Currently, the code will generate a range of natural numbers from 1 to N and store it in a list. Then the program will iterate through that list, marking each multiple of a prime as 0 and storing each prime in a secondary list.
This is a translation of a TI-Basic program, shown here, so the same description still applies.
Here's an animation:
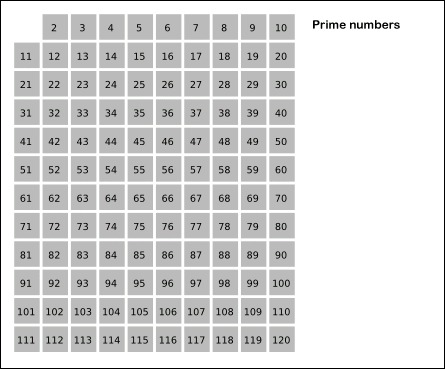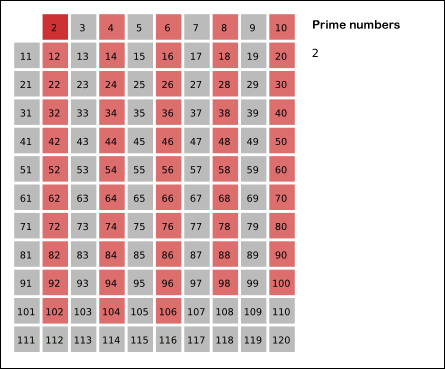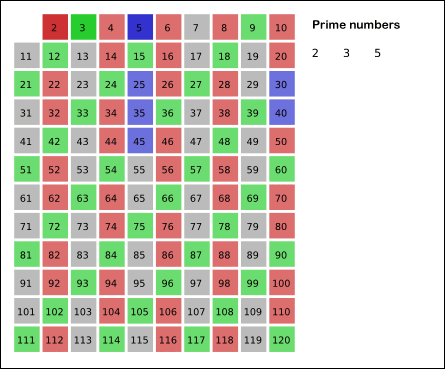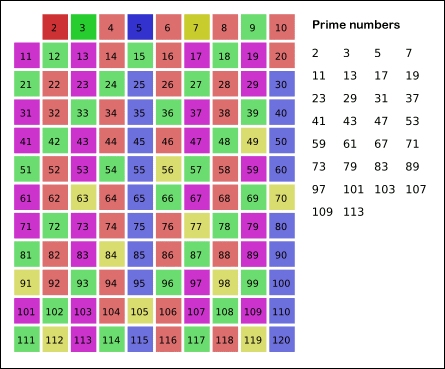{kind=link}
One of the main optimizations that I want to see implemented would be the actual removal of prime multiples from the list instead of simply setting them to 0. As it is currently written, this would be a challenge to perform without adding in another if statement. Any suggestions would be helpful.
def sieve(end):
prime_list = []
sieve_list = list(range(end+1))
for each_number in range(2,end+1):
if sieve_list[each_number]:
prime_list.append(each_number)
for every_multiple_of_the_prime in range(each_number*2, end+1, each_number):
sieve_list[every_multiple_of_the_prime] = 0
return prime_list
Here's a link to PythonTutor, which will visualize the code in operation.
-
\$\begingroup\$ Hey that's a pretty cool animation! \$\endgroup\$Mathieu Guindon– Mathieu Guindon2015年09月11日 17:00:11 +00:00Commented Sep 11, 2015 at 17:00
-
2\$\begingroup\$ @Mat'sMug It came from Wikipedia, turns out they have some very enlightening gifs. :) \$\endgroup\$Slinky– Slinky2015年09月11日 17:03:45 +00:00Commented Sep 11, 2015 at 17:03
1 Answer 1
Just a couple things:
sieve_list = list(range(end+1))
You don't actually need your list to be [0, 1, 2, ... ]. You just need an indicator of whether or not it's true or false. So it's simpler just to start with:
sieve_list = [True] * (end + 1)
That'll likely perform better as well.
When you're iterating over multiples of primes, you're using:
range(each_number*2, end+1, each_number)
But we can do better than each_number*2, we can start at each_number*each_number. Every multiple of that prime between it and its square will already have been marked composite (because it will have a factor smaller than each_number). That'll save a steadily larger increment of time each iteration.
As an optimization, we know up front that 2 and 3 are primes. So we can start our iteration at 5 and ensure that we only consider each_number to not be multiples of 2 or 3. That is, alternate incrementing by 4 and 2. We can write this function:
def candidate_range(n):
cur = 5
incr = 2
while cur < n+1:
yield cur
cur += incr
incr ^= 6 # or incr = 6-incr, or however
Full solution:
def sieve(end):
prime_list = [2, 3]
sieve_list = [True] * (end+1)
for each_number in candidate_range(end):
if sieve_list[each_number]:
prime_list.append(each_number)
for multiple in range(each_number*each_number, end+1, each_number):
sieve_list[multiple] = False
return prime_list
Impact of various changes with end at 1 million, run 10 times:
initial solution 6.34s
[True] * n 3.64s (!!)
Square over double 3.01s
candidate_range 2.46s
Also, I would consider every_multiple_of_the_prime as an unnecessary long variable name, but YMMV.
-
\$\begingroup\$ These are excellent suggestions, and I will use them. I want to know though, how well do you think the original optimization that I was trying to wrap my head around would have worked? \$\endgroup\$Slinky– Slinky2015年09月11日 17:41:02 +00:00Commented Sep 11, 2015 at 17:41
-
\$\begingroup\$ Thank you. This is exactly the answer that I was looking for. \$\endgroup\$Slinky– Slinky2015年09月11日 17:45:47 +00:00Commented Sep 11, 2015 at 17:45
Explore related questions
See similar questions with these tags.