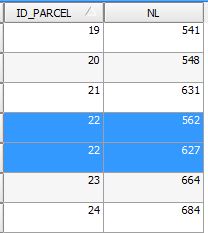
I have two fields: ID_PARCEL and NL. The ID_PARCEL is the field that contains duplicate records. I would like to remove the duplicate record by keeping the minimum NL field value. For example: the value 22 in the ID_PARCEL field is duplicated, so the row of the attributes table that should be removed is the one with the highest value in the NL field, which in this case is the value 627.
I searched on the site, but what I found was deleting duplicate records without the condition to keep the minimum value of another field. Can someone help me?
{kind=link}
-
1it's possible to do this without code using SQL (even if you're not using a database). Or do you want to use pyqgis specifically?Steven Kay– Steven Kay2017年05月23日 20:34:33 +00:00Commented May 23, 2017 at 20:34
1 Answer 1
If I understand your question, you may use the following code:
layer= iface.activeLayer() # load the layer as you want
vals = {} # create an empty dictionary
# Let's populate the dictionary
for feat in layer.getFeatures():
if feat['ID_PARCEL'] not in vals:
vals[feat['ID_PARCEL']] = [feat['NL']]
else:
vals[feat['ID_PARCEL']].append(feat['NL'])
# Let's find the minimum value from the "NL" field for each "ID_PARCEL" field
for key, value in vals.iteritems():
vals[key] = min(value)
# Let's delete the unwanted features
with edit(layer):
for feature in layer.getFeatures():
k = feature['ID_PARCEL']
if feature['NL'] != vals[k]:
layer.deleteFeature(feature.id())
Since the edits will apply immediately, please create a backup copy of the original data before running the above code.
-
If i change the field names to the field names i have, all is deleted, why?Sander Van Beuningen– Sander Van Beuningen2022年09月14日 07:29:45 +00:00Commented Sep 14, 2022 at 7:29
Explore related questions
See similar questions with these tags.