I have such TABLE with data:
A | B | C | D | E
-----------------------
a1 | b1 | c1 | d1 | PA
a1 | b1 | c1 | d1 | PR
a2 | b2 | c2 | d2 | PA
a3 | b3 | c3 | d3 | PA
a3 | b3 | c3 | d3 | PR
- row1 has its counterpart row2 (they are only different by col E)
- row3 has no counterpart - unique
- row4 has its counterpart row5 ( same as first statement - col E )
the query should gave me a result like this:
A | B | C | D | E
-----------------------
a2 | b2 | c2 | d2 | PA
only unique row which has no counterpart - no row with same set of data only which different only by value in column E
- we can apply here a few approaches which one will be most effective if we have more rows with its counterparts as unique rows (without counterpart)
- which join use ?
- which one created select statement subtract or add ?
ps. an extended case
A | B | C | D | E
----------------------------------------
a1 | b1 | c1 | 2017年05月16日 11:46:36 | PA
a1 | b1 | c1 | 2017年05月16日 11:46:37 | PR
a2 | b2 | c2 | 2017年05月17日 01:34:28 | PA
a3 | null | c3 | 2017年05月12日 19:14:15 | PA
a3 | b3 | c3 | 2017年05月12日 19:14:15 | PR
a4 | b4 | c4 | 2017年05月12日 19:16:15 | PA
a4 | b4 | c4 | 2017年05月12日 23:16:15 | PR
- column A -D may contain null values (row4)
- column D is a TIMESTAMP and it could vary from its counterpart by 1-2minutes (row1, row2)
- we add the max difference in timestamp = example 2 minutes (row6 has no counterpart as row7 vs row6 timestamp difference is greeter than 2 minuts (4 hours)
- we don't want any row with PR in our result
expected result:
A | B | C | D | E
----------------------------------------
a2 | b2 | c2 | 2017年05月17日 01:34:28 | PA
a4 | b4 | c4 | 2017年05月12日 19:16:15 | PA
-
In your extended case, which is the intended result? Rows 4 and 5 where considered "equivalent, and non-reported" in your original scenario. What should happen now? Which time-threshold to use to consider that two times are equivalent or not?joanolo– joanolo2017年05月21日 17:15:22 +00:00Commented May 21, 2017 at 17:15
-
@joanolo see editceph3us– ceph3us2017年05月21日 17:32:30 +00:00Commented May 21, 2017 at 17:32
-
See edit on response.joanolo– joanolo2017年05月21日 18:21:23 +00:00Commented May 21, 2017 at 18:21
2 Answers 2
I wouldn't use a JOIN. If you would like to look for rows that have a set of columns in common (in your case, all but one), I would just GROUP the rows by the common columns. Then, restrict which groups you want to return (using a HAVING clause):
SELECT
A, B, C, D, min(E) AS E
FROM
t
GROUP BY
A, B, C, D
HAVING
count(*) = 1 ;
The min(E) part is just a trick to be "SQL compliant". max(E), or first(E) (for the databases that have it) would do the job as well. As you're choosing just groups with a single row, the min value of a column within the group is the single value there is. In mySQL 5.6 and earlier, leaving E as a column would work as well; although this is not SQL standard and doesn't work in 5.7 (thanks to
ypercubeTM for pointing the fact that this doesn't work on 5.7).
| A | B | C | D | E |
|----|----|----|----|----|
| a2 | b2 | c2 | d2 | PA |
You can get everything at this SQL Fiddle
You can also take a different approach. Look for rows that literally comply with what you're looking for: that is, it does NOT exist another row with the same A, B, C and D and different E. In this case, use an EXISTS condition in your WHERE clause:
SELECT
A, B, C, D, E
FROM
t AS t0
WHERE
NOT EXISTS
(SELECT
*
FROM
t AS t1
WHERE
t1.A = t0.A
AND t1.B = t0.B
AND t1.C = t0.C
AND t1.D = t0.D
AND t1.E <> t0.E
) ;
Older versions of MySQL would probably not handle this query too well, because EXISTS conditions are not well optimized. mySQL 5.7 does a decent job; and so do most other databases (Oracle, MS SQL Server, PostgreSQL, ...) . You do need an index on (A, B, C, D, E) (or, at least, (A, B, C, D) to be really performant.
The two queries will not work the same in the case where you have two exact duplicate rows (which I interpret is a case not allowed by your spec). The first one will return no rows, whereas the second one will return both rows.
MySQL 5.6 Schema Setup:
CREATE TABLE t
(
`A` varchar(2),
`B` varchar(2),
`C` varchar(2),
`D` varchar(2),
`E` varchar(2)
) ;
INSERT INTO t
(`A`, `B`, `C`, `D`, `E`)
VALUES
('a1', 'b1', 'c1', 'd1', 'PA'),
('a1', 'b1', 'c1', 'd1', 'PR'),
('a2', 'b2', 'c2', 'd2', 'PA'),
('a3', 'b3', 'c3', 'd3', 'PA'),
('a3', 'b3', 'c3', 'd3', 'PR');
For your extended case, the second query is your starting point.
Change your equalities with whichever conditions meet your needs.
For instance, if your D columns is a timestamp, and you want to consider that "two times are equivalent if the difference is less than 2 minutes"... then change
t1.D = t0.D
by
abs( unix_timestamp(t1.D) - unix_timestamp(t0.D) ) < 120 -- seconds
The possibility of nulls (that work as "jokers") should be handled with:
(t1.A = t0.A or t0.A is null or t1.A is null)
If E is nullable, then the comparison is done with
NOT (t1.E <=> t0.E)
which is mySQL equivalent of (t1.E is distinct from t0.E)
This will give you:
SELECT
A, B, C, D, E
FROM
t AS t0
WHERE
NOT EXISTS
(SELECT
*
FROM
t AS t1
WHERE
(t1.A = t0.A or t1.A is NULL or t0.A is NULL)
AND (t1.B = t0.B or t1.B is NULL or t0.B is NULL)
AND (t1.C = t0.C or t1.C is NULL or t0.C is NULL)
AND (abs( unix_timestamp(t1.D) - unix_timestamp(t0.D) ) < 120)
AND NOT (t1.E <=> t0.E)
)
AND t0.E <> 'PR' ;
A | B | C | D | E :- | :- | :- | :------------------ | :- a2 | b2 | c2 | 2017年05月17日 01:34:28 | PA a4 | b4 | c4 | 2017年05月12日 19:16:15 | PA
dbfiddle here
Don't expect this kind of queries to be efficient in realistic scenarios.
-
"In the current implementations of mySQL, leaving E as a column would work as well" No, it wouldn't in 5.7 (latest stable version)ypercubeᵀᴹ– ypercubeᵀᴹ2017年05月21日 16:48:24 +00:00Commented May 21, 2017 at 16:48
-
-
and what about shivam-kumar he ads count on e column and check on this column ? in your example we are checking on all columns countceph3us– ceph3us2017年05月21日 16:54:09 +00:00Commented May 21, 2017 at 16:54
-
@ceph3us
count(*)andcount(e)andcount(a)and ... are all equivalent when the columns are not nullable.ypercubeᵀᴹ– ypercubeᵀᴹ2017年05月21日 16:56:13 +00:00Commented May 21, 2017 at 16:56 -
second question if i have a column with timestamp and its counterpart can vary by 1 minute how can I handle this ?ceph3us– ceph3us2017年05月21日 16:56:29 +00:00Commented May 21, 2017 at 16:56
Here is my test table:
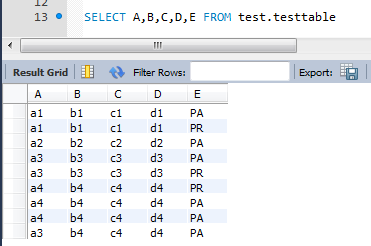{kind=link}
I will give this a try:
SELECT A,B,C,D,E,count(E) as dup
FROM TEST.TESTTABLE
GROUP BY A,B,C,D
HAVING count(E) = 1;
Here is the result I got:
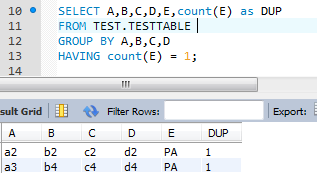{kind=link}
You can remove the Dup column added for demo purpose and use the below query instead:
SELECT A,B,C,D,E
FROM TEST.TESTTABLE
GROUP BY A,B,C,D
HAVING count(E) = 1;