I have a procedure that insert data to table where the data doesn't exists.
right now it's done in two steps :
- check if the data exists already,
- if not, insert it
i want to change it to do INSERT where not exists as proposed in this article it should improve performance. https://devblogs.microsoft.com/azure-sql/the-insert-if-not-exists-challenge-a-solution/
Here are the procedures :
- Current proceudre
ALTER PROCEDURE [dbo].[AddTest_IfInsert]
(
@CorrelationId uniqueidentifier,
@TransactionId BIGINT
)
AS
BEGIN
IF NOT EXISTS (SELECT TOP 1 1 FROM dbo.Test
WHERE [CorrelationId] = @CorrelationId and TransactionId = @TransactionId
)
BEGIN
INSERT INTO dbo.Test
(CorrelationId,TransactionId)
values (@CorrelationId,@TransactionId)
SELECT SCOPE_IDENTITY() AS ResultId
END
ELSE
SELECT 0 AS ResultId
END
- New procedure :
CREATE OR ALTER PROCEDURE [dbo].[AddTest_WhereInsert]
(
@CorrelationId uniqueidentifier,
@TransactionId BIGINT
)
AS
BEGIN
INSERT INTO dbo.Test
(CorrelationId,TransactionId)
select
@CorrelationId,
@TransactionId
from dbo.Test
where not exists (select top 1 1
FROM dbo.Test WITH (NOLOCK)
where CorrelationId = @CorrelationId
AND TransactionId = @TransactionId
)
IF @@ROWCOUNT = 0
BEGIN
SELECT 0 AS ResultId
END
ELSE
BEGIN
SELECT SCOPE_IDENTITY() AS ResultId
END
END
Here is the Test table that i work with :
CREATE TABLE Test
(
Id BIGINT Identity(1,1) ,
CorrelationId uniqueidentifier,
TransactionId BIGINT
)
Here are my problems with the new procedure:
- If i try to run it for the first time on a empty table It doesn't insert any data. only when i insert the first row it starts inserting data. Here is my code :
DECLARE @CorrelationId nvarchar(100) = 'C0E68827-CC46-4A16-BEDE-B3D98D21AFFA'
DECLARE @TransactionId BIGINT = 4
exec [dbo].[AddTest_WhereInsert] @CorrelationId,@TransactionId
then i inserted data :
DECLARE @CorrelationId nvarchar(100) = 'C0E68827-CC46-4A16-BEDE-B3D98D21AFFA'
DECLARE @TransactionId BIGINT = 4
INSERT INTO dbo.Test
(CorrelationId,TransactionId)
values (@CorrelationId,@TransactionId)
and i try to run it again it starts inserting data.
DECLARE @CorrelationId nvarchar(100) = 'D0E68827-CC46-4A16-BEDE-B3D98D21AFFA'
DECLARE @TransactionId BIGINT = 5
exec [dbo].[AddTest_WhereInsert] @CorrelationId,@TransactionId
don't understand why is that?
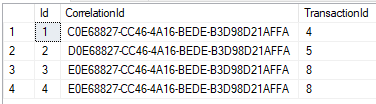
- Problem number 2 : when i start inserting data, after the second insert it inserts duplicate data. enter image description here
{kind=link}
then i run
DECLARE @CorrelationId nvarchar(100) = 'E0E68827-CC46-4A16-BEDE-B3D98D21AFFA'
DECLARE @TransactionId BIGINT = 8
exec [dbo].[AddTest_WhereInsert] @CorrelationId,@TransactionId
select * from dbo.Test
and this is the result: enter image description here
{kind=link}
why does it insert duplicate data? what is wrong with my code?
1 Answer 1
If you want to go that route then you can use
INSERT INTO dbo.Test
(CorrelationId,
TransactionId)
SELECT @CorrelationId,
@TransactionId
WHERE NOT EXISTS (SELECT *
FROM dbo.Test WITH (UPDLOCK, HOLDLOCK)
WHERE CorrelationId = @CorrelationId
AND TransactionId = @TransactionId)
The FROM dbo.Test in your original code is a mistake and explains why you get no rows inserted when the table is empty and too many rows inserted when it already has multiple rows.
You can do a SELECT without a FROM.
In the case that the row does not exist when the subquery is evaluated then the HOLDLOCK hint will lock the range where it would exist.
Without locking the range it is still possible for two concurrent executions to both run the subquery and conclude the row does not exist and proceed to try and insert it.
The UPDLOCK hint in conjunction with this means that one of the transactions will encounter blocking trying to lock the range - rather than allowing both to succeed and then waiting for the deadlock monitor to kick in after deadlock ensues when they both try and upgrade their S locks.
The above talk of "ranges" does assume that you have a suitable index that such a range lock can be acquired on. The screenshot in the question shows that duplicates exist for CorrelationId, TransactionId.
You should add a unique index on this anyway so that (amongst other benefits)
- Duplicates are never possible
- The
EXISTScheck can be done as an index seek. - The key range locked can be minimal and not just fall back to locking the whole table as no suitable index.
I also changed select top 1 1 to SELECT *.
SQL Server already knows that it only needs to read a single row from the semi join without the top 1 and selecting the constant 1 in this context is treated the same as selecting *.
-
Many thanks for the informative solution. I did not know you can run a SELECT without a FROM... Also i will read more about the hints you suggested as i didn't use that one before. Do you think it would help the performance on this case?dexon– dexon2024年01月23日 18:05:28 +00:00Commented Jan 23, 2024 at 18:05
-
2For performance you need an index on
CorrelationId, TransactionIdso it doesn't have to scan the whole table to see if there are duplicates. And this should be declared as unique whilst you are at it. With that in place you'll just have to test performance. If you expect attempts to insert duplicates to be quite rare then simply optimistically trying the insert and catching any duplicate key exception could be bestMartin Smith– Martin Smith2024年01月23日 18:11:21 +00:00Commented Jan 23, 2024 at 18:11