I have rewritten my python code in cython in order to speed up it quite a bit. However after checking the code in jupyter it seems that part of it is still compiled as python code, therefore its not being sped up enough.
My function is pretty basic, it gets start date, end date and creates array of additional dates based on that and some other conditions.
The thing is I’m a bit clueless how could I change the highlighted yellow part of code of the date_range_np function as seen on the attached imaged. Because I’m already using numpy arrays so I thought it would be compiled as cython code. There is also one loop that I think is slowing down the function but so far I wasn’t able to come up with any replacement that sginificatly sped up the function. Actually speed is very important as those functions are executed thousands of times.
Any ideas how could I refactor it to speed it up?
Here is my code:
%%cython -a
import numpy as np
cimport numpy as np
from datetime import datetime
cpdef np.int64_t get_days(np.int64_t year, np.int64_t month):
cdef np.ndarray months=np.array([31,28,31,30,31,30,31,31,30,31,30,31])
if month==2:
if (year%4==0 and year%100!=0) or (year%400==0):
return 29
return months[month-1]
cpdef np.ndarray[np.int64_t] date_range_np(np.int64_t start, np.int64_t end, char* freq):
cdef np.ndarray res
cdef np.int64_t m_start
cdef np.int64_t m_end
if freq.decode("utf-8")[len(freq)-1] == "M":
m_start = np.int64(start).astype('M8[D]').astype('M8[M]').view("int64")
m_end = np.int64(end).astype('M8[D]').astype('M8[M]').view("int64")
res = np.arange(m_start, m_end-2, np.int64(freq[:(len(freq)-1)])).view("M8[M]").astype("M8[D]").view("int64")
return np.array([np.min([x+datetime.fromtimestamp(start*24*60*60).day-1, x+get_days(datetime.fromtimestamp(start*24*60*60).year,datetime.fromtimestamp(start*24*60*60).month)]) for x in res])
elif freq.decode("utf-8")[len(freq)-1] == "D":
return np.arange(start, end-2, np.int64(freq[:(len(freq)-1)]))
cpdef np.ndarray[np.int64_t] loanDates(np.int64_t startDate,np.int64_t endDate,np.int64_t freq):
# if frequency indicates repayment every n months
if int(12 / freq) == 12 / freq:
# Generate date range and add offset depending on starting day
#print(date_range_np(start=startDate, end=endDate, freq=(str(-int(12 / freq)) + "M").encode("utf8")))
ts = date_range_np(start=startDate, end=endDate, freq=(str(-int(12 / freq)) + "M").encode("utf8"))
else:
ts = date_range_np(start=startDate, end=endDate, freq=(str(-int(365 / freq)) + "D").enocode("utf8"))
#print(ts)
if ts.shape[0] == 0:
return np.array([])
elif ts.shape[0] >= 1 and ts[0] > startDate:
ts = np.delete(arr=ts, obj=0)
if ts[ts.shape[0]-1] < endDate:
ts = np.delete(arr=ts, obj=-1)
if ts[0] != startDate:
ts = np.insert(ts,0,startDate)
# If no dates generated (start date>end date)
ts = ts
# If last date generated is not end date add it
return ts.astype('int64')
And the function highlighted:
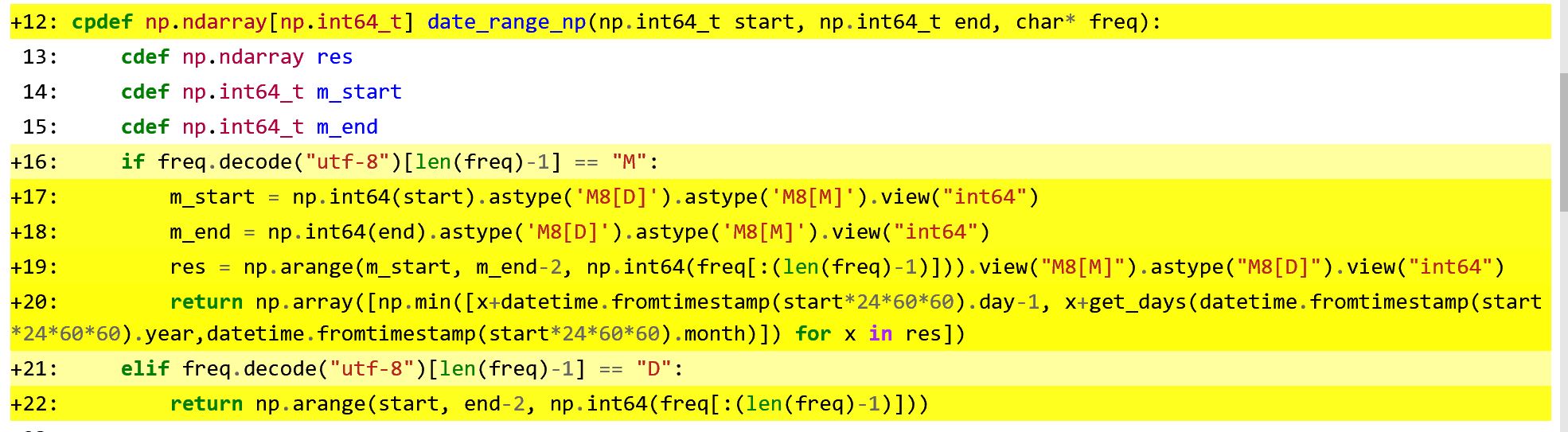{kind=link}
If you want to test the functions you can try:
%timeit date_range_np(20809,17986, b"-1M")
I get about 1ms for that function.
1 Answer 1
I'm sorry, but this code is really hard to read. I must admit I don't know Cython too well, so I won't be able to comment too much on that part. But anyways, here are a few comments, in random order.
While Cython does not fully support docstrings (they do not show up in the interactive
help), this should not prevent you from adding some to explain what the different functions do and what arguments they take.You seem to be doing
np.int64(start).astype('M8[D]').astype('M8[M]').view("int64")quite a lot. As far as I can tell, this extracts the month from a date, which was given as an integer(?). There is quite possibly a better way to do that (using the functions indatetime), but they might be slower. Nevertheless, you should put this into its own function.You do
freq.decode("utf-8")[len(freq)-1]twice. Do it once and save it to a variable. Also,freq[len(freq)-1]should be the same asfreq[-1]andfreq[:len(freq)-1]the same asfreq[:-1]. This is especially costly aslen(freq)is \$\mathcal{O}(n)\$ forchar *, in Cython.You create
datetime.fromtimestamp(start*24*60*60)three times, once each to get the day, month and year. Save it to a variable and reuse it.The last two comments in
loanDatesseem not to be true anymore:# If no dates generated (start date>end date) ts = ts # If last date generated is not end date add it return ts.astype('int64')- The documentation seems to recommend against using C strings, unless you really need them. If I read the documentation correctly you could just make the type of
freqstrand get rid of all yourencode("utf-8")anddecode("utf-8")code. The definition of the
monthsarray is done every time the functionget_daysis called. In normal Python I would recommend making it a global constant, here you would have to try and see if it makes the runtime worse.Python has an official style-guide, PEP8. Since Cython is only an extension, it presumably also applies here. It recommends surrounding operators with whitespace (
freq[len(freq) - 1]), usinglower_casefor all function and variable names and limiting your linelength (to 80 characters by default, but 120 is also an acceptable choice).
In the end, taking 1ms to create a date range is already quite fast. As you said this is already faster than pandas.daterange (which does a lot of parsing of the input first, which you avoid by passing in numbers directly). You might be able to push it down to microseconds, but you should ask yourself if and why you need this many dateranges per second.
-
1\$\begingroup\$ Thanks for the reply. Are the points 2 and 4 suggested to save time or more to make the code more readable? \$\endgroup\$Alex T– Alex T2019年08月20日 17:35:04 +00:00Commented Aug 20, 2019 at 17:35
-
\$\begingroup\$ @AlexT Both! Although there is a small function overhead, it will probably be less than doing the computation twice (especially since it involves multiple attribute lookups). But when in doubt, measure it! \$\endgroup\$Graipher– Graipher2019年08月20日 17:42:27 +00:00Commented Aug 20, 2019 at 17:42
Explore related questions
See similar questions with these tags.
pandas.date_range? \$\endgroup\$