Here is the classic K-means clustering algorithm implemented in Python 3. My main concern is time/memory efficiency and if there are version specific idioms that I could use to address issues of the former.
import numpy as np
class kmeans():
'''
Implementation of classical k-means clustering algorithm
parameters : dataset n x m ndarray of n samples and m features
n_clusters : number of clusters to assign samples to
limit : tolerance between successive iterations
'''
def __init__(self, dataset, n_clusters, limit):
self.dataset = dataset
self.n_clusters = n_clusters
self.limit = limit
# dictionary to hold each cluster as a list of samples
self.clusters = {i: [] for i in range(self.n_clusters)}
# the centroids of each cluster
self.centroids = np.ndarray((n_clusters, dataset.shape[1]))
# values of utility function. increases in size by 1
# in each iteration
self.util_func_vals = []
def assign_to_clusters(self):
for idx, sample in enumerate(self.dataset):
distances = []
# for each sample we compute its distance from every centroid
for centroid in self.centroids:
distances.append(np.linalg.norm(sample - centroid))
# and assign it to the appropriate cluster
appropriate_cluster = distances.index(min(distances))
self.clusters[appropriate_cluster].append(sample)
def calc_utility_function(self):
total_sum = 0
# utility function is the sum of intra-cluster distances
# the goal is to minimize it
for cluster, samples in self.clusters.items():
for i in range(len(samples)):
for j in range(i + 1, len(samples)):
total_sum += np.linalg.norm(samples[i] - samples[j])
return total_sum
def calc_new_centroids(self):
# we calculate new centroids by obtaining the centers of each
#(each) cluster
centers = np.ndarray(shape=self.centroids.shape)
for key, samples in self.clusters.items():
temp_mean = []
temp_sam = np.array(samples)
# that is the mean of each feature
for i in range(self.dataset.shape[1]):
temp_mean.append(sum(temp_sam[:, i]) / temp_sam.shape[0])
centers[key] = np.array(temp_mean)
# the new centroid is the sample in the cluster that is closest
# to the mean point
for i in range(centers.shape[0]):
distances = [np.linalg.norm(centers[i] - sample)
for sample in self.clusters[i]]
new_centroid = distances.index(min(distances))
self.centroids[i] = self.clusters[i][new_centroid]
# clusters dictionary must empty in order to repopulate
self.clusters = {i: [] for i in range(self.n_clusters)}
def compute(self):
# core method that computes the clusters
# initialize centroids by randomly choosing #n_clusters samples
# from dataset
self.centroids = self.dataset[np.random.choice(self.dataset.shape[0],
size=self.n_clusters,
replace=False), :]
# apply the first two steps of the algorithm
self.assign_to_clusters()
self.util_func_vals.append(self.calc_utility_function())
self.calc_new_centroids()
self.assign_to_clusters()
self.util_func_vals.append(self.calc_utility_function())
# and continue until the succesive value difference of utility
# function becomes lower than the user specified limit
while abs(self.util_func_vals[-1] - self.util_func_vals[-2]) > self.limit:
self.calc_new_centroids()
self.assign_to_clusters()
self.util_func_vals.append(self.calc_utility_function())
Here is the code for a demo execution of the algorithm:
from kmeans import kmeans
import matplotlib.pyplot as pl
import numpy as np
# put some random samples with different distributions in the plane
# in order to visualize as 3 groups
r1 = np.ndarray(shape=(200, 2))
r2 = np.ndarray(shape=(200, 2))
r3 = np.ndarray(shape=(200, 2))
r1x = 0.7 * np.random.randn(200) + 2
r1y = 0.5 * np.random.randn(200) + 4
r2x = 0.7 * np.random.randn(200) + 2
r2y = 0.5 * np.random.randn(200) + 2
r3x = 0.7 * np.random.randn(200) + 8
r3y = 0.5 * np.random.randn(200) + 6
for i in range(200):
r1[i] = np.array([r1x[i],r1y[i]])
r2[i] = np.array([r2x[i],r2y[i]])
r3[i] = np.array([r3x[i],r3y[i]])
R = np.concatenate((r1,r2,r3),0)
# plot them
BEFORE = pl.figure(1)
pl.plot(R[:,0],R[:,1],'o')
BEFORE.show()
# apply kmeans clustering
g = kmeans(R,3,0.5)
g.compute()
# and plot the clusters in different colors
AFTER = pl.figure(2)
x = [item[0] for item in g.clusters[0]]
y = [item[1] for item in g.clusters[0]]
pl.plot(x, y, 'co')
x = [item[0] for item in g.clusters[1]]
y = [item[1] for item in g.clusters[1]]
pl.plot(x, y, 'yo')
x = [item[0] for item in g.clusters[2]]
y = [item[1] for item in g.clusters[2]]
pl.plot(x, y, 'mo')
pl.show()
1 Answer 1
import numpy as np
class kmeans():
Use a PEP 8 checker such as pycodestyle or flake8. Integrate it into your file editor or IDE, if you're not doing it already. Some violations get missed by those tools. For example, class names should use uppercase, so "KMeans" here.
'''
Implementation of classical k-means clustering algorithm
parameters : dataset n x m ndarray of n samples and m features
n_clusters : number of clusters to assign samples to
limit : tolerance between successive iterations
'''
def __init__(self, dataset, n_clusters, limit):
self.dataset = dataset
self.n_clusters = n_clusters
self.limit = limit
# dictionary to hold each cluster as a list of samples
self.clusters = {i: [] for i in range(self.n_clusters)}
For speed, consider storing the cluster membership information in the dataset.
# the centroids of each cluster
self.centroids = np.ndarray((n_clusters, dataset.shape[1]))
I like that the code is generic enough to handle more than two dimensions. 👍
# values of utility function. increases in size by 1
# in each iteration
self.util_func_vals = []
util_func_vals is not really descriptive. First, we usually describe this as the objective, not as an "utility function". And vals does not add value to the name. Consider using a name such as objective_history. Not great, but better. Finding great names is hard, but it's worth it.
def assign_to_clusters(self):
for idx, sample in enumerate(self.dataset):
A for loop! This is among the first thing you should try to eliminate to make your code faster. This is called vectorizing your code. You can probably make most operations on the whole self.dataset at once. See this awesome k-means answer to see how it could be done.
distances = []
# for each sample we compute its distance from every centroid
for centroid in self.centroids:
distances.append(np.linalg.norm(sample - centroid))
For speed, don't use linalg.norm, because it does an extra square root that you don't need. Indeed sqrt(a)> sqrt(b) is equivalent to a> b, so you don't need the square root. However, I tried to replace linalg.norm with a version without square roots, and it was slower. Always profile your code before trying to optimize it.
def calc_utility_function(self):
total_sum = 0
# utility function is the sum of intra-cluster distances
# the goal is to minimize it
for cluster, samples in self.clusters.items():
for i in range(len(samples)):
for j in range(i + 1, len(samples)):
total_sum += np.linalg.norm(samples[i] - samples[j])
return total_sum
I profiled your code using cProfile and gprof2dot, and this takes 85% of the time.
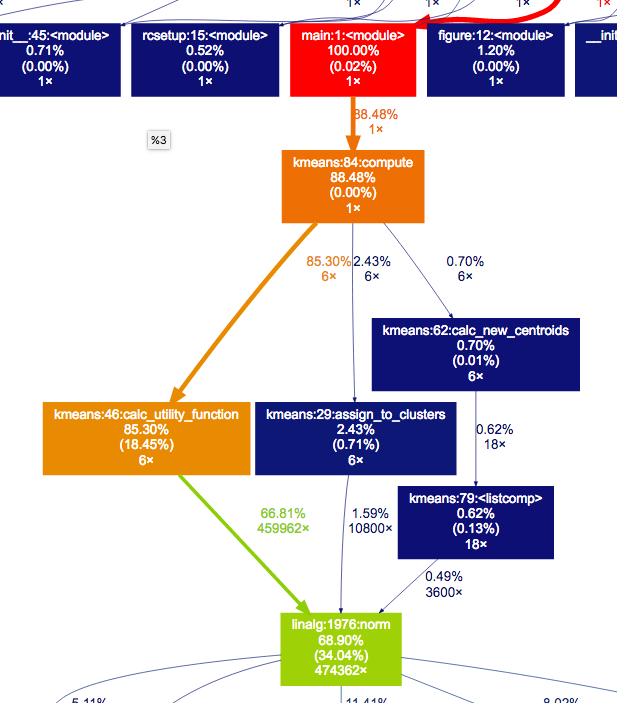{kind=link}
85%! But it only serves to know when to stop, this should not be the most expensive function. And indeed, there's a mistake. You're computing the distance between all points in a given cluster, which is O(n^2), while you only need to compute the distance for all points to the centroid, which is O(n), much much faster. Here's the new function:
def calc_utility_function(self):
total_sum = 0
for cluster, samples in self.clusters.items():
centroid = self.centroids[cluster]
for i in range(len(samples)):
total_sum += np.linalg.norm(samples[i] - centroid)
return total_sum
If it took 1s for 100 samples, it will now take about 4s for 400 samples. But with your code it would have taken 16s. For 200 samples, it's a 10x improvement. The calc_utility_function optimization was so effective that most of the time is spent initializing the code. I went to 2000 samples and profiled again:
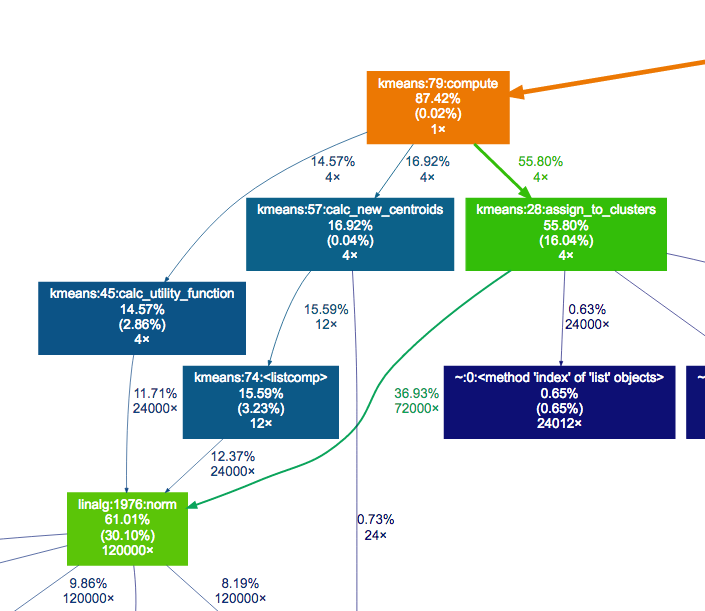{kind=link}
The function that was previously taking 85% of the time is now taking 15% of the time.
def calc_new_centroids(self):
# we calculate new centroids by obtaining the centers of each
# (each) cluster
Not much to say here, but try to see if this can be vectorized.
# clusters dictionary must empty in order to repopulate
self.clusters = {i: [] for i in range(self.n_clusters)}
Don't do this here, but do it at the beginning of the function. This way, it's easy to access the dictionary outside of the function since there's no side effect.
def compute(self):
# core method that computes the clusters
# initialize centroids by randomly choosing #n_clusters samples
# from dataset
self.centroids = self.dataset[np.random.choice(self.dataset.shape[0],
size=self.n_clusters,
replace=False), :]
# apply the first two steps of the algorithm
self.assign_to_clusters()
self.util_func_vals.append(self.calc_utility_function())
self.calc_new_centroids()
self.assign_to_clusters()
self.util_func_vals.append(self.calc_utility_function())
This is ugly because you're repeating yourself. If you define self.utils_func_vals to [math.inf], then you can put everything in the loop (see below).
# and continue until the succesive value difference of utility
# function becomes lower than the user specified limit
while abs(self.util_func_vals[-1] - self.util_func_vals[-2]) > self.limit:
Use math.isclose: math.isclose(self.util_func_vals[-1], self.util_func_vals[-2], abs_tol=limit).
Here's the new loop:
converged = False
while not converged:
self.assign_to_clusters()
self.calc_new_centroids()
self.util_func_vals.append(self.calc_utility_function())
converged = math.isclose(
self.util_func_vals[-1],
self.util_func_vals[-2],
abs_tol=self.limit)
Much cleaner, and there's no messy initialization.
And of course, if you really want speed, use the implementation from scipy as mentioned by @GarethRees.
-
2\$\begingroup\$ "I tried to replace
numpy.linalg.normwith a version without square roots, and it was slower" — did you tryscipy.spatial.distance.cdistwithmetric='sqeuclidean'? See for example the code at the end of this answer. \$\endgroup\$Gareth Rees– Gareth Rees2016年09月05日 11:29:42 +00:00Commented Sep 5, 2016 at 11:29 -
\$\begingroup\$ That's an awesome answer :) Good job. I'd also recommend
scipywhen talking about speed. \$\endgroup\$Grajdeanu Alex– Grajdeanu Alex2016年09月05日 11:32:07 +00:00Commented Sep 5, 2016 at 11:32 -
\$\begingroup\$ @GarethRees cdist expects an ndarray, so I doubt I would get any benefit without vectorizing first. \$\endgroup\$Quentin Pradet– Quentin Pradet2016年09月05日 11:44:48 +00:00Commented Sep 5, 2016 at 11:44
-
\$\begingroup\$ What a great answer! Thank you for your time! I'm using sublime 3 with anaconda package which has PEP8 compliance auto check but missed the naming conventions. Also +1 for code vectorization which is something i have to dig into i guess. \$\endgroup\$Sorrop– Sorrop2016年09月05日 11:55:47 +00:00Commented Sep 5, 2016 at 11:55
Explore related questions
See similar questions with these tags.
scipy.cluster.vq.kmeans? \$\endgroup\$