I'm trying to create this result (see the first row below):
{kind=link}
using this data (see the selected row):
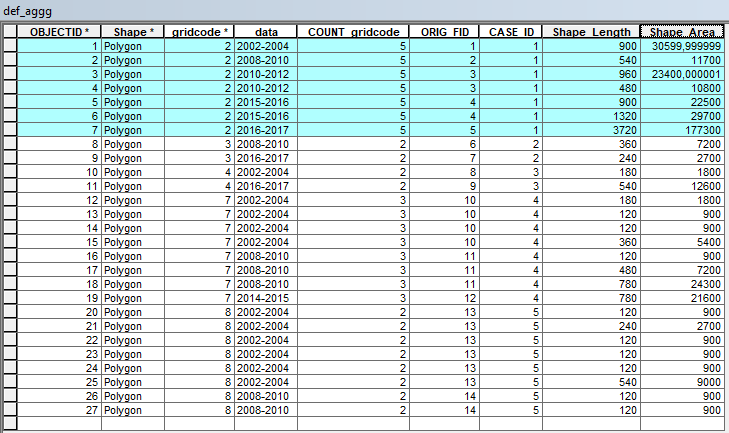{kind=link}
As you can see, the two vector tables have a common field, that relate themselves, the input is "gridcode" and the output must be "id_group".
I'm not expert and I've expent too much time trying to get a solution, nevertheless I can't find anyone.
The pictures are just an example, because the real shapefiles are from around 1M of features.
I was trying to implement this solution from Comparison between two fields of two tables using ArcPy cursors? without success, perhaps because I it takes so much time to create the dictionary.
import arcpy
from time import strftime
print "Start script: " + strftime("%Y-%m-%d %H:%M:%S")
def_agrupada = r'neighbours'
deff = r'entry_data'
fields_deff = ["gridcode", "data", "Shape_Area"]
list1 = [r[0] for r in arcpy.da.SearchCursor(deff, fields_deff)]
list2 = list(set(list1))
list2.sort()
dicc = {}
for f in list2:
dicc[f] = [r[:] for r in arcpy.da.SearchCursor(deff, fields_deff) if r[0] == f]
dicc
print "Finished script: " + strftime("%Y-%m-%d %H:%M:%S")
2 Answers 2
You are wasting time creating a list set and sorting it and then running a cursor over and over to match one value at a time from the ordered data. The dictionary eliminates all of that. The dictionary key is inherently stored as a set and is always stored without any predefined order. The power of a dictionary is that it can access all keys in any order with virtually no lag time. After loading a dictionary randomly you can output the dictionary records in key sort order using sorted(dict),
See my Turbo Charging Data Manipulation with Python Cursors and Dictionaries blog for the best ways to load a dictionary. Load the dictionary using this code. It will load the data into the dictionary in about 2 to 5 minutes if your data has around 1 million records.
You could run into a memory issue if you are using Python 2.7. If you run the code in Python 3.4 it should be fine.
import arcpy
from time import strftime
print "Start script: " + strftime("%Y-%m-%d %H:%M:%S")
def_agrupada = r'neighbours'
deff = r'entry_data'
fields_deff = ["gridcode", "data", "Shape_Area"]
dicc = {r[0]:(r[1:]) for r in arcpy.da.SearchCursor(deff, fields_deff)}
print "Finished script: " + strftime("%Y-%m-%d %H:%M:%S")
-
thanks for your answer Richard. I understand they way as you create the dictionaries, nevertheless, my problem go on a different way. What I'm expecting is access to all the records that have the same gridcode, and do some operations with them. That's why I tried to create a dictionary with the gridcode as the Key.dguerrero– dguerrero2018年08月08日 23:16:39 +00:00Commented Aug 8, 2018 at 23:16
-
1The dictionary key is the gridcode in the code I have given. The code is only showing the dictionary loading step. You want to load the dictionary from the source that will not change. The blog shows examples that do what you want to do. The next step would be to run an updatecursor on the related table that you want to update and use the information from the dictionary to update it based on the matching gridcode. Read the blog.Richard Fairhurst– Richard Fairhurst2018年08月08日 23:22:35 +00:00Commented Aug 8, 2018 at 23:22
-
I've already read a few sections of the blog, however I still do not know how I could create the dictionary with the same key for several records, i.e., gridcode "2" is repeated several times in the logs. In your example, the dictionary only save the las record, isn't it?.dguerrero– dguerrero2018年08月09日 01:50:24 +00:00Commented Aug 9, 2018 at 1:50
-
You did not make it clear that the gridcode was a key for multiple source records. The blog is intended to introduce the key concepts, but by no means explores all of the possible relationships that can be supported. The last example works if you are summarizing the many records into a summary of values. The code to build a dictionary with a list of all records for the key is in lines 14 thru 29 in my Creating Labels blog community.esri.com/blogs/richard_fairhurst/2015/02/07/…. Then please explain what kind of update you want to do in other table.Richard Fairhurst– Richard Fairhurst2018年08月09日 03:55:42 +00:00Commented Aug 9, 2018 at 3:55
-
Ok. I want the other table the field "id_group" acts as a target join field with the "gridcode" as a source join field. So, in the other table I want, for example, for the first record, in the field "n_fids" the script count the number of records that have the grid code "2" (in the source table), and after put this value in that field. Thats why I was trying to build a dictionary with the gridcode as a key.dguerrero– dguerrero2018年08月09日 11:41:22 +00:00Commented Aug 9, 2018 at 11:41
According with the @Richard Fairhurst help, I was able to adapt and implement their code to solve my problem, below is the code. I do not know if it is optimised, but it's working for me without problems.
import arcpy
from time import strftime
updateFC = r'\neighbours'
deff = r'\data'
fields_deff = ["gridcode", "data", "Shape_Area"]
updateFieldsList = [u'id_group', u'n_events', u'ini_date', u'end_date', u'ini_ha', u'end_ha', u'n_fids', u'fids', u'dates_ev', u'ha_ev']
def getIniDate(relateDict, key_value):
list1 = [f[0] for f in relateDict[key_value]]
return min(list1)
def getEndDate(relateDict, key_value):
list1 = [f[0] for f in relateDict[key_value]]
return max(list1)
def getArea(relateDict, key_value):
listaa = relateDict[key_value]
datos = list(set([f[0] for f in listaa]))
datos.sort()
area = []
for d in datos:
cuenta = 0
for e in listaa:
if d == e[0]:
cuenta += e[1]
area.append(cuenta)
return area,datos
def getFids(relateDict, key_value):
listaa = relateDict[key_value]
fids = list(set([f[0] for f in listaa]))
return fids
print "Start script: " + strftime("%Y-%m-%d %H:%M:%S")
relateDict = {}
with arcpy.da.SearchCursor(deff, fields_deff) as relateRows:
for relateRow in relateRows:
relateKey = relateRow[0]
if not relateKey in relateDict:
relateDict[relateKey] = [relateRow[1:]]
else:
relateDict[relateKey].append(relateRow[1:])
del relateRows, relateRow
with arcpy.da.UpdateCursor(updateFC, updateFieldsList) as updateRows:
for updateRow in updateRows:
# store the Join value of the row being updated in a keyValue variable
key_value = updateRow[0]
# verify that the keyValue is in the Dictionary
if keyValue in relateDict:
# transfer the value stored under the keyValue from the dictionary to the updated field.
n_events = len(getFids(relateDict, key_value))
ini_date = getIniDate(relateDict, key_value)
end_date = getEndDate(relateDict, key_value)
ini_area = getArea(relateDict, key_value)[0][0]
end_area = sum(getArea(relateDict, key_value)[0])
n_fids = len(relateDict[key_value])
dates_ev = ";".join(getArea(relateDict, key_value)[1])
ha_ev = ';'.join(str(round(x,0)) for x in getArea(relateDict, key_value)[0])
updateRow[1] = n_events
updateRow[2] = ini_date
updateRow[3] = end_date
updateRow[4] = ini_area
updateRow[5] = end_area
updateRow[6] = n_fids
updateRow[8] = dates_ev
updateRow[9] = ha_ev
updateRows.updateRow(updateRow)
print "Finished script: " + strftime("%Y-%m-%d %H:%M:%S")