Create a function that will output a set of distinct random numbers drawn from a range. The order of the elements in the set is unimportant (they can even be sorted), but it must be possible for the contents of the set to be different each time the function is called.
The function will receive 3 parameters in whatever order you want:
- Count of numbers in output set
- Lower limit (inclusive)
- Upper limit (inclusive)
Assume all numbers are integers in the range 0 (inclusive) to 231 (exclusive). The output can be passed back any way you want (write to console, as an array, etc.)
Judging
Criteria includes the 3 R's
- Run-time - tested on a quad-core Windows 7 machine with whatever compiler is freely or easily available (provide a link if necessary)
- Robustness - does the function handle corner cases or will it fall into an infinite loop or produce invalid results - an exception or error on invalid input is valid
- Randomness - it should produce random results that are not easily predictable with a random distribution. Using the built in random number generator is fine. But there should be no obvious biases or obvious predictable patterns. Needs to be better than that random number generator used by the Accounting Department in Dilbert
If it is robust and random then it comes down to run-time. Failing to be robust or random greatly hurts its standings.
-
\$\begingroup\$ Is the output supposed to pass something like the DIEHARD or TestU01 tests, or how will you judge its randomness? Oh, and should the code run in 32 or 64 bit mode? (That will make a big difference for optimization.) \$\endgroup\$Ilmari Karonen– Ilmari Karonen2012年01月27日 06:35:32 +00:00Commented Jan 27, 2012 at 6:35
-
\$\begingroup\$ TestU01 is probably a bit harsh, I guess. Does criterion 3 imply a uniform distribution? Also, why the non-repeating requirement? That's not particularly random, then. \$\endgroup\$Joey– Joey2012年01月27日 08:36:17 +00:00Commented Jan 27, 2012 at 8:36
-
\$\begingroup\$ @Joey, sure it is. It's random sampling without replacement. As long as no-one claims that the different positions in the list are independent random variables there's no problem. \$\endgroup\$Peter Taylor– Peter Taylor2012年01月27日 11:07:33 +00:00Commented Jan 27, 2012 at 11:07
-
\$\begingroup\$ Ah, indeed. But I'm not sure whether there are well-established libraries and tools for measuring randomness of sampling :-) \$\endgroup\$Joey– Joey2012年01月27日 11:12:22 +00:00Commented Jan 27, 2012 at 11:12
-
\$\begingroup\$ @IlmariKaronen: RE: Randomness: I've seen implementations before that were woefully unrandom. Either they had a heavy bias, or lacked the ability to produce different results on consecutive runs. So we are not talking cryptographic level randomness, but more random than the Accounting Department's random number generator in Dilbert. \$\endgroup\$Jim McKeeth– Jim McKeeth2012年01月28日 05:08:53 +00:00Commented Jan 28, 2012 at 5:08
16 Answers 16
Python
import random
def sample(n, lower, upper):
result = []
pool = {}
for _ in xrange(n):
i = random.randint(lower, upper)
x = pool.get(i, i)
pool[i] = pool.get(lower, lower)
lower += 1
result.append(x)
return result
I probably just re-invented some well-known algorithm, but the idea is to (conceptually) perform a partial Fisher-Yates shuffle of the range lower..upper to get the length n prefix of a uniformly shuffled range.
Of course, storing the whole range would be rather expensive, so I only store the locations where the elements have been swapped.
This way, the algorithm should perform well both in the case where you're sampling numbers from a tight range (e.g. 1000 numbers in the range 1..1000), as well as the case where you're sampling numbers from a large range.
I'm not sure about the quality of randomness from the built-in generator in Python, but it's relatively simple to swap in any generator that can generate integers uniformly from some range.
-
1\$\begingroup\$ Python uses Mersenne Twister, so it's relatively decent. \$\endgroup\$ESultanik– ESultanik2012年03月05日 13:49:20 +00:00Commented Mar 5, 2012 at 13:49
python 2.7
import random
print(lambda x,y,z:random.sample(xrange(y,z),x))(input(),input(),input())
not sure what your standing is on using builtin random methods, but here you go anyways. nice and short
edit: just noticed that range() doesn't like to make big lists. results in a memory error. will see if there is any other way to do this...
edit2: range was the wrong function, xrange works. The maximum integer is actually 2**31-1 for python
test:
python sample.py
10
0
2**31-1
[786475923, 2087214992, 951609341, 1894308203, 173531663, 211170399, 426989602, 1909298419, 1424337410, 2090382873]
C
Returns an array containing x unique random ints between min and max. (caller must free)
#include <stdlib.h>
#include <stdint.h>
#define MAX_ALLOC ((uint32_t)0x40000000) //max allocated bytes, fix per platform
#define MAX_SAMPLES (MAX_ALLOC/sizeof(uint32_t))
int* randsamp(uint32_t x, uint32_t min, uint32_t max)
{
uint32_t r,i=x,*a;
if (!x||x>MAX_SAMPLES||x>(max-min+1)) return NULL;
a=malloc(x*sizeof(uint32_t));
while (i--) {
r= (max-min+1-i);
a[i]=min+=(r ? rand()%r : 0);
min++;
}
while (x>1) {
r=a[i=rand()%x--];
a[i]=a[x];
a[x]=r;
}
return a;
}
Works by generating x sequential random integers in the range, then shuffling them.
Add a seed(time) somewhere in caller if you don't want the same results every run.
Ruby >= 1.8.7
def pick(num, min, max)
(min..max).to_a.sample(num)
end
p pick(5, 10, 20) #=>[12, 18, 13, 11, 10]
R
s <- function(n, lower, upper) sample(lower:upper,n); s(10,0,2^31-2)
The question is not correct. Do you need uniform sampling or not? In the case uniform sampling is needed I have the following code in R, which has average complexity O(s log s), where s is the sample size.
# The Tree growing algorithm for uniform sampling without replacement
# by Pavel Ruzankin
quicksample = function (n,size)
# n - the number of items to choose from
# size - the sample size
{
s=as.integer(size)
if (s>n) {
stop("Sample size is greater than the number of items to choose from")
}
# upv=integer(s) #level up edge is pointing to
leftv=integer(s) #left edge is poiting to; must be filled with zeros
rightv=integer(s) #right edge is pointig to; must be filled with zeros
samp=integer(s) #the sample
ordn=integer(s) #relative ordinal number
ordn[1L]=1L #initial value for the root vertex
samp[1L]=sample(n,1L)
if (s > 1L) for (j in 2L:s) {
curn=sample(n-j+1L,1L) #current number sampled
curordn=0L #currend ordinal number
v=1L #current vertice
from=1L #how have come here: 0 - by left edge, 1 - by right edge
repeat {
curordn=curordn+ordn[v]
if (curn+curordn>samp[v]) { #going down by the right edge
if (from == 0L) {
ordn[v]=ordn[v]-1L
}
if (rightv[v]!=0L) {
v=rightv[v]
from=1L
} else { #creating a new vertex
samp[j]=curn+curordn
ordn[j]=1L
# upv[j]=v
rightv[v]=j
break
}
} else { #going down by the left edge
if (from==1L) {
ordn[v]=ordn[v]+1L
}
if (leftv[v]!=0L) {
v=leftv[v]
from=0L
} else { #creating a new vertex
samp[j]=curn+curordn-1L
ordn[j]=-1L
# upv[j]=v
leftv[v]=j
break
}
}
}
}
return(samp)
}
Of course, one may rewrite it in C for better performance. The complexity of this algorithm is discussed in: Rouzankin, P. S.; Voytishek, A. V. On the cost of algorithms for random selection. Monte Carlo Methods Appl. 5 (1999), no. 1, 39-54. http://dx.doi.org/10.1515/mcma.1999年5月1日.39
You may look through this paper for another algorithm with the same average complexity.
But if you do not need uniform sampling, only requiring that all sampled numbers be different, then the situation changes dramatically. It is not hard to write an algorithm that has average complexity O(s).
See also for uniform sampling: P. Gupta, G. P. Bhattacharjee. (1984) An efficient algorithm for random sampling without replacement. International Journal of Computer Mathematics 16:4, pages 201-209. DOI: 10.1080/00207168408803438
Teuhola, J. and Nevalainen, O. 1982. Two efficient algorithms for random sampling without replacement. /IJCM/, 11(2): 127–140. DOI: 10.1080/00207168208803304
In the last paper the authors use hash tables and claim that their algorithms have O(s) complexity. There is one more fast hash table algorithm, which will soon be implemented in pqR (pretty quick R): https://stat.ethz.ch/pipermail/r-devel/2017-October/075012.html
APL, (削除) 18 (削除ここまで) 22 bytes
{⍵[0]+(1↑⍺)?⍵[1]-⍵[0]}
Declares an anonymous function that takes two arguments ⍺ and ⍵. ⍺ is the number of random numbers you want, ⍵ is a vector containing the lower and upper bounds, in that order.
a?b picks a random numbers between 0-b without replacement. By taking ⍵[1]-⍵[0] we get the range size. Then we pick ⍺ numbers (see below) from that range and add the lower bound. In C, this would be
lower + rand() * (upper - lower)
⍺ times without replacement. Parentheses not needed because APL operates right-to-left.
(削除) Assuming I've understood the conditions correctly, this fails the 'robustness' criteria because the function will fail if given improper arguments (e.g. passing a vector instead of a scalar as ⍺). (削除ここまで)
In the event that ⍺ is a vector rather than a scalar, 1↑⍺ takes the first element of ⍺. For a scalar, this is the scalar itself. For a vector, it's the first element. This should make the function meet the 'robustness' criteria.
Example:
Input: 100 {⍵[0]+⍺?⍵[1]-⍵[0]} 0 100
Output: 34 10 85 2 46 56 32 8 36 79 77 24 90 70 99 61 0 21 86 50 83 5 23 27 26 98 88 66 58 54 76 20 91 72 71 65 63 15 33 11 96 60 43 55 30 48 73 75 31 13 19 3 45 44 95 57 97 37 68 78 89 14 51 47 74 9 67 18 12 92 6 49 41 4 80 29 82 16 94 52 59 28 17 87 25 84 35 22 38 1 93 81 42 40 69 53 7 39 64 62
-
2\$\begingroup\$ This is not a code golf but a fastest cose, therefore the goal is producing the fastest code to perform the task rather than the shortest. Anyway, you don't really need to pick the items from the arguments like that, and you can determine their order, so
{⍵+⍺?⎕-⍵}should suffice, where the prompt is for the upper bound and right arg is lower bound \$\endgroup\$Uriel– Uriel2017年11月06日 21:12:37 +00:00Commented Nov 6, 2017 at 21:12
Scala
object RandSet {
val random = util.Random
def rand (count: Int, lower: Int, upper: Int, sofar: Set[Int] = Set.empty): Set[Int] =
if (count == sofar.size) sofar else
rand (count, lower, upper, sofar + (random.nextInt (upper-lower) + lower))
}
object RandSetRunner {
def main (args: Array [String]) : Unit = {
if (args.length == 4)
(0 until args (0).toInt).foreach { unused =>
println (RandSet.rand (args (1).toInt, args (2).toInt, args (3).toInt).mkString (" "))
}
else Console.err.println ("usage: scala RandSetRunner OUTERCOUNT COUNT MIN MAX")
}
}
compile and run:
scalac RandSetRunner.scala
scala RandSetRunner 200 15 0 100
The second line will run 200 tests with 15 values from 0 to 100, because Scala produces fast bytecode but needs some startup time. So 200 starts with 15 values from 0 to 100 would consume more time.
Sample on a 2 Ghz Single Core:
time scala RandSetRunner 100000 10 0 1000000 > /dev/null
real 0m2.728s
user 0m2.416s
sys 0m0.168s
Logic:
Using the build-in random and recursively picking numbers in the range (max-min), adding min and checking, if the size of the set is the expected size.
Critique:
- It will be fast for small samples of big ranges, but if the task is to pick nearly all elements of a sample (999 numbers out of 1000) it will repeatedly pick numbers, already in the set.
- From the question, I'm unsure, whether I have to sanitize against unfulfillable requests like Take 10 distinct numbers from 4 to 8. This will now lead to an endless loop, but can easily be avoided with a prior check which I will append if requested.
Scheme
Not sure why you need 3 parameters passed nor why i need to assume any range...
(import srfi-1) ;; for iota
(import srfi-27) ;; randomness
(import srfi-43) ;; for vector-swap!
(define rand (random-source-make-integers
default-random-source))
;; n: length, i: lower limit
(define (random-range n i)
(let ([v (list->vector (iota n i))])
(let f ([n n])
(let* ([i (rand n)] [n (- n 1)])
(if (zero? n) v
(begin (vector-swap! v n i) (f n)))))))
R
random <- function(count, from, to) {
rand.range <- to - from
vec <- c()
for (i in 1:count) {
t <- sample(rand.range, 1) + from
while(i %in% vec) {
t <- sample(rand.range, 1) + from
}
vec <- c(vec, t)
}
return(vec)
}
C++
This code is best when drawing many samples from the range.
#include <exception>
#include <stdexcept>
#include <cstdlib>
template<typename OutputIterator>
void sample(OutputIterator out, int n, int min, int max)
{
if (n < 0)
throw std::runtime_error("negative sample size");
if (max < min)
throw std::runtime_error("invalid range");
if (n > max-min+1)
throw std::runtime_error("sample size larger than range");
while (n>0)
{
double r = std::rand()/(RAND_MAX+1.0);
if (r*(max-min+1) < n)
{
*out++ = min;
--n;
}
++min;
}
}
-
\$\begingroup\$ This can easily get stuck in an infinite loop unless
max-minis much larger thann. Also, the output sequence is monotonically increasing, so you're getting very low quality randomness but still paying the cost of callingrand()multiple times per result. A random shuffle of the array would probably be worth the extra run-time. \$\endgroup\$Peter Cordes– Peter Cordes2016年12月18日 22:49:16 +00:00Commented Dec 18, 2016 at 22:49
Q (19 characters)
f:{(neg x)?y+til z}
Then use f[x;y;z] as [count of numbers in output set;starting point;size of range]
e.g. f[5;10;10] will output 5 distinct random numbers between 10 and 19 inclusive.
q)\ts do[100000;f[100;1;10000]]
2418 131456j
Results above show performance at 100,000 iterations of picking 100 random numbers between 1 & 10,000.
R, 31 or 40 bytes (depending on the meaning of the word "range")
If the input has 3 numbers, a[1], a[2], a[3], and by "range" you mean "an integer sequence from a[2] to a[3]", then you have this:
a=scan();sample(a[2]:a[3],a[1])
If you have an array n from which you are about to resample, but under the restriction of the lower and upper limits, like "resample values of the given array n from the range a[1]...a[2]", then use this:
a=scan();sample(n[n>=a[2]&n<=a[3]],a[1])
I am quite surprised why the previous result was not golfed considering the built-in sample with replacement facilities! We create a vector that satisfies the range condition and re-sample it.
- Robustness: the corner cases (sequences of the same length as the range to sample from) are handled by default.
- Run-time: extremely fast because it is built in.
- Randomness: the seed is automatically changed every time the RNG is invoked.
-
\$\begingroup\$ at least on my machine,
0:(2^31)causes anError: cannot allocate a vector of size 16.0 Gb\$\endgroup\$Giuseppe– Giuseppe2018年04月05日 21:56:03 +00:00Commented Apr 5, 2018 at 21:56 -
\$\begingroup\$ @Giuseppe Recently, I have been working with big-memory problems, and the solution to that is actually... running it on a better machine. The restrictions in the formulation of the task pertain to the processor, not to memory, so is it... rule abuse? Ah, I am an ass. I thought it was a code golf challenge, but actually it is... fastest-code. I lose I guess? \$\endgroup\$Andreï V. Kostyrka– Andreï V. Kostyrka2018年04月06日 08:41:11 +00:00Commented Apr 6, 2018 at 8:41
Javascript (using external library) (64 bytes / 104 bytes??)
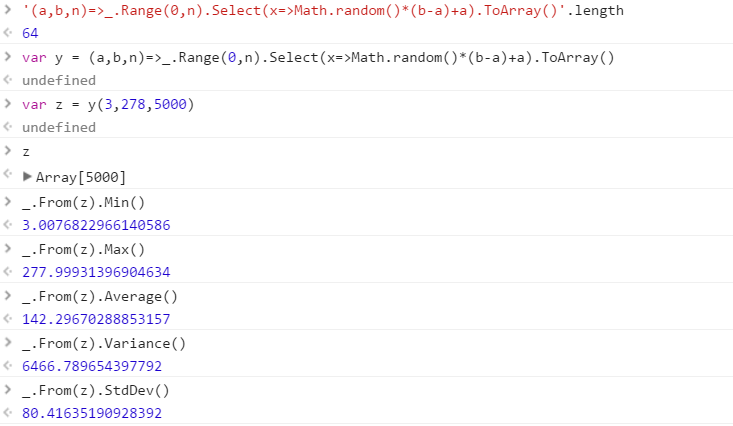
(a,b,n)=>_.Range(0,n).Select(x=>Math.random()*(b-a)+a).ToArray()
Link to lib: https://github.com/mvegh1/Enumerable/
Code explanation: Lambda expression accepts min,max,count as args. Create a collection of size n, and map each element to a random number fitting the min/max criteria. Convert to native JS array and return it. I ran this also on an input of size 5,000,000, and after applying a distinct transform still showed 5,000,000 elements. If it is agreed upon that this isn't safe enough of a guarantee for distinctness I will update the answer
I included some statistics in the image below...
{kind=link}
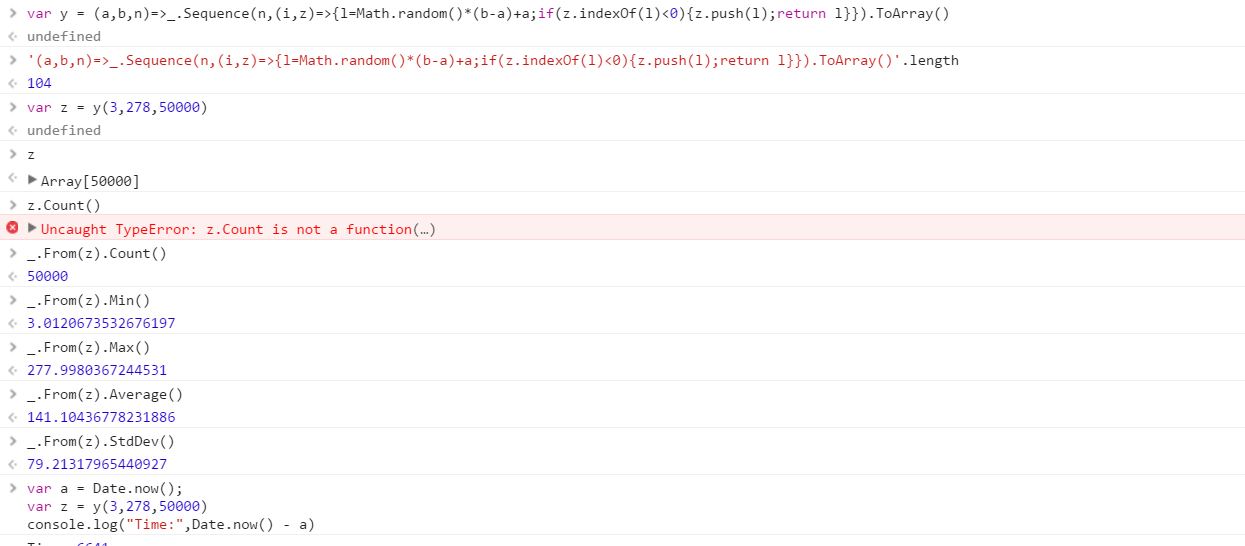
EDIT: The below image shows code / performance that guarantees every element will be distinct. It's much much slower (6.65 seconds for 50,000 elements) vs the original code above for same args (0.012 seconds)
{kind=link}
K (oK), 14 bytes
Solution:
{y+(-x)?1+z-y}
Example:
> {y+(-x)?1+z-y}. 10 10 20 / note: there are two ways to provide input, dot or
13 20 16 17 19 10 14 12 11 18
> {y+(-x)?1+z-y}[10;10;20] / explicitly with [x;y;z]
12 11 13 19 15 17 18 20 14 10
Explanation:
Takes 3 implicit inputs per spec:
x, count of numbers in output set,y, lower limit (inclusive)z, upper limit (inclusive)
{y+(-x)?1+z-y} / the solution
{ } / lambda function with x, y and z as implicit inputs
z-y / subtract lower limit from upper limit
1+ / add 1
(-x)? / take x many distinct items from 0..(1+z=y)
y+ / add lower limit
Notes:
Also a polyglot in q/kdb+ with an extra set of brackets: {y+((-)x)?1+z-y} (16 bytes).
Axiom + its library
f(n:PI,a:INT,b:INT):List INT==
r:List INT:=[]
a>b or n>99999999 =>r
d:=1+b-a
for i in 1..n repeat
r:=concat(r,a+random(d)$INT)
r
The above f() function return as error the empty list, in the case f(n,a,b) with a>b. In other cases of invalid input, it not run with one error message in Axiom window, because argument will be not of the right type. Examples
(6) -> f(1,1,5)
(6) [2]
Type: List Integer
(7) -> f(1,1,1)
(7) [1]
Type: List Integer
(10) -> f(10,1,1)
(10) [1,1,1,1,1,1,1,1,1,1]
Type: List Integer
(11) -> f(10,-20,-1)
(11) [- 10,- 4,- 18,- 5,- 5,- 11,- 15,- 1,- 20,- 1]
Type: List Integer
(12) -> f(10,-20,-1)
(12) [- 4,- 5,- 3,- 4,- 18,- 1,- 2,- 14,- 19,- 8]
Type: List Integer
(13) -> f(10,-20,-1)
(13) [- 18,- 12,- 12,- 19,- 19,- 15,- 5,- 17,- 19,- 4]
Type: List Integer
(14) -> f(10,-20,-1)
(14) [- 8,- 11,- 20,- 10,- 4,- 8,- 11,- 3,- 10,- 16]
Type: List Integer
(15) -> f(10,9,-1)
(15) []
Type: List Integer
(16) -> f(10,0,100)
(16) [72,83,41,35,27,0,33,18,60,38]
Type: List Integer
Explore related questions
See similar questions with these tags.