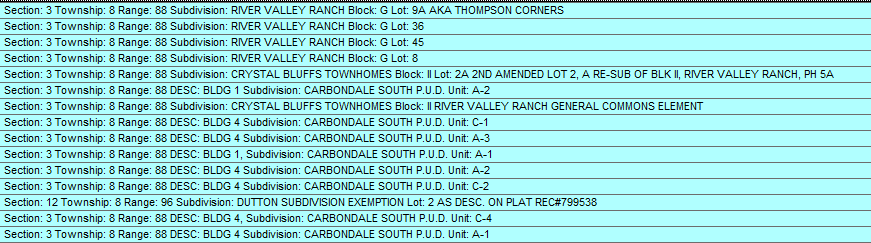
I have some parcel data where I need to extract a subdivision name from a long string. The format is always "Subdivision: ____ ______ _____" etc. BUT, there is no uniformity to what comes before or after "Subdivision: " or the actual name of the subdivision. In my example below it shows that "Block: " follows "Subdivision: " but that's not always the case.
I'd like to learn how to solve this issue using python, but VB can also be used. I was reading about re (edit: Regex) in python, but without some further explanation I'm a little lost. Here is a screen shot showing what the data looks like.
Any tips on where I should try to go with this?
{kind=link}
-
What is the "re" in "I was reading about re in python"? Regular Expressions? You could use Regex to solve this.Dan C– Dan C2019年01月31日 15:10:46 +00:00Commented Jan 31, 2019 at 15:10
-
Hi Dan, yes, i'm referring to Regex. I have no prior experience with Regex and I was mainly asking this question to see if that's the easiest/most straight forward way to do this. Relatively new to Python as well, so reading the documentation to Regex is pretty confusing.Rusty– Rusty2019年01月31日 15:24:16 +00:00Commented Jan 31, 2019 at 15:24
2 Answers 2
For a more general approach, you could use a regex like r'\s*(\w+):\s*' in the re.split() function to build a dict of parcel "keys" and "values" (not sure of your parcel terminology).
This regex looks for:
\s*- zero or more whitespace characters(\w+)- one or more alphanumeric (a-Z, 0-9, but not other characters), note that the()brackets indicate a capture group:- followed by a colon\s*- followed by zero or more whitespace characters
The re.split function returns a list of each section of text between the matches, but because because we've used brackets to specify a capture group, those captured groups are returned as well.
For example:
import re
parcel_text = 'Section: 3 Township: 8 Range: 88 Subdivision: Blah blah blah Block: G Lot: 9A'
print(re.split(r'\s*(\w+):\s*', parcel_text))
['', 'Section', '3', 'Township', '8', 'Range', '88', 'Subdivision', 'Blah blah blah', 'Block', 'G', 'Lot', '9A']
parcel_list = re.split(r'\s*(\w+):\s*', parcel_text)[1:] # Strip the first element as it's an empty string for some reason
parcel_dict = dict(zip(parcel_list[0::2], parcel_list[1::2]))
# [0::2] = makes a list of every 2nd element starting from 0, [1::] is the same except starting from 1
# zip "zips" those 2 lists together into a list of 2 element lists, i.e [['Section', '3'], ['Township', '8'], etc...]
print(parcel_dict)
{'Section': '3',
'Township': '8',
'Range': '88',
'Subdivision': 'Blah blah blah',
'Block': 'G',
'Lot': '9A'}
You can turn that into a field calculator expression, something like:
Code block / Pre-logic Script Code
import re
def parse_parcel(parcel_text):
parcel_list = re.split(r'\s*(\w+):\s*', parcel_text)[1:]
parcel_dict = dict(zip(parcel_list[0::2], parcel_list[1::2]))
return parcel_dict
Expression
parse_parcel (!your_parcel_field!).get('Subdivision') #.get avoids a KeyError if there's no "Subdivision"
-
Hi! Thanks for your reply. I have tried your code and I'm getting the error: AttributeError: 'list' object has no attribute 'get'Rusty– Rusty2019年02月01日 15:42:54 +00:00Commented Feb 1, 2019 at 15:42
-
-
Also, worth noting that if I run the script without ".get('Subdivision')", it runs without errors, but returns nothing.Rusty– Rusty2019年02月01日 17:41:41 +00:00Commented Feb 1, 2019 at 17:41
-
it seems like we're almost there, but all that returned was the word "Subdivision" for each record in the table that contained the word in the original string. Just to clarify, I'm trying to return the actual name of the subdivision following the string "Subdivision: ".Rusty– Rusty2019年02月01日 22:22:51 +00:00Commented Feb 1, 2019 at 22:22
-
Just for clarification if anyone finds this. I was also getting the error "Invalid column value" when trying to edit in SDE. When attempting to work with a shapefile I received the error "The row contains a bad value." Turns out my field wasn't long enough. Thank you @user2856Rusty– Rusty2019年02月04日 15:34:27 +00:00Commented Feb 4, 2019 at 15:34
I think the following Script should work.
def getsubdivison (a)
x = a.find("Subdivision:")
a2 = a[x:]
x = 1
while x != 0 :
y = a2.rfind(":")
x2 = a2.find(":")
if y == x2:
y2 = a2.rfind(" ")
a3 = a2[:y2]
return (a3)
else:
a2 = a2[:y]
The script will first search the Indexposition for Subdivison:
After that the script slices the string until y and x2 are the same. In practice that will look like this:
abc Subdivison: abc12 Unit: abcd Block: qwq
Subdivison: abc12 Unit: abcd Block: qwq
Subdivison: abc12 Unit: abcd Block
Subdivison: abc12 Unit
Now the script just find the last whitespace and slices the string that way, that just the Subdivion Information is available.
Subdivison: abc12
The script you must only copy into the Codeblock(Pre logic script Code)inside the field calculator and in the lower box you enter the following:
getsubdivison (!your_field_name!)
{kind=link}
Hope this will help you.
-
Thanks for your response. I'm getting a 999999 error "Invalid Column Value [SUBDNAME]. My only guess is that there are values longer than my field allows. Hmm.Rusty– Rusty2019年01月31日 16:10:37 +00:00Commented Jan 31, 2019 at 16:10
-
1Your method also worked. Just wanted to let you know. Turns out my field wasn't long enough which was causing the error.Rusty– Rusty2019年02月04日 15:48:28 +00:00Commented Feb 4, 2019 at 15:48
Explore related questions
See similar questions with these tags.