The following code is my lab which focused on implementing any 3 known sorting algorithms out there. Since the professor gave us a choice to pick any of them and compare their execution time I chose Quick Sort, Selection Sort, and Heap Sort. I had the option to choose bogo or bubble sort but I think that's boring and doesn't present a challenge.
I had to measure the execution time for every algorithm and print the size = 10 one, I used the chrono library to measure the execution time of the algorithms. Is there a way to speed some of the algorithms up? Would anyone recommend different design choices?
I know the heap sort could be implemented with STL using std::make_heap() and then use std::sort() but when I thought about it, it felt like it defies the purpose of the lab (own implementation).
I used a random pivot since I read that QS is very slow if the elements are sorted/partially sorted/ or all the same. I was using rand() which made a system call every iteration and really slowed down performance. Would the median of three be better in this case?
Restrictions:
- C++ 11 standard
- Flags:
-Werror -Wall -pedantic - No templates
- Can't use
std::vectororstd::arrayorstd::list... - I had to pass a new, random, non-sorted array (not a copy of the original) into every single algorithm separately
I find the last one stupid, since it offers no "control" over the time measurements, especially for quicksort. The odds of getting a size = 10 sorted array out of 100000 numbers are slim but still there.
Edit: in the merge function I used i, j, and k as my variable names, which could go in the "bad practice" basket...This is due to the lack of MS I was following my professor's flowchart that she made in class. Also I know that C++ prefers to use camelCase for variables over snake_case, I prefer snake_case and I hope that's not an issue.
Perfect timing lol: I got my grade back (92/100), and I got downgraded (-4) for readability of code and I quote "Comments could be better"(-4).
Code:
/**
* @author Jakob Balkovec
* @file lab5.cpp [Driver Code]
* @note Driver code for lab5
*
* @brief This assignment focuses on using sorting algorithms such as:
* - Heap Sort
* - Quick Sort
* - Merge Sort
* @note use of function pointers
*/
#include <iostream>
#include <chrono>
#include <random>
#include <iomanip>
/**
* @brief Maintains the max heap property of a subtree rooted at index 'root'.
* @param arr The array to be sorted.
* @param size The size of the heap/subtree.
* @param root The index of the root of the subtree.
*/
void heapify(int *arr, int size, int root) {
int largest = root; //largest is the root of the heap
int left = 2 * root + 1; // L child
int right = 2 * root + 2; // R child
// if left child is larger than root
if (left < size && arr[left] > arr[largest]) {
largest = left;
}
// if right child is larger than current largest
if (right < size && arr[right] > arr[largest]) {
largest = right;
}
// if largest is not root
if (largest != root) {
std::swap(arr[root], arr[largest]);
heapify(arr, size, largest); //recursive call
}
}
/**
* @brief Performs heap sort on an array.
* @param arr The array to be sorted.
* @param size The size of the array.
*/
void heap_sort(int *arr, int size) {
// build a max heap
for (int i = size / 2 - 1; i >= 0; i--) {
heapify(arr, size, i);
}
// extract elements from heap one by one
for (int i = size - 1; i >= 0; i--) {
// move current root to the end
std::swap(arr[0], arr[i]);
// call max heapify on the reduced heap
heapify(arr, i, 0);
}
}
/**
* @brief Merges two subarrays of arr[]
* @param arr The array to be sorted
* @param p Starting index of the first subarray
* @param q Ending index of the first subarray
* @param r Ending index of the second subarray
*/
void merge(int *arr, int p, int q, int r) {
int n1 = q - p + 1; // size of the first subarray
int n2 = r - q; // size of the second subarray
//temp arrays
int* left_sub = new int[n1];
int* right_sub = new int[n2];
//copy elements
for(int i = 0; i < n1; i++) {
left_sub[i] = arr[p+i];
}
//copy elements
for(int j = 0; j < n2; j++) {
right_sub[j] = arr[q+1+j];
}
int i = 0;
int j = 0;
int k = p;
// merge the elements from the temporary arrays back into arr[] in sorted order
while(i < n1 and j < n2) {
if(left_sub[i] < right_sub[j]) {
arr[k] = left_sub[i];
i++;
} else {
arr[k] = right_sub[j];
j++;
}
k++;
}
//copy elements over if any
while (i < n1) {
arr[k] = left_sub[i];
i++;
k++;
}
//copy elements over if any
while (j < n2) {
arr[k] = right_sub[j];
j++;
k++;
}
delete[] left_sub; //free memory
delete[] right_sub;
}
/**
* @brief Sorts an array using merge sort algorithm
* @param arr The array to be sorted
* @param p Starting index of the array
* @param r Ending index of the array
*/
void merge_sort_helper(int *arr, int p, int r) {
if (p < r) {
int q = (p + r) / 2;
merge_sort_helper(arr, p, q);
merge_sort_helper(arr, q + 1, r);
merge(arr, p, q, r);
}
}
/**
* @brief Sorts an array using merge sort algorithm
* @param arr The array to be sorted
* @param size The size of the array
*/
void merge_sort(int *arr, int size) {
merge_sort_helper(arr, 0, size - 1);
}
/**
* @brief Generates a random pivot index between low and high (inclusive)
* @param low Starting index of the array
* @param high Ending index of the array
* @return Random pivot index
*/
int random_pivot(int low, int high) {
return low + rand() % (high - low + 1);
}
/**
* @brief Partitions the array and returns the partition index
* @param arr The array to be partitioned
* @param low Starting index of the partition
* @param high Ending index of the partition
* @return Partition index
*/
int partition(int* arr, int low, int high) {
int pivotIndex = random_pivot(low, high);
int pivot = arr[pivotIndex];
std::swap(arr[pivotIndex], arr[high]);
int i = low - 1; // Index of the smaller element
for (int j = low; j <= high - 1; j++) {
// If current element is smaller than or equal to the pivot
if (arr[j] <= pivot) {
i++; // Increment index of smaller element
std::swap(arr[i], arr[j]); // Swap current element with the smaller element
}
}
std::swap(arr[i + 1], arr[high]); // Swap the pivot with the element at the partition index
return i + 1; // Return the partition index
}
/**
* @brief Sorts an array using the QuickSort algorithm
* @param arr The array to be sorted
* @param low Starting index of the array
* @param high Ending index of the array
*/
void quick_sort_helper(int* arr, int low, int high) {
if (low < high) {
int partition_index = partition(arr, low, high); // partition the array and get the partition index
quick_sort_helper(arr, low, partition_index - 1); // recursively sort the left subarray
quick_sort_helper(arr, partition_index + 1, high); // recursively sort the right subarray
}
}
/**
* @brief Sorts an array using the QuickSort algorithm
* @param arr The array to be sorted
* @param size The size of the array
*/
void quick_sort(int* arr, int size) {
quick_sort_helper(arr, 0, size - 1);
}
/**
* @brief
* @param arr
*/
void print_arr(int *arr, int size) {
std::cout << "[";
for(int i = 0; i < size; i++) {
if(i == size-1) {
std::cout << arr[i]; //drop comma if last element
} else {
std::cout << arr[i] << ", ";
}
}
std::cout << "]" << std::endl;
}
/**
* @brief Checks if the array is sorted by going through every element in the array
* @param arr Array of integers
* @param size Size of the Array
* @return Boolean, True if it's sorted and False if not
*/
bool sorted(int *arr, int size) {
for (int i = 1; i < size; i++) {
if (arr[i] < arr[i - 1]) {
return false;
}
}
return true;
}
/**
* @brief Measures the execution time of a sorting algorithm on arrays of different sizes.
* @param sorting_function The sorting function to be measured.
*/
void measure_sort(void (*sorting_function)(int*, int)) {
int sizes[] = {10, 100, 1000, 10000, 100000}; // sizes of the array
int const MAX = 100000;
int const SMALL = 10;
std::random_device rd; // a seed source for the random number engine
std::mt19937 gen(rd()); // mersenne_twister_engine seeded with rd()
std::uniform_int_distribution<> distrib(1, MAX);
for (auto i = 0; i < 5; i++) {
int* arr = new int[sizes[i]];
for(auto j = 0; j < sizes[i]; j++) { //fill array with random numbers
arr[j] = distrib(gen);
}
if (sizes[i] == SMALL) { //print og array before sorting
std::cout << "\n[Original]: "; // << std::setw(2);
print_arr(arr, sizes[i]);
}
//{
/**
* @note Measure execution time
* @typedef std::chrono::high_resolution_clock::time_point as clock for better readability
* @typedef std::chrono::microseconds as ms for better readability
*/
//}
typedef std::chrono::high_resolution_clock::time_point clock;
typedef std::chrono::microseconds ms;
clock start = std::chrono::high_resolution_clock::now();
sorting_function(arr, sizes[i]);
clock end = std::chrono::high_resolution_clock::now();
ms duration = std::chrono::duration_cast<ms>(end - start);
long long durationCount = duration.count();
if(sizes[i] == SMALL) {
std::string const SPACE = " "; //width const to align output
std::cout << std::setw(4) << "[Sorted]:" << SPACE;
print_arr(arr, sizes[i]);
std::cout << std::endl << std::endl;
}
int const SIZE_W = 9;
int const TIME_W = 8;
int const W = 6;
std::cout << std::left << std::setw(SIZE_W) << "[size]: " << std::setw(W+1) << sizes[i] << std::left <<std::setw(TIME_W) << "[time]: " << std::setw(W) << durationCount << " [ms]" << std::endl;
// Clean up dynamically allocated memory
delete[] arr;
}
}
/**
* @brief Brains of the program, handles the logic
* @return void-type
*/
void run() {
/** @note srand seed */
std::cout << std::endl;
std::cout << "Measuring Sorting Algorithms" << std::endl;
std::cout << "\n[***** [Merge Sort] *****]" << std::endl;
measure_sort(merge_sort);
std::cout << "\n[***** [Quick Sort] *****]" << std::endl;
measure_sort(quick_sort);
std::cout << "\n[***** [Heap Sort] *****]" << std::endl;
measure_sort(heap_sort);
std::cout << std::endl;
}
/**
* @brief Main function of the program, calls run()
* @return EXIT_SUCCESS upon successful execution
*/
int main() {
std::srand(static_cast<unsigned int>(std::time(nullptr)));
run();
return EXIT_SUCCESS;
}
Please excuse some typos and spelling errors, English is not my first language and I'm really trying my best. Oh, and also, I am aware that the typedef statements are sort of useless especially when you give them a name like ms, in my mind it seemed right and I thought it improved readability.
-
1\$\begingroup\$ Are you sure you are comparing apples-to-apples when you input different arrays to each function to measure them? I would generate 1 array (or the same array N times) and sort it with every algorithm. Like you said some algorithms are good with certain datasets, others excel in other cases. Maybe random test data isn't the best approach, but pre-made edge cases of arrays too? \$\endgroup\$Raf– Raf2023年05月30日 13:40:20 +00:00Commented May 30, 2023 at 13:40
-
1\$\begingroup\$ @Raf --"I had to pass a new, random, non-sorted array (not a copy of the original) into every single algorithm separately" -- it's a requirement to generate a new random array for every algorithm \$\endgroup\$i_hate_F_sharp– i_hate_F_sharp2023年05月30日 16:57:25 +00:00Commented May 30, 2023 at 16:57
-
1\$\begingroup\$ I know it's a restriction (hence a comment), but I'd ask for clarification from the professor, or if you dare -- challenge that requirement :) \$\endgroup\$Raf– Raf2023年06月01日 10:08:07 +00:00Commented Jun 1, 2023 at 10:08
-
\$\begingroup\$ In your title, you talk about O(N log N) sorting algorithms, but in the body, you mention QuickSort and Selection Sort. Both QuickSort and Selection Sort are O(N²). (I am assuming you are talking about the worst-case number of comparisons in terms of the length of the input, which is the typical way to measure comparison-based sorts – unfortunately, you don't define what N is and what you are counting.) \$\endgroup\$Jörg W Mittag– Jörg W Mittag2023年06月04日 11:18:31 +00:00Commented Jun 4, 2023 at 11:18
-
\$\begingroup\$ @JörgWMittag NLogN because they're the fastest and most commonly used algorithms-- N is usually the size of the input, that's how they taught me in school \$\endgroup\$i_hate_F_sharp– i_hate_F_sharp2023年06月05日 15:45:32 +00:00Commented Jun 5, 2023 at 15:45
3 Answers 3
I will mainly review your algorithms (except the quicksort, though). Namely, you can go faster with them.
Advice 1 - heapify
In your heapify, when you sift down an element, you make 3 assignments in std::swap, so we have \3ドルn\$ assignments to sift \$n\$ times. You can do better: \$n + 1\$ assignments, and here is how:
void coderodde_sift_down(int* arr, int index, int heap_size) {
int left_child_index = index * 2 + 1;
int right_child_index = left_child_index + 1;
int maximum_index = index;
int target = arr[index];
while (true) {
if (left_child_index < heap_size && arr[left_child_index] > target) {
maximum_index = left_child_index;
}
if (maximum_index == index) {
if (right_child_index < heap_size && arr[right_child_index] > target) {
maximum_index = right_child_index;
}
}
else if (right_child_index < heap_size && arr[right_child_index] > arr[left_child_index]) {
maximum_index = right_child_index;
}
if (maximum_index == index) {
arr[maximum_index] = target;
return;
}
arr[index] = arr[maximum_index];
index = maximum_index;
left_child_index = index * 2 + 1;
right_child_index = left_child_index + 1;
}
}
Advice 2 - Mergesort
As most novices do while implementing mergesort, you keep allocating memory for left and right runs at each recursion level worth \$n\$ ints. (In total of \$\Theta(n \log n)\$ worth memory allocations.)
One trick you could do is to allocate (only once) a buffer array with exactly the same content as the input array, and keep alternating their roles: at the bottom recursion level, you take two adjacent runs from a source array and merge them into a target array. Then, at the next recursion level, you swap the roles of the two arrays and keep doing that until you merge two topmost runs (covering the entire array) from the source array to the target array. (Using recursion magic, we can ensure that at that point the target array is the input array we want to sort; not the buffer.)
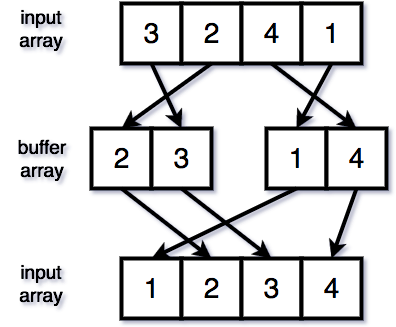{kind=link}
(The entire program for running all you sorts and my mergesort + heapsort is behind this link.)
Advice 3 - sorted
You have defined the sorted function, yet you don't use it. Since the data on each run is random, to me it seems sensible to deploy sorted to make sure that algorithms don't fail.
-
\$\begingroup\$ Thanks for reviewing my code, yeah
sorted()func was implemented only for testing purposes, I called it in the early stages to see if my algorithms work. I forgot to remove it for the submission \$\endgroup\$i_hate_F_sharp– i_hate_F_sharp2023年05月30日 07:02:43 +00:00Commented May 30, 2023 at 7:02 -
\$\begingroup\$ @TheCompile-TimeComedian Did my linked gist compile? If so, can you spot any performance improvements? \$\endgroup\$coderodde– coderodde2023年05月30日 07:09:48 +00:00Commented May 30, 2023 at 7:09
-
\$\begingroup\$ Can I fork it from your Git Repo? \$\endgroup\$i_hate_F_sharp– i_hate_F_sharp2023年05月30日 07:11:46 +00:00Commented May 30, 2023 at 7:11
-
1\$\begingroup\$ @TheCompile-TimeComedian Sure. Seems like you already did. \$\endgroup\$coderodde– coderodde2023年05月30日 07:13:41 +00:00Commented May 30, 2023 at 7:13
-
\$\begingroup\$ Yeah, your implementation is almost twice as fast when it comes to larger array sizes. Thanks a lot! \$\endgroup\$i_hate_F_sharp– i_hate_F_sharp2023年05月30日 07:16:12 +00:00Commented May 30, 2023 at 7:16
@coderodde already sufficiently covered the algorithm parts, thus I only cover implementation:
You only need 2 things to identify an array-slice, start and length (or end). Adding a start-index is just cumbersome.
Avoid
std::endl. It isn't some kind of magically platform-appropriate end of line marker, but'\n'(widened if needed) followed by a manual flush.
The manual flush generally just eats performance, if you actually need it be explicit and usestd::flush.Use the "new" C++11 random throughout. No need to use the old one arbitrarily for some of it.
Output the random seed chosen for your test, and let the caller override it if they wish. Repeatability is quite valuable especially when debugging or testing.
Use the same test-data for all tests. We want it to be fair, right?
There are doc-comments which end up in the documentation and should be enough to use the code, and implementation-comments.
The latter should describe why you do the things you do the way you do them, where appropriate. That might include a simplified overview of the algorithm, but won't include paraphrasing each step. More about good comments.
-
1\$\begingroup\$ I see a lot of complaints for number [5], they all sound reasonable to me, but the professor stated we need to pass a random array fro every algorithm, not a copy of the original one. Sounds incredibly stupid and you might even think I am in the wrong here...but I went to her office hours and asked specifically about that and she said she want's it that way. \$\endgroup\$i_hate_F_sharp– i_hate_F_sharp2023年05月30日 20:26:22 +00:00Commented May 30, 2023 at 20:26
-
1\$\begingroup\$ @TheCompile-TimeComedian The Boss always has the final word, that's just the way it is. \$\endgroup\$Deduplicator– Deduplicator2023年05月30日 20:30:05 +00:00Commented May 30, 2023 at 20:30
-
\$\begingroup\$ Unfortunately, yeah
:/\$\endgroup\$i_hate_F_sharp– i_hate_F_sharp2023年05月30日 20:30:39 +00:00Commented May 30, 2023 at 20:30 -
\$\begingroup\$ Added a point about the comments. Read the linked answer too. \$\endgroup\$Deduplicator– Deduplicator2023年05月30日 20:38:19 +00:00Commented May 30, 2023 at 20:38
Using
intfor indexing is wrong. Usestd::size_t.An addition in
int q = (p + r) / 2;may overflow. Considerint q = p + (r - p)/2;A single most important advantage of merge sort is stability: element compare equal retain their original order. In your implementation
if(left_sub[i] < right_sub[j])stability is lost: of the two equals the one from the right is merged first. It doesn't really matter for integers, but still
if(left_sub[i] <= right_sub[j])is a correct way.
As the partitions get smaller and smaller, a recursion overhead of quick sort becomes more and more expensive. Do not recurse into small partitions; have a final pass of an insertion sort instead, like in:
void quick_sort_helper(int* arr, int low, int high) { if (low + CUTOFF < high) { int partition_index = partition(arr, low, high); // partition the array and get the partition index quick_sort_helper(arr, low, partition_index - 1); // recursively sort the left subarray quick_sort_helper(arr, partition_index + 1, high); // recursively sort the right subarray } } void quick_sort(int* arr, int size) { quick_sort_helper(arr, 0, size - 1); insertion_sort(arr, 0, size - 1); }Selection of a cutoff value is an interesting question. Insertion sorting an arbitrary array has a quadratic time complexity; however we are guaranteed that by the time
insertion_sortis called, the array is almost sorted. Every element is within aCUTOFFof its final destination. The time complexity becomesO(n * CUTOFF). Since we are striving to obtain anO(N * log n)complexity,log nis a natural choice.That said, most implementation use a cutoff constant like 16 or 32.