I am practising interview questions from here.
Problem : You are given a read only array of n integers from 1 to n. Each integer appears exactly once except A which appears twice and B which is missing. Return A and B such that output A should precede B.
My approach :
Sum(Natural numbers) = Sum(given numbers) - A + B
Sum_squares(Natural numbers) = Sum_squares(given numbers) - A*A + B*B
where :
Sum of n Natural numbers is given by : n(n+1)/2
Sum of squares of n Natural numbers is given by : n((n+1)/2)((2n+1)/3)
The above two equations can be simplified to :
(B-A) = Sum(Natural numbers) - Sum(given numbers)
(B-A)*(B+A) = Sum_squares(Natural numbers) - Sum_squares(given numbers)
Solution:
def repeat_num_and_missing_num(array):
""" returns the value of repeated number and missing number in the given array
using the standard formulaes of Sum of n Natural numbers and sum of squares of n Natural Numbers"""
missing_num = 0
repeated_num = 0
x = len(array)
sum_of_num = 0
sum_of_squares = 0
sum_of_num_actual = (x*(x+1))/2
sum_of_squares_actual = ((x)*(x+1)*(2*x+1) ) / 6
for num in array:
sum_of_num += num
sum_of_squares += num*num
missing_num = (((sum_of_squares_actual - sum_of_squares) /(sum_of_num_actual - sum_of_num))
+(sum_of_num_actual - sum_of_num))/2
repeated_num = (((sum_of_squares_actual - sum_of_squares) /(sum_of_num_actual - sum_of_num))
-(sum_of_num_actual - sum_of_num))/2
return repeated_num, missing_num
#Test Cases
print repeat_num_and_missing_num([5,3,2,1,1]) == (1,4)
print repeat_num_and_missing_num([1,2,3,4,5,16,6,8,9,10,11,12,13,14,15,16]) == (16,7)
print repeat_num_and_missing_num([1,1]) == (1,2)
How can I make this code better?
3 Answers 3
Removing trailing whitespace, renaming variables, reordering the code to group statements about the same concepts and introducing temporary variable to avoid writing and computing the same expressions multiple times and adding comments:
def repeat_num_and_missing_num(array):
""" Return the value of repeated number and missing number in the given array
using the standard formulaes of Sum of n Natural numbers and sum of squares of n Natural Numbers"""
sum_of_num = 0
sum_of_squares = 0
for num in array:
sum_of_num += num
sum_of_squares += num*num
x = len(array)
sum_of_num_expected = (x * (x+1)) / 2
sum_of_squares_expected = ((x) * (x+1) * (2*x+1)) / 6
# Assuming A is present twice and B is missing:
# B - A
b_minus_a = sum_of_num_expected - sum_of_num
# B^2 - A^2 = (B-A) * (B+A)
b2_minus_a2 = sum_of_squares_expected - sum_of_squares
# B + A
b_plus_a = b2_minus_a2 / b_minus_a
a = (b_plus_a - b_minus_a) / 2
b = (b_plus_a + b_minus_a) / 2
return a, b
In addition to what @Josay has already mentioned, I'd advise making use of the inbuilt sum function.
sum_of_num = sum(array)
sum_of_squared = sum((n*n for n in array))
which would be faster than a for-loop iterative solution.
I'd like to demonstrate a solution that differs from yours in the following ways:
Yours is written in pure Python. For arrays thousands of times larger than your current test case, there are performance advantages to instead calling into a C library with Python bindings like Numpy.
You can avoid an unconditional O(n) traversal as you're doing in your for loop. Instead,
- Sort, which is O(n log n) - but, in practice, has a much lower coefficient, then
- Iterate to find the gap between consecutive elements. This is worst-case O(n) but will usually terminate before getting to the end.
One Numpy version of (2) is to instead execute a discrete differential and then a bisection search to find the gaps and duplicates. diff is also O(n), but this can be mitigated if necessary by partitioning the input.
An advantage of this approach is that it can easily be modified to find all gaps and duplicates.
For example,
import timeit
import typing
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn
def op(array: typing.Sequence[int]) -> tuple[int, int]:
""" returns the value of repeated number and missing number in the given array
using the standard formulaes of Sum of n Natural numbers and sum of squares of n Natural Numbers"""
x = len(array)
sum_of_num = 0
sum_of_squares = 0
sum_of_num_actual = (x*(x+1))/2
sum_of_squares_actual = ((x)*(x+1)*(2*x+1) ) / 6
for num in array:
sum_of_num += num
sum_of_squares += num*num
missing_num = (((sum_of_squares_actual - sum_of_squares) /(sum_of_num_actual - sum_of_num))
+(sum_of_num_actual - sum_of_num))/2
repeated_num = (((sum_of_squares_actual - sum_of_squares) /(sum_of_num_actual - sum_of_num))
-(sum_of_num_actual - sum_of_num))/2
return repeated_num, missing_num
def sylvain_hjp_modified(array: typing.Sequence[int]) -> tuple[int, int]:
sum_of_num = sum(array)
sum_of_squares = sum(n*n for n in array)
x = len(array)
sum_of_num_expected = x*(x + 1)//2
sum_of_squares_expected = sum_of_num_expected*(2*x + 1)//3
# Assuming A is present twice and B is missing:
# B - A
b_minus_a = sum_of_num_expected - sum_of_num
# B^2 - A^2 = (B-A) * (B+A)
b2_minus_a2 = sum_of_squares_expected - sum_of_squares
# B + A
b_plus_a = b2_minus_a2//b_minus_a
a = (b_plus_a - b_minus_a)//2
b = (b_plus_a + b_minus_a)//2
return a, b
def python_early_terminate(array: typing.Iterable[int]) -> tuple[int, int]:
increasing = sorted(array)
missing = None
duplicated = None
for x0, x1 in zip(increasing[:-1], increasing[1:]):
if x0 == x1:
if missing is not None:
return x0, missing
duplicated = x0
elif x0 + 2 == x1:
missing = x0 + 1
if duplicated is not None:
return duplicated, missing
def numpy_arith(array: np.ndarray) -> tuple[int, int]:
sum_of_num = array.sum()
sum_of_squares = array.dot(array)
x = len(array)
sum_of_num_expected = x*(x + 1)//2
sum_of_squares_expected = sum_of_num_expected*(2*x + 1)//3
b_minus_a = sum_of_num_expected - sum_of_num
b2_minus_a2 = sum_of_squares_expected - sum_of_squares
b_plus_a = b2_minus_a2//b_minus_a
a = (b_plus_a - b_minus_a)//2
b = (b_plus_a + b_minus_a)//2
return a, b
def numpy_diff(array: np.ndarray) -> tuple[int, int]:
increasing = np.sort(array)
diff = np.diff(increasing)
(i_dupe,), = (diff == 0).nonzero()
(i_miss,), = (diff == 2).nonzero()
return increasing[i_dupe], increasing[i_miss] + 1
METHODS = (
op, sylvain_hjp_modified, python_early_terminate, numpy_arith, numpy_diff,
)
def test() -> None:
for method in METHODS:
assert (1, 4) == method(np.array((5, 3, 2, 1, 1)))
assert (16, 7) == method(np.array((1, 2, 3, 4, 5, 16, 6, 8, 9, 10, 11, 12, 13, 14, 15, 16)))
# This test doesn't make sense: there is no missing value
# assert (1, 2) == method(np.array((1, 1)))
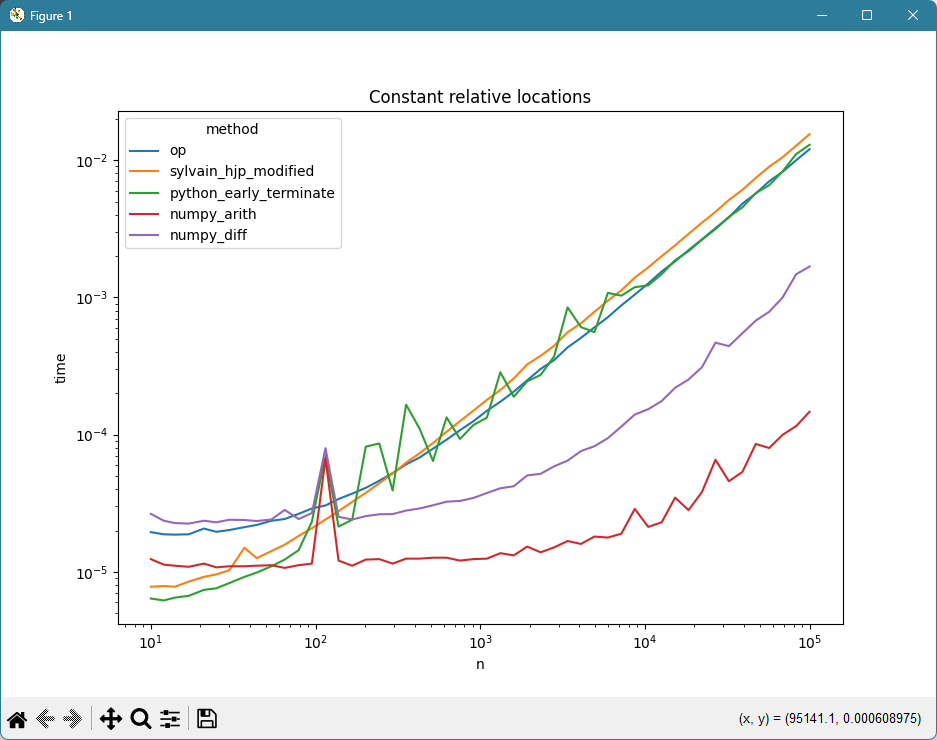
def benchmark() -> None:
times = []
for n in np.logspace(start=1, stop=5, num=50, dtype=int):
diffs = np.ones(n, dtype=int)
diffs[n//3] = 0
diffs[2*n//3] = 2
data = diffs.cumsum()
for method in METHODS:
def run():
return method(data)
t = timeit.timeit(stmt=run, number=1)
times.append({'method': method.__name__, 'n': n, 'time': t})
df = pd.DataFrame(times)
fig, ax = plt.subplots()
seaborn.lineplot(data=df, x='n', y='time', hue='method', ax=ax)
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_title('Constant relative locations')
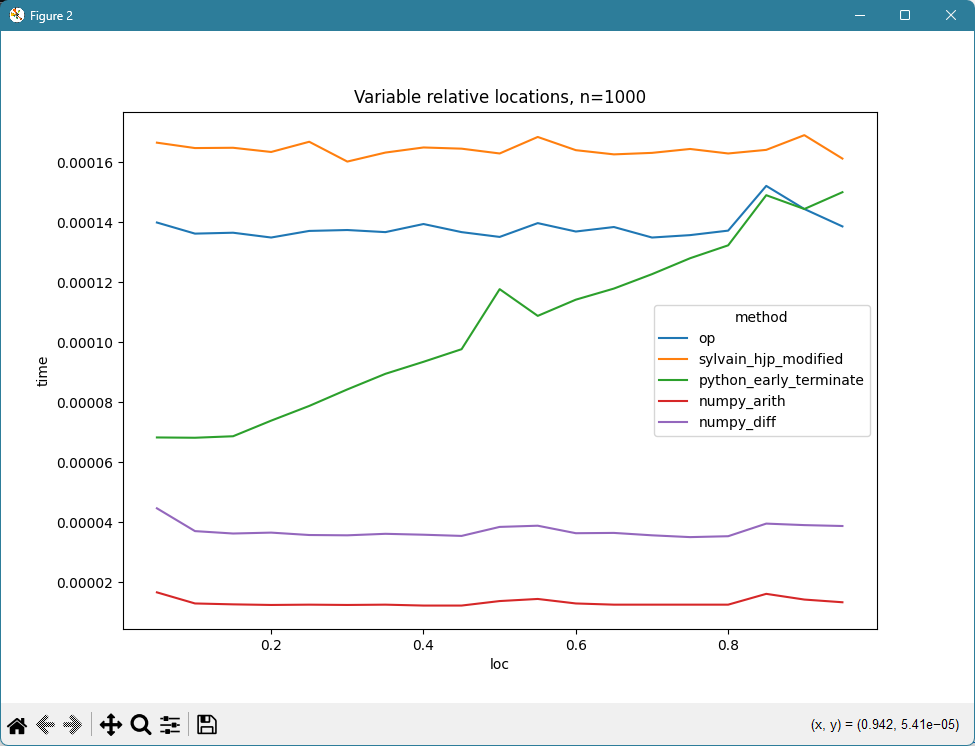
n = 1000
for loc in range(50, 1000, 50):
diffs = np.ones(n, dtype=int)
diffs[loc] = 0
diffs[loc + 2] = 2
data = diffs.cumsum()
for method in METHODS:
def run():
return method(data)
t = timeit.timeit(stmt=run, number=1)
times.append({'method': method.__name__, 'loc': loc/n, 'time': t})
df = pd.DataFrame(times)
fig, ax = plt.subplots()
seaborn.lineplot(data=df, x='loc', y='time', hue='method', ax=ax)
ax.set_title(f'Variable relative locations, n={n}')
plt.show()
if __name__ == '__main__':
test()
benchmark()
{kind=link}
{kind=link}
-
\$\begingroup\$ I don't get it. You're suggesting him to do an o(nlogn) operation to save an O(n)? \$\endgroup\$Bharel– Bharel2024年09月26日 15:30:28 +00:00Commented Sep 26, 2024 at 15:30
-
2\$\begingroup\$ @Bharel Yes. Look at the benchmark. Despite the sort being O(nlogn) in theory, in practice its coefficient is very low in comparison, and so this method out-performs the other two pure-Python methods, its real-life time complexity still has O(n) as the dominant effect, and is faster due to early termination. \$\endgroup\$Reinderien– Reinderien2024年09月28日 14:32:47 +00:00Commented Sep 28, 2024 at 14:32