How to export/print version differences between child version and default version from ArcGIS Pro to an Excel spreadsheet or .csv file?
When I have a version other than the default, and click on version changes in the versioning tab. The window is opened to two tabs with target version tab, and differences tab.
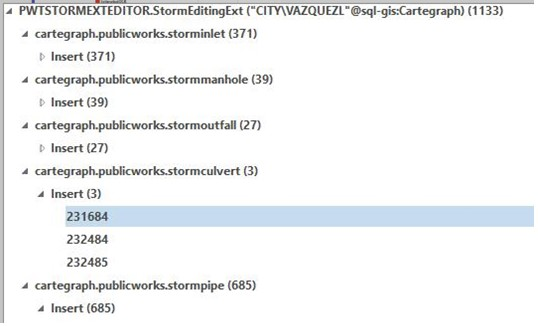
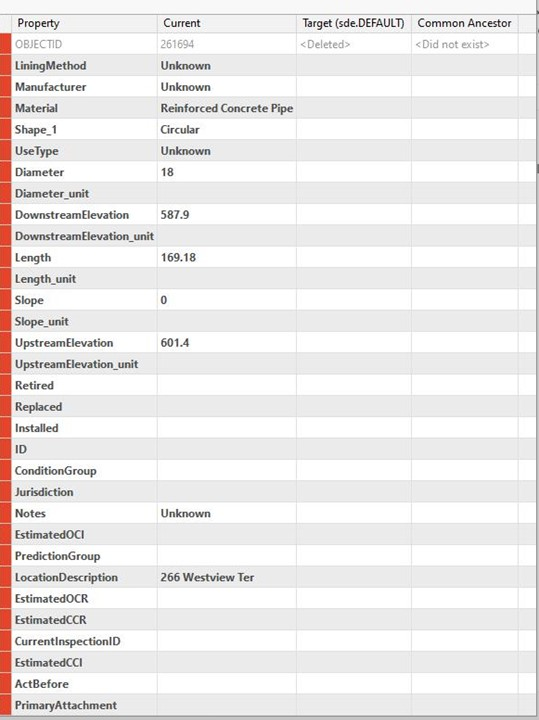
The differences tab shows a tree list of the version changes by feature class, and on the side there is another window that has a table of columns with the first column being the schema of the attribute table, then the second column is what is currently in the table, then the next column is the selected target version, then there is the common ancestor version.
The view of columns looks like it could easily be exported into an Excel spreadsheet for each update. Does anyone have any leads on python scripts or tools that could help do this?
I looked into the diagnose version tables, but ArcGIS Pro wouldn't let me put any type of file into the diagnose version table log field.
Version Differences List per feature class Columns of current target and common ancestor
{kind=link}
{kind=link}
1 Answer 1
Found a Python 2 script on the Stack Exchange, and converted it into a python 3 script. Brought in the parent and child versions into a project as separate database connections, so I could have two different paths for the parent and child version.
import arcpy
import os
inputDataset = r"C:\Users\vazquel\OneDrive\Documents\LocalWorkspace\Parent.gdb\ParentVersion"
targetDataset = r"C:\Users\vazquel\OneDrive\Documents\LocalWorkspace\Child.gdb\ChildVersion"
outputFolder = r"C:\Users\vazquel\Desktop\LocalWorkspace\ComparisonReports"
outputName = "Comparison_Report_1"
inputDict = {}
changes = []
#GET FIELDS
arcpy.AddMessage("Getting Fields\n")
fields = ["OID@", "Shape@JSON"]
fieldList = arcpy.ListFields(targetDataset)
for field in fieldList:
if field.name not in ("OBJECTID", "SHAPE", "Shape_Length", "Shape_Area", "RuleID", "Override"):
fields.append(field.name)
#SEARCH INPUT DATASET, ADD DATA TO DICTIONARY
arcpy.AddMessage("Searching Input Dataset\n")
with arcpy.da.SearchCursor(inputDataset, fields) as inputRows:
for inputRow in inputRows:
oid = inputRow[0]
geom = inputRow[1]
attrs = {"Geometry":geom}
for i in range(len(fields)):
if i > 1:
field = str(fields[i])
attrs[field] = inputRow[i]
inputDict[oid] = attrs
#SEARCH TARGET DATASET AND COMPARE TO DICTIONARY DATA
arcpy.AddMessage("Searching Target Dataset\n")
with arcpy.da.SearchCursor(targetDataset, fields) as targetRows:
for targetRow in targetRows:
# If no match in dictionary, it's a delete
oid = targetRow[0]
if oid not in inputDict.keys():
changes.append([oid, "Delete", "N/A", "N/A", "N/A"])
else:
# If geometries don't match, it's a geometry update
geom = targetRow[1]
if geom != inputDict[oid]["Geometry"]:
changes.append([oid, "Geometry Update", "N/A", "N/A", "N/A"])
# If attribute values don't match, it's an attribute update
for j in range(len(fields)):
if j > 1:
field = str(fields[j])
value = targetRow[j]
if value != inputDict[oid][field]:
changes.append([oid, "Attribute Update", field, value, inputDict[oid][field]])
# If there was a match, remove item from dictionary
del inputDict[oid]
#Anything left in the dictionary is an added feature
for oid in inputDict.keys():
changes.append([oid, "Add", "N/A", "N/A", "N/A"])
#Write Output Change File
arcpy.AddMessage("Writing Output File\n")
outputFile = open(outputFolder + os.sep + outputName + ".csv", "w")
outputFile.write("OID,CHANGETYPE,FIELD,INPUTVALUE,TARGETVALUE\n")
for change in changes:
line = ""
for item in change:
line += str(item)
line += ","
line = line[:-1]
line += "\n"
outputFile.write(line)
arcpy.AddMessage("\n\nAll Done!\n\n")
outputFile.close()