Im relatively new in python. I've wrote my "first" script to do some staff for me. I am creating Image dataset for Mashine Lerning. In Photoshop, I select the area I need in the large image and using the Photoshop script I save the selected area to a folder tree_checker. I have different scripts configured in Photoshop, each script saves a file with a specific name. This script takes every new file in directory and moves it in depending directory.
"""
This script provides automatically file ordering.
"""
import os
import time
def get_dir_length(path):
"""
Returns the length of given directory e.g the amount of files inside the folder.
"""
return len([f for f in os.listdir(path)if os.path.isfile(os.path.join(path, f))])
ORC_MALE = 'orc_male.jpg'
ORC_MALE_MAG = 'orc_male_mag.jpg'
ORC_FEMALE = 'orc_female.jpg'
DARKELF_MALE = 'darkelf_male.jpg'
DARKELF_FEMALE = 'darkelf_female.jpg'
HUMAN_MALE = 'human_male.jpg'
HUMAN_MALE_MAG = 'human_male_mag.jpg'
HUMAN_FEMALE = 'human_female.jpg'
ELF_MALE = 'elf_male.jpg'
ELF_FEMALE = 'elf_female.jpg'
DWARF_MALE = 'dwarf_male.jpg'
DWARF_FEMALE = 'dwarf_female.jpg'
PATH_TO_WATCH = './tf_models/tree_checker/'
BEFORE = dict([(f, None) for f in os.listdir(PATH_TO_WATCH)])
COUNT_AMOUNT_OF_FILE_MOVE = 0
try:
while 1:
time.sleep(1)
AFTER = dict([(f, None) for f in os.listdir(PATH_TO_WATCH)])
ADDED = [f for f in AFTER if not f in BEFORE]
REMOVED = [f for f in BEFORE if not f in AFTER]
if ADDED:
if ''.join(ADDED) == ORC_MALE:
DIR_LEN = get_dir_length('./tf_models/orc_male/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/orc_male/orc_male_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/orc_male/orc_male_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == ORC_MALE_MAG:
DIR_LEN = get_dir_length('./tf_models/orc_male_mag/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/orc_male_mag/orc_male_mag_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/orc_male_mag/orc_male_mag_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == ORC_FEMALE:
DIR_LEN = get_dir_length('./tf_models/orc_female/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/orc_female/orc_male_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/orc_female/orc_male_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == DARKELF_MALE:
DIR_LEN = get_dir_length('./tf_models/darkelf_male/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/darkelf_male/darkelf_male_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/darkelf_male/darkelf_male_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == DARKELF_FEMALE:
DIR_LEN = get_dir_length('./tf_models/darkelf_female/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/darkelf_female/darkelf_female_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/darkelf_female/darkelf_female_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == HUMAN_MALE:
DIR_LEN = get_dir_length('./tf_models/human_male/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/human_male/human_male_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/human_male/human_male_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == HUMAN_MALE_MAG:
DIR_LEN = get_dir_length('./tf_models/human_male_mag/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/human_male_mag/human_male_mag_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/human_male_mag/human_male_mag_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == HUMAN_FEMALE:
DIR_LEN = get_dir_length('./tf_models/human_female/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/human_female/human_female_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/human_female/human_female_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == ELF_MALE:
DIR_LEN = get_dir_length('./tf_models/elf_male/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/elf_male/elf_male_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/elf_male/elf_male_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == ELF_FEMALE:
DIR_LEN = get_dir_length('./tf_models/elf_female/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/elf_female/elf_female_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/elf_female/elf_female_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == DWARF_MALE:
DIR_LEN = get_dir_length('./tf_models/dwarf_male/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/dwarf_male/dwarf_male_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/dwarf_male/dwarf_male_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
if ''.join(ADDED) == DWARF_FEMALE:
DIR_LEN = get_dir_length('./tf_models/dwarf_female/')
try:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/dwarf_female/dwarf_female_' + str(DIR_LEN+1) + '.jpg'))
except FileExistsError:
os.rename((PATH_TO_WATCH + ''.join(ADDED)), \
('./tf_models/dwarf_female/dwarf_female_' + str(DIR_LEN+1) + 'a.jpg'))
COUNT_AMOUNT_OF_FILE_MOVE += 1
BEFORE = AFTER
if (COUNT_AMOUNT_OF_FILE_MOVE % 10 == 0 and COUNT_AMOUNT_OF_FILE_MOVE > 0):
print('Currently moved ' + str(COUNT_AMOUNT_OF_FILE_MOVE) + \
' files. - ' + str(time.clock))
except KeyboardInterrupt:
print(COUNT_AMOUNT_OF_FILE_MOVE)
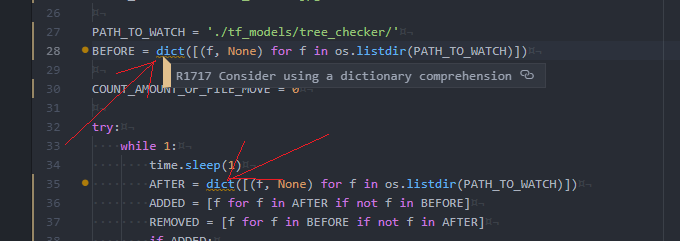
Some of place wich could be refactored is
"using a dictionary comprehension"
as my pylint says. But I don't know how to du that. Also Pylint says that is will be faster if I do refactor here. enter image description here
{kind=link}
consider-using-dict-comprehension (R1717): Consider using a dictionary comprehension Although there is nothing syntactically wrong with this code, it is hard to read and can be simplified to a dict comprehension.Also it is faster since you don't need to create another transient list
What does this code do?
Folders tree:
Project
|-elf_male
|-elf_female
|-darkelf_male
|-darkelf_female
|-dwarf_male
|-dwarf_female
|-human_male
|-human_male_mag
|-human_female
|-orc_male
|-orc_male_mag
|-orc_female
`-tree_checker
In general this script continuously watching if there is a new image in folder tree_checker as soon as there is new image (images in this folder you have to put manually) script checks the name of the image (e.g orc_male.jpg, orc_male_mag.jpg, orc_female.jpg etc) and moves the image to the folder according to the name of the image.
This script is actually quite slow. If you too quickly insert few images into the tree_checker folder, it breaks.
2 Answers 2
Some of place wich could be refactored is
"using a dictionary comprehension"
as my pylint says. But I don't know how to du that.
Let's start with that as this is the least of this code problems. A dictionary comprehension is roughly like a list-comprehension (that you know of and use well) except:
- it produces a dictionary instead of a list;
- it uses braces instead of brackets;
- it uses a
key: valuetoken instead of a single element in front of theforkeyword.
BEFORE = {f: None for f in os.listdir(PATH_TO_WATCH)}
But since you’re not changing the value, you can use dict.fromkeys:
BEFORE = dict.fromkeys(os.listdir(PATH_TO_WATCH))
However, you never make use of the values of the dictionary anyway. So keep it simple and use sets instead. This even let you compute additions and suppressions ways more easily:
after = set(os.listdir(PATH_TO_WATCH))
added = after - before
removed = before - after
Now, onto your real problem: this code repeats exactly the same instructions for each of your subfolders! This less than optimal. Instead, write a function that operate on the folder name. It would also be a good idea to list these destination folders automatically instead of hardcoding their names.
Also your usage of ''.join(ADDED) is problematic: if you ever add more than one file every second in the folder you monitor, you will end up with a name that can't be matched againts anything:
>>> added = ['human_male.jpg', 'elf_female.jpg']
>>> ''.join(added)
human_male.jpgelf_female.jpg
Instead you should loop over ADDED and check if the file names match either of the destination folder.
Your check for existing file may help catch some overwrite errors, but what if the second filename also already exist? If you want to properly handle such cases, you should try in a loop with increasing attempts to write the new file.
Lastly, try to separate computation from presentation. Make this a reusable function and move your prints outside of there, into a main part:
#! /usr/bin/env python3
"""This script provides automatic file ordering.
"""
import os
import time
import pathlib
from itertools import count
def get_dir_length(path):
"""Return the amount of files inside a folder"""
return sum(1 for f in path.iterdir() if f.is_file())
def monitor_folder(path):
path = pathlib.Path(path).absolute()
destinations = {f.name for f in path.parent.iterdir() if f.is_dir()}
destinations.remove(path.name)
content = {f.name for f in path.iterdir()}
while True:
time.sleep(1)
current = {f.name for f in path.iterdir()}
added = current - content
# removed = content - current
for filename in added:
name, suffix = os.path.splitext(filename)
if suffix != '.jpg':
continue
if name in destinations:
size = get_dir_length(path.parent / name)
new_name = '{}_{}.jpg'.format(name, size)
for attempt in count():
try:
os.rename(str(path / filename), str(path.parent / name / new_name))
except FileExistsError:
new_name = '{}_{}({}).jpg'.format(name, size, attempt)
else:
break
yield filename, new_name
content = current
def main(folder_to_watch):
files_moved = 0
try:
for _ in monitor_folder(folder_to_watch):
files_moved += 1
if files_moved % 10 == 0:
print('Currently moved', files_moved, 'files. −', time.process_time())
except KeyboardInterrupt:
print('End of script, moved', files_moved, 'files.')
if __name__ == '__main__':
main('./tf_models/tree_checker/')
-
\$\begingroup\$ Thanks! Works like a charm! Is there a way to check performance of the script to show which of two answers works faster? \$\endgroup\$khashashin– khashashin2019年02月25日 20:01:12 +00:00Commented Feb 25, 2019 at 20:01
-
\$\begingroup\$ @khashashin
timeitand/orcProfile. \$\endgroup\$301_Moved_Permanently– 301_Moved_Permanently2019年02月25日 20:06:29 +00:00Commented Feb 25, 2019 at 20:06
Warning: I did not run your code, and the revised version is not tested.
- Get familiar with PEP 8 style guide. You violate some of its points, like maximum line length and naming conventions (upper case is for constants).
- Use pathlib over
os. It has many nice features that will make your life easier. You use dicts incorrectly in lines like this one:
BEFORE = dict([(f, None) for f in os.listdir(PATH_TO_WATCH)])There is no point in having the pairs of "file"-
Noneand never update the values. Probably, you meant to use sets instead.while 1:should bewhile True:.Don't repeat yourself. The code following after
if ADDED:line has code blocks with the same logic over and over again. Consider putting all thoseORC_MALE,ORC_MALE_MAG, etc. in a set, and check if an added file is in that set. If it is, you move the file from one location to another where the path names of both locations can be constructed from the names in the initial set.Don't repeat yourself again. In those lines where you create new names of the files that are going to be moved, you repeat the code in
tryandexcept FileExistsError:clauses:try: os.rename((PATH_TO_WATCH + ''.join(ADDED)), \ ('./tf_models/orc_male/orc_male_' + str(DIR_LEN+1) + '.jpg')) except FileExistsError: os.rename((PATH_TO_WATCH + ''.join(ADDED)), \ ('./tf_models/orc_male/orc_male_' + str(DIR_LEN+1) + 'a.jpg'))Take the common logic out.
Split the logic into smaller functions. Now you have a huge block of code that does too many things.
Make use of f-strings
Revised code:
"""This script provides automatically file ordering."""
import time
from pathlib import Path
from typing import (Any,
Iterable,
Iterator,
Set)
IMAGES_PATHS = {'orc_male.jpg',
'orc_male_mag.jpg',
'orc_female.jpg',
'darkelf_male.jpg',
'darkelf_female.jpg',
'human_male.jpg',
'human_male_mag.jpg',
'human_female.jpg',
'elf_male.jpg',
'elf_female.jpg',
'dwarf_male.jpg',
'dwarf_female.jpg'}
PATH_TO_WATCH = Path('tf_models', 'tree_checker')
def run_transfer(path: Path,
*,
sleep_time: int = 1,
check_against: Set[str]) -> None:
"""TODO: add docstring"""
files_before = set(path.iterdir())
moved_files_count = 0
try:
while True:
time.sleep(sleep_time)
files_after = set(path.iterdir())
added_files = files_after - files_before
for added_file in added_files:
if added_file.stem in check_against:
transfer_file(added_file)
moved_files_count += len(added_files)
files_before = files_after
if moved_files_count % 10 == 0 and moved_files_count > 0:
print(f'Currently moved {str(moved_files_count)} files. '
f'- {str(time.clock)}')
except KeyboardInterrupt:
print(moved_files_count)
def transfer_file(file: Path) -> None:
"""TODO: add docstring"""
path = Path('tf_models', file.stem)
dir_len = dir_length(path)
path_to_rename = PATH_TO_WATCH / file
new_name = Path('tf_models',
file.stem,
f'{file.stem}_{str(dir_len + 1)}.jpg')
if new_name.exists():
new_name = new_name.parent / f'{new_name.stem}a.jpg'
path_to_rename.rename(new_name)
def dir_length(path: Path) -> int:
"""
Returns the length of given directory,
e.g the amount of files inside the folder.
"""
return capacity(files_paths(path))
def files_paths(path: Path = '.') -> Iterator[Path]:
yield from filter(Path.is_file, Path(path).iterdir())
def capacity(iterable: Iterable[Any]) -> int:
return sum(1 for _ in iterable)
if __name__ == '__main__':
run_transfer(PATH_TO_WATCH, check_against=IMAGES_PATHS)
Note how simple became the logic of getting newly added files when using sets.
You should also do something with the 'tf_models' string. It shouldn't be hardcoded, and it's better to take it out as a constant or a default parameter.
-
\$\begingroup\$ It didn't moved in first test, I'll debug it and find the problem. I'll check first which of the two implementations are faster in performance perspective. \$\endgroup\$khashashin– khashashin2019年02月25日 20:03:18 +00:00Commented Feb 25, 2019 at 20:03
time.sleep(1)which is not much point in performance testing. \$\endgroup\$