A simple challenge for your Monday evening (well, or Tuesday morning in the other half of the world...)
You're given as input a nested, potentially ragged array of positive integers:
[1, [[2, 3, [[4], 5], 6, [7, 8]], 9, [10, [[[11]]]], 12, 13], 14]
Your task is to determine its depth, which is the greatest nesting-depth of any integer in the list. In this case, the depth of 11 is 6, which is largest.
You may assume that none of the arrays will be empty.
You may write a program or function, taking input via STDIN (or closest alternative), command-line argument or function argument and outputting the result via STDOUT (or closest alternative), function return value or function (out) parameter.
Input may be taken in any convenient list or string format that supports non-rectangular arrays (with nested arrays of different depths), as long as the actual information isn't preprocessed.
You must not use any built-ins related to the shape of arrays (including built-ins that solve this challenge, that get you the dimensions of a nested array). The only exception to this is getting the length of an array.
Standard code-golf rules apply.
Test Cases
[1] -> 1
[1, 2, 3] -> 1
[[1, 2, 3]] -> 2
[3, [3, [3], 3], 3] -> 3
[[[[1], 2], [3, [4]]]] -> 4
[1, [[3]], [5, 6], [[[[8]]]], 1] -> 5
[1, [[2, 3, [[4], 5], 6, [7, 8]], 9, [10, [[[11]]]], 12, 13], 14] -> 6
[[[[[[[3]]]]]]] -> 7
55 Answers 55
K, 4 bytes
#,/\
In K, ,/ will join all the elements of a list. The common idiom ,// iterates to a fixed point, flattening an arbitrarily nested list completely. ,/\ will iterate to a fixed point in a similar way, but gather a list of intermediate results. By counting how many intermediate results we visit before reaching the fixed point (#), we get the answer we want: the maximum nesting depth.
"Count of join over fixed-point scan".
In action:
(#,/\)'(,1
1 2 3
,1 2 3
(3;(3;,3;3);3)
,((,1;2);(3;,4)))
1 1 2 3 4
Retina, 10
- Saved 1 byte thanks to @ӍѲꝆΛҐӍΛПҒЦꝆ
- Saved 14 extra bytes thanks to @MartinBüttner
+`\w|}{
{
Here the input format is a bit contrived - _ characters are used for list separators, so an input would look like this {1_{{2_3_{{4}_5}_6_{7_8}}_9_{10_{{{11}}}}_12_13}_14}
- Stage 1 - repeatedly remove
}{and all other\wcharacters. This has the effect of a) making all lists at all levels consist of only one element and b) removing all non-list-structural characters. - Stage 2 - count remaining
{. This gives the deepest level of nesting.
If that's too much of a stretch, then the previous answer was:
Retina, 13
Assumes lists are contained in curly braces {}.
+`[^}{]|}{
{
-
1\$\begingroup\$ Your code can be shortened to 13 bytes (11 if you stretch the input format a bit). Let me know if you want a hint. :) (I don't really want to post it myself, since it's virtually the same solution.) \$\endgroup\$Martin Ender– Martin Ender2016年02月09日 07:33:26 +00:00Commented Feb 9, 2016 at 7:33
-
\$\begingroup\$ It's two things. a) You can save a byte or so by slightly tweaking the input format. b) You can save a lot of bytes regardless of that... can you find a shorter (and much simpler) solution if you try not to handle multiple test cases in a single run? \$\endgroup\$Martin Ender– Martin Ender2016年02月09日 18:19:06 +00:00Commented Feb 9, 2016 at 18:19
-
\$\begingroup\$ I didn't even think of that. That's amount byte saved then. My change to the input format would have been even weaker. Regarding b) remember what Retina's very first and simplest mode of operation was? \$\endgroup\$Martin Ender– Martin Ender2016年02月09日 18:35:02 +00:00Commented Feb 9, 2016 at 18:35
-
1\$\begingroup\$ yep. My a) was referring to removing spaces from the input though. And you can then save two more bytes by using
_instead of,but that might be a bit of a stretch. \$\endgroup\$Martin Ender– Martin Ender2016年02月09日 18:37:52 +00:00Commented Feb 9, 2016 at 18:37 -
\$\begingroup\$ @MartinBüttner Nice idea! Agreed -
_separators might be too contrived. So I'm leaving both versions in the answer \$\endgroup\$Digital Trauma– Digital Trauma2016年02月09日 18:47:26 +00:00Commented Feb 9, 2016 at 18:47
Python 2, 33 bytes
f=lambda l:l>{}and-~max(map(f,l))
Recursively defines the depth by saying the depth of a number is 0, and the depth of a list is one more than the maximum depth of its elements. Number vs list is checked by comparing to the empty dictionary {}, which falls above numbers but below lists on Python 2's arbitrary ordering of built-in types.
-
1\$\begingroup\$ Length built-ins are now allowed if it helps. \$\endgroup\$Martin Ender– Martin Ender2016年02月08日 23:10:07 +00:00Commented Feb 8, 2016 at 23:10
Pyth - (削除) 11 (削除ここまで) (削除) 10 (削除ここまで) 7 bytes
1 bytes saved thanks to @Dennis
4 bytes saved thanks to @Thomas Kwa
eU.usNQ
Keeps on summing the array till it stops changing, which means its just a number, does this cumulatively to save all the intermediate results and gets length by making a urange with the same length as list and taking the last element.
-
\$\begingroup\$
m!!dcan become&R1. \$\endgroup\$Dennis– Dennis2016年02月08日 22:21:01 +00:00Commented Feb 8, 2016 at 22:21 -
\$\begingroup\$ @Dennis cool, that's smart \$\endgroup\$Maltysen– Maltysen2016年02月08日 22:21:26 +00:00Commented Feb 8, 2016 at 22:21
-
\$\begingroup\$ @ThomasKwa
lisn't allowed in OP. \$\endgroup\$Maltysen– Maltysen2016年02月08日 22:25:58 +00:00Commented Feb 8, 2016 at 22:25 -
\$\begingroup\$ Length built-ins are now allowed if it helps. \$\endgroup\$Martin Ender– Martin Ender2016年02月08日 23:10:17 +00:00Commented Feb 8, 2016 at 23:10
Haskell, 43 bytes
'['#x=x-1
']'#x=x+1
_#x=x
maximum.scanr(#)0
Usage example: maximum.scanr(#)0 $ "[1, [[3]], [5, 6], [[[[8]]]], 1]" -> 5.
Haskell doesn't have mixed lists (Integer mixed with List of Integer), so I cannot exploit some list detection functions and I have to parse the string.
Im starting at the right with 0 and add 1 for every ], subtract 1 for every [ and keep the value otherwise. scanr keeps all intermediate results, so maximum can do it's work.
Julia, (削除) 55 (削除ここまで) 26 bytes
f(a)=0a!=0&&maximum(f,a)+1
This is a recursive function that accepts a one-dimensional array with contents of type Any and returns an integer. When passing an array to the function, prefix all brackets with Any, i.e. f(Any[1,Any[2,3]]).
The approach is pretty simple. For an input a, we multiply a by 0 and check whether the result is the scalar 0. If not, we know that a is an array, so we apply the function to each element of a, take the maximum and add 1.
Saved 29 bytes thanks to Dennis!
-
3\$\begingroup\$ Dat golf. <filler> \$\endgroup\$El'endia Starman– El'endia Starman2016年02月10日 07:27:13 +00:00Commented Feb 10, 2016 at 7:27
JavaScript (ES6), 35 bytes
f=a=>a[0]?Math.max(...a.map(f))+1:0
Explanation
Recursive function that returns the maximum depth of an array, or 0 if passed a number.
var solution =
f=a=>
a[0]? // if a is an array
Math.max(...a.map(f)) // return the maximum depth of each element in the array
+1 // add 1 to increase the depth
:0 // if a is a number, return 0
// Test cases
result.textContent =
`[1] -> 1
[1, 2, 3] -> 1
[[1, 2, 3]] -> 2
[3, [3, [3], 3], 3] -> 3
[[[[1], 2], [3, [4]]]] -> 4
[1, [[3]], [5, 6], [[[[8]]]], 1] -> 5
[1, [[2, 3, [[4], 5], 6, [7, 8]], 9, [10, [[[11]]]], 12, 13], 14] -> 6
[[[[[[[3]]]]]]] -> 7`
.split`\n`.map(t=>(c=t.split`->`.map(p=>p.trim()),c[0]+" == "+c[1]+": "+(solution(eval(c[0]))==c[1]?"Passed":"Failed"))).join`\n`<input type="text" id="input" value="[1, [[2, 3, [[4], 5], 6, [7, 8]], 9, [10, [[[11]]]], 12, 13], 14]" />
<button onclick="result.textContent=solution(eval(input.value))">Go</button>
<pre id="result"></pre>-
\$\begingroup\$ Length built-ins are now allowed if it helps. \$\endgroup\$Martin Ender– Martin Ender2016年02月08日 23:10:30 +00:00Commented Feb 8, 2016 at 23:10
MATL, 11 (削除) 14 15 (削除ここまで) bytes
'}{'!=dYsX>
Curly braces are used in MATL for this type of arrays. Anyway, the input is taken and processed as a string, so square brackets could equally be used, modifying the two characters in the code.
% implicitly take input as a string (row array of chars)
'}{'! % 2x1 (column) char array with the two curly brace symbols
= % 2-row array. First / second row contains 1 where '}' / '{' is found
d % second row minus first row
Ys % cumulative sum of the array
X> % maximum of the array
% implicitly display result
-
\$\begingroup\$ Length built-ins are now allowed if it helps. \$\endgroup\$Martin Ender– Martin Ender2016年02月08日 23:10:20 +00:00Commented Feb 8, 2016 at 23:10
Jelly, (削除) 10 (削除ここまで) 7 bytes
¬;/SпL
Try it online! or verify all test cases.
How it works
¬;/SпL Main link. Input: A (list)
¬ Negate all integers in A. This replaces them with zeroes.
п Cumulative while loop.
S Condition: Compute the sum of all lists in A.
If the sum is an integer, it will be zero (hence falsy).
;/ Body: Concatenate all lists in A.
L Count the number of iterations.
Update
While writing this answer, I noticed that Jelly behaves rather weirdly for ragged lists, because I calculated the depth of a list as the incremented minimum of depths of its items.
This has been addressed in the latest version, so the following code (6 bytes) would work now.
¬SSпL
This sums the rows of the array instead of concatenating them.
-
\$\begingroup\$ Presumably,
ŒḊis newer than the challenge? \$\endgroup\$2017年10月19日 16:28:08 +00:00Commented Oct 19, 2017 at 16:28 -
\$\begingroup\$ You must not use any built-ins related to the shape of arrays (including built-ins that solve this challenge, that get you the dimensions of a nested array). \$\endgroup\$Dennis– Dennis2017年10月19日 16:39:32 +00:00Commented Oct 19, 2017 at 16:39
Octave, 29 bytes
@(a)max(cumsum(92-(a(a>90))))
Maps [ to 1 and ] to -1, then takes the max of the cumulative sum.
Input is a string of the form
S6 = '[1, [[3]], [5, 6], [[[[8]]]], 1]';
Sample run on ideone.
-
\$\begingroup\$ Should you use
{,}? The Octave equivalent to the arrays in the OP are cell arrays, I think \$\endgroup\$Luis Mendo– Luis Mendo2016年02月09日 10:42:01 +00:00Commented Feb 9, 2016 at 10:42 -
\$\begingroup\$ @LuisMendo No, because that's 2 extra bytes :) Plus, since I never actually create the array, simply parse the input string, I don't think it matters. But you've reminded me to add the expected input to my answer. \$\endgroup\$beaker– beaker2016年02月09日 16:20:15 +00:00Commented Feb 9, 2016 at 16:20
-
\$\begingroup\$ True! Longer ASCII code \$\endgroup\$Luis Mendo– Luis Mendo2016年02月09日 17:16:56 +00:00Commented Feb 9, 2016 at 17:16
-
\$\begingroup\$ @LuisMendo Actually, 1 byte longer. That second comparison only needs to be greater than '9'. But you get the idea :D \$\endgroup\$beaker– beaker2016年02月09日 17:20:27 +00:00Commented Feb 9, 2016 at 17:20
Ruby, 53 bytes
i=0;p gets.chars.map{|c|i+=('] ['.index(c)||1)-1}.max
Input from STDIN, output to STDOUT.
i=0; initialize counter variable
p output to STDOUT...
gets get line of input
.chars enumerator of each character in the input
.map{|c| map each character to...
i+= increment i (and return the new value) by...
('] ['.index(c)||1) returns 0 for ], 2 for [, 1 for anything else
-1 now it's -1 for ], 1 for [, 0 for anything else
therefore: increment i on increase in nesting, decrement i
on decrease, do nothing otherwise
}.max find the highest nesting level that we've seen
-
\$\begingroup\$ Length built-ins are now allowed if it helps. \$\endgroup\$Martin Ender– Martin Ender2016年02月08日 23:10:22 +00:00Commented Feb 8, 2016 at 23:10
Mathematica, 18 bytes
Max@#+1&//@(0#-1)&
-
\$\begingroup\$ Could you explain it, please? \$\endgroup\$skan– skan2016年12月20日 01:49:11 +00:00Commented Dec 20, 2016 at 1:49
Mathematica, (削除) 27 (削除ここまで) 20 bytes
Max[#0/@#]+1&[0#]-1&
Simple recursive function.
-
\$\begingroup\$ It's possible to void the
If, saving 7 bytes. (Let me know if you want a hint.) \$\endgroup\$Martin Ender– Martin Ender2016年02月09日 07:39:29 +00:00Commented Feb 9, 2016 at 7:39 -
\$\begingroup\$ @MartinBüttner I give up... A
Replace-based solution is at least as long as this one... \$\endgroup\$LegionMammal978– LegionMammal9782016年02月09日 12:16:08 +00:00Commented Feb 9, 2016 at 12:16 -
1\$\begingroup\$
Mapping over an integer is a no-op:Max[#0/@#]+1&[0#]-1&. The-1can also go inside the inner call like...&[0#-1]&. \$\endgroup\$Martin Ender– Martin Ender2016年02月09日 12:30:31 +00:00Commented Feb 9, 2016 at 12:30
PHP, 61 bytes
function d($a){return is_array($a)?1+max(array_map(d,$a)):0;}
recursive function that uses itself as a mapping function to replace each element with its depth.
-
\$\begingroup\$ I just noticed: The same thing in JS has only 35 bytes. Still pretty in php. \$\endgroup\$Titus– Titus2016年12月20日 03:47:46 +00:00Commented Dec 20, 2016 at 3:47
-
PHP, (削除) 84 (削除ここまで) (削除) 72 (削除ここまで) (削除) 64 (削除ここまで) (削除) 63 (削除ここまで) 60 bytes
Note: requires PHP 7 for the combined comparison operator. Also uses IBM-850 encoding
for(;$c=$argv[1][$i++];)$c>A&&$t=max($t,$z+=~ú<=>$c);echo$t;
Run like this:
php -r 'for(;$c=$argv[1][$i++];)$c>A&&$t=max($t,$z+=~ú<=>$c);echo$t;' "[1, [[3]], [5, 6], [[[[8]]]], 1]"
- Saved 12 bytes by just counting braces of the string representation instead
- Saved 8 bytes by simplifying string comparisons and using ordinal number of the char in case of
[and] - Saved a byte by not casting
$ito an int. String offsets are casted to an int implicitly - Saved 3 bytes by using combined comparison operator instead of ordinal number
C, (削除) 98 (削除ここまで) 69 bytes
29 bytes off thanks @DigitalTrauma !!
r,m;f(char*s){for(r=m=0;*s;r-=*s++==93)r+=*s==91,m=r>m?r:m;return m;}
Takes an string as input and return the result as integer.
Live example in: http://ideone.com/IC23Bc
Python 3, (削除) 42 (削除ここまで) 39 bytes
-3 bytes thanks to Sp3000
This is essentially a port of xnor's Python 2 solution:
f=lambda l:"A"<str(l)and-~max(map(f,l))
Unfortunately, [] > {} returns an unorderable types error, so that particular clever trick of xnor's cannot be used. In its place, -0123456789 are lower in ASCII value than A, which is lower than [], hence the string comparison works.
CJam (15 bytes)
q~{__e_-M*}h],(
Dissection
q~ e# Read line and parse to array
{ e# Loop...
_ e# Leave a copy of the array on the stack to count it later
_e_- e# Remove a flattened version of the array; this removes non-array elements from
e# the top-level array.
M* e# Remove one level from each array directly in the top-level array
}h e# ...until we get to an empty array
],( e# Collect everything together, count and decrement to account for the extra []
For the same length but rather more in ugly hack territory,
q'[,-{:~_}h],2-
-
\$\begingroup\$
s/ugly/beautiful/\$\endgroup\$Dennis– Dennis2016年02月10日 20:05:31 +00:00Commented Feb 10, 2016 at 20:05 -
\$\begingroup\$ @Dennis, I was referring specifically to the use of
'[,-to strip the string down to[], which relies on the contents being limited. The approach which flattens works regardless of the contents of the array. \$\endgroup\$Peter Taylor– Peter Taylor2016年02月10日 22:05:28 +00:00Commented Feb 10, 2016 at 22:05 -
\$\begingroup\$ The second one is prettier. The first one has two types of mismatched braces \$\endgroup\$Cyoce– Cyoce2016年10月07日 00:21:08 +00:00Commented Oct 7, 2016 at 0:21
Sed, 40 characters
(39 characters code + 1 character command line option.)
s/[^][]+//g
:;s/]\[//;t
s/]//g
s/\[/1/g
Input: string, output: unary number.
Sample run:
bash-4.3$ sed -r 's/[^][]+//g;:;s/]\[//;t;s/]//g;s/\[/1/g' <<< '[1, [[2, 3, [[4], 5], 6, [7, 8]], 9, [10, [[[11]]]], 12, 13], 14]'
111111
Sed, 33 characters
(32 characters code + 1 character command line option.)
If trailing spaces are allowed in the output.
s/[^][]+//g
:;s/]\[//;t
y/[]/1 /
Input: string, output: unary number.
Sample run:
bash-4.3$ sed -r 's/[^][]+//g;:;s/]\[//;t;y/[]/1 /' <<< '[1, [[2, 3, [[4], 5], 6, [7, 8]], 9, [10, [[[11]]]], 12, 13], 14]'
111111
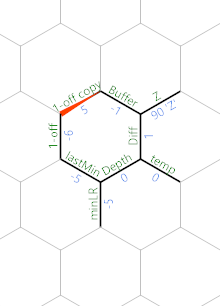
Hexagony, 61 bytes
Edit: Thanks @Martin Ender♦ for saving me 1 byte from the marvelous -1 trick!
|/'Z{>"-\..(.."/'&<'..{>-&,=+<$.{\$._{..><.Z=/...({=Z&"&@!-"
Try it online to verify test cases!
The images below are not modified but the flow is basically the same. Also note that this will return -1 if the input is not an array (i.e. without []).
I have lots of no-ops inside the Hexagon... I guess it can definitely be golfed more.
Explanation
In brief, it adds -1 when encounters a [ and adds 1 when encounters a ]. Finally it prints the max it has got.
Let's run along Test Case 5 to see its behaviour when it runs along the String [1, [[3]], [5, 6], [[[[8]]]], 1]:
It starts at the beginning and takes its input at the W corner:
{kind=link}
Since there is still input (not the null character 0円 or EOL), it wraps to the top and starts the crimson path.
Here is what happens when from there till cute ><:
, reads [ into Buffer, and { and Z sets the constant Z to be 90. ' moves to Diff and - calculates the difference. For [ and ] the difference will be 1 and 3 respectively. For numbers and spaces and commas it'll be negative.
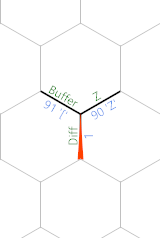{kind=link}
{kind=link}
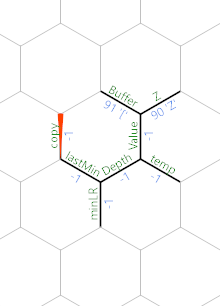
Then we run ( twice (once at the end of crimson path, one at the start after wrapping at the green path) to get -1 and 1 resp for [ and ]. Here we change the naming of Diff to Value. Add this Value to Depth. (I used Z& to ensure that it copies the right neighbor). Then we calculate lastMin - Depth and got a number on the Memory edge minLR.
Then we apply & (at the end of green path) to minLR: If the number is <=0, it copies the left value (i.e. lastMin - Depth <= 0 => lastMin <= Depth), otherwise it takes the right value.
We wraps to the horizontal blue path and we see Z& again which copies the minLR. Then we "& and made a copy of the calculated min. The brackets are assumed to be balanced, so the min must be <=0. After wrapping, the blue path go left and hit (, making the copy 1 less than the real min. Reusing the -, we created one more 1-off copy as a neighbor of Buffer:
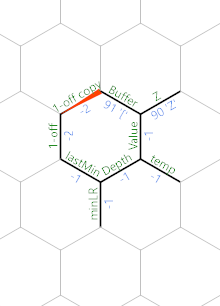{kind=link}
Note: copy is renamed as 1-off
When blue path hits \ and got a nice " and < catches it back to the main loop.
When the loop hits 1, , or or other numbers as input:
{kind=link}
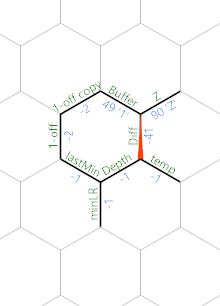{kind=link}
The Diff will become negative and it got reflected back to the main loop for next input.
When everything has gone through the main loop, we reach EOL which makes Buffer -1 and it finally goes to the bottom edge:
{kind=link}
' moves the MP to the 1-off copy and ) increments it, and with ~ negation it got the correct Max Depth value which is printed with !
And the story ends with a @.
I guess I must have over complicating things a little bit. If I have had to only "move back" and "print" without incrementing and negation, I would have well saved 2 bytes without using the full Hexagon.
Great thanks to Timwi for Esoteric IDE and Hexagony Colorer!
-
\$\begingroup\$ You can save a byte by making use of the
-1from,by changing the last row to:@!-".(although I agree that it is probably possible to shave off a lot more or even fit this into side-length 4 with some restructuring). \$\endgroup\$Martin Ender– Martin Ender2016年10月12日 12:33:08 +00:00Commented Oct 12, 2016 at 12:33 -
\$\begingroup\$ Haven't thought of making use of the -1! Will edit once I got my computer. If the temp is on left neighbor, I would have saved quite a few
Zfrom usingZ&. And there should be better ways to start the program with the implicit if. \$\endgroup\$Sunny Pun– Sunny Pun2016年10月12日 15:51:58 +00:00Commented Oct 12, 2016 at 15:51
brainfuck, 48 bytes
,[<++[>-<------]>++[+[<]>>[-]]+<,]-[<[>+<-]>>]<.
Formatted:
,
[
<++[>-<------]>++
[
not close paren
+
[
not open paren
<
]
>>[-]
]
+<,
]
-[<[>+<-]>>]
<.
Takes input formatted like (1, ((3)), (5, 6), ((((8)))), 1) and outputs a byte value.
This stores the depth by memory location, moving the pointer right for ( and left for ) and ignoring other characters. Visited cells are marked with a 1 flag, so at the end of the main loop there will be depth + 1 flags to the right of the current cell. These are then added to print the final result.
A previous 69-byte solution using a different approach:
,
[
>>++[<<->>------]<-<++
[
not close paren
>++<+
[
not open paren
>-<[-]
]
]
<
[
[>+>]
<[<-<]
>
]
>>[<+> >+<-]
,
]
<.
In this version, the depth and max depth are stored explicitly in cells.
Io, 53 bytes
Port of the JavaScript (ES6) answer.
f :=method(x,if(x type=="List",x map(i,f(i))max+1,0))
Jelly, 3 bytes
ẎƬL
This is a translation of JohnE's K answer.
Ẏ is the "tighten" command. When applied to a list, it "unwraps" each list in it, essentially reducing the depth by one. Ƭ repeated applies Ẏ to the input until it reaches a fixed point. We then count the number of iterations with L.
05AB1E, 7 bytes
dΔ€`}N>
Try it online or verify all test cases.
Explanation:
d # Convert each integer in the (implicit) input-list to 1 (with a >=0 check)
Δ # Loop until the result no longer changes:
€ # Map over each inner item:
` # Pop and dump its contents to the stack
}N # After the loop, push the last 0-based index
> # Increase it by 1 to make it a 1-based index
# (which is output implicitly as result)
The €` basically flattens a list one level down, but will push its items in reversed order. E.g. list [[1,[2,3],4]] will become [4,[2,3],1]. In addition, it will do the same for multi-digit numbers, hence the need for the leading d to convert every integer to a single digit first. E.g. list [12,345,67] will become [2,1,5,4,3,7,6].
Whython, 28 bytes
f=lambda l:1+max(map(f,l))?0
Explanation
The depth of a list is the maximum depth of its elements; the depth of an integer is 0.
f=lambda l:1+max(map(f,l))?0
f= # Define f as
lambda l: # a function of one argument, l:
map(f,l) # Call f recursively on each element of l
max( ) # Take the maximum
1+ # Add 1
# If l is an integer, map raises an exception
?0 # Catch that exception and return 0
Brachylog, 8 bytes
>0|↰m⌉+1
0| Output 0
> if the input is a positive integer;
|↰m else map this over the elements of the input
+1 and add 1 to
⌉ the largest result.
Raku, (削除) 53 (削除ここまで) 48 bytes
The closure:
{my $d;/[\[{$d++;$!=max $!,$d}|\]{$d--}|.]*/;$!}
Needs an argument, eg:
> {my $d;/[\[{$d++;$!=max $!,$d}|\]{$d--}|.]*/;$!}("[[[3]][2]]")
3
Explanation:
{ # start outer IIFE closure;
my $d; # declare depth variable `$d`;
/ # start IIFE regex match;
[ # start (non-capturing) group;
# EITHER:
\[ # match `[` in input; if successful then:
{ # start inner (within regex) IIFE closure;
$d++; # increment depth variable; and then:
$! = max $!, $d # (ab)use `$!` variable to track MAX depth;
} # end inner IIFE closure;
| # OR:
\] # match `[` in input; if successful then:
{$d--} # decrement depth variable in IIFE closure;
| # OR:
. # match one character;
]* # end capture group; match zero or more times;
/; # end regex;
$! # max depth as last value in closure;
} # end outer closure, returning last value (max depth);
("[[[3]][2]]") # pass string "[[[3]][2]]" as outer closure argument.
Pyth, (削除) 15 (削除ここまで) 13 bytes
-2 bytes by @Maltysen
eSm-F/Ld`Y._z
Counts the difference between the cumulative counts of [ and ], and takes the maximum. Y is the empty array, and its string representation (`) is conveniently [].
Try it here.
-
\$\begingroup\$ Length built-ins are now allowed if it helps. \$\endgroup\$Martin Ender– Martin Ender2016年02月08日 23:10:13 +00:00Commented Feb 8, 2016 at 23:10
Explore related questions
See similar questions with these tags.
≡is APL's built-in primitive for exactly this. \$\endgroup\$\in the inputs? EDIT: nevermind just tried it like that. That doesn't even work either. Darn can I not use CMD args? \$\endgroup\$