I'm trying to obtain the following S2 from a given S1,
$$ S2(i, j) = \sum _{k=0} ^i \sum _{l=0} ^j S1(k, i-k, j, l) e^{ -\sqrt{-1} (i-k)^2 (j-l) } $$
and I've written the following code using four loops. However, when I increase the parameter N, the computation becomes too slow.
import numpy as np
N=3
S1=np.arange(N**4).reshape(N,N,N,N)
S2=np.zeros((N,N),dtype ='complex_')
for i in range(N):
for j in range(N):
for k in range(i+1):
for l in range(j+1):
S2[i,j]+=S1[k,i-k,j,l]*np.exp(-1j*(i-k)**2*(j-l))
Are there more fast methods without using the loops, such as numpy's trace?
For the k summation, by inverse-ordering 0 axis or 1 axis for S1, trace seemed to be available with i-N as the offset with weight of the exponential, but a tuple cannot be the offset.
1 Answer 1
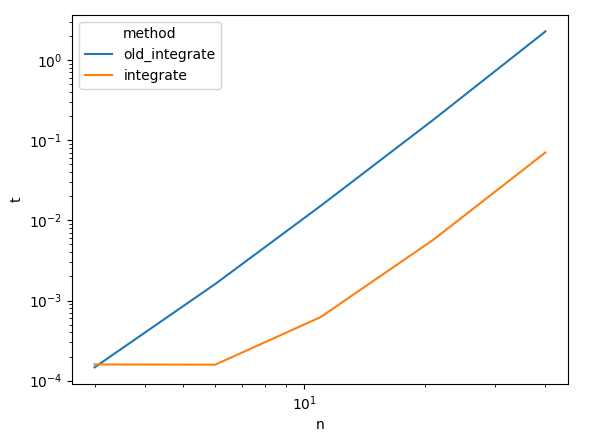
This can be vectorised, and when that's done it does run faster, though the time complexity does not improve and is still O(n^4). The proposed implementation has a speedup of roughly 35x.
Your current algorithm - which is a reasonable first step prior to optimisation - uses nested loops and direct indices. Whereas it computes fewer elements when compared to a fully-vectorised multiplication with pre- and post-triangularisation, the latter is more efficient at scale.
Recognise that the following three expressions:
for k in range(i+1)for l in range(j+1)S1[k,i-k,j,l]
all imply triangular matrices. Triangularising S1 can be done with a partial assignment to an initially-zero matrix using modified triu_indices. Triangularising the k and l assignments can be done after your calculation with a tril call.
A quick profile shows that the heart of the calculation - the Euler-form exp(i*theta) - is the bottleneck. Euler-form polar space calculations in Numpy are slow. Convert this to a rectangular expression and calculate the cos and sin in two halves of a contiguous array.
Further optimisations may be possible where you calculate only the non-zero segment and then reshape it. I have not shown this.
Suggested
from timeit import timeit
import numpy as np
import pandas as pd
import seaborn as sns
import cProfile
from matplotlib import pyplot as plt
def old_integrate(S1: np.ndarray) -> np.ndarray:
N = S1.shape[0]
S2 = np.zeros((N, N), dtype='complex_')
for i in range(N):
for j in range(N):
for k in range(i + 1):
for l in range(j + 1):
S2[i, j] += S1[k, i - k, j, l] * np.exp(-1j * (i - k) ** 2 * (j - l))
return S2
def slide_s1(S1: np.ndarray, N: int) -> np.ndarray:
# Achieve the effect of S1[k, i-k, :, :]
S1_slid = np.zeros_like(S1)
k, i = np.triu_indices(N)
S1_slid[i, k, :, :] = S1[k, i-k, :, :]
return S1_slid
def addend_expr(
S1_slid: np.ndarray,
i_minus_k: np.ndarray,
j_minus_l: np.ndarray,
) -> np.ndarray:
# return S1_slid * np.exp(-1j * (i_minus_k**2 * j_minus_l)) # 820 ms
'''theta = i_minus_k**2 * j_minus_l # 437 ms
result = S1_slid * (
np.cos(theta) - 1j * np.sin(theta)
)
return result'''
# 268 ms
theta = -i_minus_k**2 * j_minus_l
rect = np.empty((*S1_slid.shape, 2), dtype=np.float64)
np.cos(theta, out=rect[..., 0])
np.sin(theta, out=rect[..., 1])
as_complex = rect.view(dtype=np.complex128)[..., 0]
as_complex *= S1_slid
return as_complex
def make_addends(S1_slid: np.ndarray, N: int):
# Numeric indices over any of the dimensions
idx = np.arange(N)
# Broadcast index difference to two-dimensional matrix
idx_diff = idx[:, np.newaxis] - idx
# Four-dimensional term: (j - l)
j_minus_l = idx_diff[np.newaxis, np.newaxis, :, :]
# Four-dimensional term: (i - k)
i_minus_k = idx_diff[:, :, np.newaxis, np.newaxis]
# Full addends before triangularisation
addends = addend_expr(S1_slid, i_minus_k, j_minus_l)
# Triangularise
return np.tril(addends)
def integrate(S1: np.ndarray) -> np.ndarray:
N = S1.shape[0]
S1_slid = slide_s1(S1, N)
addends = make_addends(S1_slid, N)
# sum ("integrate").
S2 = np.sum(addends, axis=(1, 3))
return S2
def synthetic(N: int) -> np.ndarray:
return np.arange(N**4).reshape((N, N, N, N))
def test() -> None:
# Regression test.
# Original input data
N = 3
S1 = synthetic(N)
s2_expected = np.array((
( 0, 7.00000000 + 0.00000000j, 21.00000000 + 0.00000000j),
( 36, 80.48362767 - 10.09765182j, 121.40263435 - 27.10299716j),
(108, 184.34527389 - 16.92451601j, 238.92174068 - 79.19827981j),
))
for method in (old_integrate, integrate):
S2 = method(S1)
assert np.allclose(S2, s2_expected, rtol=1e-10, atol=0)
def profile() -> None:
N = 60
cProfile.runctx(
'integrate(S1)',
locals={
'S1': synthetic(N),
},
globals=globals(),
sort='tottime',
)
def compare() -> None:
times = []
for n in np.round(10**np.linspace(0.5, 1.6, 5)):
S1 = synthetic(int(n))
for method in (old_integrate, integrate):
def run():
return method(S1)
t = timeit(run, number=1)
times.append((n, method.__name__, t))
df = pd.DataFrame(times, columns=('n', 'method', 't'))
ax = sns.lineplot(data=df, x='n', hue='method', y='t')
ax.set(xscale='log', yscale='log')
plt.show()
if __name__ == '__main__':
test()
profile()
compare()
Output
99 function calls (96 primitive calls) in 0.357 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.264 0.264 0.264 0.264 274360.py:32(addend_expr)
8/5 0.049 0.006 0.061 0.012 {built-in method numpy.core._multiarray_umath.implement_array_function}
1 0.012 0.012 0.012 0.012 {method 'reduce' of 'numpy.ufunc' objects}
1 0.012 0.012 0.357 0.357 <string>:1(<module>)
{kind=link}
-
\$\begingroup\$ For the expressions
S1[k,i-k,j,l]andfor k in range(i+1), aren't the two corresponding triangularizings are equivalent? Then, further triangularizing forfor k in range(i+1)is not necessary. \$\endgroup\$user16308– user163082022年02月23日 16:07:09 +00:00Commented Feb 23, 2022 at 16:07 -
\$\begingroup\$ @user16308 You're right! Thanks; edited. \$\endgroup\$Reinderien– Reinderien2022年02月23日 16:28:40 +00:00Commented Feb 23, 2022 at 16:28
-
\$\begingroup\$ You're welcome! Thanks for the answer \$\endgroup\$user16308– user163082022年02月23日 16:31:28 +00:00Commented Feb 23, 2022 at 16:31
-
\$\begingroup\$ When the
Nis increased a lot to ~200, which is the case I am studying, the memory problem may pop up, only for the vectorisation, not for the explicit for loops. I may need to figure out how the vectorisations can avoid the memory problem. \$\endgroup\$user16308– user163082022年02月24日 16:00:54 +00:00Commented Feb 24, 2022 at 16:00
forloops in the code. I think your summary title is incorrect. \$\endgroup\$