I faced unusual behavior associated with automatic failover so that automatic failover does not work in the case of turning off SQL Server service. It seems that clustered disks are still remaining attached to the failed node, but I cannot find out the final issue that causes this behavior. I will be very thankful to you if you can help me understand this issue.
For testing purposes, I have created iSCSI target on Domain Controller with 2 initiators connected to it:
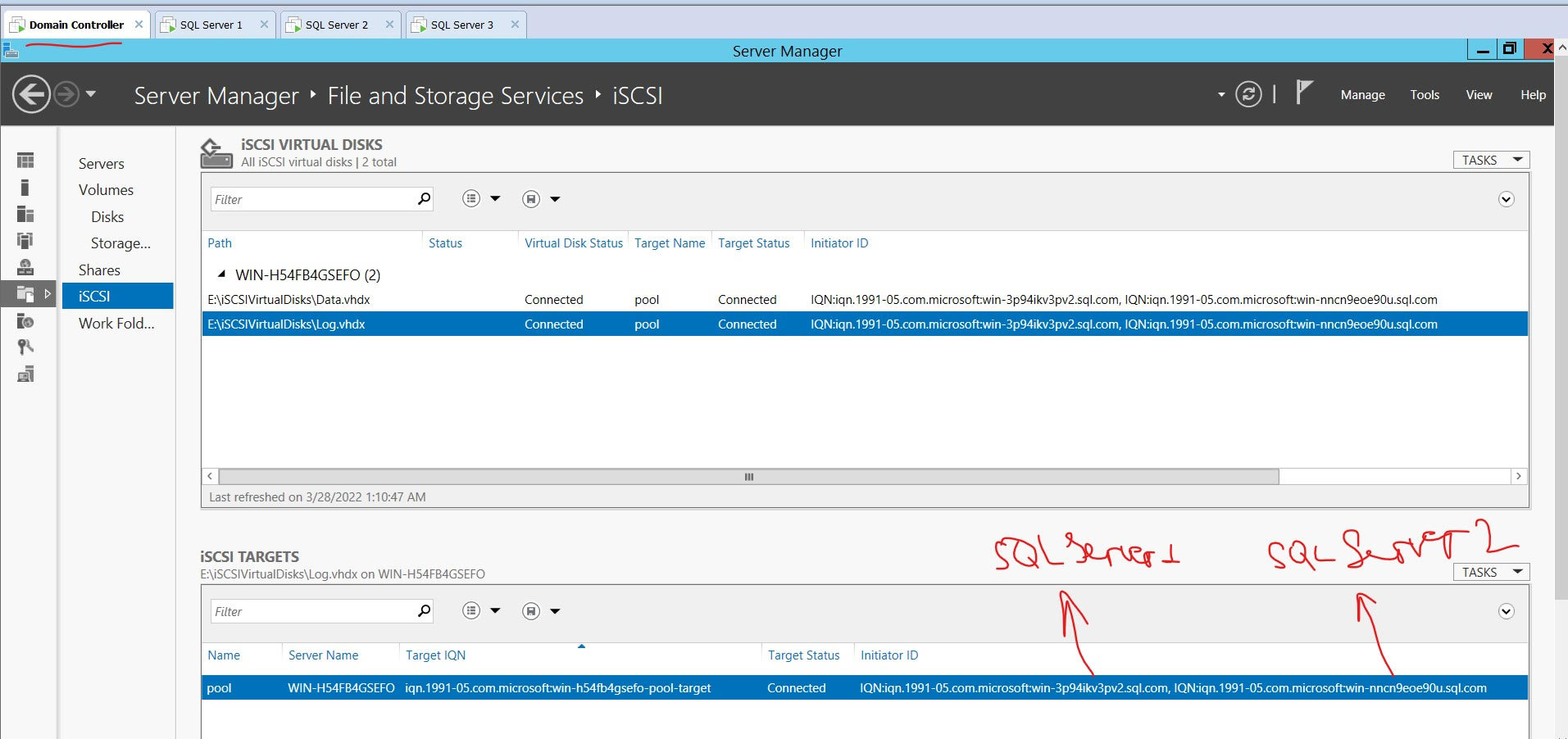{kind=link}
Here are details about my cluster:
enter image description here enter image description here enter image description here
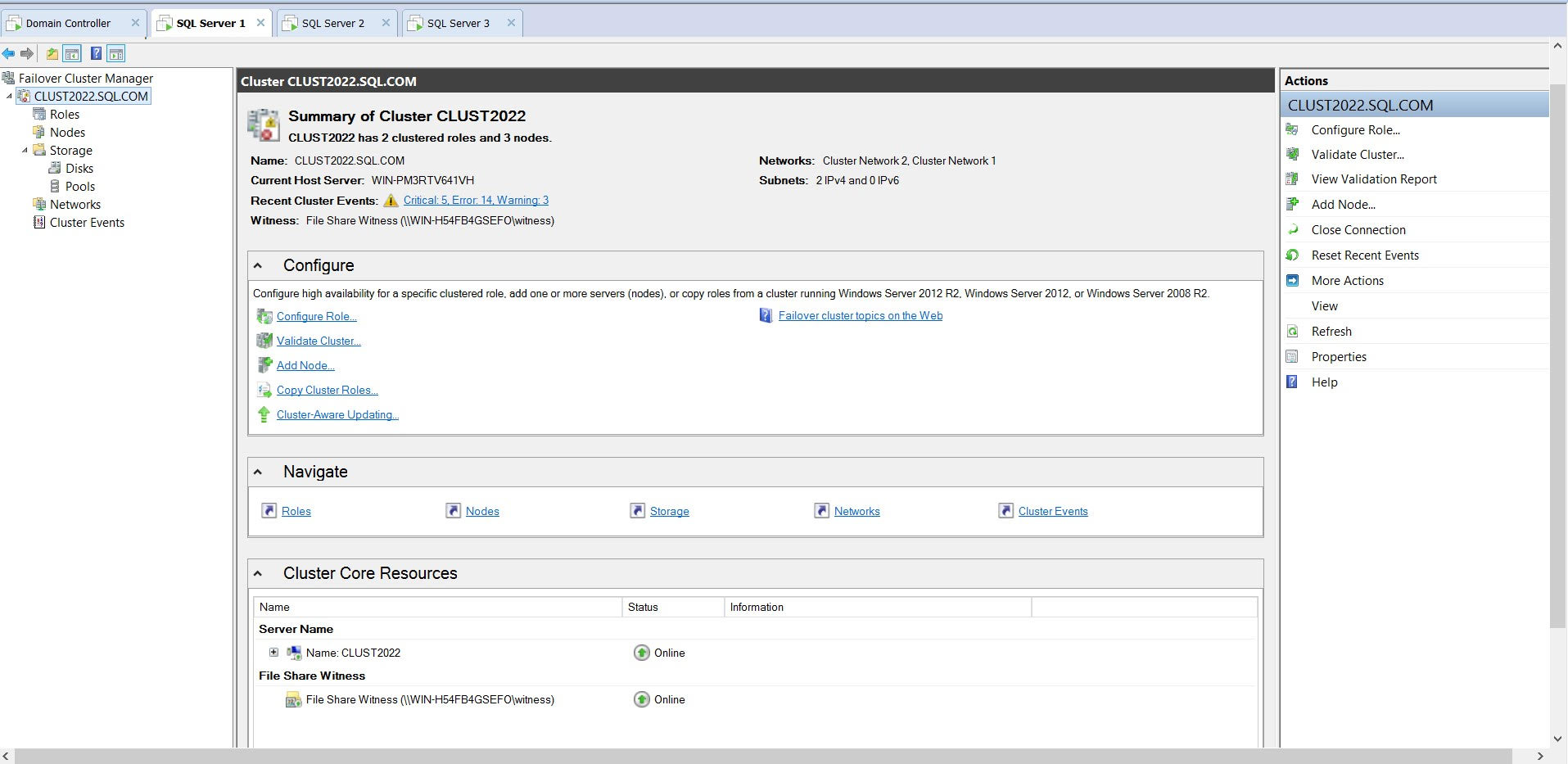{kind=link}
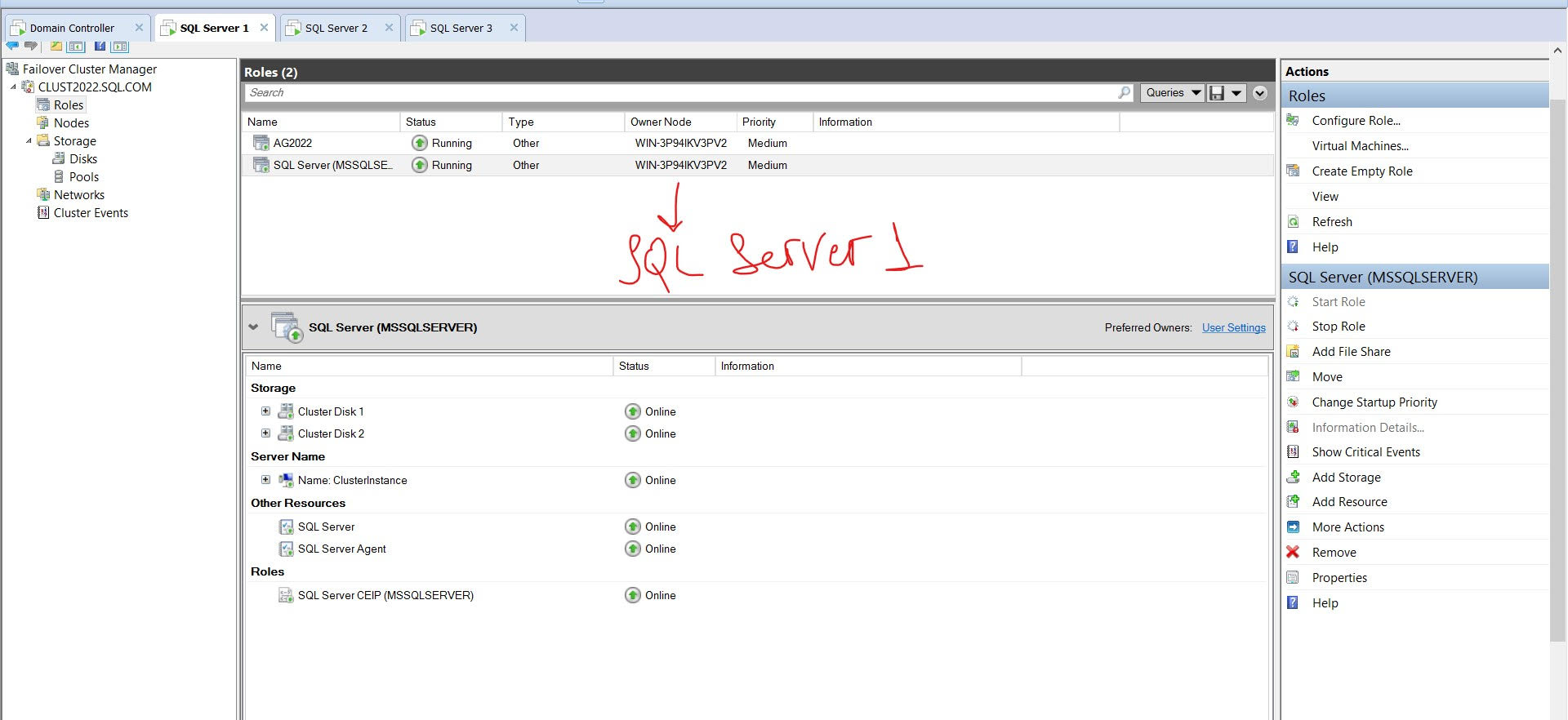{kind=link}
{kind=link}
Here are details about my SQL Server service:
enter image description here enter image description here enter image description here
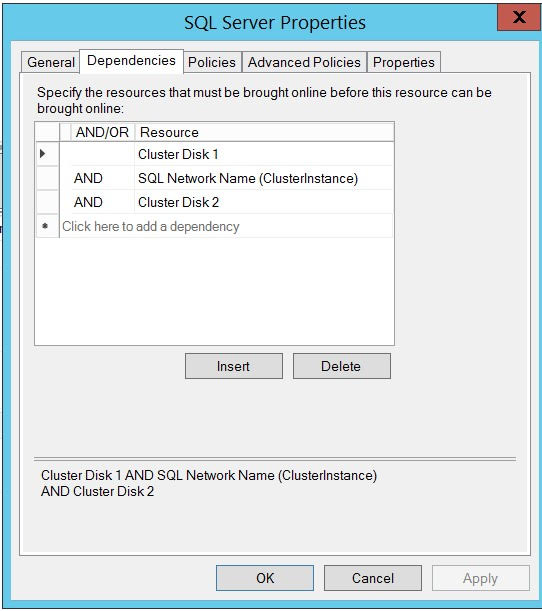{kind=link}
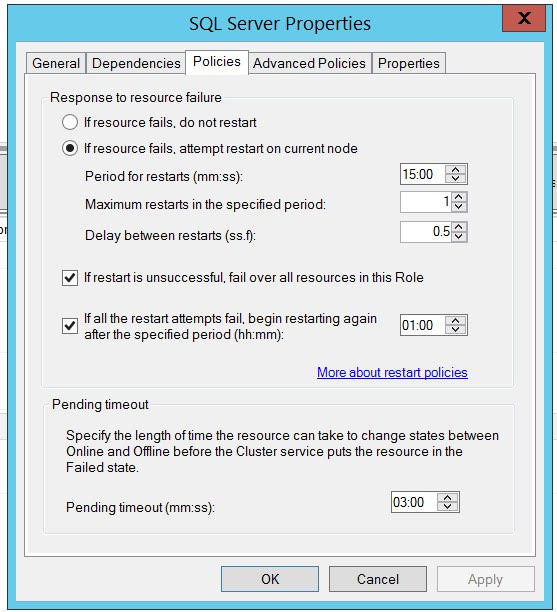{kind=link}
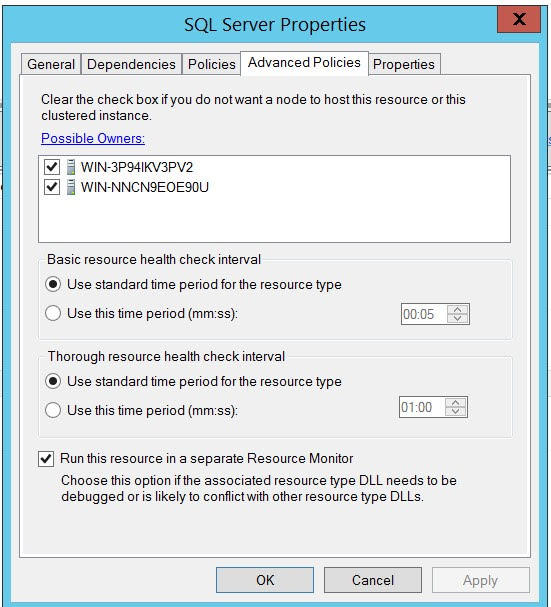{kind=link}
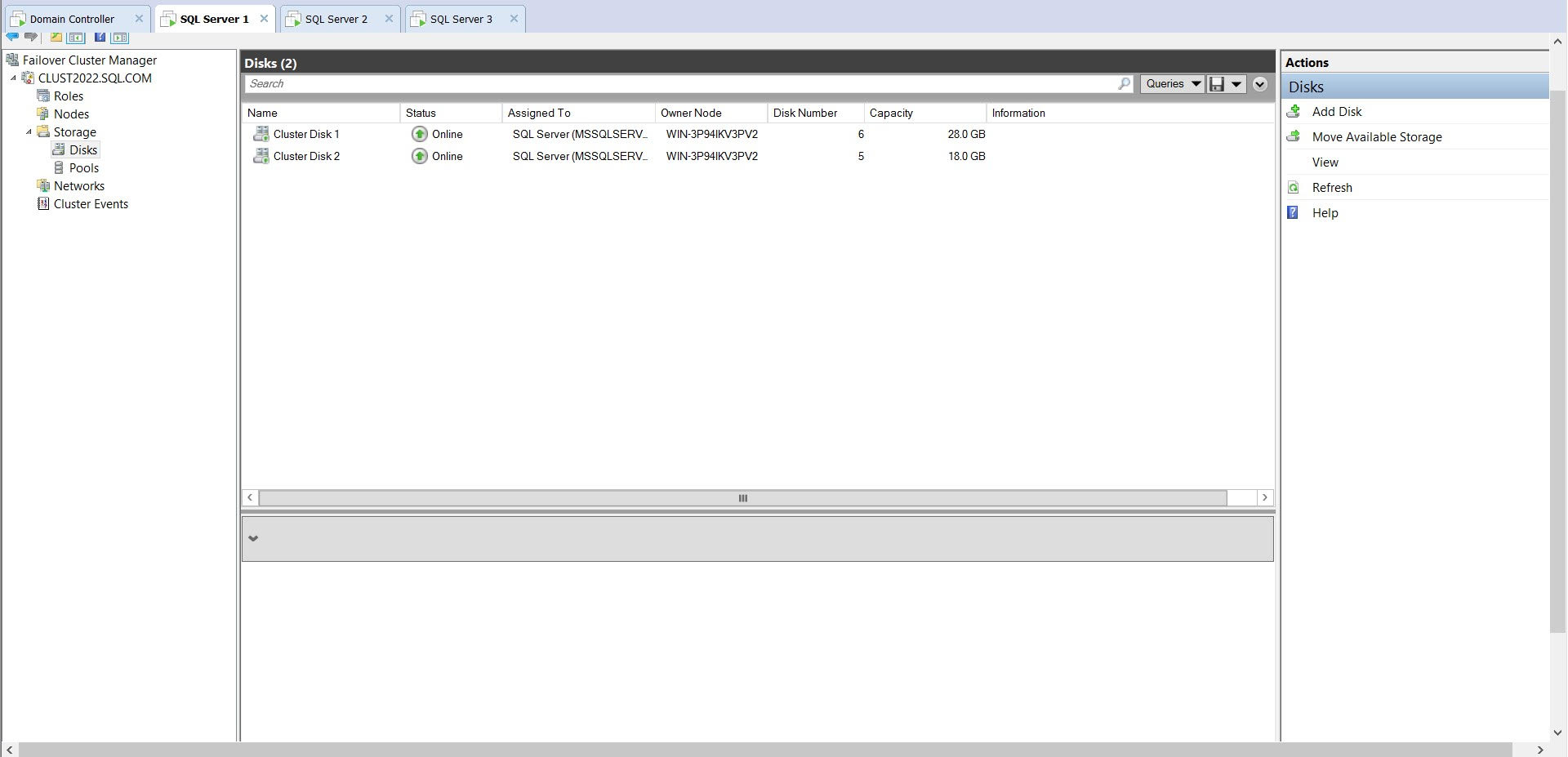
Here are details about clustered disks (I have only added details for one of the disk because two disks are identical):
enter image description here enter image description here
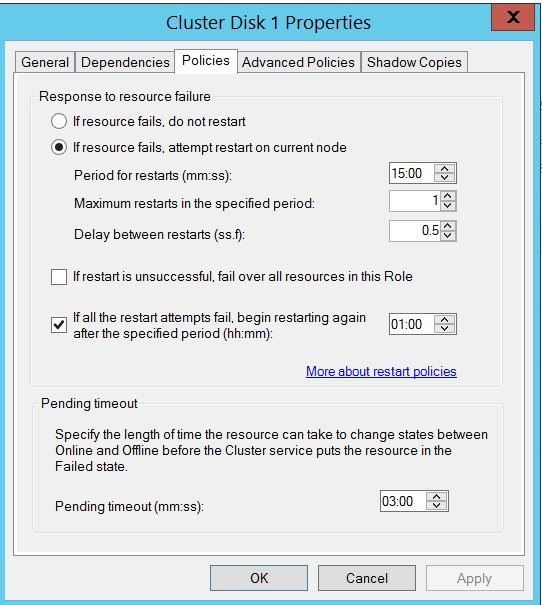{kind=link}
{kind=link}
Now, when I turn off SQL Server service, automatic failover of services does not occur:
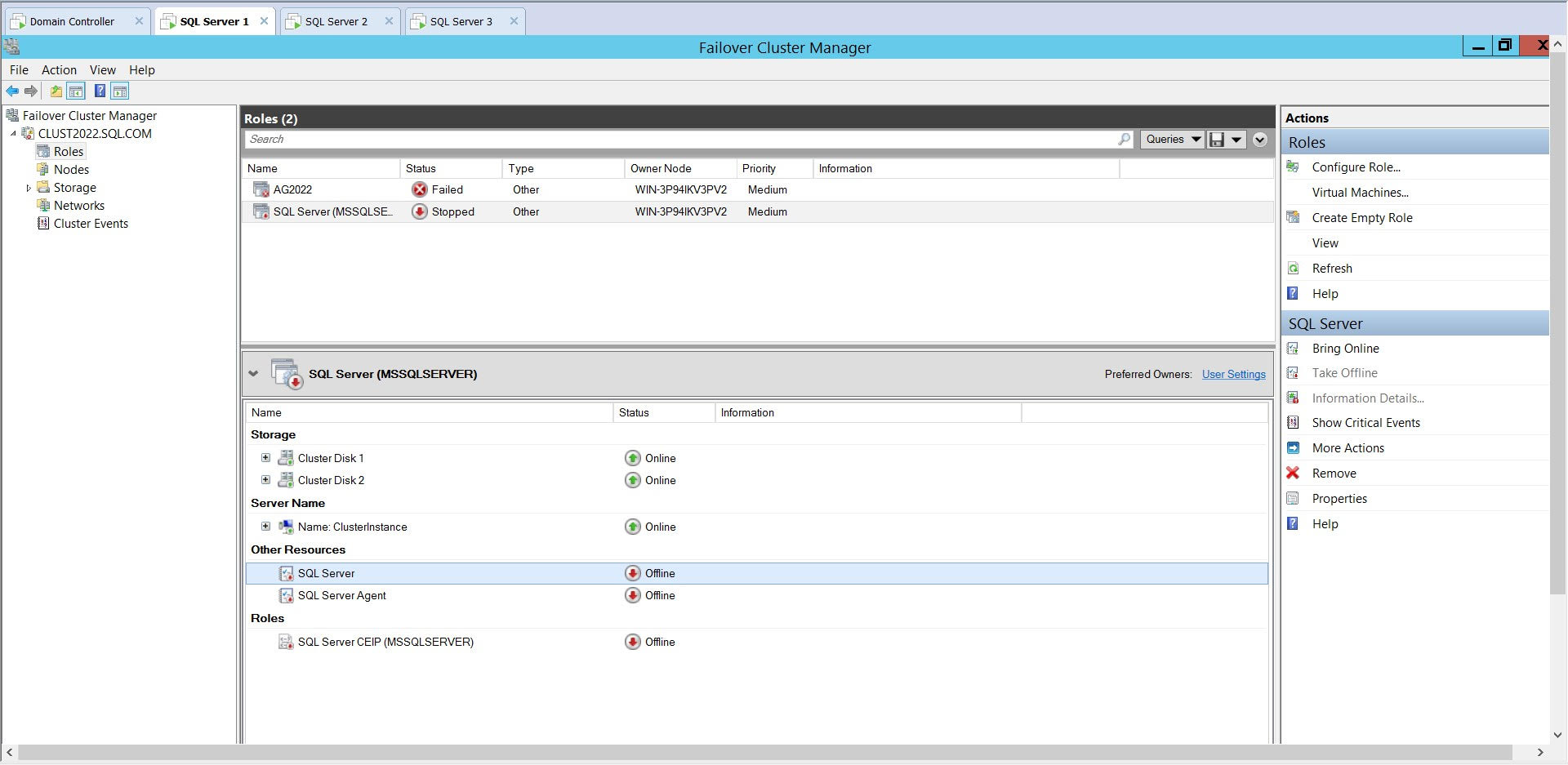{kind=link}
I tested other scenarios where automatic failover successfully works:
- Manual failover
- Shutting down active node
- Disabling adapter on active node
- killing sql server process in task manager
- killing sql agent service process in task manager
In all above scenarios, resources successfully failed over to another node.
Could you please help me to figure out what is going wrong with automatic failover when I shutdown SQL Server service on active node?
1 Answer 1
The Failover Cluster Manager is THE tool for managing the services protected by the cluster, so I believe it's not supposed to fail over the service if the administrator chose to stop the service using it. That situation might be interpreted as some maintenance that requires the service to be stopped.
The 5 scenarios you described as working are outside of the Cluster Manager (except the one option that explicitly fails over the service), so they represent situations where the service was stopped without the knowledge of the admin (if it was the admin, he would have used the Failover Cluster Manager, right?) and the cluster acknowledges the situation as hazardous and acts as supposed to in order to reestablish the service.
Explore related questions
See similar questions with these tags.