削除) 129 (削除ここまで) 117 bytes
function(s){z={}
y=diff(x<-utf8ToInt(s)-64)
z[diffinv(y+26*(y<0))+x[1]]=LETTERS[x]
z[is.na(z)]=" "
write(z,1,26,,"")}
Explanation (ungolfed):
function(s){
z <- c() # initialize an empty vector
x <- utf8ToInt(s)-64 # map to char code, map to range 1:26
y <- diff(x) # successive differences of x
idx <- cumsum(c( # indices into z: cumulative sum of:
x[1], # first element of x
ifelse(y<=0,y+26,y))) # vectorized if: maps non-positive values to themselves + 26, positives to themselves
z[idx] <- LETTERS[x] # put letters at indices
z[is.na(z)] <- " " # replace NA with space
write(z,"",26,,"") # write z as a matrix to STDOUT ("") with 26 columns and empty separator.
R, 95 bytes
Just run through the upper case alphabet repeatedly while advancing a counter by 1 if you encounter the letter in the counter position of the word and printing out the letter, a space otherwise.
function(s)while(F>""){for(l in LETTERS)cat("if"((F=substr(s,T,T))==l,{T=T+1;l}," "));cat("
")}
GolfScript, 37 bytes
64:a;{.a>{}{'
'64円:a;}if.a-(' '*\:a}%
I did a Golfscript one under a different name, but it had incorrect output.
Ruby -n, 62 bytes
Scans the input string for sequences of increasing letters, and for each sequence, replace letters not in the sequence with spaces.
g=*?A..?Z
$_.scan(/#{g*??}?/){puts g.join.tr"^#$&"," "if$&[0]}
Powershell, (削除) 70 (削除ここまで) 63 bytes
-7 bytes thanks @Veskah
$args|%{if($_-le$p){$x;rv x}
$x=("$x"|% *ht($_-65))+($p=$_)}
$x
Explanation:
For each character in the splatted argument:
- Output string
$xand clear$xvalue (rvis alias for Remove-Variable), if a code of the current character less or equivalent (-le) to a code of the previous character. - Append spaces and the current character to
$x, store it to$x. Also it freshes a previous character value.
Output last $x.
-
1\$\begingroup\$ 63 Bytes using splatting. Tried to use
|% *htto save some bytes but looks like it broke even. \$\endgroup\$Veskah– Veskah2019年10月09日 17:10:14 +00:00Commented Oct 9, 2019 at 17:10
BALLOON(two adjacent characters that are the same). \$\endgroup\$