I recently created a new language called ;# (pronounced "Semicolon Hash") which only has two commands:
; add one to the accumulator
# modulo the accumulator by 127, convert to ASCII character and output without a newline. After this, reset the accumulator to 0. Yes, 127 is correct.
Any other character is ignored. It has no effect on the accumulator and should do nothing.
Your task is to create an interpreter for this powerful language!
It should be either a full program or a function that will take a ;# program as input and produce the correct output.
Examples
Output: Hello, World!
Program: ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#
Output: ;#
Program: ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#
Output: 2 d����{���
Program: ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;hafh;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;f;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;###ffh#h#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;ffea;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;aa;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#au###h;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;h;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;o
Output: Fizz Buzz output
Program: link below
Output: !
Program: ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#
-
1\$\begingroup\$ Is it acceptable if an interpreter doesn't terminate its execution at the end of the input but instead keeps looping indefinitely without producing extra output? \$\endgroup\$Leo– Leo2017年05月22日 09:26:15 +00:00Commented May 22, 2017 at 9:26
-
6\$\begingroup\$ The second example makes me wonder about a program to encode a program to produce an output... recursive compilation! \$\endgroup\$frarugi87– frarugi872017年05月22日 09:29:14 +00:00Commented May 22, 2017 at 9:29
-
1\$\begingroup\$ @iamnotmaynard Semicolon Hash \$\endgroup\$caird coinheringaahing– caird coinheringaahing ♦2017年05月23日 15:09:07 +00:00Commented May 23, 2017 at 15:09
-
5\$\begingroup\$ Maybe Wink Hash would be easier to say \$\endgroup\$James Waldby - jwpat7– James Waldby - jwpat72017年05月23日 17:42:41 +00:00Commented May 23, 2017 at 17:42
-
2\$\begingroup\$ The Pastebin link appears to be dead. \$\endgroup\$EasyasPi– EasyasPi2021年05月22日 04:29:06 +00:00Commented May 22, 2021 at 4:29
141 Answers 141
Python 3, (削除) 69 (削除ここまで) 68 bytes
-1 byte thanks to @WheatWizard
i=0
for c in input():
i+=c==';'
if'#'==c:print(end=chr(i%127));i=0
-
4\$\begingroup\$ You can save a byte by reversing your
if. Try it online! \$\endgroup\$2017年05月21日 23:30:38 +00:00Commented May 21, 2017 at 23:30
JavaScript (ES6), (削除) 76 (削除ここまで) (削除) 82 (削除ここまで) 80 bytes
s=>s.replace(/./g,c=>c=='#'?String.fromCharCode(a%(a=127)):(a+=(c==';'),''),a=0)
Demo
let f =
s=>s.replace(/./g,c=>c=='#'?String.fromCharCode(a%(a=127)):(a+=(c==';'),''),a=0)
console.log(JSON.stringify(f(";;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#")))
console.log(JSON.stringify(f(";;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#")))
console.log(JSON.stringify(f(";;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;hafh;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;f;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;###ffh#h#;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;ffea;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;aa;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#au###h;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;h;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;o")))
console.log(JSON.stringify(f(";;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;#")))Recursive version, (削除) 82 (削除ここまで) 77 bytes
Saved 5 bytes thanks to Neil
This one is likely to crash for large inputs such as the Fizz Buzz example.
f=([c,...s],a=0)=>c?c=='#'?String.fromCharCode(a%127)+f(s):f(s,a+(c==';')):""
-
\$\begingroup\$ I think
f(s,a+(c==';'))might knock three bytes off your recursive version. \$\endgroup\$Neil– Neil2017年05月22日 08:52:20 +00:00Commented May 22, 2017 at 8:52 -
\$\begingroup\$ @Neil It actually saves 5 bytes. :-) \$\endgroup\$Arnauld– Arnauld2017年05月22日 11:10:05 +00:00Commented May 22, 2017 at 11:10
-
\$\begingroup\$ I feel really silly now. I originally had a buggy version, and subtracted 2 bytes to fix the bug. But I had miscounted and the buggy version actually saved 7 bytes... \$\endgroup\$Neil– Neil2017年05月22日 11:23:40 +00:00Commented May 22, 2017 at 11:23
Java 8, 100 bytes
s->{int i=0;for(byte b:s.getBytes()){if(b==59)i++;if(b==35){System.out.print((char)(i%127));i=0;}}};
-
3\$\begingroup\$ Welcome to the site! :) \$\endgroup\$DJMcMayhem– DJMcMayhem2017年05月22日 16:25:08 +00:00Commented May 22, 2017 at 16:25
-
\$\begingroup\$ I added a link to an online interpreter with the FizzBuzz example for you (link text was too long to fit in a comment) \$\endgroup\$Jonathan Allan– Jonathan Allan2017年05月22日 20:26:57 +00:00Commented May 22, 2017 at 20:26
-
\$\begingroup\$ Java uses UTF-16 for its programs. So, these aren't 100 bytes but 100 characters. \$\endgroup\$Gerold Broser– Gerold Broser2017年05月23日 12:50:51 +00:00Commented May 23, 2017 at 12:50
-
5\$\begingroup\$ @GeroldBroser Unicode is a character set: UTF-8 and UTF-16 are two encodings of that character set. ASCII source is perfectly valid as a Java program, and I have plenty of Java source files encoded in ASCII (which is also valid UTF-8, hence also a Unicode encoding). \$\endgroup\$user18932– user189322017年05月23日 20:24:23 +00:00Commented May 23, 2017 at 20:24
-
1\$\begingroup\$ Entirely golfed, for 81 bytes as a
Consumer<char[]>:s->{char i=0;for(int b:s){if(b==59)i++;if(b==35){System.out.print(i%=127);i=0;}}}\$\endgroup\$Olivier Grégoire– Olivier Grégoire2017年08月11日 09:55:51 +00:00Commented Aug 11, 2017 at 9:55
Japt, 18 bytes
®è'; %# d}'# ë ̄JThere's an unprintable \x7f char after %#. Test it online!
How it works
® è'; %# d}'# ë ̄ J
mZ{Zè'; %127 d}'# ë s0,J
// Implicit: operate on input string
mZ{ }'# // Split the input at '#'s, and map each item Z to
Zè'; // the number of semicolons in Z,
%127 // mod 127,
d // turned into a character.
m '# // Rejoin the list on '#'. At this point the Hello, World! example
// would be "H#e#l#l#o#,# #W#o#r#l#d#!#" plus an null byte.
ë // Take every other character. Eliminates the unnecessary '#'s.
̄J // Slice off the trailing byte (could be anything if there are
// semicolons after the last '#').
// Implicit: output result of last expression-
2\$\begingroup\$ D'oh, should have checked the answers! Just spent some time on this only to find you'd beaten me to the punch.
q'# ®è'; u# dì¯Jalso works for the same score. \$\endgroup\$Shaggy– Shaggy2017年05月22日 10:35:13 +00:00Commented May 22, 2017 at 10:35
Python, 65 bytes
This is a golf of this earlier answer.
lambda t:''.join(chr(x.count(';')%127)for x in t.split('#')[:-1])
Explanation
This is a pretty straightforward answer we determine how many ;s are between each # and print the chr mod 127. The only thing that might be a little bit strange is the [:-1]. We need to drop the last group because there will be no # after it.
For example
;;#;;;;#;;;;;#;;;
Will be split into
[';;',';;;;',';;;;;',';;;']
But we don't want the last ;;; because there is no # after it to print the value.
-
1\$\begingroup\$ I was busy trying to get all tests in one TIO link. Was chr for chr except
tandx. \$\endgroup\$Jonathan Allan– Jonathan Allan2017年05月21日 23:54:53 +00:00Commented May 21, 2017 at 23:54
Retina, (削除) 336 (削除ここまで) (削除) 63 (削除ここまで) (削除) 67 (削除ここまで) (削除) 65 (削除ここまで) (削除) 66 (削除ここまで) (削除) 62 (削除ここまで) 59 bytes
T`;#-ÿ` ̄_
;{127}|;+$
(^| ̄)
̄
+T`-~`_-`[^ ̄]
T\` ̄`
Readable version using hypothetical escape syntax:
T`;#\x01-ÿ`\x01 ̄_
;{127}|;+$
(^| ̄)\x01\x01
̄\x02
+T`\x01-~`_\x03-\x7f`[^\x01 ̄]\x01
T\` ̄`
Does not print NUL bytes, because TIO doesn't allow them in the source code. (削除) Also prints an extra newline at the end, but I guess it can't do otherwise. (削除ここまで) Trailing newline suppressed thanks to @Leo.
-273 (!) bytes thanks to @ETHproductions.
-2 bytes thanks to @ovs.
-3 bytes thanks to @Neil. Check out their wonderful 34-byte solution.
-
1\$\begingroup\$ Oh my word. But can you not save a thousand bytes with
+T`\x01-~`_\x03-\x7f`[^\x01¯]\x01? (including the unprintables as single chars, of course) \$\endgroup\$ETHproductions– ETHproductions2017年05月21日 23:41:50 +00:00Commented May 21, 2017 at 23:41 -
\$\begingroup\$ @ETHproductions Of course you can. Thank you! :) \$\endgroup\$eush77– eush772017年05月21日 23:51:16 +00:00Commented May 21, 2017 at 23:51
-
1\$\begingroup\$ Currently the last letter is always in the output, even if there is no trailing
#in the input. You can fix it by changing your second stage to(;{127}|;+$)\$\endgroup\$ovs– ovs2017年05月22日 05:10:25 +00:00Commented May 22, 2017 at 5:10 -
1\$\begingroup\$ Do you need the +` on the third line? As you remove the entire match, there should be nothing left to replace in the second iteration. \$\endgroup\$ovs– ovs2017年05月22日 09:14:58 +00:00Commented May 22, 2017 at 9:14
-
1\$\begingroup\$ I think I can do this in 34 bytes:
T`;#\x01-ÿ`\x80\x7F_\x80+$(empty line)\+T`\x7Fo`\x01-\x80_`\x80[^\x80](using hexadecimal escapes to represent unprintables). Outputs \x7F instead of nulls. \$\endgroup\$Neil– Neil2017年05月22日 09:45:19 +00:00Commented May 22, 2017 at 9:45
Ruby, (削除) 41 (削除ここまで) (削除) 35 (削除ここまで) 34 characters
((削除) 40 (削除ここまで) (削除) 34 (削除ここまで) 33 characters code + 1 character command line option)
gsub(/.*?#/){putc$&.count ?;%127}
Thanks to:
- Jordan for suggesting to use
putcto not need explicit conversion with.chr(6 characters) - Kirill L. for finding the unnecessary parenthesis (1 character)
Sample run:
bash-4.4$ ruby -ne 'gsub(/.*?#/){putc$&.count ?;%127}' < '2d{.;#' | od -tad1
0000000 2 etb d nul nul nul nul { nul nul nul
50 23 100 0 0 0 0 123 0 0 0
0000013
-
1\$\begingroup\$ To my own surprise, you can actually drop parentheses after count to save a byte \$\endgroup\$Kirill L.– Kirill L.2018年08月10日 11:35:44 +00:00Commented Aug 10, 2018 at 11:35
-
1\$\begingroup\$ Thank you, @Deadcode. BTW,
gsub(/.*?#/){putc$&.count(?;)%127}is shorter. \$\endgroup\$manatwork– manatwork2020年01月23日 13:46:22 +00:00Commented Jan 23, 2020 at 13:46 -
1
-
1\$\begingroup\$ Try it online. The regex should use
;instead of.seems like to adhere to the requirements. Otherwise awesome answer \$\endgroup\$south– south2022年11月11日 03:38:16 +00:00Commented Nov 11, 2022 at 3:38 -
1\$\begingroup\$ Oops, you are right, @south. However changing to
;only solves your test case, but will fail on a mixture of valid and invalid input. Try it online! So I revert to previous version. \$\endgroup\$manatwork– manatwork2022年11月14日 00:14:43 +00:00Commented Nov 14, 2022 at 0:14
Python 3, 69 Bytes
Improved, thanks to @Wheat Wizard, @Uriel
print(''.join(chr(s.count(';')%127)for s in input().split('#')[:-1]))
-
3\$\begingroup\$ Welcome to Programming Puzzles and Code Golf! The objective here is to make the code as short as possible (in bytes), so you need to include the byte count in the header :). \$\endgroup\$Adnan– Adnan2017年05月21日 20:13:15 +00:00Commented May 21, 2017 at 20:13
-
\$\begingroup\$ Thanks for explaining, didn't know that. I'll work on it then. \$\endgroup\$Djaouad– Djaouad2017年05月21日 20:15:02 +00:00Commented May 21, 2017 at 20:15
-
2\$\begingroup\$ You can remove the space after the
:s. \$\endgroup\$Pavel– Pavel2017年05月21日 21:02:29 +00:00Commented May 21, 2017 at 21:02 -
1\$\begingroup\$ I count 74 bytes. tio.run/nexus/… \$\endgroup\$Dennis– Dennis2017年05月21日 22:34:07 +00:00Commented May 21, 2017 at 22:34
-
2\$\begingroup\$ Also,
';'==csaves a space, but not usingifstatements at all would be even shorter. \$\endgroup\$Dennis– Dennis2017年05月21日 22:39:37 +00:00Commented May 21, 2017 at 22:39
><>, 35 bytes
>i:0(?;:'#'=?v';'=?0
^ [0o%'␡'l~<
Try it online! Replace ␡ with 0x7F, ^?, or "delete".
Main loop
>i:0(?;:'#'=?v
^ <
This takes a character of input (i), checks if its less than zero i.e. EOF (:0() and terminates the program if it is (?;). Otherwise, check if the input is equal to # (:'#'=). If it is, branch down and restart the loop (?v ... ^ ... <).
Counter logic
';'=?0
Check if the input is equal to ; (';'=). If it is, push a 0. Otherwise, do nothing. This restarts the main loop.
Printing logic
> '#'=?v
^ [0o%'␡'l~<
When the input character is #, pop the input off the stack (~), get the number of members on the stack (l), push 127 ('␡'), and take the modulus (%). Then, output it as a character (o) and start a new stack ([0). This "zeroes" out the counter. Then, the loop restarts.
-
3\$\begingroup\$ Poor ><>. It's sad
:0(:( \$\endgroup\$2017年05月22日 06:41:10 +00:00Commented May 22, 2017 at 6:41
Röda, (削除) 44 (削除ここまで) (削除) 39 (削除ここまで) 38 bytes
5 bytes saved thanks to @fergusq
{(_/`#`)|{|d|d~="[^;]",""chr #d%127}_}
Anonymous function that takes the input from the stream.
If other characters do not have to be ignored, I get this:
Röda, 20 bytes
{(_/`#`)|chr #_%127}
Jelly, 13 bytes
ṣ"#Ṗċ€";%127Ọ
How it works
ṣ"#Ṗċ€";%127Ọ Main link. Argument: s (string)
ṣ"# Split s at hashes.
Ṗ Pop; remove the last chunk.
ċ€"; Count the semicola in each chunk.
%127 Take the counts modulo 127.
Ọ Unordinal; cast integers to characters.
-
2\$\begingroup\$ The word
semicoladoesn't exist it'ssemicolons. \$\endgroup\$Erik the Outgolfer– Erik the Outgolfer2017年06月11日 17:51:14 +00:00Commented Jun 11, 2017 at 17:51 -
3\$\begingroup\$ @EriktheOutgolfer en.m.wiktionary.org/wiki/semicola \$\endgroup\$Dennis– Dennis2017年06月11日 17:52:44 +00:00Commented Jun 11, 2017 at 17:52
-
\$\begingroup\$ Hmm, weird word. \$\endgroup\$Erik the Outgolfer– Erik the Outgolfer2017年06月11日 17:53:54 +00:00Commented Jun 11, 2017 at 17:53
-
\$\begingroup\$ @EriktheOutgolfer Someone on Wiktionary was probably trying to make the Latin plural valid in English, but cola and semicola spellings should be proscribed. \$\endgroup\$Cœur– Cœur2017年09月09日 14:23:52 +00:00Commented Sep 9, 2017 at 14:23
05AB1E, (削除) 16 (削除ここまで) (削除) 15 (削除ここまで) 14 bytes
Code:
'#¡ ̈ʒ';127ドル%ç?
Explanation:
'#¡ # Split on hashtags
̈ # Remove the last element
ʒ # For each element (actually a hacky way, since this is a filter)
';¢ # Count the number of occurences of ';'
127% # Modulo by 127
ç # Convert to char
? # Pop and print without a newline
Uses the 05AB1E-encoding. Try it online!
x86 machine code on MS-DOS - 29 bytes
00000000 31 d2 b4 01 cd 21 73 01 c3 3c 3b 75 06 42 80 fa |1....!s..<;u.B..|
00000010 7f 74 ed 3c 23 75 eb b4 02 cd 21 eb e3 |.t.<#u....!..|
0000001d
Commented assembly:
bits 16
org 100h
start:
xor dx,dx ; reset dx (used as accumulator)
readch:
mov ah,1
int 21h ; read character
jnc semicolon
ret ; quit if EOF
semicolon:
cmp al,';' ; is it a semicolon?
jne hash ; if not, skip to next check
inc dx ; increment accumulator
cmp dl,127 ; if we get to 127, reset it; this saves us the
je start ; hassle to perform the modulo when handling #
hash:
cmp al,'#' ; is it a hash?
jne readch ; if not, skip back to character read
mov ah,2 ; print dl (it was choosen as accumulator exactly
int 21h ; because it's the easiest register to print)
jmp start ; reset the accumulator and go on reading
Retina 0.8.2, (削除) 34 (削除ここまで) 32 bytes
T`;#\x00-\xFF`\x7F\x00_
\+T`\x7Eo`\x00-\x7F_`\x7F[^\x7F]|\x7F$
Try it online! Includes test case. Edit: Saved 2 bytes with some help from @MartinEnder. Now uses TIO link with null byte support thanks to @Deadcode. Note: Code includes unprintables, which I have replaced with hex escapes in the post. Explanation: The first line cleans up the input: ; is changed to \x7F, # to \x00 and everything else is deleted. Then whenever we see an \x7F that is not before another \x7F, we delete it and cyclically increment the code of any next character. This is iterated until there are no more \x7F characters left.
-
\$\begingroup\$ You can save a byte by combining the last two stages with
\x80([^\x80]|$)in the last stage. \$\endgroup\$Martin Ender– Martin Ender2017年05月23日 09:19:58 +00:00Commented May 23, 2017 at 9:19 -
\$\begingroup\$ @MartinEnder Thanks! Annoyingly,
\s+T`\x7Fo`\x01-\x80_`\x80(?!\x80).?also only saves one byte. \$\endgroup\$Neil– Neil2017年05月23日 09:30:57 +00:00Commented May 23, 2017 at 9:30 -
\$\begingroup\$ Ah, but
[^\x80]|\x80$saves two bytes, I think. \$\endgroup\$Neil– Neil2017年05月23日 09:33:00 +00:00Commented May 23, 2017 at 9:33 -
\$\begingroup\$ Ah nice, yeah the last one works. I had also tried the negative lookahead, but the
sis annoying. \$\endgroup\$Martin Ender– Martin Ender2017年05月23日 09:33:44 +00:00Commented May 23, 2017 at 9:33 -
\$\begingroup\$ TIO does allow NULs, and the third test case works. \$\endgroup\$Deadcode– Deadcode2020年01月23日 08:56:51 +00:00Commented Jan 23, 2020 at 8:56
05AB1E, (削除) 25 (削除ここまで) (削除) 21 (削除ここまで) 19 bytes
-2 bytes thanks to Adnan
Îvy';Q+y'#Qi127%ç?0
Explanation:
Î Initialise stack with 0 and then push input
v For each character
y';Q+ If equal to ';', then increment top of stack
y'#Qi If equal to '#', then
127% Modulo top of stack with 127
ç Convert to character
? Print without newline
0 Push a 0 to initialise the stack for the next print
-
1\$\begingroup\$ I think you can replace
i>}by+. \$\endgroup\$Adnan– Adnan2017年05月21日 19:58:15 +00:00Commented May 21, 2017 at 19:58
R, (削除) 97 (削除ここまで) (削除) 90 (削除ここまで) (削除) 86 (削除ここまで) 84 bytes
A function:
function(s)for(i in utf8ToInt(s)){F=F+(i==59);if(i==35){cat(intToUtf8(F%%127));F=0}}
When R starts, F is defined as FALSE (numeric 0).
Ungolfed:
function (s)
for (i in utf8ToInt(s)) {
F = F + (i == 59)
if (i == 35) {
cat(intToUtf8(F%%127))
F = 0
}
}
-
\$\begingroup\$ Shouldn't this be R+pryr? \$\endgroup\$L3viathan– L3viathan2017年05月22日 08:31:10 +00:00Commented May 22, 2017 at 8:31
-
\$\begingroup\$ @L3viathan Since
pryris an R package, it is still R code. \$\endgroup\$Sven Hohenstein– Sven Hohenstein2017年05月22日 08:58:27 +00:00Commented May 22, 2017 at 8:58 -
\$\begingroup\$ It is R code, but it requires the installation of an additional library. \$\endgroup\$L3viathan– L3viathan2017年05月22日 09:05:36 +00:00Commented May 22, 2017 at 9:05
-
\$\begingroup\$ @L3viathan Do you think my answer is invalid? Should I avoid using additional packages? \$\endgroup\$Sven Hohenstein– Sven Hohenstein2017年05月22日 09:11:35 +00:00Commented May 22, 2017 at 9:11
-
2\$\begingroup\$ @BLT There is no difference. In my opinion it is no problem to use additional packages that were created before the challenge. This is true for all languages. In Python you have to use
importwhile in R you can use::to directly access function in packages. You can often see the use of additional packages here (e.g., for Python and Java). However, I changed my former post because I don't want to engage in discussion. \$\endgroup\$Sven Hohenstein– Sven Hohenstein2017年05月23日 05:04:52 +00:00Commented May 23, 2017 at 5:04
Plain TeX, 156 bytes
\newcount\a\def\;{\advance\a by 1\ifnum\a=127\a=0\fi}\def\#{\message{\the\a}\a=0}\catcode`;=13\catcode35=13\let;=\;\let#=\#\loop\read16 to\>\>\iftrue\repeat
Readable
\newcount\a
\def\;{
\advance\a by 1
\ifnum \a=127 \a=0 \fi
}
\def\#{
\message{\the\a}
\a=0
}
\catcode`;=13
\catcode35=13
\let;=\;
\let#=\#
\loop
\read16 to \> \>
\iftrue \repeat
-
\$\begingroup\$ Can it print characters symbolically? \$\endgroup\$eush77– eush772017年05月21日 23:20:01 +00:00Commented May 21, 2017 at 23:20
Python, 82 bytes
lambda t:''.join(chr(len([g for g in x if g==';'])%127)for x in t.split('#')[:-1])
-
1\$\begingroup\$ @WheatWizard since you already posted this as an answer, I believe the right action for me would be to upvote it rather than update \$\endgroup\$Uriel– Uriel2017年05月22日 11:36:03 +00:00Commented May 22, 2017 at 11:36
;#+, 59 bytes
;;;;;~+++++++>~;~++++:>*(~<:-+!(<-;->(;))::<+-::!(<#>)-:-*)
Try it online! Input is terminated with a null byte.
Explanation
The generation is the same as from my Generate ;# code answer. The only difference here is is the iteration.
Iteration
*(~<:-+!(<-;->(;))::<+-::!(<#>)-:-*)
*( *) take input while != 0
~ swap
< read value from memory (;)
: move forward to the accumulator memory spot (AMS)
- flip Δ
+ subtract two accumulators into A
! flip A (0 -> 1, else -> 0)
( (;)) if A is nonzero, or, if A == ';'
< read from AMS
-;- increment
> write to AMS
:: move to cell 0 (#)
< read value from memory (#)
+ subtract two accumulators into A
- flip Δ
:: move to AMS
!( ) if A == '#'
< read from AMS
# output mod 127, and clear
> write to AMS
-:- move back to initial cell
C (gcc), 58 bytes
a;f(char*s){a+=*s^35?*s==59:-putchar(a%127);a=*s&&f(s+1);}
Try it online! (Hint: click ▼ Footer to collapse it.)
MATL, 29 bytes
';#'&mXz!"@o?T}vn127\c&YD]]vx
Input is a string enclosed in single quotes.
The FizzBuzz program is too long for the online interpreters; see it working offline in this gif:
{kind=link}
Explanation
The accumulator value is implemented as the number of elements in the stack. This makes the program slower than if the accumulator value was a single number in the stack, it but saves a few bytes.
';#' % Push this string
&m % Input string (implicit). Pushes row vector array of the same size with
% entries 1, 2 or 0 for chars equal to ';', '#' or others, respectively
Xz % Remove zeros. Gives a column vector
! % Transpose into a row vector
" % For each entry
@ % Push current entry
o? % If odd
T % Push true. This increases the accumulator (number of stack elements)
} % Else
v % Concatenate stack into a column vector
n % Number of elements
127\ % Modulo 127
c % Convert to char
&YD % Display immediately without newline
] % End
] % End
vx % Concatenate stack and delete. This avoids implicit display
Perl, 25 bytes
$_=chr(y%;%%%127)x/#/
Run with perl -043pe (counted as 4 bytes, since perl -e is standard).
Explanation: -043 sets the line-terminator to # (ASCII 043). -p iterates over the input "lines" (actually #-delimited strings, now). y%;%% counts the number of ; in each "line". x/#/ makes sure that we don’t print an extra character for programs that don’t end in a # (like the third testcase). %127 should be fairly obvious. $_= is the usual boilerplate.
-
\$\begingroup\$ Impressing one, though there is glitch: for
;;#;;;it outputs #5 instead of #2. \$\endgroup\$manatwork– manatwork2017年05月22日 15:24:34 +00:00Commented May 22, 2017 at 15:24 -
\$\begingroup\$ How did you get this result?
echo -n ';;#;;;' | perl -043pe '$_=chr(y%;%%%127)x/#/' | xxdcorrectly outputs00000000: 02on my machine. If you left off the043, or are using a codepage where#is not ASCII 043, that would explain your result. \$\endgroup\$Grimmy– Grimmy2017年05月22日 15:27:28 +00:00Commented May 22, 2017 at 15:27 -
1\$\begingroup\$ Oops. Sorry, I had a typo in my test. Your code works perfectly. \$\endgroup\$manatwork– manatwork2017年05月22日 15:32:06 +00:00Commented May 22, 2017 at 15:32
CJam, 27 bytes
0q{";#"#") 127%co0 "S/=~}%;
Explanation:
0 e# Push 0
q e# Push the input
{ e# For each character in the input:
";#"# e# Index of character in ";#", -1 if not found
") 127%co0 "S/ e# Push this string, split on spaces
= e# Array access (-1 is the last element)
~ e# Execute as CJam code. ")" increments the accumulator,
e# and "127%co0" preforms modulo by 127, converts to character, pops and outputs, and then pushes 0.
}% e# End for
; e# Delete the accumulator
Alternative Solution, 18 bytes
q'#/);{';e=127%c}%
Explanation:
q e# Read the whole input
'#/ e# Split on '#'
); e# Delete the last element
{ e# For each element:
';e= e# Count number of ';' in string
127% e# Modulo by 127
c e# Convert to character code
}% e# End for
Brainfuck, 135 bytes
+[>+>>,>+++++[<------->-]<[<+>>++++[<------>-]<[<->[-]]<[>>>+<<<-]<->>[-]]<<[>>>--[>>+<<--]>[>->+<[>]>[<+>-]<<[<]>-]>[-]>.[-]<<<<<<-]<]
Ungolfed
Memory layout
0 1 2 3 4 5 6 7
1 f1 f2 in tmp acc d acc%d
flag1 indicates hash
flag2 indicates semicolon
+[ infinite loop
>+ set flag1
>>, input
>+++++[<------->-]< subtract 35 (hash)
[ not hash
<+> set flag2
>++++[<------>-]< subtract 24 more (semicolon)
[ not semicolon
<-> clear flag2
[-] clear input
]
< goto flag2
[ semicolon
>>>+<<<- inc acc and clear flag2
]
<- clear flag1
>>[-] clear input
]
<< goto flag1
[ hash
>>>--[>>+<<--]> set d 127 and goto acc
[>->+<[>]>[<+>-]<<[<]>-] mod
>[-]> clear d and goto acc%d
.[-] print and clear result
<<<<<<- clear flag1
]
<]
F#, (削除) 79 (削除ここまで) (削除) 91 (削除ここまで) 93 bytes
let rec r a=function|[]->()|';'::t->r(a+1)t|'#'::t->printf"%c"(char(a%127));r 0 t|_::y->r a y
Ungolfed
let rec run acc = function
| [] -> ()
| ';'::xs ->
run (acc + 1) xs
| '#'::xs ->
printf "%c" (char(acc % 127))
run 0 xs
| x::xs -> run acc xs
Edit: Was treating any other char than ';' as '#'. Changed it so that it's ignoring invalid chars.
Alternative
F#, (削除) 107 (削除ここまで) 104 bytes
let r i=
let a=ref 0
[for c in i do c|>function|';'->a:=!a+1|'#'->printf"%c"(!a%127|>char);a:=0|_->()]
Use of reference cell saves 3 bytes
Ungolfed
let run i =
let a = ref 0;
[for c in i do
match c with
| ';' -> a := !a + 1
| '#' ->
printf "%c" (char(!a % 127))
a := 0
|_->()
]
Processing.js (Khanacademy version), 118 bytes
var n="",a=0;for(var i=0;i<n.length;i++){if(n[i]===";"){a++;}if(n[i]==="#"){println(String.fromCharCode(a%127));a=0;}}
As the version of processing used does not have any input methods input is placed in n.
-
\$\begingroup\$ You could technically forge your own input method with
keyTyped=function(){ ... }:P \$\endgroup\$ETHproductions– ETHproductions2017年05月21日 19:18:35 +00:00Commented May 21, 2017 at 19:18 -
\$\begingroup\$ @ETHproductions This is a look of disgust. \$\endgroup\$user63187– user631872017年05月21日 19:19:44 +00:00Commented May 21, 2017 at 19:19
-
\$\begingroup\$ @RandomUser yay! I have done it! I like to answer in Processing (check my answers) \$\endgroup\$user63187– user631872017年05月21日 19:37:39 +00:00Commented May 21, 2017 at 19:37
-
2\$\begingroup\$ @RandomUser Not just 1000 rep.. but 2^10 rep ( ͡° ͜ʖ ͡°) \$\endgroup\$user47018– user470182017年05月22日 17:46:12 +00:00Commented May 22, 2017 at 17:46
-
\$\begingroup\$ @Midnightas Ohhh yeah \$\endgroup\$user63187– user631872017年05月22日 18:03:04 +00:00Commented May 22, 2017 at 18:03
Labyrinth, (削除) 61 (削除ここまで) 47 bytes
_36},)@
; {
; 42_-
"#- 1
_ ; 72
_ ) %
"""".
Explanation
color coded image of the solution code
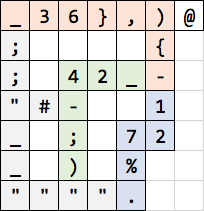{kind=link}
Code execution begins in the top left corner and the first semicolon discards an implicit zero off the stack and continues to the right.
Orange
_36pushes 36 onto the stack. This is for comparing the input with#}moves the top of the stack to the secondary stack,pushes the integer value of the character on the stack)increments the stack (if it's the end of the input, this will make the stack 0 and the flow of the program will proceed to the@and exit){moves the top of the secondary stack to the top of the primary stack-pop y, pop x, push x - y. This is for comparing the input with#(35 in ascii). If the input was#the code will continue to the purple section (because the top of the stack is 0 the IP continues in the direction it was moving before), otherwise it will continue to the green section.
Purple
127push 127 to the stack%pop x, pop y, push x%y.pop the top of the stack (the accumulator) and output as a character
From here the gray code takes us to the top left corner of the program with nothing on the stack.
Green
_24push 24 onto the stack-pop x, pop y, push x-y. 24 is the difference between#and;so this checks if the input was;. If it was;the code continues straight towards the). Otherwise it will turn to the#which pushes the height of the stack (always a positive number, forcing the program to turn right at the next intersection and miss the code which increments the accumulator);discard the top of the stack)increment the top of the stack which is either an implicit zero or it is a previously incremented zero acting as the accumulator for output
From here the gray code takes us to the top left corner of the program with the stack with only the accumulator on it.
Gray
Quotes are no-ops, _ pushes a 0 to the stack, and ; discards the top of the stack. All of this is just code to force the control-flow in the right way and discarding anything extra from the top of the stack.
-
\$\begingroup\$ Out of curiosity, how did you generate the explanation image? Did you create it yourself? \$\endgroup\$Stefnotch– Stefnotch2018年08月05日 09:16:57 +00:00Commented Aug 5, 2018 at 9:16
-
2\$\begingroup\$ @Stefnotch, I used a text editor to put a tab between each character and then pasted the code into Microsoft Excel which put each character into it's own cell. I selected all cells to give them equal width and height. Then I adjusted colors and borders and took a screenshot. \$\endgroup\$Robert Hickman– Robert Hickman2018年08月07日 16:20:40 +00:00Commented Aug 7, 2018 at 16:20
Awk, 57 bytes
BEGIN{RS="#"}RT=="#"{printf("%c",gsub(";","")%127)}
Explanation:
BEGIN{RS="#"}: make#record delimeterRT=="#": ignore the record without ending#gsub(";","")%127: count;and mod 127printf("%c",_): print as ASCII
-
\$\begingroup\$ It seems you're missing a
%127\$\endgroup\$user41805– user418052020年04月21日 05:49:14 +00:00Commented Apr 21, 2020 at 5:49 -
\$\begingroup\$ fair point, added it \$\endgroup\$Kamila Szewczyk– Kamila Szewczyk2020年04月21日 05:54:33 +00:00Commented Apr 21, 2020 at 5:54
-
\$\begingroup\$ There's a 25 bytes answer: here just FYI :) \$\endgroup\$Dom Hastings– Dom Hastings2020年04月21日 12:18:00 +00:00Commented Apr 21, 2020 at 12:18
-
1\$\begingroup\$ Using that other one as a template and since flags count as a separate version of the language here's one for 17 bytes. \$\endgroup\$Dom Hastings– Dom Hastings2020年04月21日 12:29:08 +00:00Commented Apr 21, 2020 at 12:29
Vyxal, 10 / 20 bytes
There's two main schools of thought for interpreting ;#:
- Go through every command and apply it (Iterative)
- Split the program into strings of
;, then count and output. (Split 'n Count)
Here's both!
Iterative, 20 bytes
0$(\;n=ß›\#n=[7‹%C₴0
Explanation:
# Implicit input
0$ # Initialize accumulator at the bottom of the stack
( # For each command in the program
\;n=ß # If command = ';':
› # Increment accumulator
\#n=[ # If command = '#':
7‹% # Accumulator % 127
C # Convert accumulator to character
₴ # Print accumulator w/o newline
0 # Reset accumulator
Split 'n Count K, (削除) 14 (削除ここまで) (削除) 12 (削除ここまで) 10 bytes
-1 byte thanks to @caird coinheringaahing.
-1 byte by using Map Lambda instead of a for loop.
-2 bytes by using Keg mode and removing the n I left in from the for loop.
35€ƛ59O7‹%
Output is a list of characters.
Explanation:
# Implicit input; characters are converted to ordinal values
35€ # Split input program at '#'
ƛ # For every section of program:
59O # Count ';'
7‹% # Modulus 127
# 'K' flag - ordinal values are converted to characters
-
\$\begingroup\$ Would the "split on
#, count;for each, mod 127, remove last, to chars" approach be any shorter? See my Add++ answer, or Dennis' Jelly answer for a better explanation \$\endgroup\$2021年04月22日 13:15:39 +00:00Commented Apr 22, 2021 at 13:15 -
\$\begingroup\$ @cairdcoinheringaahing As it turns out, yes! \$\endgroup\$Aaroneous Miller– Aaroneous Miller2021年04月22日 14:45:50 +00:00Commented Apr 22, 2021 at 14:45
-
\$\begingroup\$ Can you use
Oto count the number of semicola, rather than filter-length? \$\endgroup\$2021年05月06日 23:11:09 +00:00Commented May 6, 2021 at 23:11 -
\$\begingroup\$ @cairdcoinheringaahing Not sure how I missed that, but yes! Thanks! Turns out, I can also replace the for loop with a map lambda to get a list, and concatenate with a flag to save another byte. \$\endgroup\$Aaroneous Miller– Aaroneous Miller2021年05月07日 01:45:07 +00:00Commented May 7, 2021 at 1:45