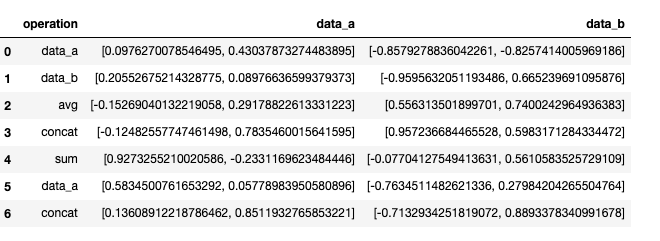
I have a data frame, which contains three columns:
import numpy as np
import pandas as pd
np.random.seed(0)
dataframe = pd.DataFrame({'operation': ['data_a', 'data_b', 'avg', 'concat', 'sum', 'take_a', 'concat'],
'data_a': list(np.random.uniform(-1,1,[7,2])), 'data_b': list(np.random.uniform(-1,1,[7,2]))})
{kind=link}
Column 'operation' represent merge column, so if there is 'data_a' value in Column 'operation', it means take that particular row's data_a value, if there is 'avg' operation, then take the average of 'data_a' and 'data_b' of that particular row so on.
What I am expecting in the output, a new column contains the values as per the operation column's merge functions:
{kind=link}
What I have tried:
dataframe['new_column'] = 'dummy_values'
for i in range(len(dataframe)):
if dataframe['operation'].iloc[i] == 'data_a':
dataframe['new_column'].iloc[i] = dataframe['data_a'].iloc[i]
elif dataframe['operation'].iloc[i] == 'data_b':
dataframe['new_column'].iloc[i] = dataframe['data_b'].iloc[i]
elif dataframe['operation'].iloc[i] == 'avg':
dataframe['new_column'].iloc[i] = dataframe[['data_a','data_b']].iloc[i].mean()
elif dataframe['operation'].iloc[i] == 'sum':
dataframe['new_column'].iloc[i] = dataframe[['data_a','data_b']].iloc[i].sum()
elif dataframe['operation'].iloc[i] == 'concat':
dataframe['new_column'].iloc[i] = np.concatenate([dataframe['data_a'].iloc[i], dataframe['data_b'].iloc[i]], axis=0)
That is obviously not a good way to do this, It's very slow too. I am looking for more pandas version to do this task.
-
\$\begingroup\$ Code Review requires concrete code from a project, with enough code and / or context for reviewers to understand how that code is used. Pseudocode, stub code, hypothetical code, obfuscated code, and generic best practices are outside the scope of this site. Please provide your real, actual function for a proper review. It's ok if the data is anonymized, just don't change the format. Every string can be replaced by a string, every int by an int, etc. Please don't change the function names though. \$\endgroup\$Mast– Mast ♦2020年09月03日 20:32:40 +00:00Commented Sep 3, 2020 at 20:32
-
\$\begingroup\$ Hi, @Mast the problem statement is same, I can't post real values because it's nth dim so I just used np.random for values. \$\endgroup\$Ayodhyankit Paul– Ayodhyankit Paul2020年09月03日 20:47:01 +00:00Commented Sep 3, 2020 at 20:47
1 Answer 1
Wrap the logic in a function, then
.applythat function.Consider then doing another function lookup using a simple dictionary. This keeps your functions very short and simple.
Something like:
def _op_get_a(row):
return row.data_a
def _op_get_b(row):
return row.data_b
def _op_avg(row):
return (row.data_a + row.data_b) / 2.0
def _op_sum(row):
return row.data_a + row.data_b
def _op_concat(row):
return np.concatenate([row.data_a, row.data_b], axis=0)
def process_row(row):
return {
'data_a': _op_get_a,
'data_b': _op_get_b,
'avg': _op_avg,
'sum': _op_sum,
'concat': _op_concat,
}[row.operation](row)
# The "axis=1" is critical to apply this row-wise rather than column-wise
dataframe['new_column'] = dataframe.apply(process_row, axis=1)
I haven't tested this code, but you get the idea. Supporting new row operations is as simple as writing it as a row-wise function and hooking it into the lookup dictionary. The code is written at the smallest possible unit and able to be individually documented without creating a big cluttered mess.
Explore related questions
See similar questions with these tags.