Based on my answer to another code review question I wrote my own python script for DLA (Diffusion Limited Aggregation).
The DLA algorithm task:
- Place seed at the center of the canvas.
- Release a random walker from the edge.
- Random walker sticks to the neighboring sites of the seed/previous points.
- Repeat N(particles) times.
Also, it was stated to use a 500x500 grid and simulate 50000 particles. And particles where not allowed to leave the area.
A brute force approach is very timeconsuming especially for increasing area size. Therefore I choose a different approach.
- Precalculate possible solutions when doing n steps in one go using multinomial distribution
- calculate a distance_matrix for all positions in the area, with the max. allowed steps that make sure, we do not leave the area (by more than one step; thats needed, or border would become sticking position) and also do not collide with another particle. This also gives automatically information about all stick positions (value == 0; sticking particles get value == -1).
- the distance matrix only has to be recalculated when a particle sticks (and also only a limited part of the whole area). While this is time consuming, it only happens N times (N=50000 particles)
- when a particle does a step, I first check the max distance and then get the corresponding precalculated possible movements and use np.random to choose from that list
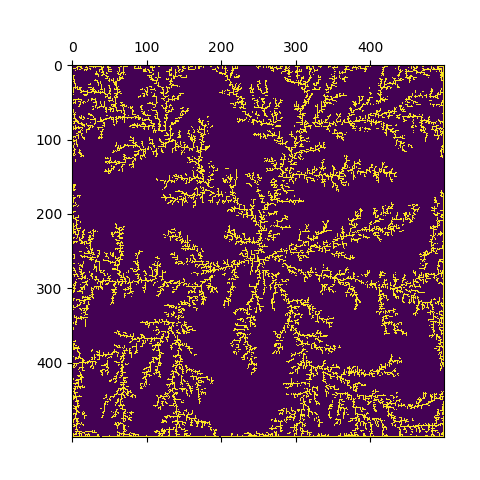
This approach could solve the task in 45 minutes (the brute force approach was stated to take more than a day):
{kind=link}
Note that 50000 particles seems to be too high a number for a 500x500 area, because in the end, particles are stopped at the border (but I wanted to reproduce the given task ^^).
For the precalculating, I used the module multiprocessing, for larger areas (200x200 and above) this improved the precalculating speed by a factor 6 with 6 cores on my test system. More than 95% of calculation time is spent in
position_list[pos_y, pos_x] += rv.pmf([n_left, n_right, n_down, n_up])
In the end, the precalculation only took 3% of the total simulation time, so I guess I can not improve efficency here (beside maybe saving precalculated values in a file, which could be loaded again for later simulations).
More than 1/3 of the total computation time is spent with DLASimulator.get_random_step()
I have a feeling, that there is still a possibility for significant improvement.
Feedback to readability, efficency and general remarks are welcome.
import bisect
from collections import defaultdict
from multiprocessing.pool import Pool
from multiprocessing.spawn import freeze_support
from typing import Optional, List
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import multinomial
def main():
np.random.seed(0)
dla_simulator = DLASimulator(area_size=(500, 500), max_steps=200) # max_steps is 167 for 500x500
dla_simulator.simulate(particles=50000)
dla_simulator.plot()
print("done")
class DLASimulator:
def __init__(self, area_size: tuple, max_steps: int, initial_particles_pos: Optional[List[tuple]] = None, max_factor=1.0):
self.area_size = area_size
if initial_particles_pos is None:
initial_particles_pos = [(area_size[0] // 2, area_size[1] // 2)]
self.initial_particles_pos = initial_particles_pos
self.distance_matrix = None # only to help code completion
self.init_distance_matrix()
self.is_first_particle = True
self.set_stick_particles(self.initial_particles_pos)
self.max_steps = min(max_steps, self.distance_matrix.max()) # no need to precalculate more than max distance
self.max_steps = max(int(self.max_steps*max_factor), 1) # no need to precalculate more than max distance
self.list_of_position_probability_dicts = generate_list_of_position_probability_dicts(self.max_steps)
def reset(self):
self.init_distance_matrix()
self.set_stick_particles(self.initial_particles_pos)
def simulate(self, particles: int = 1000, reset: bool = False):
print("start simulation")
if reset:
self.reset()
for _ in range(particles):
particle = self.get_new_particle()
self.simulate_particle(particle)
print(f"particle {_} sticked")
def simulate_particle(self, particle):
while True:
distance = self.distance_matrix[particle[1], particle[0]]
if distance == 0:
self.set_stick_particle(particle)
break
elif distance < 0:
# raise Exception("There is already a particle on This position")
break
else:
pos_x, pos_y = self.get_random_step(distance)
particle[0] = min(max(particle[0] + pos_x, 0), self.area_size[0]-1)
particle[1] = min(max(particle[1] + pos_y, 0), self.area_size[1]-1)
# calc distance to border for all positions (allowed number of steps in one go for each position)
def init_distance_matrix(self):
size_x, size_y = self.area_size
self.distance_matrix = np.zeros(self.area_size, np.int16)
for pos_x in range(size_x):
for pos_y in range(size_y):
self.distance_matrix[pos_y, pos_x] = min(pos_x + 1, pos_y + 1, size_x-pos_x, size_y - pos_y)
def set_stick_particles(self, particles):
for particle in particles:
self.set_stick_particle(particle)
def set_stick_particle(self, particle):
pos_x, pos_y = particle
self.distance_matrix[pos_y, pos_x] = -1 # no other particle allowed on this position
self.update_distance_positions(particle)
def update_distance_positions_in_rect(self, x_min, x_max, y_min, y_max, particle):
particle_x, particle_y = particle
for pos_x in range(x_min, x_max+1):
for pos_y in range(y_min, y_max + 1):
distance_to_stick = max(abs(pos_x - particle_x) + abs(pos_y - particle_y) - 1, 0)
self.distance_matrix[pos_y, pos_x] = min(self.distance_matrix[pos_y, pos_x], distance_to_stick)
def update_distance_positions(self, particle):
particle_x, particle_y = particle
x_min, y_min = 0, 0
x_max, y_max = self.area_size[0]-1, self.area_size[1]-1
# go in 4 directions; as soon as distance-value is smaller than distance from particle -> stop
for i in range(particle_x-1, -1, -1):
if self.distance_matrix[particle_y, i] <= particle_x - 1 - i:
x_min = i+1
break
for i in range(particle_y-1, -1, -1):
if self.distance_matrix[i, particle_x] <= particle_y - 1 - i:
y_min = i+1
break
for i in range(particle_x+1, self.area_size[0]):
if self.distance_matrix[particle_y, i] <= i - (particle_x + 1):
x_max = i-1
break
for i in range(particle_y+1, self.area_size[1]):
if self.distance_matrix[i, particle_x] <= i - (particle_y + 1):
y_max = i-1
break
self.update_distance_positions_in_rect(x_min, x_max, y_min, y_max, particle)
def get_new_particle(self) -> list:
random = np.random.randint(4)
if random == 0:
pos_x = 0
pos_y = np.random.randint(self.area_size[1])
elif random == 1:
pos_x = self.area_size[0] - 1
pos_y = np.random.randint(self.area_size[1])
elif random == 2:
pos_x = np.random.randint(self.area_size[0])
pos_y = 0
elif random == 3:
pos_x = np.random.randint(self.area_size[0])
pos_y = self.area_size[1] - 1
else:
raise Exception("Something went wrong in get_new_particle()")
return [pos_x, pos_y]
def get_random_step(self, distance):
n_step_dict = self.list_of_position_probability_dicts[min(distance, self.max_steps)]
random = np.random.random()
# search on numpy array seems to be slower then bisect on list
# index = np.searchsorted(n_step_dict["cumulative probability"], random)
index = bisect.bisect_left(n_step_dict["cumulative probability"], random)
pos_x = n_step_dict["pos_x"][index]
pos_y = n_step_dict["pos_y"][index]
return pos_x, pos_y
def plot(self):
canvas = np.zeros(self.area_size)
for x in range(self.area_size[0]):
for y in range(self.area_size[1]):
if self.distance_matrix[y, x] == -1:
canvas[y, x] = 1
plt.matshow(canvas)
plt.show()
plt.savefig("rand_walk_500particles.png", dpi=150)
def calc_symmetric_positions(position_list: dict) -> dict:
result = {}
for key, value in position_list.items():
pos_x = key[0]
pos_y = key[1]
result[-pos_x, pos_y] = position_list[(pos_x, pos_y)]
result[-pos_x, -pos_y] = position_list[(pos_x, pos_y)]
result[pos_x, -pos_y] = position_list[(pos_x, pos_y)]
result[pos_y, pos_x] = position_list[(pos_x, pos_y)]
result[-pos_y, pos_x] = position_list[(pos_x, pos_y)]
result[-pos_y, -pos_x] = position_list[(pos_x, pos_y)]
result[pos_y, -pos_x] = position_list[(pos_x, pos_y)]
return result
# no need for complete matrix, only list with actually reachable positions;
# creation is 1.055 times faster (compared to full matrix)
def calc_position_probability_list_symmetric(number_of_steps) -> dict:
result = {"cumulative probability": [], "pos_x": [], "pos_y": []}
# position_list = defaultdict(lambda:0.0) # multiprocessing needs to pickle -> can't have a lambda
position_list = defaultdict(float)
if number_of_steps == 0:
result["cumulative probability"].append(1)
result["pos_x"].append(0)
result["pos_y"].append(0)
return result
p_list = [0.25, 0.25, 0.25, 0.25] # all directions have same probability
rv = multinomial(number_of_steps, p_list)
# this loop finds all reachable positions
for n_right in range(number_of_steps + 1):
for n_left in range(number_of_steps - n_right + 1):
pos_x = n_right - n_left
if pos_x > 0: # due to symmetry
continue
for n_down in range(number_of_steps - n_left - n_right + 1):
n_up = number_of_steps - n_left - n_right - n_down
pos_y = n_up - n_down
# if pos_y > 0: # unnecessary; pos_x is already <=0
# continue
if pos_y > pos_x: # due to symmetry
continue
# this takes up >95% of computation time in calc_position_probability_list_symmetric!
# thus optimizing loop with impact on readability not helpful
# todo: check with pypy
position_list[pos_y, pos_x] += rv.pmf([n_left, n_right, n_down, n_up])
position_list.update(calc_symmetric_positions(position_list))
# create cummulative distribution values:
# todo: consider sorting before creating cumulative, to allow faster algorithm SLASimulator.in get_random_step()
sum=0
for key, value in position_list.items():
sum += value
result["cumulative probability"].append(sum)
result["pos_x"].append(key[0])
result["pos_y"].append(key[1])
# no speedup for bisect (np.array is even slower then list)
# result["cumulative probability"] = np.array(result["cumulative probability"])
# result["cumulative probability"] = tuple(result["cumulative probability"])
assert np.isclose(sum, 1.0)
return result
def generate_list_of_position_probability_dicts_single_process(max_number_of_steps: int) -> List[dict]:
result = []
for i in range(max_number_of_steps+1):
result.append(calc_position_probability_list_symmetric(i))
return result
def generate_list_of_position_probability_dicts(max_number_of_steps: int, multiprocessing=True) -> List[dict]:
if not multiprocessing:
return generate_list_of_position_probability_dicts_single_process(max_number_of_steps)
with Pool() as pool: # processes=None (or no argument given) -> number returned by os.cpu_count() is used.
result = pool.map(calc_position_probability_list_symmetric, range(max_number_of_steps+1))
return result
if __name__ == '__main__':
freeze_support() # needed for windows
main()
(the newest version can be found here)
2 Answers 2
As I understand the code, it 1) determines a minimum number of steps (a "radius") before a particle could run into a sticky point or the edge and 2) randomly moves to a point based on a pre-calculated multinomial distribution for that number of steps. The selected point could be anywhere within the determined "radius".
It seems that for a particle to reach a sticky point or the edge, it must first reach the circumference of the area defined by the radius. Therefore, for each step, it would suffice for the particle to jump to a randomly select point on the circumference of that area. And, because the area is symmetrical, it seems the points on the circumference are all equally probable.
This would let the particle make large jumps when it is far away from anything and take small steps when it is near something.
-
\$\begingroup\$ Interesting approach. While this is not really following the algorithm (there is no random walk done; it would be impossible to draw the path of the particle), it might generate similar results. And it would be orders of magnitude faster. The question is, how to prove, that each point on the circumference has the same probability. That is not true for doing it in the least possible number of steps. For example, there is only one option to do 10 steps to the right, but there are allready 10 options for one up and 9 right. But intuitivly, when ignoring the step number, it should be true. \$\endgroup\$natter1– natter12020年01月25日 15:26:39 +00:00Commented Jan 25, 2020 at 15:26
-
\$\begingroup\$ @natter1, Also, mapping from circumference to a grid coordinate may alter the probabilities. But the code already calculates the probabilities for every point that is upto n steps away. Just use the ones on the perimeter to calculate the cumulative distribution. \$\endgroup\$RootTwo– RootTwo2020年01月25日 19:11:55 +00:00Commented Jan 25, 2020 at 19:11
-
\$\begingroup\$ no need for mapping "circumference" to grid. The circumference is simply in dimond shape due to limiting the movement in 4 directions. Also, I don't think its a good idea to use the probabilities claculated with a fixed number of steps. I'm pretty sure, without limiting the number of steps, until reaching the circumverence, each position should have the same probability (so no precalculation; it would come down to a very simple function 1/(number of circumference positions)). The only question is, how to prof, that this is true (something like: if it is true for n, its true for n+1). \$\endgroup\$natter1– natter12020年01月25日 19:26:52 +00:00Commented Jan 25, 2020 at 19:26
-
\$\begingroup\$ Maybe I will check with a brute force approach for small n values, if all positions have same probability. \$\endgroup\$natter1– natter12020年01月25日 19:28:07 +00:00Commented Jan 25, 2020 at 19:28
-
\$\begingroup\$ Thinking about it a bit more, the number of paths to one side of the diamond circumference is just pascals triangle. One step = 1 1 (say for the upper right side of the diamond). For two steps the number of paths is 1 2 1, for three steps 1 3 3 1, and so on. \$\endgroup\$RootTwo– RootTwo2020年01月26日 08:15:47 +00:00Commented Jan 26, 2020 at 8:15
Total execution time scales with the total number of particles.
Would be interesting to see how the algorithm behaves for the given value of stickiness. Where stickiness can be defined as "probability when the moving particle stops when it collides with a particle at rest". The higher the value, the higher the chance of a particle coming to rest (and hence, the stickier the particle). Basically, how would you estimate the stickiness parameter with the given output of DLA. For simplicity, assume that stickiness parameter can only take values between 1e-3 and 5e-2.
Refer to the definition of "stickiness" as given just above Figure 6 at: http://paulbourke.net/fractals/dla/
-
4\$\begingroup\$ This does not provide an answer to the question. Once you have sufficient reputation you will be able to comment on any post; instead, provide answers that don't require clarification from the asker. - From Review \$\endgroup\$forsvarir– forsvarir2022年02月06日 10:40:57 +00:00Commented Feb 6, 2022 at 10:40