The following query is taking 5 seconds to return 9692 rows:
SELECT
Project.CalculateSequencialProject,
Project.CreateDate,
Project.OpeningDate,
Project.ForecastClosingDate,
Project.RealClosingDate,
Project.ProjectStatus,
Unit.Name AS UnitName,
UTE.Name AS UTEName,
Process.Name AS Process
FROM
Project
LEFT JOIN Unit ON Project.Unit_Id = Unit.Id AND Project.Company_Id = Unit.Company_Id
LEFT JOIN UTE ON Project.UTE_Id = UTE.Id
LEFT JOIN Process ON Project.Process_Id = Process.Id
WHERE
Project.Company_Id = '????????????????'
The execution plan is like this: ExecutionPlan
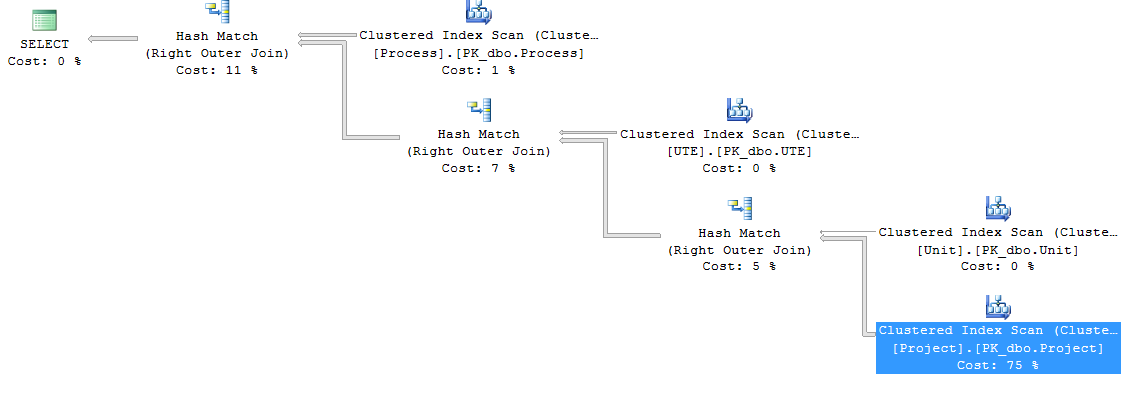{kind=link}
And the most "expensive" part of it is detailed here: Detail
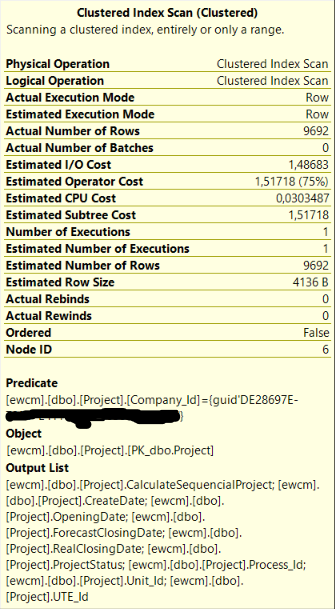{kind=link}
As you may se in the tooltip image, the Clustered Index Scan with 75% of cost is using the table primary key instead of one of the following indexes.
CREATE NONCLUSTERED INDEX [IX_Company_Id] ON [dbo].[Project]
(
[Company_Id] ASC
)
CREATE NONCLUSTERED INDEX [IX_Project_02] ON [dbo].[Project]
(
[ProjectType_Id] ASC,
[ProjectStatus] ASC,
[Unit_Id] ASC,
[Id] ASC,
[ProjectDirector_Id] ASC,
[UTE_Id] ASC,
[Company_Id] ASC,
[LostType_Id] ASC,
[Pillar_Id] ASC,
[ProjectPhase_Id] ASC
)
INCLUDE ( [CalculateSequencialProject],
[DescriptionTittle],
[OpeningDate],
[ForecastClosingDate],
[RealClosingDate])
Why?
asked Oct 7, 2015 at 18:55
1 Answer 1
None of your indexes are good for this query
- IX_Company_Id works only for the WHERE
- IX_Project_02 has not overlap with any part of the query because the leading columns do not match a JOIN or WHERE
This should be better because it matches the JOIN and the WHERE although iIt does rely on a matching (Company_Id, Unit_Id) index on Unit
CREATE NONCLUSTERED INDEX [IX_Project_02] ON [dbo].[Project]
(
[Company_Id] , --can swap these 2 to see what happens if no index on Unit
[Unit_Id] ,
[UTE_Id] ,
ProcessID
)
INCLUDE
CalculateSequencialProject,
CreateDate,
OpeningDate,
ForecastClosingDate,
RealClosingDate,
ProjectStatus
answered Oct 7, 2015 at 21:28
-
If I drop all my indexes and create a new one like the one you suggested, and I have another query in my application that doesn't need Company_id, but needs Unit_Id, will it use this index?juliano.net– juliano.net2015年10月08日 16:49:05 +00:00Commented Oct 8, 2015 at 16:49
-
Probably not, but I did not say drop any existing indexes. And any query with Unit_Id won't use the current indexes either for the same reasons I gavegbn– gbn2015年10月08日 19:54:38 +00:00Commented Oct 8, 2015 at 19:54
-
I was saying to drop existing indexes because they seem to be duplicated or even not used at all.juliano.net– juliano.net2015年10月09日 12:13:54 +00:00Commented Oct 9, 2015 at 12:13
lang-sql
[Id]column.