I don't like this function. Looks too imperative.
It takes two sorted lists and returns a sorted intersection of the two lists. There is an implicit assumption that there are no duplicate elements in either list.
Please don't suggest converting (even one of) the arguments to set, or using some sort of library function. This is a single-pass O(n+m) time, O(1) auxiliary space algorithm, and I want to keep it that way.
def sorted_lists_intersection(lst1, lst2):
i1 = 0
i2 = 0
len1 = len(lst1)
len2 = len(lst2)
intersection = []
while i1 < len1 and i2 < len2:
while lst1[i1] < lst2[i2]:
i1 += 1
if i1 == len1:
return intersection
while lst2[i2] < lst1[i1]:
i2 += 1
if i2 == len2:
return intersection
if lst1[i1] == lst2[i2]:
intersection.append(lst1[i1])
i1 += 1
i2 += 1
return intersection
6 Answers 6
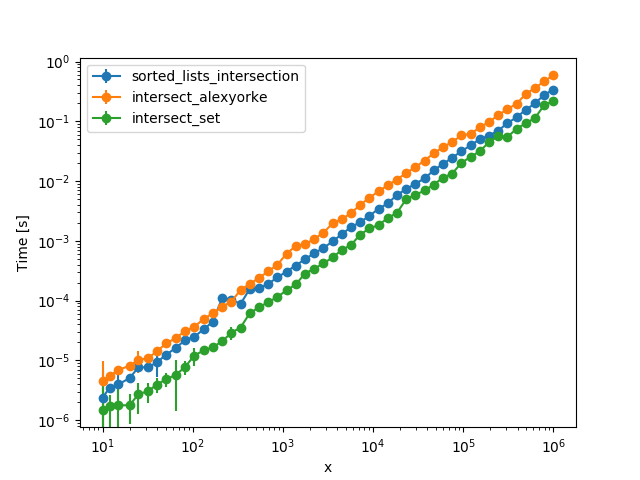
While you don't want alternative solutions, you should take a look at the data in your specific usecase. As an example, for some randomly generated input (both lists of length ~600) on my machine (Python 3.6.9, GCC 8.3.0), your function takes
In [18]: %timeit sorted_lists_intersection(a, b)
179 μs ± 1.19 μs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
The function defined in the answer by @alexyorke, while more readable IMO, takes a bit longer:
In [16]: %timeit list(intersect(a, b))
249 μs ± 4.67 μs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
In contrast, this highly readable and short implementation using set and sorted, that completely disregards the fact that the lists are already sorted (which means that it also works with unsorted lists):
def intersect_set(a, b):
return sorted(set(a) & set(b))
is about twice as fast:
In [29]: %timeit intersect_set(a, b)
77 μs ± 1.44 μs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Of course, in order to properly compare them, here are more data points:
import numpy as np
np.random.seed(42)
ns = np.logspace(1, 6, dtype=int)
inputs = [[sorted(set(np.random.randint(1, n * 10, n))) for _ in range(2)] for n in ns]
The set based function wins in all of these test cases:
{kind=link}
It looks like for lists with lengths of the order of more than 10M your function might eventually win, due to the \$\mathcal{O}(n\log n)\$ nature of sorted.
I think the greater speed (for a wide range of list sizes), coupled with the higher readability, maintainability and versatility makes this approach superior. Of course it requires objects to be hashable, not just orderable.
Whether or not this data is similar enough to yours, or whether or not you get the same timings, performing them to see which one is the best solution in your particular usecase is my actual recommendation.
-
\$\begingroup\$ Interesting; I ran your inputs with
timeit.Timer.autorangeand got these results. Also, keep in mind that my method as well as alexyorke's is implemented in pure Python, whereassetandsortedare implemented in C, that's why it's so fast. \$\endgroup\$kyrill– kyrill2019年12月05日 13:47:31 +00:00Commented Dec 5, 2019 at 13:47 -
\$\begingroup\$ @kyrill: Interesting results. Which Python version did you use? The one I used is 3.6.9. \$\endgroup\$Graipher– Graipher2019年12月05日 13:53:15 +00:00Commented Dec 5, 2019 at 13:53
-
\$\begingroup\$
3.7.3 (v3.7.3:ef4ec6ed12, Mar 25 2019, 22:22:05) [MSC v.1916 64 bit (AMD64)]\$\endgroup\$kyrill– kyrill2019年12月05日 14:04:44 +00:00Commented Dec 5, 2019 at 14:04 -
1\$\begingroup\$ @kyrill: Using functions implemented in C instead of doing everything in Python is the best practice because removes the interpreter overhead;
more-itertoolsrecipes do this for all the functions inside. Why are you trying to avoid best practice? \$\endgroup\$user179245– user1792452019年12月06日 02:42:22 +00:00Commented Dec 6, 2019 at 2:42 -
2\$\begingroup\$ @kyrill Then you definitely should modify your function to take iterables and
yieldvalues instead while utilizing theitertoolsfunctions; they're mostly written in C and this is the kind of situation they're used for. It's much cleaner and prevents all the clumsy store-keeping revolving around lists. \$\endgroup\$user179245– user1792452019年12月06日 02:57:49 +00:00Commented Dec 6, 2019 at 2:57
{kind=link}
The code seems to be too complicated. There are a few ways it can be optimized:
if i1 == len1:
return intersection
and
if i2 == len2:
return intersection
return statements can be expressed as yield so that the return for the entire array is not required; it returns constantly. However, this condition needs to be there otherwise it won't work; it can be refactored into incrementing both pointers step-wise instead, which eliminates boundary checks and intersection.append(lst1[i1]).
With these rules applied, the following is the refactored version:
def intersect(a, b):
i = 0
j = 0
while i < len(a) and j < len(b):
if a[i] > b[j]:
j += 1
elif a[i] < b[j]:
i += 1
else:
yield a[i]
j += 1
i += 1
Depending on readability, it can be expressed more tersely as:
def intersect(a, b):
i = 0
j = 0
while i < len(a) and j < len(b):
if a[i] == b[j]:
yield a[i]
i, j = i + (a[i] <= b[j]), j + (a[i] >= b[j])
This works because boolean operators return 0 if false and 1 if true. Since the failure conditions will add 0, it won't affect the result. The variables have to be assigned together on one line as it has to use i and j copies for array indexing.
-
\$\begingroup\$ @kyrill thank you for your suggestions; I have updated my answer \$\endgroup\$alexyorke– alexyorke2019年12月05日 02:28:44 +00:00Commented Dec 5, 2019 at 2:28
-
\$\begingroup\$ Note my first suggestion \$\endgroup\$kyrill– kyrill2019年12月05日 02:30:00 +00:00Commented Dec 5, 2019 at 2:30
-
\$\begingroup\$ And what do you mean by "return statements can be expressed as yield" ? \$\endgroup\$kyrill– kyrill2019年12月05日 02:33:43 +00:00Commented Dec 5, 2019 at 2:33
-
\$\begingroup\$ @kyrill The
yieldoperator "returns" a value when called; the function can then be wrapped in alist()to get the same "behavior| as returning/appending a list in a loop \$\endgroup\$alexyorke– alexyorke2019年12月05日 03:14:30 +00:00Commented Dec 5, 2019 at 3:14 -
2\$\begingroup\$ While the terse function works I don't think it's worth the extra programmer overhead in understanding it to save 5 lines of code. \$\endgroup\$Turksarama– Turksarama2019年12月07日 00:07:59 +00:00Commented Dec 7, 2019 at 0:07
If you treated your 2 inputs as iterables instead of simply lists, you could think in terms of for loops with direct access to elements instead of using __getitem__ all around. The second advantage being, obviously, that you can call the function using any iterable instead of only lists; so data that is in a file, for instance, can be processed with, e.g.:
target = [4, 8, 15, 16, 23, 42]
with open(my_file) as f:
common = sorted_lists_intersection(target, map(int, f))
without having to store the whole file in memory at once.
If you also make sure to turn your function into a generator, you can directly iterate over the results without having to store all of them at once in memory either; and you can still call list on the function if you truly need a list.
I propose the following implementation that have the same precondition than yours: the inputs must be sorted and should not contain duplicates:
from contextlib import suppress
def intersect_sorted_iterables(iterable1, iterable2):
iterator = iter(iterable2)
with suppress(StopIteration):
other = next(iterator)
for element in iterable1:
if element > other:
other = next(x for x in iterator if x >= element)
if element == other:
yield element
This version will take advantage of next raising StopIteration to exit the loop when any of the iterable is exhausted, making it par with your len checks.
-
\$\begingroup\$ I played with the idea of using iterators with
nextbut found it less elegant than the original code. Your idea is interesting as well, but TBH the code is a bit convoluted, especially theforloop with conditionalcontinueand unconditionalbreak. I think it would be neater if you did something likeother = next(x for x in iterator if x >= element). \$\endgroup\$kyrill– kyrill2019年12月05日 16:14:47 +00:00Commented Dec 5, 2019 at 16:14 -
\$\begingroup\$ @kyrill Yes, that's a neat rewrite of the inner for loop that get rid of the "must iterate over the whole first iterator" constraint. \$\endgroup\$301_Moved_Permanently– 301_Moved_Permanently2019年12月05日 21:45:27 +00:00Commented Dec 5, 2019 at 21:45
-
2\$\begingroup\$ You can exit the first loop with a return statement in an
elseblock of the second loop, which triggers when the second iterator is exhausted. \$\endgroup\$moooeeeep– moooeeeep2019年12月06日 08:13:19 +00:00Commented Dec 6, 2019 at 8:13 -
\$\begingroup\$ @moooeeep Updated the code with the suggestion from kyrill, so this is not needed anymore. \$\endgroup\$301_Moved_Permanently– 301_Moved_Permanently2019年12月06日 17:11:11 +00:00Commented Dec 6, 2019 at 17:11
using iterators
This is basically the same as your solution, but uses iterators instead of explicit indexing. I find it easy to understand.
def sorted_list_intersection(list1, list2):
iter1 = iter(list1)
iter2 = iter(list2)
intersection = []
try:
item1 = next(iter1)
item2 = next(iter2)
while True:
if item1 == item2:
intersection.append(item1)
item1 = next(iter1)
item2 = next(iter2)
elif item1 < item2:
item1 = next(iter1)
else:
item2 = next(iter2)
except StopIteration:
return intersection
-
1\$\begingroup\$ I was going to post something very similar, but instead of the
intersectionintermediate list, and appending to it,yieldeach match \$\endgroup\$Maarten Fabré– Maarten Fabré2019年12月06日 11:24:16 +00:00Commented Dec 6, 2019 at 11:24 -
1\$\begingroup\$ I'd suggest incorporating the
yieldas mentioned above. It would make sense to make your function a generator, since you're already using iterators (and hence possibly accepting generators as arguments). \$\endgroup\$kyrill– kyrill2019年12月06日 13:27:38 +00:00Commented Dec 6, 2019 at 13:27 -
1\$\begingroup\$ I agree
yield item1may be better thanintersection.append(item1), depending on the use case, I was just mirroring what the OP code did. \$\endgroup\$RootTwo– RootTwo2019年12月06日 18:57:05 +00:00Commented Dec 6, 2019 at 18:57
My own contribution.
I took inspiration from 409_Conflict and made a lazy generator which takes sorted iterables.
I further generalized it to accept an arbitrary (but non-zero) number of iterables and return their mutual intersection.
The time complexity of this algorithm is \$O(n^2*\min\{\text{len}(it) \ \vert\ it \in \texttt{iterables}\})\$ where \$n = \text{len}(\texttt{iterables})\$. Using some smart datastructure such as Fibonacci heap, the asymptotic complexity could be improved at the cost of actual performance (and also readability and such).
import contextlib
def all_equal(items):
"""
Returns `False` if and only if there is an element e2 in `items[1:]`,
such that `items[0] == e2` is false.
"""
items_it = iter(items)
try:
first_item = next(items_it)
except StopIteration:
return True
return all(first_item == next_item for next_item in items_it)
def sorted_iterables_intersection(*iterables):
iterators = [iter(iterable) for iterable in iterables]
with contextlib.suppress(StopIteration):
while True:
elems = [next(it) for it in iterators]
while not all_equal(elems):
# Find the iterator with the lowest value and advance it.
min_idx = min(range(len(iterables)), key=elems.__getitem__)
min_it = iterators[min_idx]
elems[min_idx] = next(min_it)
yield elems[0]
-
\$\begingroup\$ Lastly, allowing for 0 iterables (if desired) is trivial by changing the
while True:intowhile iterators:. \$\endgroup\$301_Moved_Permanently– 301_Moved_Permanently2019年12月05日 21:59:35 +00:00Commented Dec 5, 2019 at 21:59 -
\$\begingroup\$ Regarding the
all_equal: there's indeed no need forzip; I removed it and also replacedtrywithcontextlib.suppress. As per allowing zero iterables:while iteratorsis the exact thing that came to my mind, and I swiftly dismissed the idea because there's really no need to keep repeatedly checking whether there are any iterators; you only need to check once. And adding a check before the while loop just didn't seem worth it ‒ why would you call the function with no arguments? Anyways, thanks for the suggestions. \$\endgroup\$kyrill– kyrill2019年12月05日 22:59:59 +00:00Commented Dec 5, 2019 at 22:59 -
\$\begingroup\$ The definition of
all_euqal()is missing. \$\endgroup\$greybeard– greybeard2019年12月06日 04:48:13 +00:00Commented Dec 6, 2019 at 4:48 -
\$\begingroup\$ @kyrill Yes, also one can wonder where iterators is beeing modified in the first place. So I agree with your points, hence the "if desired". \$\endgroup\$301_Moved_Permanently– 301_Moved_Permanently2019年12月06日 07:22:05 +00:00Commented Dec 6, 2019 at 7:22
If you truly don't want to convert to sets, perhaps use the underlying idea that they implement. Note that get_hash is pretty arbitrary and definitely could be improved. Here's a resource on improving the hashing and choice of hash_map size
def get_hash(thing, hash_map):
hashed = ((hash(thing) * 140683) ^ 9011) % len(hash_map)
incr_amount = 1
while hash_map[hashed] is not None and hash_map[hashed] != thing:
hashed += incr_amount ** 2
incr_amount += 1
if hashed >= len(hash_map):
hashed = hashed % len(hash_map)
return hashed
def sorted_lists_intersection(a, b):
hash_map = [None for _ in range(len(a) * 7 + 3)]
for x in a:
hash_map[get_hash(x, hash_map)] = x
return filter(lambda x: x == hash_map[get_hash(x, hash_map)], b)
Edit based on comments:
Here is a O(m*n) in-place answer
def intersection_sorted_list(a, b):
return filter(lambda x: x in a, b)
Now, if the lists are sorted we can speed this up a bit by shrinking the range we check against after each successive match. I believe this makes it O(m+n) time.
def intersection_sorted_list(a, b):
start_indx = 0
for x in b:
for i in range(start_indx, len(a)):
if a[i] == x:
yield a[i]
if a[i] >= x:
start_indx = i + 1
break
-
\$\begingroup\$ Pardon my French, but this is awful. Firstly, Python has a built-in
hashfunction; secondly, Python has a built-indictclass which is a "hash map" and thirdly, what you try to accomplish using a hash map, can be accomplished using aset. Your answer can be summed up in one line:return filter(lambda x: x in set(a), b). Which I explicitly stated I am not interested in. \$\endgroup\$kyrill– kyrill2019年12月06日 01:39:54 +00:00Commented Dec 6, 2019 at 1:39 -
\$\begingroup\$ @kyrill, the inbuilt function is not directly applicable for hashmaps, you need to find the modulo of it and perform probing at the very least. "what you try to accomplish using a hash map, can be accomplished using a set" I explicitly stated that was the purpose of my answer. You haven't stated what you are interested in, only "I don't like this function. Looks too imperative.". This a less imperative function. I don't understand what you are looking for since you are explicitly avoiding the best solution to your problem. I thought you were trying to avoid under the hood bloat of
set. \$\endgroup\$Budd– Budd2019年12月06日 01:46:37 +00:00Commented Dec 6, 2019 at 1:46 -
\$\begingroup\$ @kyrill the answer you contributed is essentially a more abstract and less efficient implementation (due to doing O(n) lookups instead of hashes) of the above. \$\endgroup\$Budd– Budd2019年12月06日 01:48:46 +00:00Commented Dec 6, 2019 at 1:48
-
\$\begingroup\$ What I was interested in, is to avoid creating a
setif I already have a (possibly huge)list. I have no comment on your second comment... \$\endgroup\$kyrill– kyrill2019年12月06日 01:50:58 +00:00Commented Dec 6, 2019 at 1:50 -
1\$\begingroup\$ I misremembered revisions up to 3. \$\endgroup\$greybeard– greybeard2019年12月06日 05:39:40 +00:00Commented Dec 6, 2019 at 5:39
Explore related questions
See similar questions with these tags.
setordictand maintain runtime of O(n+m). So what's the reason behind not using them? Is it to not use extra space? \$\endgroup\$setordict, such as maintaining sortedness (although this one could be solved easily by something likefilter(x, set(y))). Besides, I wanted to see a more elegant way to write this specific function (without sets), since I found the original code too much like C/C++/etc.; too unpythonic. \$\endgroup\$