I have a very slow running query, and I've isolated the problem down to the following SQL.
SELECT
...
FROM
TableA a(nolock)
inner join TableB b with(nolock) on (b.Id = a.Id AND b.Date>= isnull(@timestamp_start, '17530101') AND b.Date < isnull(@timestamp_end, '99991231'))
- a = 2million+ rows
b = 2million+ rows
b.Id => Index, unique, non-clustered
- a.Id => Index, unique, non-clustered
- b.Date => Index, non-unique, non-clustered
This takes several minutes without returning a result even for a single day date range.
UPDATE:
The estimated execution plan on the production server is showing me this, which shows that a complete scan of a huge table (TableA) is occurring near the beginning of the query, rather than the TableB.date range being used to filter in the WHERE. Why is this happening and how can I force the query to filter first on my date range?
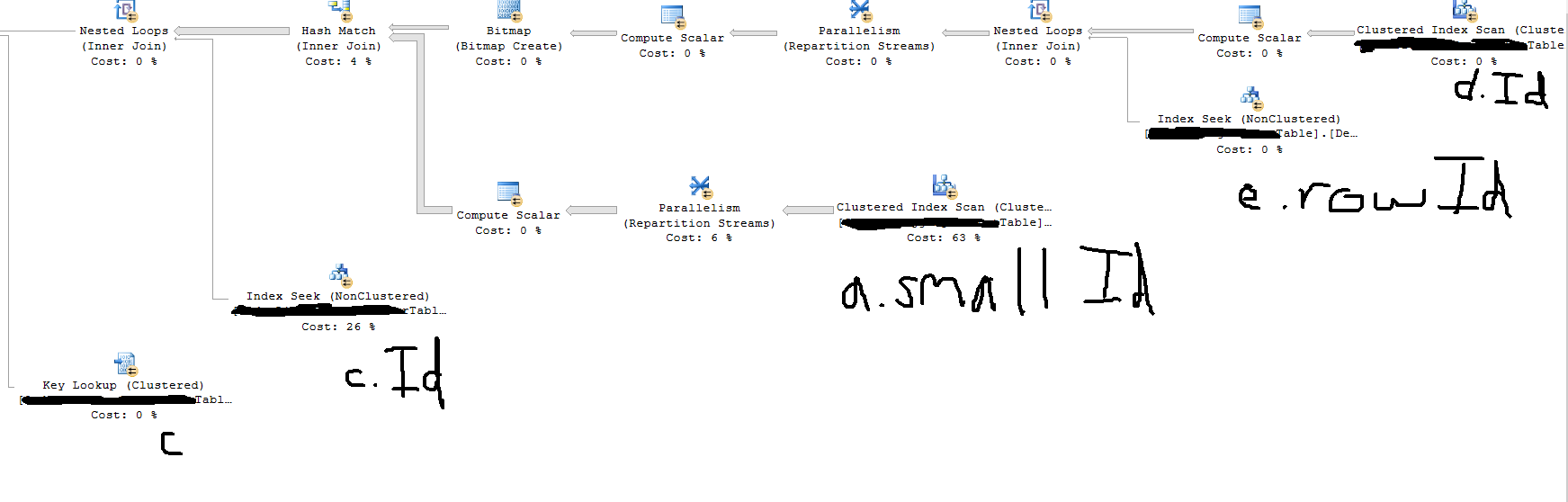{kind=link}
The plan relates to this query, which in detail is:
SELECT
...
FROM
TableA a(nolock)
inner join TableB b with(nolock) on (b.Id = a.Id AND b.Date>= isnull(@timestamp_start, '17530101') AND b.Date < isnull(@timestamp_end, '99991231'))
inner join TableC c with(nolock) on c.Id2 = s.Id2 and c.Id3 = a.Id3 and c.Id = b.Id
inner join TableD d with(nolock) on (a.DealId = d.Id and d.Id3 = s.Id3 AND (@myparam is null OR d.ProviderName = @myparam))
inner join TableE e with(nolock) on (e.Id = d.Id AND (@myparam2 is null OR e.Id = @myparam2))
2 Answers 2
You should look at the actual plan, not to the estimated one that you posted here.
Your plan uses NL with lookups in the clustered index + sorts, so it's clear the server estimated small number of rows for your filters. When you look at the actual plan and instead of 100-1000 rows see there 500.000 rows go out from your first index seek, there is a problem. It means that full scan should be used, and hash join instead of merge.
So update your post with the actual plan please
-
1Let us continue this discussion in chat.Chris Halcrow– Chris Halcrow2017年08月03日 06:11:19 +00:00Commented Aug 3, 2017 at 6:11
OK, I found out that for a complex query like this, since SQL server will cache the last execution plan, a later query can end up being poorly optimised.
I'd previously run the query using one of the parameters, and the execution plan was optimizing for that scenario on subsequent queries. By adding the following to the end of the query, SQL server is forced to recompile an execution plan for the query, and this fixes the performance:
OPTION (RECOMPILE)
-
1Another approach to address varying search conditions is dynamic SQL. See sommarskog.se/dyn-search.html.Dan Guzman– Dan Guzman2017年08月03日 11:01:25 +00:00Commented Aug 3, 2017 at 11:01
Explore related questions
See similar questions with these tags.