I'm new to web scraping and tried building a web scraper for Amazon customer reviews. The program works fine as is but I wanted to improve the design and get some feedback. The basic idea was to scrape customer review contents on Amazon product review pages using specific URL structures.
1. URL to search for product names:
https://www.amazon.com/s?k={product_name}
If I wanted to search for "Iphone 14", then the product query I provide would be "iphone+14" in the URL above.
2. To search for products over multiple pages, the URL would be:
https://www.amazon.com/s?k={product_name}&page={n}
3. Each product has a unique identifier assigned (called ASIN), and each product search page lists ASINs embedded in "div" tag for product names. Customer reviews are on a separate page with ASIN in the URL.
https://www.amazon.com/product-reviews/{ASIN}
Not all the reviews are displayed in one product review page. To search for reviews over multiple pages, the URL used is as follows:
https://www.amazon.com/product-reviews/{ASIN}?pageNumber={n}
Concerns:
- I tried using
map()function to loop over queries on multiple pages. And it led to nested lists which I had to flatten usingreduce(operator.iconcat, ...). Would it be better to just use list comprehension? Or any other suggestions?
For instance, in get_prod_name():
...
pages = range(start, end + 1)
query = list(map(lambda x: query + f"&page={str(x)}", pages))
html_raw = list(map(lambda x: getpage(x, "item"), query))
html_tag = list(map(lambda x: x.find_all("span", class_ = "a-size-medium a-color-base a-text-normal"), html_raw))
html_tag = reduce(operator.iconcat, html_tag) # flatten the ResultSet
products = list(map(lambda x: x.text, html_tag))
...
- Some of the results from
get_reviews()had text "the media could not be loaded." I don't quite understand why this is happening.
I'm very much open to any criticism and thank you guys in advance for helping!
Code:
import requests
import operator
from bs4 import BeautifulSoup
from functools import reduce
# global variables
BASE_URL = "https://www.amazon.com/"
HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36",
"Accept-Language": "en-US, en;q=0.9"}
# user defined functions
def getpage(query, url_type):
"""
A helper function to create a BeautifulSoup object. Input query string and specify the url type.
The goal is to return html code of a page.
query: str input. Accepts search query by "item name" or "asin"
url_type: specify the url type for the search you're doing. options = "item", "asin"
"""
if url_type == "item":
url = BASE_URL + "s?k=" + query
elif url_type == "asin":
url = BASE_URL + "product-reviews/" + query
else:
return "Error: url type unsupported. Choose from the following 'item', 'asin'"
response = requests.get(url, headers = HEADERS)
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser")
else:
return "Error: status_code != 200"
def get_prod_name(query, start = 1, end = None):
"""
query: string input. search items on amazon in browser url tab.
e.g. if you wanted to search for "iphone 13", it would be "iphone+13"
start: integer input. starting page number, default = 1
end: integer input. ending page number, default = None
returns a list of product names from search
"""
if end == None:
query = query + f"&page={str(start)}"
html_raw = getpage(query, "item")
products = html_raw.find_all("span", class_ = "a-size-medium a-color-base a-text-normal")
return list(map(lambda x: x.text, products))
else:
pages = range(start, end + 1)
query = list(map(lambda x: query + f"&page={str(x)}", pages))
html_raw = list(map(lambda x: getpage(x, "item"), query))
html_tag = list(map(lambda x: x.find_all("span", class_ = "a-size-medium a-color-base a-text-normal"), html_raw))
html_tag = reduce(operator.iconcat, html_tag) # flatten the ResultSet
products = list(map(lambda x: x.text, html_tag))
return products
def get_asin(query, start = 1, end = None):
"""
***NEED QUERY FORMAT ITEMS TO RETRIEVE ASIN***
query: string input. search items on amazon in browser url tab.
e.g. if you wanted to search for "iphone 13", it would be "iphone+13"
start: integer input. starting page number, default = 1
end: integer input. ending page number, default = None
returns a list of asin associated with the items from search
"""
if end == None:
query = query + f"&page={str(start)}"
html_raw = getpage(query, "item")
html_tag = html_raw.find_all("div", class_ = "s-result-item s-asin sg-col-0-of-12 sg-col-16-of-20 sg-col s-widget-spacing-small sg-col-12-of-16")
return list(map(lambda x: x.attrs["data-asin"], html_tag))
else:
pages = range(start, end + 1)
query = list(map(lambda x: query + f"&page={str(x)}", pages))
html_raw = list(map(lambda x: getpage(x, "item"), query))
html_tag = list(map(lambda x: x.find_all("div", class_ = "s-result-item s-asin sg-col-0-of-12 sg-col-16-of-20 sg-col s-widget-spacing-small sg-col-12-of-16"),
html_raw
)
)
html_tag = reduce(operator.iconcat, html_tag) # flatten the ResultSet
asin_list = list(map(lambda x: x.attrs["data-asin"], html_tag))
return asin_list
def get_reviews(asin: list, start = 1, end = None):
"""
asin: list input. a list of ASIN
start: integer input. starting page number, default = 1
end: integer input. ending page number, default = None
returns individual review contents of a product-review page.
"""
if end == None:
query = list(map(lambda x: x + f"?pageNumber={str(start)}", asin))
html_raw = list(map(lambda x: getpage(x, "asin"), query))
html_tag = list(map(lambda x: x.find_all("span", attrs = {"data-hook": "review-body"}), html_raw))
html_tag = reduce(operator.iconcat, html_tag) # flatten the ResultSet
reviews = list(map(lambda x: x.text, html_tag))
reviews = [r.strip("\n") for r in reviews]
return reviews
else:
pages = range(start, end + 1)
queries = []
for p in pages:
for id in asin:
query = id + f"?pageNumber={str(p)}"
queries.append(query)
html_raw = list(map(lambda x: getpage(x, "asin"), queries))
html_tag = list(map(lambda x: x.find_all("span", attrs = {"data-hook": "review-body"}), html_raw))
html_tag = reduce(operator.iconcat, html_tag) # flattent the ResultSet
reviews = list(map(lambda x: x.text, html_tag))
reviews = [r.strip("\n") for r in reviews]
return reviews
### test
# search_query = "iphone+14"
# print(get_prod_name(search_query, 1, 3))
# IDs = get_asin(search_query, 1, 3)
# print(get_reviews(IDs, 1, 3))
-
1\$\begingroup\$ While I'm happy that you accepted my answer, please consider waiting a few more days for additional answers. Personally, I wait a week before accepting an answer on a question, as other answers can build up from existing answers and improve the code considerably. \$\endgroup\$Ismael Miguel– Ismael Miguel2023年01月01日 16:10:42 +00:00Commented Jan 1, 2023 at 16:10
-
1\$\begingroup\$ Thanks for the advice 👍 \$\endgroup\$nightstand– nightstand2023年01月01日 16:30:37 +00:00Commented Jan 1, 2023 at 16:30
1 Answer 1
Your code is pretty clean, you implement docstrings and it seems easy enough to read.
You do have 1 extra indentation level, which I will assume that it is a copy-paste-format error.
However...
Bugs
I found 2 bugs that are easy to catch.
getpage returns strings
Here's the code in question:
# user defined functions
def getpage(query, url_type):
"""
A helper function to create a BeautifulSoup object. Input query string and specify the url type.
The goal is to return html code of a page.
query: str input. Accepts search query by "item name" or "asin"
url_type: specify the url type for the search you're doing. options = "item", "asin"
"""
if url_type == "item":
url = BASE_URL + "s?k=" + query
elif url_type == "asin":
url = BASE_URL + "product-reviews/" + query
else:
return "Error: url type unsupported. Choose from the following 'item', 'asin'"
response = requests.get(url, headers = HEADERS)
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser")
else:
return "Error: status_code != 200"
The first sentence of the docstring reads:
A helper function to create a BeautifulSoup object.
This is obviously a lie! The 6th and last lines return a string.
Return a BeautifulSoup or consider throwing a "proper" exception.
But why is this bad?
This is bad because you're using the return value directly.
Here's an example taken from get_prod_name:
# [...]
html_raw = getpage(query, "item")
products = html_raw.find_all("span", class_ = "a-size-medium a-color-base a-text-normal")
# [...]
This will throw an exception because you're accessing the method find_all on a string value. This method doesn't exist.
Input handling
More like, the lack of input handling...
You expect that the string is already URL-formatted.
Yeah, you do talk about this in the docstring, but, this is error prone and the reason why I classify it as a bug.
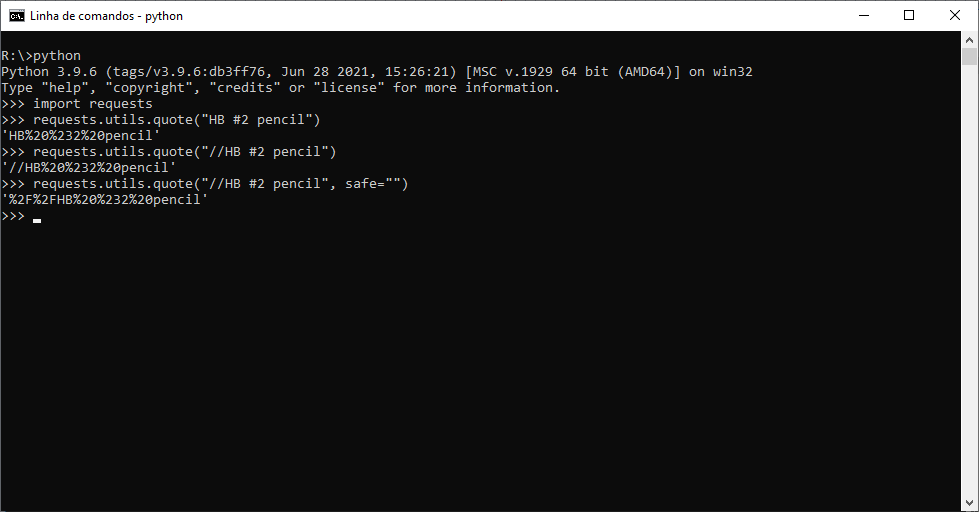
Just imagine trying to find HB #2 pencils with your code, and having to manually encode the space and the pound symbol.
You're putting the "user" in an error-prone situation because of pure lazyness.
All you have to do is to take the input and use requests.utils.quote on it.
I found this on here: https://stackoverflow.com/questions/46783078/uri-encoding-in-python-requests-package#comment126847571_46783596
You just need to go to the functions get_prod_name and get_asin and add this as the first line:
query = requests.utils.quote(query, safe='')
But why add safe=''?
As explained in the linked comment, this function assumes that / is a safe character (as it is just the function urllib.parse.quote).
Here's an example: Example of using the function requests.utils.quote
{kind=link}
Leaving the bugs behind, now it's time to talk about ...
Weird things
Strange string usage
Inside the function get_prod_name, you have the following:
query = query + f"&page={str(start)}"
Inside a formatted string, you don't need to use the str function, as it is implicitly converted to string.
And then, you're concatenating it, which is kinda weird too.
You can just do this:
query = f"{query}&page={start}"
In this case, maybe you should just use the += operator:
query += f"&page={start}"
Both will have the same exact effect.
Repeated code
You have quite a lot of repeated code, for apparently no reason at all...
Lets analyze the code inside the get_reviews function:
# asin: list, start = 1, end = None
# [...]
if end == None:
query = list(map(lambda x: x + f"?pageNumber={str(start)}", asin))
html_raw = list(map(lambda x: getpage(x, "asin"), query))
html_tag = list(map(lambda x: x.find_all("span", attrs = {"data-hook": "review-body"}), html_raw))
html_tag = reduce(operator.iconcat, html_tag) # flatten the ResultSet
reviews = list(map(lambda x: x.text, html_tag))
reviews = [r.strip("\n") for r in reviews]
return reviews
else:
pages = range(start, end + 1)
queries = []
for p in pages:
for id in asin:
query = id + f"?pageNumber={str(p)}"
queries.append(query)
html_raw = list(map(lambda x: getpage(x, "asin"), queries))
html_tag = list(map(lambda x: x.find_all("span", attrs = {"data-hook": "review-body"}), html_raw))
html_tag = reduce(operator.iconcat, html_tag) # flattent the ResultSet
reviews = list(map(lambda x: x.text, html_tag))
reviews = [r.strip("\n") for r in reviews]
return reviews
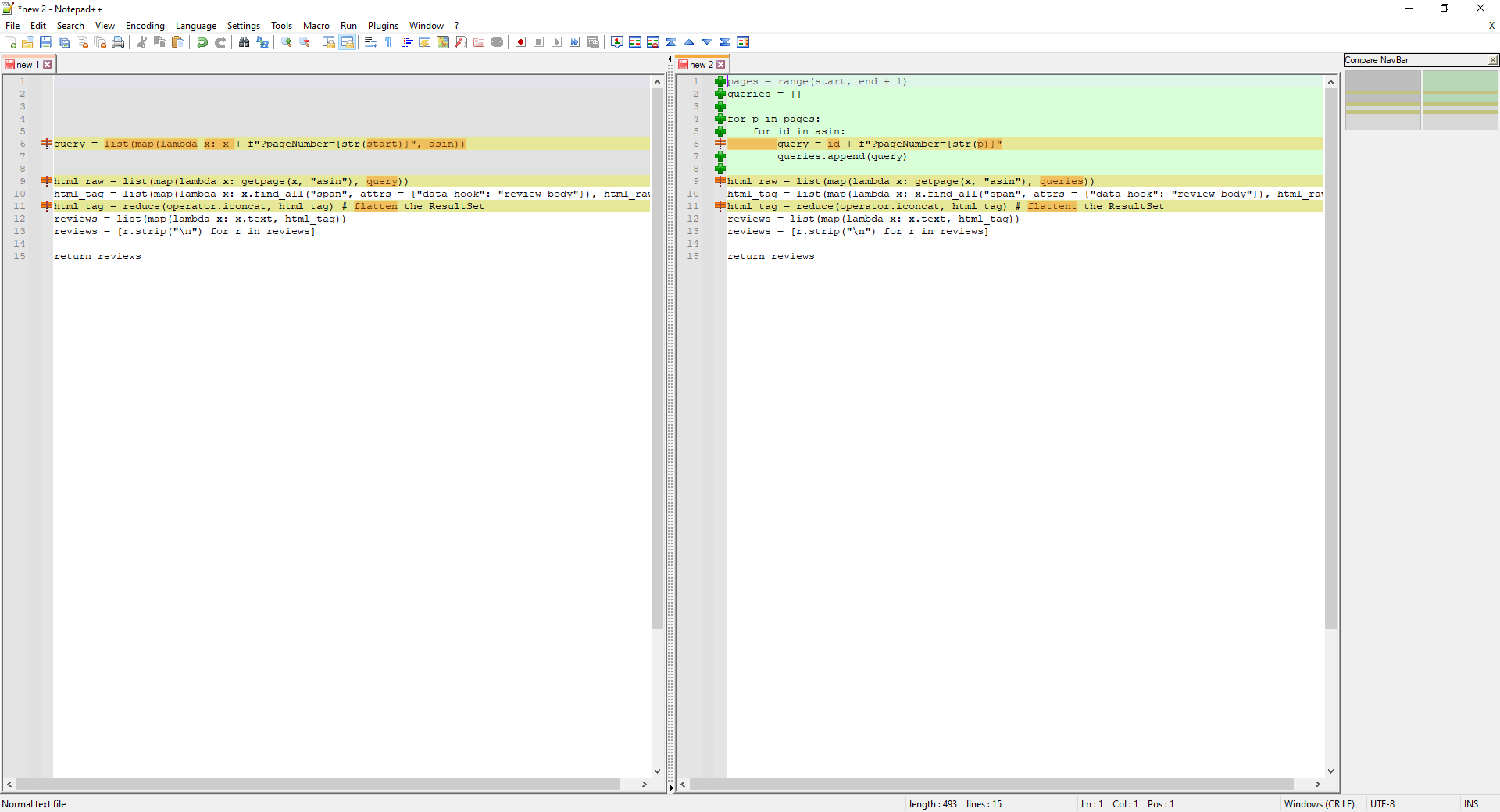
So, what's the difference between the code in the ifs?
I compared both, and this is the result: Result of comparing both ifs
{kind=link}
- The way the queries are built changes
- The way you call
getpage - The spelling of "flatten" (vs. "flattent")
All the other lines are REPEATED, exactly byte by byte.
You can just write this:
if end == None:
html_raw = list(map(lambda x: getpage(f"{x}?pageNumber={start}", "asin"), asin))
else:
pages = range(start, end + 1)
queries = []
for p in pages:
for id in asin:
queries.append(f"{id}?pageNumber={p}")
html_raw = list(map(lambda x: getpage(x, "asin"), queries))
html_tag = list(map(lambda x: x.find_all("span", attrs = {"data-hook": "review-body"}), html_raw))
html_tag = reduce(operator.iconcat, html_tag) # flatten the ResultSet
reviews = list(map(lambda x: x.text, html_tag))
reviews = [r.strip("\n") for r in reviews]
return reviews
I also removed some (kinda) useless maps, but if you want to add them back, feel free to do so.
However, it can be reduced a little more, if you're okay with changing variables as well:
if end == None:
queries = list(map(lambda x: f"{x}?pageNumber={start}", asin))
else:
queries = []
for page in range(start, end + 1):
for id in asin:
queries.append(f"{id}?pageNumber={page}")
html_raw = list(map(lambda x: getpage(x, "asin"), queries))
html_tag = list(map(lambda x: x.find_all("span", attrs = {"data-hook": "review-body"}), html_raw))
html_tag = reduce(operator.iconcat, html_tag) # flatten the ResultSet
reviews = list(map(lambda x: x.text, html_tag))
reviews = [r.strip("\n") for r in reviews]
return reviews
I've removed the variables query and pages, and reduced a repeated line.
I'm sure there's better ways to re-write this, but this is just to get your feet wet and a few ideas on what to do.
The strange pick of maps everywhere
On the above code, you do use the pattern list(map(lambda x: x)) a lot.
Try using list comprehensions, like this:
# old: html_raw = list(map(lambda x: getpage(x, "asin"), queries))
html_raw = [getpage(x, "asin") for x in queries]
Or, a better example:
# old: reviews = list(map(lambda x: x.text, html_tag))
# reviews = [r.strip("\n") for r in reviews]
reviews = [x.text.strip("\n") for x in html_tag]
This should work with BeautifulSoup, as the documentation contains the following example, in the first page:
One common task is extracting all the URLs found within a page’s tags:
for link in soup.find_all('a'): print(link.get('href')) # http://example.com/elsie # http://example.com/lacie # http://example.com/tillie
The name choices
There are some names that are extremely puzzling:
getpage- gives you a BeautifulSoup object or a stringhtml_raw- it's either a BeautifulSoup object or a string (no HTML here)html_tag- has a list of HTML elements, not tagsproducts- it's either a list of HTML elements or a list of product names
Please, try to come up with better names.
There's a lot more to say about the code, but, I don't feel comfortable talking about those points.
I do have a limited python knowledge, and I just hope I've helped enough for others to pick and carry on from here (or even see any mistakes I've made and point them out to me as well).
Any questions, just throw them in the comments.