-
Notifications
You must be signed in to change notification settings - Fork 1.4k
Releases: jundot/omlx
0.4.4rc1
This release candidate focuses on DiffusionGemma support, DeepSeek V4 oQ/MTP support, and major cache-reuse correctness improvements for agent workloads.
Highlights
- Added DiffusionGemma support via @Blaizzy's mlx-vlm, currently without cache. oMLX can now serve DiffusionGemma models through the mlx-vlm path.
- Added DeepSeek V4 oQ quantization and MTP support. oMLX now supports fractional oQ levels, pre-quantized DeepSeek V4 oQ tensors, and safer DeepSeek V4 MTP loading and rollback behavior.
- Dramatically improved agent cache reuse for Gemma and Qwen models. Paged SSD cache and prefix-cache correctness fixes now prevent stale layer-cache reuse, handle rotating-family prefix restore more safely, and strip superseded rotating-tip payloads so agent-style repeated prompts can reuse cache much more reliably. by @cfbraun in #1815 and @hojin12312 in #1807
- Improved Memory Guard and preflight accounting. Scheduler preflight now avoids counting hot-cache bytes incorrectly, includes chunk KV growth, mirrors MLX SDPA fallback behavior more closely, and handles tracked model memory before load admission.
Improvements and Fixes
- Added VLM MTP support with an external Qwen MTP drafter. VLM models can now use a separate Qwen MTP draft model for speculative decoding, with admin UI support for the new drafter settings. by @imi4u36d in #1791
- Added a scheduler-facing output parser abstraction for Harmony, Gemma 4, and Cohere2 MoE style streamed output/tool parsing.
- Fixed VLM MTP hidden-output preservation and made MTP draft rollback atomic.
- Fixed DeepSeek V4 MTP rollback/loading and rejected unsupported DeepSeek V4 fp16 oQ configurations.
- Added fractional oQ levels and support for pre-quantized DeepSeek V4 oQ tensors.
- Fixed TurboQuant cache handling after hybrid cache restore and chunked prefill cache insertion. (#1793)
- Fixed benchmark loading so VLM MTP benchmark paths are not forced through LM-only loading. by @imi4u36d in #1813
- Added a benchmark option to force mlx-lm loading when needed.
- Fixed paged SSD cache invalidation for stale layer cache signatures. by @cfbraun in #1815
- Fixed prefix-cache restore for rotating-family models and stripped superseded rotating-tip payloads. by @hojin12312 in #1807
- Added a prefix-cache divergence probe for always-miss diagnosis. by @popfido in #1784
- Fixed scheduler preflight accounting for hot-cache bytes, chunk KV growth, SDPA fallback, and scheduler memory-guard test doubles. (#1796, #1797)
- Fixed engine-pool settle waits so other serving engines are not delayed unnecessarily. by @JimStenstrom in #1785
- Fixed
logits_processorsrows that are dropped toNoneduring batch merge. by @efortin in #1799 - Fixed API-key safety by fingerprinting rejected keys in logs and rejecting non-ASCII configured API keys at validation time. by @richgoodson in #1751 and #1804
- Fixed admin global profile form synchronization. (#1816)
- Refined speculative draft model dropdowns and removed the experimental label from VLM MTP.
- Added
cohere2_moesupport via mlx-vlm. (#1809) - Improved native embedding, reranker, DFlash, and audio model paths, including BGE/XLM-R/BERT serving, DFlash memory/cache accounting, TTS language forwarding, Gemma 4 Unified discovery, and NeMo ASR discovery.
Thanks
Thanks to @richgoodson, @paalolav, @JimStenstrom, @apetersson, @popfido, @FaisalFehad, @scaryrawr, @hojin12312, @efortin, @imi4u36d, and @cfbraun for the reports and fixes that shaped this release.
New Contributors
Thank you to @paalolav, @hojin12312, and @efortin for making their first contributions in this release.
Full Changelog: v0.4.3...v0.4.4rc1
Contributors
- @scaryrawr
- @apetersson
- @efortin
- @popfido
- @cfbraun
- @FaisalFehad
- @hojin12312
- @JimStenstrom
- @imi4u36d
- @paalolav
- @richgoodson
Assets 4
0.4.4.dev1
This development release improves memory-pressure handling, paged SSD cache reliability, native embedding/reranker serving, DFlash memory/cache accounting, and audio model support.
- Improved emergency memory handling for pinned workloads. Active requests are only aborted as a last resort when memory exceeds the real ceiling.
- Improved paged SSD cache write-back reliability. Dirty hot-cache blocks now fall back to inline SSD writes instead of being dropped.
- Improved API-key log safety. Rejected API keys are logged as fingerprints instead of raw values. by @richgoodson in #1751
- Improved native BGE/XLM-R/BERT serving. bf16 reranker loads, embedding eval mode, and CLS pooling are handled correctly. by @paalolav in #1767
- Improved DFlash prefill memory guarding. DFlash primary mode now applies the prefill memory guard before admission. by @JimStenstrom in #1770
- Improved native embedding and reranker inference. Native paths now match shared serving behavior more closely.
- Improved DFlash preflight memory safety. Unsafe MLX telemetry calls were removed from the preflight guard path.
- Added TTS language forwarding. The audio speech
languagefield now reaches mlx-audiolang_code. by @apetersson in #1773 - Improved DFlash cache accounting. Prefix-cache hits are reported in
prompt_tokens_details.cached_tokens. by @popfido in #1768 - Fixed TTS argument forwarding. TTS engine argument order is preserved when language is forwarded.
- Improved Gemma 4 Unified discovery.
gemma4_unifiedmodels are detected as VLMs even withoutvision_config. by @FaisalFehad in #1744 - Improved NeMo ASR discovery. NeMo ASR models are detected as speech-to-text models. by @scaryrawr in #1742
- Improved pre-load memory admission. Tracked model memory now participates in LRU eviction decisions before loading another model. by @popfido in #1766
Contributors
Assets 4
0.4.3
This hotfix release focuses on macOS 27 compatibility, Throughput recovery for Qwopus and other affected models, and Memory Guard optimization and correctness fixes.
Highlights
- Added macOS 27 beta compatibility. oMLX now handles the larger
HOST_VM_INFO64response shape used by macOS 27 and avoids fragilepsutilmemory-stat paths on macOS. (#1748, #1749) - Fixed slow Streaming decode on Qwopus and related models. Active Memory Guard polling no longer calls MLX/Metal telemetry from the background thread during active requests, removing a major source of decode stalls. (#1745)
- Improved decode performance. In a single-run Qwen 3.6-35B-A3B
tg512check, throughput improved from 77.5 to 79.0 tok/s (+1.9%) compared with 0.4.2. - Improved per-model MTP behavior. MTP decode eligibility is now stored on each loaded model instance, so loading a non-MTP model later no longer disables MTP decode on an already-loaded Qwen/Qwopus MTP model. (#1758)
- Optimized Memory Guard preflight estimates. TurboQuant KV, hybrid cache models, fused SDPA, and tiled SDPA scratch memory are now accounted for more accurately, reducing false rejections and avoiding unsafe underestimates. (#1763, #1764)
Improvements and Fixes
- Fixed Memory Guard active-request polling so scheduler-recorded MLX memory samples are reused instead of querying MLX telemetry from the enforcer loop.
- Fixed macOS memory detection so system memory and process enforcement remain stable when
HOST_VM_INFO64sizing changes on macOS 27 beta. - Fixed TurboQuant KV preflight accounting so Memory Guard no longer overestimates KV peak memory by several times on TurboQuant-enabled models. (#1763)
- Fixed preflight support for hybrid
ArraysCachemodels with TurboQuant enabled. - Fixed fused SDPA memory estimation so MLX fused attention is treated as linear-memory for all
head_dimvalues where applicable. by @fqx (#1764) - Added tiled SDPA scratch accounting for high-head-dimension prefill paths so large VLM/Qwen-style models are guarded more accurately.
- Fixed prefill Memory Guard errors to return a client-visible failure path instead of surfacing as an internal server failure.
- Fixed DFlash fallback scheduler resolution and bumped
dflash-mlxfor the Qwen wrapper compatibility fix. - Fixed Llama 4 batch cache offsets. (#1752)
- Fixed
max_completion_tokenshandling as an alias formax_tokens. (#1759) - Fixed Harmony encoding loading by retrying transient tokenizer/encoding load failures.
- Fixed stored MarkItDown file placeholders so existing uploaded-file references remain usable after 0.4.2. (#1750)
- Fixed
logits_processors=Nonehandling to avoid mlx-lm crashes. by @monroewilliams (#1747) - Added Thaw menu bar manager support. by @youvegotmoxie (#1743)
- Bumped the
mlx-lm,mlx-vlm, anddflash-mlxpins to include upstream compatibility fixes used by this hotfix.
Thanks
Thanks to @Collinw24, @ritbl, @orangeseasun205, @smkzw, @fqx, @monroewilliams, and @youvegotmoxie for the reports and fixes that shaped this release.
New Contributors
Thank you to @youvegotmoxie for making their first contribution in this release.
Full Changelog: v0.4.2...v0.4.3
Contributors
Assets 4
0.4.2
This release focuses on native MarkItDown document processing, Qwen throughput and DFlash stability, adaptive Burst Decode throughput, Gemma 4 unified multimodal support, and broad cache/server reliability fixes.
Highlights
- Added native MarkItDown document processing. Chat file uploads can now be converted through MarkItDown, including PDF, DOCX, PPTX, TXT, and Markdown inputs, with OpenAI-style
file_datasupport. - Added selectable PDF processing engines. PDFs can use either MarkItDown conversion or VLM OCR from Integration settings.
- Recovered Qwen throughput after the 0.4.0 regression. Qwen VLM/MTP batching and singleton decode handling were updated so single-row decode no longer falls into the slower batched cache path.
- Improved Qwen DFlash stability. DFlash Qwen target ops now stay pointed at the real text wrapper after the mlx-lm pipeline wrapper update, and idle DFlash engines are isolated across model switches.
- Added adaptive Burst Decode. oMLX can now coalesce multiple decode steps per executor hand-off to improve fast single-request decode throughput, with bounded responsiveness and Off / Light / Balanced / Aggressive controls.
- Added Gemma 4 unified audio input support. Gemma 4 unified models can accept audio input alongside image inputs, with suppress-token handling for multimodal placeholders.
- Improved long-context cache reliability. SSD cache pending-write saturation is tuned by block size and model KV size, transient writer backlog waits before dropping blocks, and hot-cache memory is reclaimed after model unload.
- Improved model and server controls. Server-wide context window caps, comma-separated bind addresses, embedding context fallback, and better engine teardown behavior are now covered.
Performance
- Burst Decode further reduces per-token executor overhead on fast local decode paths. Tokens may arrive in small bursts; the default Balanced mode can be changed from Global Settings -> Advanced.
- Internal
tg512measurements show the main Qwen regression recovered while keeping Gemma performance stable:
Screenshot 2026年06月09日 at 01 25 30
{kind=link}
Fixes
- Fixed Qwen VLM/MTP decode behavior by keeping singleton cache layers out of
BatchKVCacheuntil a second request is actually appended. - Fixed Qwen DFlash output corruption after model switches by patching dflash-mlx Qwen target wrapper detection and unloading other idle DFlash engines before loading a new DFlash model. (#1707)
- Fixed prompt-prefix token seeding in
BatchGeneratorso penalty processors see cached prompt tokens correctly. Thanks to @Yukon for identifying the missing token buffer seed. - Fixed generation recovery for MLX
__next_prime overflowerrors by resetting decode state and retrying affected requests serially. (#1725) - Fixed chunked prefill admission so prefilling requests count against the configured concurrency cap. (#1704)
- Fixed SSD cache compatibility across model and cache-layout switches so valid persisted blocks are not deleted for other models or layouts.
- Fixed SSD cache write saturation for long-context workloads by tuning pending-write capacity from real block/KV size and waiting through transient writer backlog. by @cfbraun (#1627)
- Fixed SSD cache hit decode overhead by materializing restored cache backing arrays before decode starts.
- Fixed scalar mRoPE cache offsets for cached VLM prefixes.
- Fixed hot-cache memory retained after model unload and made the admin hot-cache clear action reclaim orphaned hot-cache owners and MLX buffers. by @khsd6327 (#1713)
- Fixed engine close fallback paths so SSD cache managers are still released when shutdown/deep reset raises.
- Fixed stuck engine teardown by treating long teardown stalls as fatal so a supervisor can restart from a clean process.
- Fixed embedding context length handling so
/v1/embeddingsuses request limits, configured context caps, or the model's own context length instead of falling back to 512 tokens. by @JimStenstrom (#1718) - Fixed non-ASCII API keys returning 500; invalid credentials now return 401. by @richgoodson (#1719)
- Fixed
response_formatdowngrade visibility by returning a client-visibleWarningheader when grammar-constrained output cannot be enforced. by @richgoodson (#1564) - Fixed raw tool-call JSON recovery when model output contains tabs or newlines inside string values.
- Added Hermes-style tool call parsing and streaming support. by @scubamount (#1596)
- Fixed Gemma 4 MoE multi-turn tool-call corruption by stripping stray tool-call close markers before history is re-rendered. by @kreeger (#1665)
- Fixed Gemma special tokens leaking into API output. by @JimStenstrom (#1698)
- Fixed multimodal oQ precision by preserving protected vision and audio tensors as float32 where needed. by @dodams258 (#1682)
- Fixed STT language handling so ISO language codes are preserved for backends that expect codes, while Qwen3-ASR-style backends still receive language names. (#1733)
- Fixed mlx-audio resample export compatibility for input audio.
- Fixed decoder-aware streaming detokenization and kept the fallback path compatible with older tokenizer wrappers.
- Fixed Gemma 4 unified routing, prompt kwargs preservation, assistant drafter acceptance, and suppress-token handling across scheduler, DFlash, and VLM MTP paths.
- Bumped the mlx-vlm pin to include Gemma 4 shared-KV/load fixes, Qwen quantized KV prompt-state fixes, Qwen3-VL visual mask alignment, Phi 3.5 VL EOS fixes, and prior unified audio/MTP fixes.
- Fixed small-system memory behavior so sub-24GB Apple Silicon systems use the small-system reserve path.
- Fixed idle CPU overhead while models are loaded and guarded idle wakeups for partial engine cores.
- Fixed interactive Claude model picker launch behavior when tier models are configured. by @fparrav (#1638)
- Fixed prerelease Homebrew formula updates so prerelease tags do not update the stable formula.
- Fixed packaging documentation for the staged app path and stale DMG build wording. by @cfbraun (#1458)
macOS App and Admin UI
- Added all DFlash settings to the native model config screen, including verify mode, draft window and sink sizes, quantization controls, in-memory cache entries, and SSD cache size.
- Added the VLM MTP toggle to model settings and gated overlapping speculative controls while VLM MTP is enabled. by @jabagawee (#1654)
- Added the server-wide context window cap to the admin settings UI.
- Added the Burst Decode setting to Global Settings -> Advanced.
- Added support for comma-separated bind addresses in the Host setting, including validation and alias detection. by @fqx (#1606)
- Fixed the chat composer at 768px tablet portrait width so the sidebar no longer covers it. by @pigeonstorm (#1699)
- Fixed the Settings menu so it stays available when the server is stopped.
- Fixed the login page so Auto theme honors the system dark-mode preference. by @monroewilliams (#1728)
- Fixed localized Memory Guard strings so placeholder interpolation no longer leaves stale tokens or duplicated units. by @fqx (#1730)
- Improved process naming so the server appears as
omlx-server. by @iamckun (#1658)
New Contributors
Thank you to everyone making their first contribution in this release:
@jabagawee, @Cmerrill1713, @kreeger, @sje397, @dodams258, @pigeonstorm, @JimStenstrom, @jackwh, @iamckun, @Kistaro.
Full Changelog: v0.4.1...v0.4.2
Contributors
- @kreeger
- @jabagawee
- @sje397
- @Kistaro
- @jackwh
- @monroewilliams
- @Yukon
- @fqx
- @cfbraun
- @fparrav
- @khsd6327
- @JimStenstrom
- @pigeonstorm
- @scubamount
- @richgoodson
- @iamckun
- @dodams258
- @Cmerrill1713
Assets 4
0.4.2rc1
This release candidate focuses on native MarkItDown document processing, Qwen throughput recovery (x1.48), Gemma 4 unified multimodal support, and cache, scheduler, and server stability improvements.
Highlights
- Added native MarkItDown document processing. Chat file uploads can now be converted through MarkItDown, including PDF, DOCX, PPTX, TXT, and Markdown inputs, with OpenAI-style
file_datasupport. - Added selectable PDF processing engines. PDFs can use either MarkItDown conversion or VLM OCR from Integration settings (currently web dashboard only).
- Recovered Qwen throughput after the 0.4.0 regression. Qwen VLM/MTP batching and singleton decode handling were updated so single-row decode no longer falls into the slower batched cache path.
- Added Gemma 4 unified audio input support. Gemma 4 unified models can now accept audio input alongside image inputs, with suppress-token handling for multimodal placeholders.
- Improved model and server controls. A server-wide context window cap policy was added, embedding requests now respect the effective model context length, and server processes now show an
omlx-serverprocess title.
Performance
Internal tg512 measurements show the main Qwen regression recovered while keeping Gemma performance stable:
{kind=link}
Fixes
- Fixed Qwen VLM/MTP decode behavior by keeping singleton cache layers out of
BatchKVCacheuntil a second request is actually appended. - Fixed prompt-prefix token seeding in
BatchGeneratorso penalty processors see cached prompt tokens correctly. Thanks to @Yukon for identifying the missing token buffer seed. - Fixed SSD cache compatibility across model and cache-layout switches so valid persisted blocks are not deleted for other models or layouts.
- Fixed SSD cache pressure handling by unlinking LRU files outside the bounded write queue and preserving capped-eviction observability. by @cfbraun (#1451)
- Fixed cache-store backpressure and aborted prefill cleanup so new prefills wait safely while cache cleanup is full.
- Fixed an engine-pool acquire-vs-use eviction race and active-request counter leak for embedding and rerank engines. by @Cmerrill1713 (#1668)
- Fixed Gemma 4 MoE multi-turn tool-call corruption by stripping stray tool-call close markers before history is re-rendered. by @kreeger (#1665)
- Fixed Gemma special tokens leaking into API output. by @JimStenstrom (#1698)
- Fixed raw tool-call JSON recovery when model output contains tabs or newlines inside string values.
- Added Hermes-style tool call parsing and streaming support. by @scubamount (#1596)
- Fixed
response_formatdowngrade visibility by returning a client-visibleWarningheader when grammar-constrained output cannot be enforced. by @richgoodson (#1564) - Fixed embedding context length handling so
/v1/embeddingsuses the effective model context window instead of falling back to 512 tokens. by @jackwh (#1694) - Fixed multimodal oQ precision by preserving protected vision and audio tensors as float32 where needed. by @dodams258 (#1682)
- Fixed mlx-audio resample export compatibility for input audio.
- Fixed decoder-aware streaming detokenization and kept the fallback path compatible with older tokenizer wrappers.
- Fixed Gemma 4 unified routing, prompt kwargs preservation, assistant drafter acceptance, and suppress-token handling across scheduler, DFlash, and VLM MTP paths.
- Fixed small-system memory behavior so sub-24GB Apple Silicon systems use the small-system reserve path.
- Fixed idle CPU overhead while models are loaded and guarded idle wakeups for partial engine cores.
- Fixed interactive Claude model picker launch behavior when tier models are configured. by @fparrav (#1638)
- Fixed prerelease Homebrew formula updates so prerelease tags do not update the stable formula.
- Fixed packaging documentation for the staged app path and stale DMG build wording. by @cfbraun (#1458)
macOS App
- Added all DFlash settings to the native model config screen, including verify mode, draft window and sink sizes, quantization controls, in-memory cache entries, and SSD cache size.
- Added the VLM MTP toggle to model settings and gated overlapping speculative controls while VLM MTP is enabled. by @jabagawee (#1654)
- Added the server-wide context window cap to the admin settings UI.
- Fixed the chat composer at 768px tablet portrait width so the sidebar no longer covers it. by @pigeonstorm (#1699)
- Fixed the Settings menu so it stays available when the server is stopped.
- Improved process naming so the server appears as
omlx-server. by @iamckun (#1658)
New Contributors
Thank you to everyone making their first contribution in this release:
@jabagawee, @Cmerrill1713, @kreeger, @sje397, @dodams258, @pigeonstorm, @JimStenstrom, @jackwh, @iamckun, @Kistaro.
Contributors
- @kreeger
- @jabagawee
- @sje397
- @Kistaro
- @jackwh
- @Yukon
- @cfbraun
- @fparrav
- @JimStenstrom
- @pigeonstorm
- @scubamount
- @richgoodson
- @iamckun
- @dodams258
- @Cmerrill1713
Assets 4
0.4.2.dev3
This development release adds native MarkItDown document processing and VLM-based PDF processing in oMLX, improves Gemma 4 tool-call stability, and hardens multimodal precision, cache, memory, and engine scheduling.
oMLX_0.4.2_MarkItDown_v2.mp4
- Added native MarkItDown document processing and VLM-based PDF processing. Uploaded files can now be converted through MarkItDown, and PDFs can use either MarkItDown or VLM OCR from the selected processing engine.
- Improved Gemma 4 tool-call stability. Multi-turn Gemma 4 MoE tool conversations now strip stray tool-call close markers before re-rendering conversation history. by @kreeger in #1665
- Improved raw tool-call JSON recovery. Tool calls with raw tabs or newlines inside generated JSON string values are now recovered and returned as valid structured tool calls.
- Improved multimodal oQ precision. Protected vision and audio tensors are preserved in float32 during oQ conversion to avoid FP16 overflow and multimodal quality loss. by @dodams258 in #1682
- Improved engine eviction safety. Embedding and rerank engines are now leased while in use, preventing acquire-vs-use eviction races and resetting leaked activity counters on teardown. by @Cmerrill1713 in #1668
- Improved cache and prefill backpressure. Hot-cache budget is shared across models, cache-heavy prefills wait while cache-store cleanup is full, and idle wakeups are guarded for partial engine cores.
- Improved small-system memory behavior. Sub-24GB Apple Silicon systems now use the small-system reserve path, reducing over-reservation from tiered defaults.
- Reduced idle CPU overhead. Loaded models now avoid unnecessary idle wakeups while remaining ready for requests.
New Contributors
- @Cmerrill1713 made their first contribution in #1668
- @kreeger made their first contribution in #1665
- @sje397 made their first contribution in #1671
- @dodams258 made their first contribution in #1682
Assets 4
0.4.2.dev2
This development release fixes Gemma4 Unified image understanding and OCR quality in oMLX, improves Gemma4 Unified vision feature cache handling, and fixes Gemma4 Unified MTP compatibility.
- Fixed Gemma4 Unified VLM prefill handling so multimodal token-type IDs are preserved through the oMLX external prefill path.
- Restored Gemma4 Unified 12B image understanding and OCR quality, including text-reading prompts that previously degraded into hallucinated descriptions.
- Improved Gemma4 Unified vision feature cache correctness for position-aware and compacted vision features.
- Fixed Gemma4 Unified MTP compatibility.
Assets 4
0.4.2.dev1
This development release updates mlx-vlm to 0.6.1 (041f889) to add Gemma4 Unified (12B) support, adds cohere2_moe (Command A+) support, and includes several bug fixes.
- Updated
mlx-vlmto 0.6.1 (041f889) with Gemma4 Unified long-text prefill fixes. - Added support for Gemma4 Unified (12B) through the updated mlx-vlm backend.
- Added support for
cohere2_moemodels, including Command A+. - Fixed streaming detokenization for raw VLM/Gemma4 paths so byte-fallback tokenizers no longer emit replacement characters in split UTF-8 output.
- Added VLM MTP controls to the macOS model settings UI.
- Exposed advanced DFlash model settings in the macOS app, including the
ddtreeverify mode. - Fixed speculative-control state in the macOS app while VLM MTP is enabled.
- Restored the interactive Claude model picker in
omlx launch.
Assets 4
v0.4.1
For the major 0.4.0 upgrade notes, please see the 0.4.0 release notes.
This patch release focuses on memory-pressure stability, robust model discovery, managed server lifecycle controls, and macOS app and CLI quality-of-life improvements.
Highlights
- Improved prefill memory handling. Static memory reserves were reduced, throttle tiers were simplified, and prefill chunk floors were raised for more stable throughput.
- Idle-model eviction before prefill throttling. Loaded but idle models can now be freed before new work is rejected or throttled.
- Managed server lifecycle controls. The macOS app and admin surfaces now expose server lifecycle control, and when the macOS app is installed the server can also be controlled from the CLI with
omlx start,omlx stop, andomlx restart. - Copyable model IDs in the SwiftUI app. Model ID copy buttons were added to the Models list and per-model detail header.
Fixes
- Fixed TurboQuant KV cache selection for MLA models by excluding incompatible MLA models from TurboQuant cache paths. by @popfido (#1626)
- Fixed scheduler handling so prefill error outputs are preserved during decode. by @ken-zzzzz (#1622)
- Fixed inaccessible secondary model directories so they are tolerated instead of breaking model discovery or admin reload flows.
- Fixed LFM2 pythonic tool parser support.
- Fixed a macOS crash when deleting chat template kwargs. by @nethbotheju (#1634)
- Fixed shell integration behavior so editing shell init files requires explicit user consent. (#1633)
- Fixed app CLI wrapper symlink resolution in bundled macOS builds.
macOS App
- Added model ID copy affordances in the SwiftUI Models screen and model detail screen.
- Improved server lifecycle integration between the macOS app and local control server.
- Improved shell integration consent flow and related UI copy.
New Contributors
Thank you to everyone making their first contribution in this release:
Assets 4
v0.4.0
0.4.1 is now available. If you reached this page from a direct link, please use the latest patch release instead.
0.4.0 is the first official release of the native Swift macOS app. The old PyObjC menubar app has been retired, and the macOS bundle now ships as a Swift app with a redesigned onboarding flow, settings UI, status surfaces, model management, and GitHub Releases based updater.
This Swift transition was driven by excellent work from @popfido, with follow-up polish and release-path fixes folded in after the initial merge. Thank you for the huge amount of thoughtful work here — this is the biggest user-facing macOS change oMLX has shipped so far, and it substantially raises the quality of the desktop app.
oMLX 0.4.0 native Swift macOS app screenshot
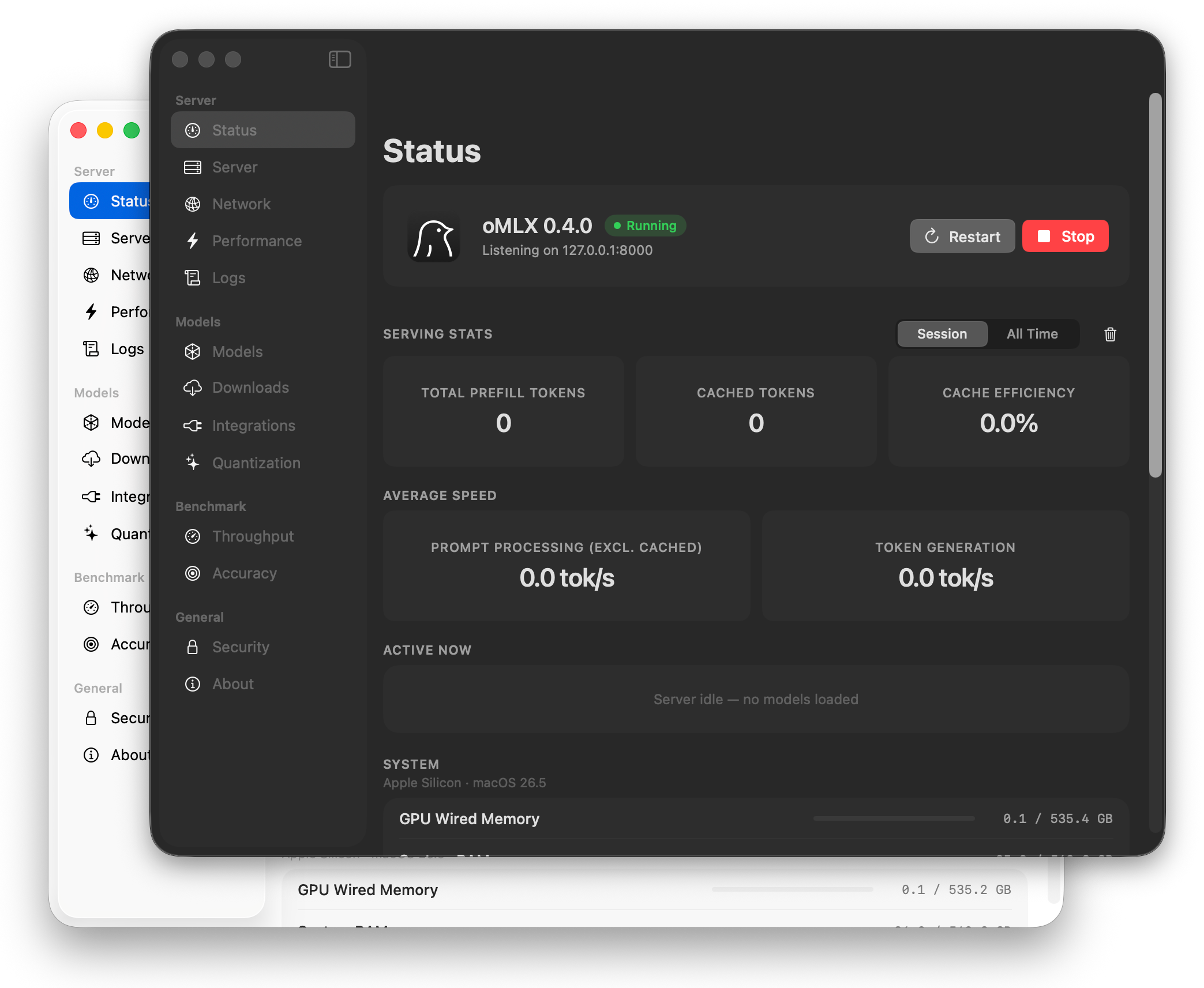{kind=link}
Highlights
- Native Swift macOS app. The old PyObjC menubar app has been replaced by a native Swift/SwiftUI app, with new onboarding, settings, status, model management, downloads, integrations, and update flows. by @popfido
- Improved menubar and app status. Live port/status updates, StatusKit fixes, version display, supervised-server handling, and cleaner running-state behavior. by @popfido
- Standard Hugging Face cache model directory support. oMLX can now discover models from the standard Hugging Face cache location, with controls for toggling HF cache discovery and managing local model directories.
- Safer update flow. App updates now honor the selected update channel and require confirmation before download.
- Browser chat UI received a major usability overhaul and follow-up message/action fixes. by @beamivalice
- xgrammar is bundled into the venvstacks export with the no-torch stub path. by @cfbraun
- Memory guard tuning relaxed throttle/eviction thresholds, improved Custom tier behavior, and added CLI options for memory guard configuration.
Runtime, cache, and scheduler
- Per-engine MLX threads eliminate cross-engine stream contamination. by @ivaniguarans
- Store-cache and boundary snapshot paths now materialize lazy arrays on the owning thread before async byte extraction. by @aeyeopsdev
- Boundary snapshot cleanup races and stale snapshot handling were fixed. by @cfbraun
- Predictive prefill throttling and reclaim/requeue behavior reduce mid-stream OOM failures. by @sdiamanEXUS
- Paged cache references are released correctly on preflight/prefill rejection paths. by @cfbraun
- Paged cache now disables itself cleanly when SSD initialization fails instead of breaking startup. by @lvsijian8
- VLM, SpecPrefill, and draft-model lazy state is materialized on loader threads to avoid stream errors. by @cfbraun
- Engine stop now yields back to the event loop so shutdown/restart paths do not monopolize the loop. by @fqx
- Unreadable model directories are handled during startup instead of aborting discovery.
- DMG builds now preserve engine commit metadata.
MTP, oQ, TurboQuant, and model compatibility
- Safe row-wise MTP decoding is enabled for aligned batches, with fallback for unsafe late-join batches.
- Qwen3.6 MXFP4 mixed norm conventions and MTP preservation are handled more safely. by @scubamount
- TurboQuant now supports batched KV-cache compression and fixes batch merge edge cases. by @popfido
- DFlash/MTP transition restores Qwen GQA attention hooks.
- LFM text MoE model discovery is classified correctly as LLM instead of mlx-audio STS. by @samfenwick
- Step 3.7 Flash support is patched through the mlx-lm compatibility path.
API and integrations
- Guided grammar is now exposed as a model setting and maps into the existing structured-output grammar path. by @MrNiceRicee
- Anthropic cache-control accounting and model context length reporting were fixed. by @richgoodson
tool_choice: "none"is respected for MCP tools. by @lvsijian8- Tool call function names are trimmed while preserving type validation behavior. by @palvaleri
- Wildcard bind addresses such as
0.0.0.0are normalized to usable local client addresses. by @monroewilliams - Top-level
omlximports are lazy-loaded to improve startup compatibility, including NumPy 2.x environments. by @fparrav - Claude Code compatibility was updated for newer request behavior. by @lx1229
- CLI shutdown handles
KeyboardInterruptcleanly. by @fry69 - Integration launch context was unified across external tool integrations.
Admin UI and macOS UI
- Downloads now include a model card sheet with metadata, files, and tags. by @popfido
- Local Models sorting is now case-insensitive ascending. by @MwC-Trexx
- SwiftUI model lists now also sort case-insensitively.
- Active Models layout works better on narrow screens. by @samfenwick
- Model settings table headers are aligned. by @ilukashin
- Server/app settings apply behavior and live port display were cleaned up. by @popfido
- Light mode settings contrast was restored.
- Mac app CLI launch shim and CLI wrapper signing were restored.
- Admin custom-tier memory text is synced with server behavior.
Packaging, CI, and tests
- The venvstacks driver is pinned/detected more reproducibly. by @popfido
- The
mlx-frameworkvenvstacks layer was renamed tomlx-base. by @popfido - CI workflow and broader unit-test coverage were added. by @Mearman, @cfbraun, @fry69
- Python 3.14 was added to the CI matrix. by @fry69
- Formula automation and release URL substitution were corrected.
- paroquant dev dependency was bumped to 0.1.15.
New Contributors
Thank you to everyone making their first contribution in this release:
@cfbraun, @chenqianhe, @jcalvert, @MwC-Trexx, @azhangd, @scubamount, @sdiamanEXUS, @ilukashin, @tylerliu, @MrNiceRicee, @lx1229, @palvaleri, @monroewilliams.
Contributors
- @jcalvert
- @monroewilliams
- @Mearman
- @popfido
- @fqx
- @cfbraun
- @MwC-Trexx
- @fparrav
- @tylerliu
- @lvsijian8
- @ilukashin
- @palvaleri
- @lx1229
- @samfenwick
- @MrNiceRicee
- @chenqianhe
- @scubamount
- @richgoodson
- @azhangd
- @fry69
- @beamivalice
- @sdiamanEXUS
- @ivaniguarans
- @aeyeopsdev