I have been looking for answers for how to easily scrape data from Wikipedia into a CSV file with Beautiful Soup. This is the code so far. Is there an easier way to do it?
import urllib.request
from bs4 import BeautifulSoup
import csv
#the websites
urls = ['https://en.wikipedia.org/wiki/Transistor_count']
data =[]
#getting the websites and the data
for url in urls:
## my_url = requests.get(url)
my_url = urllib.request.urlopen(url)
html = my_url.read()
soup = BeautifulSoup(html,'html.parser')
My_table = soup.find('table',{'class':'wikitable sortable'})
My_second_table = My_table.find_next_sibling('table')
with open('data.csv', 'w',encoding='UTF-8', newline='') as f:
fields = ['Title', 'Year']
writer = csv.writer(f, delimiter=',')
writer.writerow(fields)
with open('data.csv', "a", encoding='UTF-8') as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for tr in My_table.find_all('tr')[2:]: # [2:] is to skip empty and header
tds = tr.find_all('td')
try:
title = tds[0].text.replace('\n','')
except:
title = ""
try:
year = tds[2].text.replace('\n','')
except:
year = ""
writer.writerow([title, year])
with open('data.csv', "a", encoding='UTF-8') as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for tr in My_second_table.find_all('tr')[2:]: # [2:] is to skip empty and header
tds = tr.find_all('td')
row = "{}, {}".format(tds[0].text.replace('\n',''), tds[2].text.replace('\n',''))
writer.writerow(row.split(','))
-
3\$\begingroup\$ @AlexV I was suggested to post here by a user on stackoverflow. I only posted here because they told me to after posting on stackoverflow. My code is working but not the way I want. However the issue has been solved so if you want you can remove this post. Thank you anyway. \$\endgroup\$Sofelia– Sofelia2019年09月13日 13:22:45 +00:00Commented Sep 13, 2019 at 13:22
-
4\$\begingroup\$ You can also fix the issue in the post, reword the question and leave your code for an actual review. \$\endgroup\$AlexV– AlexV2019年09月13日 13:24:08 +00:00Commented Sep 13, 2019 at 13:24
-
4\$\begingroup\$ @AlexV , Thank you, I reworded it, however I do not know if I need it anymore but I guess it is always nice to get your code reviewed. \$\endgroup\$Sofelia– Sofelia2019年09月13日 13:27:47 +00:00Commented Sep 13, 2019 at 13:27
-
3\$\begingroup\$ In general, when I want a table from a web page, I select it with my mouse, paste \$\endgroup\$WGroleau– WGroleau2019年09月15日 22:45:28 +00:00Commented Sep 15, 2019 at 22:45
-
\$\begingroup\$ stackoverflow.com/questions/41510383/… \$\endgroup\$Vishesh Mangla– Vishesh Mangla2020年07月03日 07:48:55 +00:00Commented Jul 3, 2020 at 7:48
6 Answers 6
Is there a way to simplify this code?
Yes. Don't scrape Wikipedia. Your first thought before "should I need to scrape this thing?" should be "Is there an API that can give me the data I want?" In this case, there super is.
There are many informative links such as this StackOverflow question, but in the end reading the API documentation really is the right thing to do. This should get you started:
from pprint import pprint
import requests, wikitextparser
r = requests.get(
'https://en.wikipedia.org/w/api.php',
params={
'action': 'query',
'titles': 'Transistor_count',
'prop': 'revisions',
'rvprop': 'content',
'format': 'json',
}
)
r.raise_for_status()
pages = r.json()['query']['pages']
body = next(iter(pages.values()))['revisions'][0]['*']
doc = wikitextparser.parse(body)
print(f'{len(doc.tables)} tables retrieved')
pprint(doc.tables[0].data())
This may seem more roundabout than scraping the page, but API access gets you structured data, which bypasses an HTML rendering step that you shouldn't have to deal with. This structured data is the actual source of the article and is more reliable.
-
5\$\begingroup\$ At the end of the day, you still have to parse the wikitext. It's not clear to me why that's really better/easier than parsing HTML - they're just two different markup formats. If Wikipedia had an actual semantic API just for extracting data from tables in articles, that would be different. \$\endgroup\$Jack M– Jack M2019年09月15日 11:04:45 +00:00Commented Sep 15, 2019 at 11:04
-
3\$\begingroup\$ @JackM - given the readily-available choices: let MediaWiki render to a format intended for browser representation to a human, or let MediaWiki return structured data intended for consumption by either humans or computers, I would choose the latter every time for this kind of application. Not all markup formats are made equal, and here intent is important. It's entirely possible for MediaWiki to change its rendering engine, still returning visually valid web content but breaking all scrapers that make assumptions about HTML. \$\endgroup\$Reinderien– Reinderien2019年09月15日 13:53:21 +00:00Commented Sep 15, 2019 at 13:53
-
5\$\begingroup\$ You make some good points. For this application however (a one-off script), parsing the HTML is as good, and it avoids having to spend time learning a new technology and a new tool (wikitext and the wikitext parsing library). Basically, even being presumably more experienced than OP, in their shoes I probably would have chosen to do the same thing in this case, although your general point that you should always look for an API before you try scraping is definitely a lesson they should take on-board. \$\endgroup\$Jack M– Jack M2019年09月15日 13:58:20 +00:00Commented Sep 15, 2019 at 13:58
-
\$\begingroup\$ @JackM the scraper would break if the page's UI was updated, so it's a less useful approach if the script is going to be re-run at any point in the future. APIs on the other hand, are often versioned, and tend to change less often than HTML \$\endgroup\$touch my body– touch my body2019年09月16日 18:22:09 +00:00Commented Sep 16, 2019 at 18:22
-
\$\begingroup\$ Interesting, came across this today and currently doing exactly the opposite. Mostly cause the API is jank and I don't really want to waste time learning it for a 1 off... \$\endgroup\$2020年05月07日 23:03:44 +00:00Commented May 7, 2020 at 23:03
Let me tell you about IMPORTHTML()...
So here's all the code you need in Google Sheets:
=IMPORTHTML("https://en.wikipedia.org/wiki/Transistor_count", "table", 2)
The import seems to work fine: enter image description here
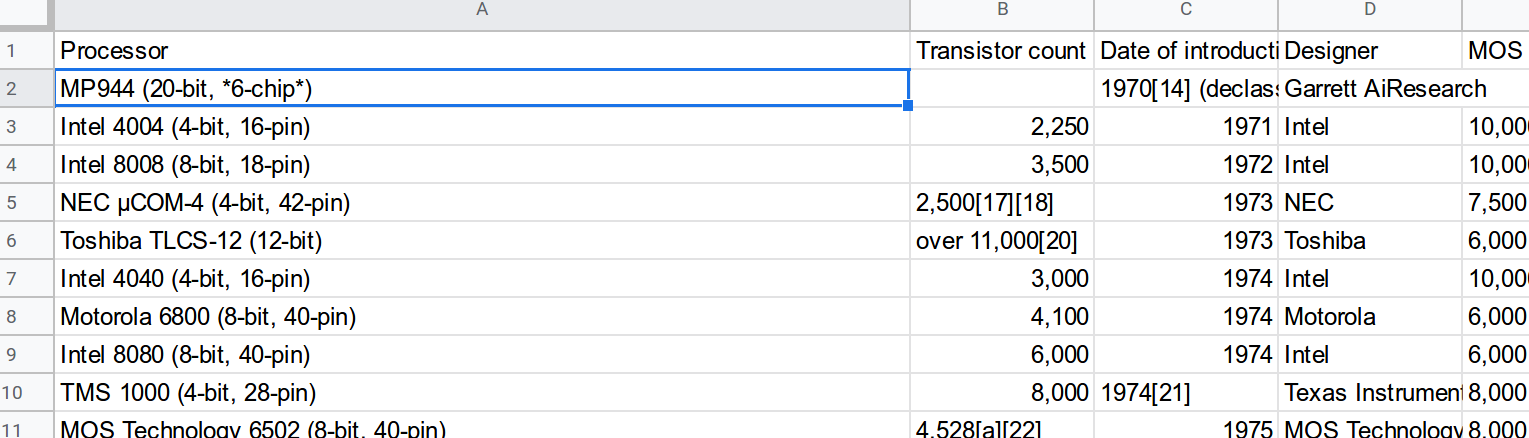{kind=link}
And it's possible to download the table as CSV:
Processor,Transistor count,Date of introduction,Designer,MOS process,Area
"MP944 (20-bit, *6-chip*)",,1970[14] (declassified 1998),Garrett AiResearch,,
"Intel 4004 (4-bit, 16-pin)","2,250",1971,Intel,"10,000 nm",12 mm2
"Intel 8008 (8-bit, 18-pin)","3,500",1972,Intel,"10,000 nm",14 mm2
"NEC μCOM-4 (4-bit, 42-pin)","2,500[17][18]",1973,NEC,"7,500 nm[19]",*?*
Toshiba TLCS-12 (12-bit),"over 11,000[20]",1973,Toshiba,"6,000 nm",32 mm2
"Intel 4040 (4-bit, 16-pin)","3,000",1974,Intel,"10,000 nm",12 mm2
"Motorola 6800 (8-bit, 40-pin)","4,100",1974,Motorola,"6,000 nm",16 mm2
...
...
You'll just need to clean the numbers up, which you'd have to do anyway with the API or by scraping with BeautifulSoup.
-
7\$\begingroup\$ Copy/pasting the raw text into a spreadsheet (in my case, into Numbers.app) automatically picked up the tabular formatting perfectly. Done. \$\endgroup\$Alexander– Alexander2019年09月14日 00:09:06 +00:00Commented Sep 14, 2019 at 0:09
-
8\$\begingroup\$ That's seriously spooky. \$\endgroup\$Volker Siegel– Volker Siegel2019年09月15日 05:27:42 +00:00Commented Sep 15, 2019 at 5:27
-
21\$\begingroup\$ @VolkerSiegel: It looks like Google knows a thing or two about scraping data from websites. :D \$\endgroup\$Eric Duminil– Eric Duminil2019年09月15日 08:49:23 +00:00Commented Sep 15, 2019 at 8:49
Make sure to follow naming conventions. You name two variables inappropriately:
My_table = soup.find('table',{'class':'wikitable sortable'})
My_second_table = My_table.find_next_sibling('table')
Those are just normal variables, not class names, so they should be lower-case:
my_table = soup.find('table',{'class':'wikitable sortable'})
my_second_table = my_table.find_next_sibling('table')
Twice you do
try:
title = tds[0].text.replace('\n','')
except:
title = ""
I'd specify what exact exception you want to catch so you don't accidentally hide a "real" error if you start making changes in the future. I'm assuming here you're intending to catch an
AttributeError.Because you have essentially the same code twice, and because the code is bulky, I'd factor that out into its own function.
Something like:
import bs4
def eliminate_newlines(tag: bs4.element.Tag) -> str: # Maybe pick a better name
try:
return tag.text.replace('\n', '')
except AttributeError: # I'm assuming this is what you intend to catch
return ""
Now that with open block is much neater:
with open('data.csv', "a", encoding='UTF-8') as csv_file:
writer = csv.writer(csv_file, delimiter=',')
for tr in My_table.find_all('tr')[2:]: # [2:] is to skip empty and header
tds = tr.find_all('td')
title = eliminate_newlines(tds[0])
year = eliminate_newlines(tds[2])
writer.writerow([title, year])
Edit: I was in the shower, and realized that you're actually probably intending to catch an IndexError in case the page is malformed or something. Same idea though, move that code out into a function to reduce duplication. Something like:
from typing import List
def eliminate_newlines(tags: List[bs4.element.Tag], i: int) -> str:
return tags[i].text.replace('\n', '') if len(tags) < i else ""
This could also be done using a condition statement instead of expression. I figured that it's pretty simple though, so a one-liner should be fine.
If you're using a newer version of Python, lines like:
"{}, {}".format(tds[0].text.replace('\n',''), tds[2].text.replace('\n',''))
Can make use of f-strings to do in-place string interpolation:
f"{tds[0].text.replace('\n', '')}, {tds[2].text.replace('\n', '')}"
In this particular case, the gain isn't much. They're very helpful for more complicated formatting though.
Using the Wikipedia API
As mentioned in another answer, Wikipedia provides an HTTP API for fetching article content, and you can use it to get the content in much cleaner formats than HTML. Often this is much better (for example, it's a much better choice for this little project I wrote that extracts the first sentence of a Wikipedia article).
However, in your case, you have to parse tables anyway. Whether you're parsing them from HTML or from the Wikipedia API's "wikitext" format, I don't think there's much of a difference. So I consider this subjective.
Using requests, not urllib
Never use urllib, unless you're in an environment where for some reason you can't install external libraries. The requests library is preferred for fetching HTML.
In your case, to get the HTML, the code would be:
html = requests.get(url).text
with an import requests up-top. For your simple example, this isn't actually any easier, but it's just a general best-practice with Python programming to always use requests, not urllib. It's the preferred library.
What's with all those with blocks?
You don't need three with blocks. When I glance at this code, three with blocks make it seem like the code is doing something much more complicated than it actually is - it makes it seem like maybe you're writing multiple CSVs, which you aren't. Just use one, it works the same:
with open('data.csv', 'w',encoding='UTF-8', newline='') as f:
fields = ['Title', 'Year']
writer = csv.writer(f, delimiter=',')
writer.writerow(fields)
for tr in My_table.find_all('tr')[2:]: # [2:] is to skip empty and header
tds = tr.find_all('td')
try:
title = tds[0].text.replace('\n','')
except:
title = ""
try:
year = tds[2].text.replace('\n','')
except:
year = ""
writer.writerow([title, year])
for tr in My_second_table.find_all('tr')[2:]: # [2:] is to skip empty and header
tds = tr.find_all('td')
row = "{}, {}".format(tds[0].text.replace('\n',''), tds[2].text.replace('\n',''))
writer.writerow(row.split(','))
Are those two tables really that different?
You have two for loops, each one processing a table and writing it to the CSV. The body of the two for loops is different, so at a glance it looks like maybe the two tables have a different format or something... but they don't. You can copy paste the body of the first for loop into the second and it works the same:
for tr in My_table.find_all('tr')[2:]: # [2:] is to skip empty and header
tds = tr.find_all('td')
try:
title = tds[0].text.replace('\n','')
except:
title = ""
try:
year = tds[2].text.replace('\n','')
except:
year = ""
writer.writerow([title, year])
for tr in My_second_table.find_all('tr')[2:]: # [2:] is to skip empty and header
tds = tr.find_all('td')
try:
title = tds[0].text.replace('\n','')
except:
title = ""
try:
year = tds[2].text.replace('\n','')
except:
year = ""
With the above code, the only difference to the resulting CSV is that there aren't spaces after the commas, which I assume is not really important to you. Now that we've established the code doesn't need to be different in the two loops, we can just do this:
table_rows = My_table.find_all('tr')[2:] + My_second_table.find_all('tr')[2:]
for tr in table_rows:
tds = tr.find_all('td')
try:
title = tds[0].text.replace('\n','')
except:
title = ""
try:
year = tds[2].text.replace('\n','')
except:
year = ""
writer.writerow([title, year])
Only one for loop. Much easier to understand!
Parsing strings by hand
So that second loop doesn't need to be there at all, but let's look at the code inside of it anyway:
row = "{}, {}".format(tds[0].text.replace('\n',''), tds[2].text.replace('\n',''))
writer.writerow(row.split(','))
Um... you just concatenated two strings together with a comma, just to call split and split them apart at the comma at the very next line. I'm sure now it's pointed out to you you can see this is pointless, but I want to pull you up on one other thing in these two lines of code.
You are essentially trying to parse data by hand with that row.split, which is always dangerous. This is an important and general lesson about programming. What if the name of the chip had a comma in it? Then row would contain more commas than just the one that you put in there, and your call to writerow would end up inserting more than two columns!
Never parse data by hand unless you absolutely have to, and never write data in formats like CSV or JSON by hand unless you absolutely have to. Always use a library, because there are always pathological edge cases like a comma in the chip name that you won't think of and which will break your code. The libraries, if they're been around for a while, have had those bugs ironed out. With these two lines:
row = "{}, {}".format(tds[0].text.replace('\n',''), tds[2].text.replace('\n',''))
writer.writerow(row.split(','))
you are attempting to split a table row into its two columns yourself, by hand, which is why you made a mistake (just like anyone would). Whereas in the first loop, the code which does this splitting are the two lines:
title = tds[0].text.replace('\n','')
year = tds[2].text.replace('\n','')
Here you are relying on BeautifulSoup to have split the columns cleanly into tds[0] and tds[2], which is much safer and is why this code is much better.
Mixing of input parsing and output generating
The code that parses the HTML is mixed together with the code that generates the CSV. This is poor breaking of a problem down into sub-problems. The code that writes the CSV should just be thinking in terms of titles and years, it shouldn't have to know that they come from HTML, and the code that parses the HTML should just be solving the problem of extracting the titles and years, it should have no idea that that data is going to be written to a CSV. In other words, I want that for loop that writes the CSV to look like this:
for (title, year) in rows:
writer.writerow([title, year])
We can do this by rewriting the with block like this:
with open('data.csv', 'w',encoding='UTF-8', newline='') as f:
fields = ['Title', 'Year']
writer = csv.writer(f, delimiter=',')
writer.writerow(fields)
table_rows = My_table.find_all('tr')[2:] + My_second_table.find_all('tr')[2:]
parsed_rows = []
for tr in table_rows:
tds = tr.find_all('td')
try:
title = tds[0].text.replace('\n','')
except:
title = ""
try:
year = tds[2].text.replace('\n','')
except:
year = ""
parsed_rows.append((title, year))
for (title, year) in parsed_rows:
writer.writerow([title, year])
Factoring into functions
To make the code more readable and really separate the HTML stuff from the CSV stuff, we can break the script into functions. Here's my complete script.
import requests
from bs4 import BeautifulSoup
import csv
urls = ['https://en.wikipedia.org/wiki/Transistor_count']
data = []
def get_rows(html):
soup = BeautifulSoup(html,'html.parser')
My_table = soup.find('table',{'class':'wikitable sortable'})
My_second_table = My_table.find_next_sibling('table')
table_rows = My_table.find_all('tr')[2:] + My_second_table.find_all('tr')[2:]
parsed_rows = []
for tr in table_rows:
tds = tr.find_all('td')
try:
title = tds[0].text.replace('\n','')
except:
title = ""
try:
year = tds[2].text.replace('\n','')
except:
year = ""
parsed_rows.append((title, year))
return parsed_rows
for url in urls:
html = requests.get(url).text
parsed_rows = get_rows(html)
with open('data.csv', 'w',encoding='UTF-8', newline='') as f:
fields = ['Title', 'Year']
writer = csv.writer(f, delimiter=',')
writer.writerow(fields)
for (title, year) in parsed_rows:
writer.writerow([title, year])
What would be even better would be for get_rows to be a generator rather than a regular function, but that's advanced Python programming. This is fine for now.
-
\$\begingroup\$ "In Python 3 the
requestslibrary comes built-in..." It does not, unfortunately. But you can easily install it usingpip install requests. \$\endgroup\$grooveplex– grooveplex2019年09月15日 17:46:39 +00:00Commented Sep 15, 2019 at 17:46 -
\$\begingroup\$ @grooveplex Oh, maybe it just comes with Ubuntu? I don't think I've had to install
requestsin recent memory. \$\endgroup\$Jack M– Jack M2019年09月15日 19:10:07 +00:00Commented Sep 15, 2019 at 19:10
A little late to the party, but how about pandas? The read_csv method returns a list of all the tabels on the page as dataframes. Note that the table of interest is at index position 1. You probably want to do some cleaning up of the data, but this should get you started.
import pandas as pd
tables = pd.read_html("https://en.wikipedia.org/wiki/Transistor_count")
tables[1].to_csv('data.csv', index=False)
The CSV file:
Processor,MOS transistor count,Date ofintroduction,Designer,MOS process(nm),Area (mm2),Unnamed: 6
"MP944 (20-bit, 6-chip, 28 chips total)","74,442 (5,360 excl. ROM & RAM)[23][24]",1970[21][a],Garrett AiResearch,?,?,
"Intel 4004 (4-bit, 16-pin)",2250,1971,Intel,"10,000 nm",12 mm2,
"TMX 1795 (?-bit, 24-pin)","3,078[25]",1971,Texas Instruments,?,30 mm2,
"Intel 8008 (8-bit, 18-pin)",3500,1972,Intel,"10,000 nm",14 mm2,
"NEC μCOM-4 (4-bit, 42-pin)","2,500[26][27]",1973,NEC,"7,500 nm[28]",?,
Documentation: pandas.read_csv
When you asked for an easier way, do you mean an easier way that uses "real code" as in the cartoon?
That looks pretty easy, but I think slightly easier is possible.
In general, when I want a table from a web page, I select it with my mouse and paste special (unformatted) into a spreadsheet. Bonus is that I don’t have to deal with NSA’s biggest competitor (Google).
-
\$\begingroup\$ Why the downvotes? This is absolutely the easiest way to get a single table without much fuss. One has to clean the tables up in any case, which will usually require some manual checking. After repeating this a few times, then feel free to automate it, but don't automate from the very start.
Premature optimisation is the root of all evil - Knuth. \$\endgroup\$Contango– Contango2020年01月11日 09:18:00 +00:00Commented Jan 11, 2020 at 9:18