I made this code for take some data from a .txt file. The text file is a large list of data from temperature with a format that is repetitive and have some lines at the beginning with the station reference. I took the first ten lines but only one time, then I jump to line 12 to take the headers and then I have a mark that tell me if a new year of records is beginning and jump to line 13 and write from the line 13 to 30.
Is there a Pythonic way, without a lot of next(f)?
from itertools import islice
with open(rutaEscribir,'w') as w:
with open(rutaLeer) as f:
for line in islice(f,1,10):
w.write(line)
f.seek(0)
for line in islice(f,12,13):
w.write(line)
f.seek(0)
ano = 1977
for line in f:
sena = '&'
if sena in line:
print('Found')
print('Año: ',ano)
next(f)
next(f)
next(f)
next(f)
next(f)
next(f)
next(f)
next(f)
next(f)
next(f)
next(f)
next(f)
next(f)
for n in islice(f,0,31):
w.write(n)
ano += 1
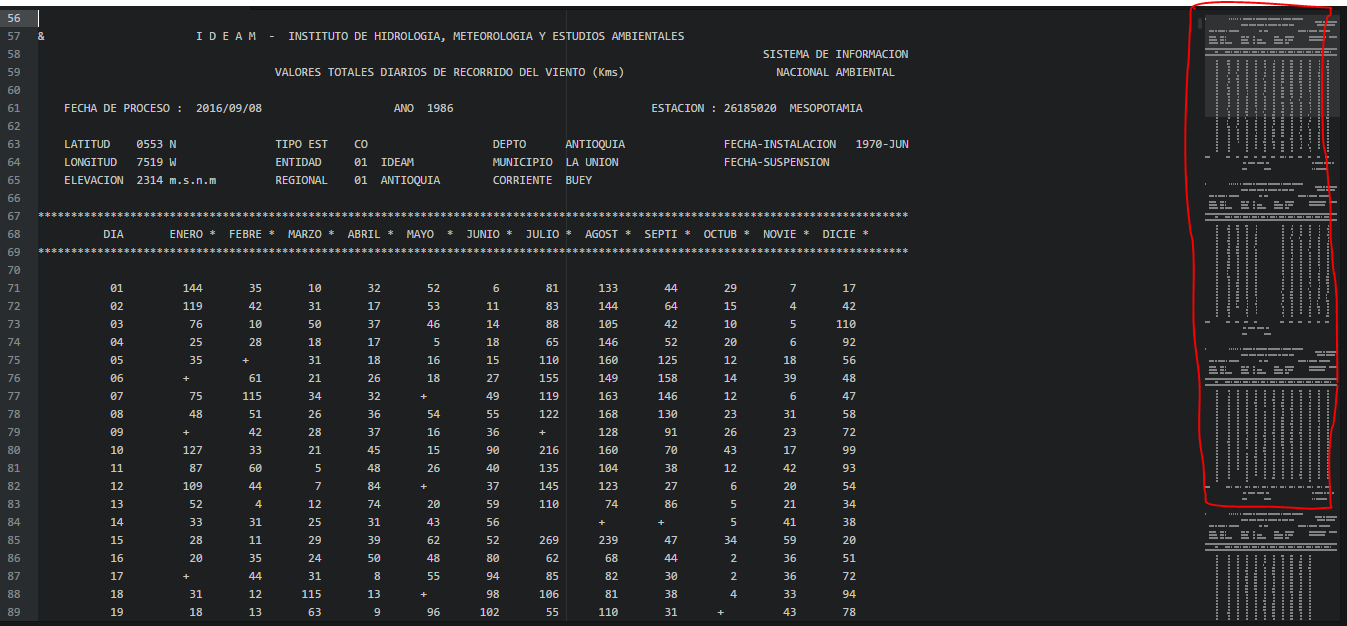
Here is an excerpt from the file:
& I D E A M - INSTITUTO DE HIDROLOGIA, METEOROLOGIA Y ESTUDIOS AMBIENTALES
SISTEMA DE INFORMACION
VALORES TOTALES DIARIOS DE RECORRIDO DEL VIENTO (Kms) NACIONAL AMBIENTAL
FECHA DE PROCESO : 2016年09月08日 ANO 1986 ESTACION : 26185020 MESOPOTAMIA
LATITUD 0553 N TIPO EST CO DEPTO ANTIOQUIA FECHA-INSTALACION 1970-JUN
LONGITUD 7519 W ENTIDAD 01 IDEAM MUNICIPIO LA UNION FECHA-SUSPENSION
ELEVACION 2314 m.s.n.m REGIONAL 01 ANTIOQUIA CORRIENTE BUEY
***********************************************************************************************************************************
DIA ENERO * FEBRE * MARZO * ABRIL * MAYO * JUNIO * JULIO * AGOST * SEPTI * OCTUB * NOVIE * DICIE *
***********************************************************************************************************************************
01 144 35 10 32 52 6 81 133 44 29 7 17
...
05 35 + 31 18 16 15 110 160 125 12 18 56
...
{kind=link}
As you can see on the right, this is a repetitive file. In line 57 I put the & marker for the start of a new year of records. The next few lines (57 to 65) contain the geographical position from the station, followed by the month header (ENERO,FEB...). Then, 31 lines contain the data for that year. I want to use PANDAS to analyze that data.
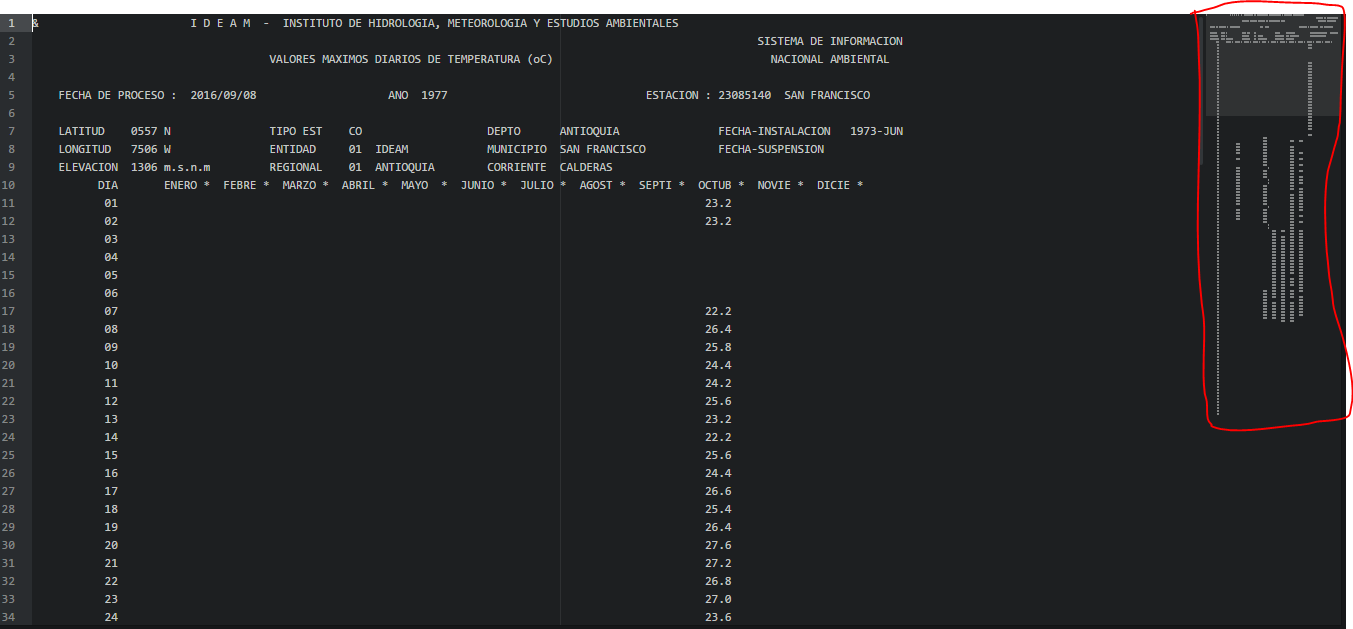
My code transforms it into something like this: Expected output
{kind=link}
As you can see, the repetitive headers for geographical position and the months now appear just once.
But I think is possible to do it in a Pythonic way and not with a lot of next(f).
-
\$\begingroup\$ If your goal is to load the data into PANDAS for data analysis, why do you want to convert the data from one somewhat-difficult-to-parse format into another somewhat-difficult-to-parse format? \$\endgroup\$200_success– 200_success2016年09月14日 03:19:53 +00:00Commented Sep 14, 2016 at 3:19
-
\$\begingroup\$ With pandas I can skip the first lines and read that I want, keeping the geografical position in one file. \$\endgroup\$Manuel Alejandro– Manuel Alejandro2016年09月14日 03:23:51 +00:00Commented Sep 14, 2016 at 3:23
2 Answers 2
Well, you could find a "Pythonic" way to skip around a file, but that still wouldn't make it good code, in my opinion. There are some fundamental issues with your approach that make it rather hackish:
f.seek(0)means that the file isn't being processed sequentially, and creates extra work.- You're hard-coding
ano = 1977when in factANO 1977would be right there in the data file itself! And you're deliberately skipping over that valuable information! And then you have to hope that the file really does start with data for 1977! - This data format is human-friendly but machine-hostile. You say that your ultimate goal is to import the data into pandas for analysis. But PANDAS doesn't easily understand this IDEAM data format. In fact, your output is just as difficult to parse as the original, but worse, since stripping out the year headers makes the data less self-documenting. The work to implement a real parser seems unavoidable. So, if you're going to transform the data, why not transform it into one of the formats that PANDAS knows how to read?
1,10,12, and13are "magic" numbers. There is no way to understand why those numbers are there in the code. Basically, you're blindly assuming that the input is in a certain format without any verification. If your assumption is wrong, you could easily load data into your analysis incorrectly, and you would never know about the mistake. You wouldn't want the wrong kind of publicity for your climate analysis, would you?
Therefore, I consider your approach to be a poor substitute for properly parsing the file. Here, for example, would be one way to parse this data format:
import fileinput
import re
class IdeamParser:
def __init__(self, *patterns):
self.patterns = [(re.compile(regex), act) for regex, act in patterns]
def parse(self, line_iter):
for line in line_iter:
for regex, action in self.patterns:
matches = regex.search(line)
if matches:
yield from action(self, matches)
def start_meta(self, matches):
self.meta = {}
yield from []
def read_meta(self, matches):
self.meta.update(dict(zip(matches.groups()[::2], matches.groups()[1::2])))
yield from []
def months_header(self, matches):
line = matches.group()
self.month_cols = [m.span() for m in re.finditer(' *(\S+) *[*]', line)]
yield from []
def read_data(self, matches):
day_of_month = int(matches.group(1))
line = matches.group()
values = [line[start:end] for start, end in self.month_cols]
values = [float(val) if re.search(r'\d', val) else None for val in values]
yield self.meta, day_of_month, values
parser = IdeamParser(
(r'^\s*(\d{2})\s+(.*)', IdeamParser.read_data),
(r'I D E A M', IdeamParser.start_meta),
(r'(VALORES) (.*\(.*\))', IdeamParser.read_meta),
(r'(FECHA DE PROCESO) : *(\d{4}/\d{2}/\d{2}) *'
r'(ANO) +(\d{4}) *'
r'(ESTACION) : *(.*?) *$', IdeamParser.read_meta),
(r'(LATITUD) +(.*?) *'
r'(TIPO EST) +(.*?) *'
r'(DEPTO) +(.*?) *'
r'(FECHA-INSTALACION) +(.*?) *$', IdeamParser.read_meta),
...
(r'\s*DIA +ENERO.*', IdeamParser.months_header),
)
for meta, day_of_month, values in parser.parse(fileinput.input()):
print(meta, day_of_month, values)
Sample output:
{'DEPTO': 'ANTIOQUIA', 'FECHA DE PROCESO': '2016/09/08', 'LATITUD': '0553 N', 'FECHA-INSTALACION': '1970-JUN', 'ANO': '1986', 'TIPO EST': 'CO', 'ESTACION': '26185020 MESOPOTAMIA', 'VALORES': 'TOTALES DIARIOS DE RECORRIDO DEL VIENTO (Kms)'} 1 [144.0, 35.0, 10.0, 32.0, 52.0, 6.0, 81.0, 133.0, 44.0, 29.0, 7.0, 17.0]
...
{'DEPTO': 'ANTIOQUIA', 'FECHA DE PROCESO': '2016/09/08', 'LATITUD': '0553 N', 'FECHA-INSTALACION': '1970-JUN', 'ANO': '1986', 'TIPO EST': 'CO', 'ESTACION': '26185020 MESOPOTAMIA', 'VALORES': 'TOTALES DIARIOS DE RECORRIDO DEL VIENTO (Kms)'} 5 [35.0, None, 31.0, 18.0, 16.0, 15.0, 110.0, 160.0, 125.0, 12.0, 18.0, 56.0]
The print() statement at the end is just for demonstration. You should replace it with code that generates a CSV file or SQL INSERT statements or something. Or you could just load it into PANDAS directly.
-
\$\begingroup\$ Thanks a lot, It is a great code. I'm learning about patterns to understand all the code, It works great. I want to understand for write better code in future. \$\endgroup\$Manuel Alejandro– Manuel Alejandro2016年09月15日 00:45:28 +00:00Commented Sep 15, 2016 at 0:45
Well, why not use a loop?
for i in range(13):
next(f)
You should also use constants instead of magic numbers, like this:
LINES_BETWEEN_SIGN_AND_DATA = 13
for i in range(LINES_BETWEEN_SIGN_AND_DATA):
next(f)
More generally, make sure you comment the intent of the code since readers of your code might see the code but not the example files.
Explore related questions
See similar questions with these tags.