What method should I use to populate a tree as I'm consuming data that is contained within the tree?
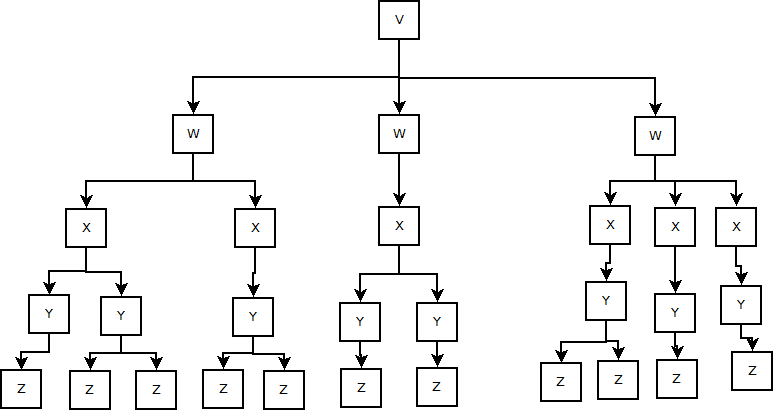
I have a tree that consists of 5 types of nodes - V, W, X, Y, and Z. V represents the root node, and a given tree has exactly one element of type V. A V contains one or more Ws, a W contains one or more Xs, an X contains one of more Ys, and a Y contains one or more Zs:
{kind=link}
Looking at this, I decided to model this with the following class structure:
{kind=link}
Not shown in the class structure are the data elements that are unique to each type of node along with the methods to access those data elements. However, each node does have a unique set of attributes and operations.
To give a perspective on size, there could be up to thousands of nodes at the Z level. It's going to be much smaller at the W level, as there are almost no cases of 1:1:1:1 mappings from W to Z.
My problem comes when I think about how to build this tree.
The data comes in what can be thought of as a stream. There is a unit that I'll refer to as DataChunk. A DataChunk contains the data for one or more levels of the tree. If the DataChunk contains data for a Z, then it also contains data for a Y, X, and W. However, a DataChunk that contains data for X will contain data for W, but not necessarily Y.
In a stream, the start of a DataChunk is marked off by a sync word. In a set of datagrams, each DataChunk is a single datagram. In a set of files, the DataChunk could be presented as a set of files where 1 file is one DataChunk or 1 file contains multiple DataChunks, each marked by the sync word. The order is not specified.
In order to build the tree, I need to accept a DataChunk and parse information out of it.
One approach would be to have each node accept a DataChunk object, parse the information out, and set its own attributes and then see if it has a matching child to pass the node to. If the corresponding child exists, pass the data chunk to it. If the corresponding child doesn't exist, create it and then pass the data chunk to it. However, this leaves me with a mutable object - after construction, I can pass an arbitrary DataChunk into any node and change the tree. This also appears to be a violation of SRP, as each data node is responsible for not only the data associated with it, but to help build the tree.
Another approach may be to have some kind of Builder approach, but this would balloon my classes to 10 - I would need the node data class and the builder class. It also seems like this would be rather inefficient, since the Builder would essentially be a second tree with a mutable interface that would return the tree structure described above. It doesn't seem performant in terms of time or memory consumption.
I'm also somewhat concerned with flexibility going forward. The tree data model isn't likely to change, but the format of the DataChunk may change or be supplemented with additional formats for the data to use to build the tree. That may be another point to the builder-style approach.
Is there a data-consuming / tree-building approach that I've overlooked? Would it be preferable to do what appears to be a violation of SRP and present a client with a mutable data structure (assuming they have or construct instances of DataChunk) or go with a more complex builder to present the client with a cleaner interface, but have a more complex code base.
1 Answer 1
Ok, so here's what I came up with. This contains Java, better get yourself some coffee. The Irish one. (for the same reason)
In a sense, a tree is self similar. After all, a tree is a graph. Each node knows a certain number of other nodes.
Speaking of Nodes:
import java.util.HashMap;
public class Node <Child extends ICanBeMergedWith<? super Child> & ICanBecomeImmutable> implements ICanBecomeImmutable, ICanBeMergedWith<Node<Child>>
{
private HashMap<Child, Child> children;
private String name;
private boolean mutable;
public Node(String name)
{
this.name = name;
children = new HashMap<Child,Child>();
mutable = true;
}
public boolean add(Child child)
{
if (!mutable)
{
return false;
}
if(!children.containsKey(child))
{
children.put(child, child);
}
else
{
children.get(child).merge(child);
}
return true;
}
@Override
public void merge(Node<Child> other)
{
if (!mutable || !equals(other))
{
return;
}
for(Child child : other.children.values())
{
add(child);
}
}
@Override
public String toString()
{
String s = name + ":";
for (Child child : children.values())
{
s += System.getProperty("line.separator") + child.toString().replaceAll("(?m)^", "\t");
}
return s;
}
@Override
public void petrify()
{
mutable = false;
for (Child child : children.values())
{
child.petrify();
}
}
@Override
public int hashCode()
{
return name.hashCode();
}
@Override
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
if (name == null)
if (((Node<Child>) obj).name != null)
return false;
return name.equals(((Node<Child>) obj).name);
}
}
Sorry for serving that thing up front, but there's no way around it.
- Each Node should be able to compare itself to other Nodes. That gives a great advantage, because you can create different objects modelling the same node as you see fit (and as the incoming data stream dictates), then throw it all together and let the objects figure out which of them should be merged together. In
Javaland you have to do some shenanigans withequals()andhashCode(). I just copied that together from the web. You have to come up with your own implementation depending on what the actual implementations ofX,Yetc. do in your use case. I my case they all just have a name. If two nodes of the same type have the same name, they are equal. - There's a
HashMap<Child, Child> children;, which is the list of other knownNodes I was talking about above. Admittedly, aHashSet<Child>could also work, for all we need is some data structure that keeps its children unique, but it's kind of hard to get something back out of aHashSet, which is necessary to add more things to it. Basically speaking,HashMap<Child, Child>is used like aHashSet<Child>, but is more convenient (and faster). - This list is filled via
add(Child child)method. If the child is not in the list already, add it as is. If the child is in the list already, that means that this exact child is not necessarily already in the list, but some child that is considered equal, so the incoming child received as parameter is merged into the one that's in the list already. Think of this like placing two folders together that have the name: that doesn't mean they have the same sub folders. To do this, I had to createICanBeMergedWith<T>, which you can find below, because I am unable to integrate big code blocks into list (editors?!) - As you said this leaves you with a mutable data structure. My initial solution to this was to create a
NullObjectinstance per class. So all the mutating method calls could be either delegated tothiswithin the class or to theNullObject. It turns out thatstaticand generic types do not go well together. I was no able to create a generic innerNullObjectsingleton. As can be seen above, I went for a simple flag variable that prevents access to the internal data structure. I createdICanBecomeImmutablefor that. - These interfaces are just marker interfaces to differentiate between
Node<Child>andChild. I think this would all be a lot easier if there were self types (that is, being able to type something to whatever classthisis) But for a lack thereof and my lack of skills, this is the solution I came up with. You can explicitly type things, which soon becomes as ugly withNode<Node<Node<V>>>. Or maybe I'm just totally wrong here.
So much for Node. The actual classes a a tad bit simpler, here they are:
V:
public class V extends Node<W>
{
public V(String name)
{
super(name);
}
}
W:
public class W extends Node<X>
{
public W(String name)
{
super(name);
}
}
X:
public class X extends Node<Y>
{
public X(String name)
{
super(name);
}
}
Y:
public class Y extends Node<Z>
{
public Y(String name)
{
super(name);
}
}
Z:
public class Z implements ICanBecomeImmutable, ICanBeMergedWith <Z>
{
@Override
public String toString()
{
return "Z";
}
@Override
public void petrify()
{
// nothing to do
}
@Override
public void merge(Z other)
{
// whatever
}
}
Only Z is a little different, because it can be known to Node but is not a Node itself. Two empty methods aren't too bad I guess.
Last but not least, the above mentioned interfaces:
interface for merging:
public interface ICanBeMergedWith<T>
{
void merge(T other);
}
interface for making object immutable:
public interface ICanBecomeImmutable
{
void petrify();
}
I created a little test application:
public class Main
{
public static void main(String[] args)
{
// building main tree
System.out.println("========= main tree ========= ");
V v1 = new V("v1");
W w1 = new W("w1");
W w2 = new W("w2");
X x1 = new X("x1");
X x2 = new X("x2");
Y y1 = new Y("y1");
Y y2 = new Y("y2");
v1.add(w1);
// v1.petrify();
v1.add(w2);
w1.add(x1);
w2.add(x2);
x1.add(y1);
// v1.petrify();
x2.add(y2);
y1.add(new Z());
y1.add(new Z());
y1.add(new Z());
// v1.petrify();
y1.add(new Z());
y2.add(new Z());
y2.add(new Z());
System.out.println(v1);
System.out.println("========= sub tree ========= ");
// building second tree
V v2 = new V("v1"); // !!! same name as v1 object, should be merged to one
W w3 = new W("w2"); // !!! same name as w2 object, should be merged to one
X x3 = new X("x2"); // !!! same name as x2 object, should be merged to one
X x4 = new X("x4");
Y y3 = new Y("y2"); // !!! same name as y2 object, should be merged to one
v2.add(w3);
w3.add(x3);
w3.add(x4);
x3.add(y3);
y3.add(new Z());
y3.add(new Z());
y3.add(new Z());
y3.add(new Z());
y3.add(new Z());
System.out.println(v2);
System.out.println("========= merge tree ========= ");
v1.merge(v2);
System.out.println(v1);
}
}
There are a few v1.petrify(); scattered around to stop further expansion of the tree.
The output is as follows for me:
========= main tree =========
v1:
w1:
x1:
y1:
Z
Z
Z
Z
w2:
x2:
y2:
Z
Z
========= sub tree =========
v1:
w2:
x2:
y2:
Z
Z
Z
Z
Z
x4:
========= merge tree =========
v1:
w1:
x1:
y1:
Z
Z
Z
Z
w2:
x2:
y2:
Z
Z
Z
Z
Z
Z
Z
x4:
This is where my partial answer ends, because I do not know how the DataChunks look like. What you have to do now is to transform the data into a tree, then merge the tree with the main tree. As far as I could tell. Every DataChunk has to start at some V Node, because it would otherwise be impossible to which parent Node this subtree belongs to. But even if it wasn't, you have the ability now to add and merge Nodes at every level of the tree. When the stream is finished, call petrify() on the rootV Node to prevent any further mutation of the data.
Also, do some more testing.
Something should probably be final. It looks more professional if something is final. No seriously, this is to show that not every detail was thought through entirely. This is to prove that from the types and the stated requirements, this can be possible. Nothing more nothing less.
disclaimer: I don't have much experience with generics so far. Chances are this is the worst horrible nonsense ever. I was about to deem this impossible, when I gave it a last try, typed "super" to create and upper bound and all the red lines disappeared. Magic!
Also: yeah WTF, how dare I post an implementation on programmers.SE? The thing is: you can do stuff on the whiteboard for sure, but there ain't no result without implementation. And what is supported by the language you choose in the end makes a huge difference on the effort it takes to do the actual implementation. You cannot hit "compile" and the compiler is always right. That's why I went for a concrete implementation.
-
would love to hear some suggestions on how to name a method that makes an object immutable other than "petrify".null– null2015年08月10日 23:47:30 +00:00Commented Aug 10, 2015 at 23:47
-
-
-
1Those sound like good names, thanks for the suggestions.null– null2016年09月24日 16:59:33 +00:00Commented Sep 24, 2016 at 16:59
DataChunkalways become aWnode or any kind of node?DataChunkmay contain data for any of the nodes. It, by itself, never becomes a node at all. Pieces are extracted by each level to populate its fields.DataChunkas a subtree before. That may be interesting. I'll think about that, but if you could expand on it as an answer, that would be great. I'm not sure if there's anything that precludes it from happening.