I have 3 tables:
test_productInfo: contains information about the product
test_productCreator: contains all the users in our system
test_productOwner: contains information about who is the owner of a product(s). A cross reference table between test_productInfo and test_productCreator.
My stored procedure takes a productCreatorId or multiple productCreatorIds and a sort key and returns the first 1000 rows from test_productInfo(all columns) sorted by the sort key passed in. Unfortunately, I do have to select everything.
I have pasted the current query we have below and here is the execution plan for it: https://www.brentozar.com/pastetheplan/?id=SyKgEEVNj
I'm getting back data for 20 users. The current query has sort spilling into tempdb.
I added a new non-clustered index on productId which is the clustering key and included all the sort keys. I modified the query to only select productId when sorting so that this new index can be used and stored the results in a temp table. In a subsequent query I'm adding all the columns required and doing a sort again. This query works well for users who have more than 1000 rows coz' I'm not sorting more than 1000 rows when all the columns are being selected. For users less than 1000 rows i'm hitting the productInfo table twice but I did not observe much of a difference in timing between my current query and the modified query. Here's the exeuction plan for the modified query: https://www.brentozar.com/pastetheplan/?id=SyA_SVEVs
With the new modified query, i'm trying to reduce the sort spills and i'm seeing some improvement especially when there are more than 1000 rows.
Does it make sense to create a non-clustered index on a clustering key with some columns included? is there a better way to re-write my current query?
--drop table test_productInfo
--drop table test_productOwner
--drop table test_productCreator
Create Table test_productInfo
(
productId uniqueIdentifier Primary Key,
productName varchar(100),
productRegion varchar(100),
productCreatedDt Datetime,
productUpdatedDt Datetime,
productStatus varchar(100),
isProductsold bit,
productLineNumber Int,
productLineId uniqueIdentifier,
productAddress varchar(100),
productAddress2 varchar(100),
productCity varchar(100),
productState varchar(100),
productCountry varchar(100),
productZip Varchar(100),
productLatitude varchar(100),
productLongitude varchar(100)
)
Create Table test_productOwner
(
productOwnerId Int Identity(1,1),
productId uniqueIdentifier,
productCreatorId uniqueIdentifier,
Createddate datetime,
modifieddate datetime
)
Create Table test_productCreator
(
productCreatorId uniqueIdentifier primary key,
productCreatorName varchar(100),
createddate datetime,
modifieddate datetime
)
ALTER TABLE test_productOwner ADD CONSTRAINT PK_test_productOwner PRIMARY KEY NONCLUSTERED(productOwnerId)
create clustered index ix_test_productOwner_productId On dbo.test_productOwner(productId)
create nonclustered index ix_test_productOwner_test_productCreatorId On dbo.test_productOwner(productCreatorId)
/* Insert data */
Declare @i int = 1, @j int = 1
Declare @newIdi uniqueidentifier, @newIdj uniqueidentifier
While @i < 100
Begin
set @newIdi = newid()
Insert Into dbo.test_productCreator values (@newIdi, 'ABC'+convert(varchar(10),@i), getdate(),getdate())
while @j <= 2300
Begin
set @newIdj = newId()
Insert Into dbo.test_productInfo values (@newIdj, 'ProductName'+convert(varchar(10),@i)+convert(varchar(10),@j), 'Region1',getdate(),getdate(),'completed', 1, @i,newId()
,'Address1'+convert(varchar(10),@i)+convert(varchar(10),@j), 'Address2'+convert(varchar(10),@i)+convert(varchar(10),@j), 'los angeles','ca','USA','22231','26.45','33.23')
insert into dbo.test_productOwner values (@newIdj, @newIdi, getdate(), getdate())
set @j = @j + 1
End
set @i = @i + 1
set @j = 1
End
**CURRENT Query:**
set statistics io on
Declare @sort varchar(100) = 'PRODMODIFIED'
Declare @PageNumber int = 1, @PageSize int = 1000
Declare @prodCreator Table(productCreatorId Uniqueidentifier)
insert into @prodCreator
select top 10 productCreatorId
from dbo.test_productCreator
Select p_pi.*
from test_productInfo p_pi
join test_productowner p_po
on p_pi.productId = p_po.productId
join @prodcreator p_pc
on p_po.productCreatorId = p_pc.productCreatorId
order by case when @sort = 'PRODMODIFIED' then p_pi.productUpdatedDt
when @sort = 'PRODCREATED' then p_pi.productCreatedDt
when @sort = 'PRODNAME' then p_pi.productName
end
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
**MODIFIED Query:**
create nonclustered index idx_non_productInfo on dbo.productInfo(productId) include(productUpdatedDt, productCreatedDt, productName)
set statistics io on
Declare @sort varchar(100) = 'PRODMODIFIED'
Declare @PageNumber int = 1, @PageSize int = 1000
Declare @prodCreator Table(productCreatorId Uniqueidentifier)
Create Table #tmpProduct (productId uniqueidentifier)
insert into @prodCreator
select top 10 productCreatorId
from dbo.test_productCreator
Insert Into #tmpProduct
Select p_pi.productId
from test_productInfo p_pi
join test_productowner p_po
on p_pi.productId = p_po.productId
join @prodcreator p_pc
on p_po.productCreatorId = p_pc.productCreatorId
order by case when @sort = 'PRODMODIFIED' then p_pi.productUpdatedDt
when @sort = 'PRODCREATED' then p_pi.productCreatedDt
when @sort = 'PRODNAME' then p_pi.productName
end
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
Select p_pi.*
from #tmpProduct tmp_pi
join test_productInfo p_pi
on tmp_pi.productId = p_pi.productId
join test_productowner p_po
on p_pi.productId = p_po.productId
join @prodcreator p_pc
on p_po.productCreatorId = p_pc.productCreatorId
order by case when @sort = 'PRODMODIFIED' then p_pi.productUpdatedDt
when @sort = 'PRODCREATED' then p_pi.productCreatedDt
when @sort = 'PRODNAME' then p_pi.productName
end
If object_id('tempdb..#tmpProduct') is not null
begin
drop table #tmpProduct
end
1 Answer 1
The sort spills primarily because table variables do not support statistics and default to a cardinality estimate of one row. You can work around the cardinality issue on SQL Server 2012 with a recompile hint or trace flag 2453, but you still won't get statistics, which are important for any operation that depends on data distribution (like joins and grouping).
There are any number of ways to improve your query, including using dynamic SQL, but for the relatively small tables involved, I probably wouldn't bother writing that much code. The solution below copies rows from your table variable to a temporary table, which does support statistics:
DECLARE @ProdCreator table (productCreatorId uniqueidentifier PRIMARY KEY);
INSERT @ProdCreator
(productCreatorId)
SELECT TOP (10)
TPC.productCreatorId
FROM dbo.test_productCreator AS TPC;
CREATE TABLE #ProdCreator
(
productCreatorId uniqueidentifier PRIMARY KEY
);
INSERT #ProdCreator
(productCreatorId)
SELECT
PC.productCreatorId
FROM @ProdCreator AS PC;
DECLARE
@Sort varchar(100) = 'PRODMODIFIED',
@PageNumber integer = 1,
@PageSize integer = 1000;
-- This query now benefits from automatic statistics
-- on the #ProdCreator table
SELECT TPI.*
FROM
(
SELECT
TPI.productId,
rn = ROW_NUMBER() OVER (
ORDER BY
CASE @Sort
WHEN 'PRODMODIFIED'
THEN CONVERT(sql_variant, TPI.productUpdatedDt)
WHEN 'PRODCREATED'
THEN CONVERT(sql_variant, TPI.productCreatedDt)
WHEN 'PRODNAME'
THEN CONVERT(sql_variant, TPI.productName)
END)
FROM dbo.test_productInfo AS TPI
WHERE EXISTS
(
SELECT *
FROM #ProdCreator AS PC
JOIN dbo.test_productOwner AS TPO
ON TPO.productCreatorId = PC.productCreatorId
WHERE
TPO.productId = TPI.productId
)
ORDER BY rn
OFFSET (@PageNumber - 1) * @PageSize ROWS
FETCH FIRST @PageSize ROWS ONLY
) AS ThePage
JOIN dbo.test_productInfo AS TPI
ON TPI.productId = ThePage.productId
ORDER BY
ThePage.rn
OPTION (RECOMPILE, MAXDOP 4);
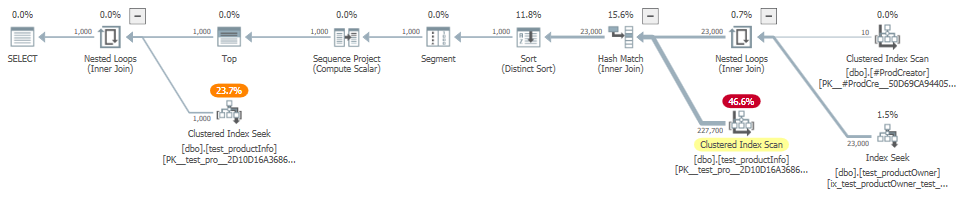
Example plan:
{kind=link}
It avoids the conversion error that prevented your originals from working with a PRODNAME sort order by converting to sql_variant. The recompile hint enables the parameter embedding optimization, which minimizes the impact of the case expression by evaluating it once before execution begins.
The MAXDOP hint is not required, but it's something you might want to consider if you naturally get a parallel plan and don't have your maximum degree of parallelism set. Parallelism has an extra benefit in this plan as it allows early semi-join reduction via a hash build bitmap.
The extra join to the info table is to only fetch all the columns for the single page of rows. It avoids sorting the extra columns for rows that are not ultimately needed. It may or may not add a tremendous amount of value; omit it if you prefer. The index proposed in the question would make the initial join a little more efficient, but for a table of this size it may not be worth it. That's really a decision for you to make.
This query does have an 'excessive' memory grant due to the sql_variant conversion. If that's important to you in the real application, you'll have to use dynamic SQL. The grant isn't so large in this example that I'd particularly worry about it.
Dynamic SQL example for comparison (still uses the temporary table):
DECLARE
@Sort varchar(100) = 'PRODMODIFIED',
@PageNumber integer = 1,
@PageSize integer = 1000,
@SQL nvarchar(max);
SET @SQL =
REPLACE
(
N'
SELECT TPI.*
FROM
(
SELECT
TPI.productId,
rn = ROW_NUMBER() OVER (ORDER BY ##OrderBy##)
FROM dbo.test_productInfo AS TPI
WHERE EXISTS
(
SELECT *
FROM #ProdCreator AS PC
JOIN dbo.test_productOwner AS TPO
ON TPO.productCreatorId = PC.productCreatorId
WHERE
TPO.productId = TPI.productId
)
ORDER BY rn
OFFSET (@PageNumber - 1) * @PageSize ROWS
FETCH FIRST @PageSize ROWS ONLY
) AS ThePage
JOIN dbo.test_productInfo AS TPI
ON TPI.productId = ThePage.productId
ORDER BY
ThePage.rn
OPTION (MAXDOP 4);
',
N'##OrderBy##',
CASE @Sort
WHEN 'PRODMODIFIED' THEN N'TPI.productUpdatedDt'
WHEN 'PRODCREATED' THEN N'TPI.productCreatedDt'
WHEN 'PRODNAME' THEN N'TPI.productName'
END
);
EXECUTE sys.sp_executesql
@SQL,
N'@PageNumber integer, @PageSize integer',
@PageNumber = @PageNumber,
@PageSize = @PageSize;
{kind=link}
The dynamic version completes in around 80ms on my machine. The non-dynamic version runs in about 40ms but uses more memory and parallelism.
Explore related questions
See similar questions with these tags.