Create the shortest program/function/whatever that splits an inputted string along un-nested commas. A comma is considered nested if it is either within parentheses, brackets, or braces.
Input and output
Output should be a list or a string joined with linebreaks. The input may contain any characters. All testcases will have valid/balanced parentheses, brackets, and braces. There will also not be two adjacent commas, nor will there be commas at the start or end. Also, all inputs will be valid, printable ASCII characters from ' ' to '~' (no tabs or linebreaks).
Test cases:
"asd,cds,fcd"->["asd","cds","fcd"]
"(1,2,3)"->["(1,2,3)"]
"(1),{[2,3],4}"->["(1)","{[2,3],4}"]
"(1),[2]{3}"->["(1)","[2]{3}"]
"(1),((2,3),4)"->["(1)","((2,3),4)"]
"(1),(4,(2,3))"->["(1)","(4,(2,3))"]
Example program:
function f(code){
code = code.split(',');
let newCode = [];
let last = "";
for (part of code){
if (last.split("(").length == last.split(")").length && last.split("[").length == last.split("]").length && last.split("{").length == last.split("}").length){
last = part;
newCode.push(part);
}
else{
last += "," + part;
newCode[newCode.length - 1] = last;
}
}
return newCode;
}<input id=in oninput="document.getElementById('out').innerText=f(this.value).join('\n')">
<p id=out></p>23 Answers 23
Excel (ms365), 186 bytes
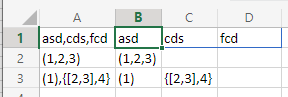{kind=link}
Formula in B1:
=TEXTSPLIT(@REDUCE(VSTACK(A1,0),SEQUENCE(LEN(A1)),LAMBDA(a,b,LET(c,MAX(a),d,MID(@a,b,1),IF(d=",",IF(c,a,VSTACK(REPLACE(@a,b,1,"|"),c)),VSTACK(@a,c+IFERROR(FIND(d,")}]|[{(")-4,)))))),"|")
The idea I started of with here was that I needed a ticker-system. REDUCE() gave me the option to keep this ticker counting and thus decide if a comma was nested within paranthesis or not. A fair chance that this specific idea lead me to use quite a bit of bytes.
I do believe there will be a fair bit of golfing possible here.
JavaScript (ES6), 79 bytes
-2 thanks to @tsh
70 bytes if we assume there's no linefeed in the input and use it as a separator in the output (also suggested by tsh)
The code includes the unprintable character SOH.
s=>s.replace(/(,)|([([{])|[)\]}]/g,(s,c,o)=>(c?d:o?++d:d--)?s:``,d=0).split``
Commented
Regular expression
regex = /(,)|([([{])|[)\]}]/g
// \_/ \_____/ \__/
// | | |
// | | +---> closing character (not captured)
// | +----------> opening character (captured)
// +----------------> comma (captured)
Function
s => // s = input string
s.replace( // replace in s:
regex, // we match either a comma, an opening character,
// or a closing character (see above)
( //
s, // s = matched character
c, // c = defined if this is a comma
o // o = defined if this is an opening character
) => //
( c ? // if this is a comma:
d // leave the nesting depth unchanged
: // else:
o ? // if this is an opening character:
++d // pre-increment the depth
: // else:
d-- // post-decrement the depth
) ? // if the above test returns a non-zero depth:
s // leave the character unchanged
: // else:
'1円', // replace it with SOH
d = 0 // start with d = 0
).split('1円') // end of replace(); split on SOH characters
-
2\$\begingroup\$ That is valid. I added a line about it to my original question. \$\endgroup\$Dadsdy– Dadsdy2023年06月05日 18:20:22 +00:00Commented Jun 5, 2023 at 18:20
-
1\$\begingroup\$
s=>s.replace(/(,)|([([{])|[)\]}]/g,(s,c,o)=>(c?d:o?++d:d--)?s:`/n`,d=0).split`/n`is 79 bytes. And I would argue that you can omit the.splitpart. \$\endgroup\$tsh– tsh2023年06月06日 07:59:45 +00:00Commented Jun 6, 2023 at 7:59 -
\$\begingroup\$ I'd say you can use linebreaks as seperators (partly because it will make my own (,) answer easier) \$\endgroup\$Dadsdy– Dadsdy2023年06月11日 04:47:09 +00:00Commented Jun 11, 2023 at 4:47
Funciton, 1396 bytes
(The byte count uses UTF-16 and includes the BOM. UTF-8 is bigger, unfortunately.)
┌┐ ╓─╖ ┌──┐
┌┘├─╢Ṕ╟─┐ ┌─┤ ┌┴╖
┌┘┌┴╖╙┬╜┌┴╖│┌┴╖│♯║
│┌┤·╟┐└─┤·╟┤│♭║╘╤╝┌┐
││╘╤╝└─┐╘╤╝│╘╤╝┌┴╖└┤╔═╗
││ ├──┐└─┘ └┐└─┤?╟─┼╢4║
││╔╧╗┌┴┐ └┐ ╘╤╝ │╚═╝
││║2║└┬┘ ┌┴╖┌┴╖┌┴╖┌─╖╔═══════╗
││║0║┌┴─────┤·╟┤·╟┤·╟┤ʘ╟╢1063382║
││║9║│ ┌─╖ ╘╤╝╘╤╝╘╤╝╘╤╝║7738808║
││║7║└─┤!!╟┐ │ ┌┘┌┐├──┴┐║3063189║
││║1║ ╘╤╝│ │┌┴╖└┴┼─┐ │║1329769║
││║5║ ┌┴╖│ ┌┴┤?╟──┘╔╧╗│║3925556║
││║1║┌─┤·╟┘┌┴┐╘╤╝ ║0║│║879404 ║
││╚═╝│ ╘╤╝ └┬┘┌┴╖┌┐ ╚═╝│╚═══════╝
││ ┌┘ ┌┴╖ └┬┤·╟┤├────┘
│└┐┌┴╖┌┤«║ ┌┘╘╤╝└┘
│┌┴┤»║│╘╤╝ ┌┴╖┌┴╖
││ ╘╤╝│┌┴╖┌┤?╟┤Ṕ╟┐
││ │ └┤·╟┘╘╤╝╘╤╝│
││ │ ╘╤╝ ┌┴╖┌┴╖│╔═══╗
││ └───┘ ┌┤«╟┤·╟┼╢−21║
││┌───────┘╘═╝╘╤╝│╚═══╝
│└┤ ┌┴╖└┐
│ └───────────┤?╟┬┘
│ ╘╤╝│
└────────────────┘
Oh boy, what an ungolfable language. I tried really hard to move things around to eke out a few bytes but this is the most compact arrangement I was able to find.
Funciton has two ways of representing collections: "sequences" and "lists". I’m taking the challenge statement literally and made a function that returns a list of the results.
Here’s how the function (Ṕ) works:
- The function takes three parameters:
s, the input string;n, a running count of currently-open parentheses/brackets/braces; andl, the list we’re constructing.
- The function must initially be called with
n= 0 andl= 1. The integer 1 here represents a one-element list containing a 0, and 0 in turn represents the empty string. - If
sis empty, we just returnl. - Otherwise, let
cbe the first character ofs, and letibe the index ofcwithin the string",([{)]}"(this is the big box on the right).iis −1 if the character is not in there. - Now perform a recursive call with the following parameters:
sbecomes the rest of the string with the first character removed.- If
i> 0, then: { ifi< 4, then we’re looking at an opening parenthesis, so incrementn; else, we’re looking at a closing parenthesis, so decrementn; } else, we’re looking at a comma (i= 0) or something else (i= −1), so leavenunchanged. - If
ibitwise-ornis 0, this means thati= 0 (we’re seeing a comma) andn= 0 (we are not in a parenthesis), so append an empty string tol. Otherwise, appendcto the last string inl.
An interesting golfing trick I used: See the −21 in the bottom-right? That’s used to do a shift-right by 21 on the input string s (this removes its first character). This construct uses the raw syntax (┼) which means it can also compute a "less-than" operation. Since s is certainly non-negative, it will never be less than −21, so this will always return 0. I re-use that 0 as the empty string to be appended to the list when a comma is encountered. This allowed me to save an entire 0 literal box, as well as the loop-de-loop I would otherwise need to swallow the less-than result.
To actually run this code, you need a program that calls the function, so here’s one provided for convenience. It’s not golfed and it’s not included in the byte count because the challenge only asked for the function.
╔═══╗
║ 0 ║
╚═╤═╝
╔═══╗ ┌─┴─╖ ╔═══╗
║ 1 ╟─┤ Ṕ ╟─╢ ║
╚═══╝ ╘═╤═╝ ╚═══╝
┌─┴─╖
│ ⌡ ║
╘═╤═╝
┌─┴─╖
│ ʝ ╟─
╘═╤═╝
╔═╧══╗
║ 10 ║
╚════╝
This program calls Ṕ with stdin, 0, and 1; uses ⌡ to convert the list to a sequence; and then uses ʝ to join the strings with newlines (ASCII #10).
Retina 0.8.2, 34 bytes
!`([({[]()|[]})](?<-2>)|2,円|[^,])+
Try it online! Link includes test cases. Explanation:
!`
Output the matches themselves rather than the count of matches, which is the default for a match stage, a match stage being the default for a single-line program.
([({[]()|[]})](?<-2>)|2,円|[^,])+
Match as many as possible of...
[({[]()
... an opening bracket, which increases the nesting level, tracked in $#2, ...
[]})](?<-2>)
... an assumed matching closing bracket, which decreases the nesting level, ...
2,円
... a comma, but only if we are nested, ...
[^,]
... or failing that, any non-comma.
The same regex would work in Retina 1 but you would have to use a List stage instead for the the same length.
-
\$\begingroup\$ Those brackets at the beginning look like Brain-Flak \$\endgroup\$Joao-3– Joao-32024年01月05日 14:09:56 +00:00Commented Jan 5, 2024 at 14:09
Java 11, 157 bytes
s->{var t="";for(var p:(s+",x").split(","))if(t.split("[\\[({]",-1).length==t.split("[)}\\]]",-1).length){if(t!="")System.out.println(t);t=p;}else t+=","+p;}
Inspired by @Dadsdy's JavaScript answer, so make sure to upvote him/her as well!
Outputs the parts on separated newlines to STDOUT.
Explanation:
s->{ // Method with String parameter and no return-type
var t=""; // Temp-String, starting empty
for(var p:(s+",x") // ††Concat ",x" to the input
.split(","))// Then split it on ",", and loop over the parts:
if(t.split("[\\[({]",-1).length==t.split("[)}\\]]",-1).length){
// †If String `t` has balanced brackets:
if(t!="") // †††If `t` is NOT empty (so it's not the first iteration):
System.out.println(t);
// Print the current `t` with newline
t=p;} // Replace the `t` with the current `p` for the next iteration
else // Else:
t+=","+p;} // Append a "," and the current `p` to `t` for the next iteration
†: The -1 in the String#split are to include empty Strings, when a part p starts with an opening bracket or ends with a closing bracket.
††: We concat an , to the input-String before splitting, in order to have an additional iteration of the loop. The additional x (could have been any character) is a golfed shortcut for ,-1 in the split of the input.
†††: In Java you'd almost always have to use String#equals when comparing Strings. In this case however, where we only want to skip the first iteration when t is still empty, we can use !="" to check whether not just the value but also the reference is the same. This is possible here, because String literals point to the same reference point in memory, so the "" in both t="" and !="" are the same in memory.
-
1\$\begingroup\$ Welcome to Code Golf, and nice first answer! \$\endgroup\$The Thonnu– The Thonnu2023年08月21日 10:36:39 +00:00Commented Aug 21, 2023 at 10:36
Charcoal, 28 bytes
≔0θFS«≧+−No([{ιNo}])ιθ¿θι≡,ι⸿ι
Try it online! Link is to verbose version of code. Explanation:
≔0θ
Start with zero nesting level.
FS«
Loop over the characters.
≧+−No([{ιNo}])ιθ
Adjust the nesting level depending on whether the characters is an open or close bracket.
¿θι≡,ι⸿ι
Output the character if it is nested or not equal to a comma, but replace an unnested comma with a newline.
Alternative approach, also 28 bytes:
⭆θ⎇›=ι,⊙⪪()[]{}2↨EλNo...θκν±1¶ι
Try it online! Link is to verbose version of code. Explanation: Inspired by @AndrovT's Vyxal answer.
θ Input string
⭆ Map over characters
⎇ Ternary
ι Current character
= Equals
, Literal string `,`
› Is greater than
()[]{} Literal string of brackets
⪪ 2 Split into pairs of brackets
⊙ Any pair satisfies
λ Current pair of brackets
E Map over brackets
No Count of
ν Current bracket in
θ Input string
... Truncated to length
κ Outer index
↨ ±1 Has a non-zero difference
¶ If true then newline
ι Else current character
Implicitly print
SNOBOL 4, 126 bytes
I haven't really tried to golf this beyond using single-letter names. Well, I guess there is one little trick. Parsing lists of items separated by commas is usually something like item arbno(',' item) (i.e., an item followed by an arbitrary number of repetitions of a comma and another item. Here I've cheated a little bit instead, and added a comma to the beginning of the input, so we can parse the resulting list with code like: arbno(',' item)
L = ARBNO(ARBNO(NOTANY('([{}])')) | '(' *L ')' | '[' *L ']' | '{' *L '}')
I = ',' INPUT
I ARBNO(',' L . OUTPUT) RPOS(0)
END
Each item in the result is printed on a new line.
Then there's the cheating version that semi-sorta works, and reduces the size to 72 bytes:
REPLACE(',' INPUT, "[]{}", "()()" ) ARBNO(',' BAL . OUTPUT) RPOS(0)
END
SNOBOL has a built-in function to match strings with balanced parentheses (but not brackets or braces). This replaces brackets/braces with parens, then matches and prints those out (which will otherwise match the correct output). For example, for the test input: (1),{[2,3],4}, this prints out:
(1)
((2,3),4)
General explanation:
Regular expressions are based on SNOBOL patterns.
NOTANY('abcd')is about the same as[^abcd]in a regexarbno(foo)is about likefoo*in a regex- RPOS(0) is like
$at the end of a regex--matches only if the rest of the pattern matches the whole string.
string1 string2 concatenates the two strings.
string pattern attempts to match the pattern against the string. The result will be the matched substring.
Then a rather strange SNOBOL thing. string pattern . variable matches pattern against string, then assigns the resulting substring to variable. In our case, we assign to output, so this prints out each matching substring.
On, I almost forgot. Formatting. SNOBOL is roughly concurrent with FORTRAN, and uses similar formatting: the only things that can go in column 0 or labels (that can be used as targets of jumps). Lines without labels have to start with a space character.
05AB1E, (削除) 23 (削除ここまで) (削除) 21 (削除ここまで) 20 bytes
-3 thanks to @Kevin Cruijssen
',¡.œ',δý.ΔεžuS¢ιË}P
Explanation
', push a comma
¡ and split the implicit input by it
.œ push all partitions, all possible ways to split it to continuous parts
',δý and join each partition with commas.
.Δ now keep (and implicitly output) the first partition such that:
ε for each of its parts
žu push "()<>[]{}"
S list of characters, ["(", ")", "<", ...]
¢ count each of the characters in the current part
ι uninterleave it, put the count of the even indices (opening brackets) and the odd ones (closing brackets) in two lists
Ë and check if the two lists are equal - the number of opening brackets of each type is equal to the number of closing ones.
}
P take the product, which functions as and.
-
1\$\begingroup\$
',¡.œ',δý.ΔεSžuS¢ιË}P- 21 bytes \$\endgroup\$Kevin Cruijssen– Kevin Cruijssen2023年06月05日 07:36:38 +00:00Commented Jun 5, 2023 at 7:36 -
1\$\begingroup\$ @KevinCruijssen thanks! The
Safter the map seems unnecessary. \$\endgroup\$Command Master– Command Master2023年06月07日 12:49:16 +00:00Commented Jun 7, 2023 at 12:49
JavaScript (Node.js), 75 (削除) 86 (削除ここまで) (削除) 98 (削除ここまで) bytes
-12 bytes after realizing the string is balanced, so there is always the correct matching ending character for each type of block (and removing some unnecessary parentheses)
-11 bytes after the added possibility to output the list as a string joined with linebreaks
(Solution without regex)
Nice challenge :)
s=>[...s].map(c=>c==","&!(a+=("{[()]}".indexOf(c)+4)%7-3)?`
`:c,a=0).join``
A little explanation:
We parse each character of the input string.
For each character, the code ("{[()]}".indexOf(c)+4)%7-3 gives
+1, +2 or +3 respectively for { [ (,
-3, -2 or -1 respectively for ) ] }, and 0 if it's another character.
We increment (or decrement) our "nesting height counter" using this result.
If the counter is 0 (meaning, when we are currently outside of a block) and the current character is a , then we replace it with a \n.
A , at heights higher than 0 is kept without transformation.
Then at the end, we join everything to get the wanted output.
-
1\$\begingroup\$ Nicely done with the counter. This is exactly what I had in mind and tried to implement myself in Excel. \$\endgroup\$JvdV– JvdV2023年06月05日 12:42:33 +00:00Commented Jun 5, 2023 at 12:42
-
\$\begingroup\$ @JvdV Thanks! Credits go to my past teachers for that counter :D Actually i don't know any other way of checking if we're outside of a block (aside from using regex, of course). Regarding your Excel answer, i hope you'll get feedbacks from specialists like TaylorAlexRaine ! \$\endgroup\$Fhuvi– Fhuvi2023年06月05日 13:08:10 +00:00Commented Jun 5, 2023 at 13:08
-
\$\begingroup\$ I just noticed that if you have two adjacent commas it doesn’t work \$\endgroup\$Dadsdy– Dadsdy2023年07月25日 23:32:22 +00:00Commented Jul 25, 2023 at 23:32
-
\$\begingroup\$ @Dadsdy Yes but you specified in the challenge that "There will also not be two adjacent commas", so i used that fact on purpose :) \$\endgroup\$Fhuvi– Fhuvi2023年07月26日 06:36:17 +00:00Commented Jul 26, 2023 at 6:36
-
\$\begingroup\$ @Fhuvi I forgot about that somehow \$\endgroup\$Dadsdy– Dadsdy2023年07月26日 06:57:39 +00:00Commented Jul 26, 2023 at 6:57
ATOM (削除) 103 (削除ここまで) 100 bytes, (削除) 99 (削除ここまで) 96 chars
{a=*/",";i=0;📏*∀{a.i🚪{📏(*/"("+*/"["+*/"{")!=📏(*/")"+*/"]"+*/"}")}:a.i+=","+a.(i+1);a-(i+1),i+=1};a}
Version 2
Saving a few characters by storing i+1 as a separate variable
{a=*/",";i=0;📏*∀{j=i+1;a.i🚪{📏(*/"("+*/"["+*/"{")!=📏(*/")"+*/"]"+*/"}")}:a.i+=","+a.j;a-j,i=j};a}
Usage
s="(1),{[2,3],4}";
s INTO {a=*/",";i=0;📏*∀{a.i🚪{📏(*/"("+*/"["+*/"{")!=📏(*/")"+*/"]"+*/"}")}:a.i+=","+a.(i+1);a-(i+1),i+=1};a}
Try it online
Explaination
It begins by splitting the original string by the comma into an array. It creates an iterator, and goes through each element in the created array. If the number of opening and closing symbols do not match, it will merge the current array element with the next one. If they do match, it will continue onwards. By the end of the iteration, all array elements should be correct, and it returns the final result.
Commented and organized code
{
a=*/","; # Split the input by the comma
i=0; # Declare an iterator
📏* FOREACH { # Repeat the following function based on the length of the string
a.i INTO {📏(*/"("+*/"["+*/"{")!=📏(*/")"+*/"]"+*/"}")}: # Check if the opening and closing characters match in the current item
a.i+=","+a.(i+1); # If there is not a match, add the next element to the current one
a-(i+1), # Remove the next element from the array and continue the loop
i+=1 # Else, increment the counter
};
a # Return the final array
}
Python, 110 bytes
f=lambda i,p=1,a=[],c="":i and f(i[1:],p+((q:=i[0])in"([{")-(q in")]}"),a+[c][(x:=q!=p*","):],(c+q)*x)or a+[c]
Defines a recursive function f. The parameter p is the number of open parenthesis plus one, a is the accumulator for the output list and c is the accumulator for the current string.
If i is nonempty we recurse, possibly adding or subtracting one from the parenthesis count p. If p is equal to 1 and we are on top of a comma we append c to a and clear the value of c. Otherwise we append q=i[0] to c.
If i is empty we just return a+[c]
Jelly, 22 bytes
="([{"}])"§_/)Ä<=",$œp
Jelly and multiple brackets + non-brackets are not friends
) For each character in the input:
= is it equal to each of
"([{"}])" ["([{", "}])"]?
§ Sum the results from each half,
_/ and take their difference,
="([{"}])"§_/) yielding 1 for opening, -1 for closing, or else 0.
Ä Cumulative sum, for depths.
< Is each character's depth strictly less than
=",$ whether or not it's a comma?
œp Split the input around those positions.
Python, (削除) 120 (削除ここまで) (削除) 118 (削除ここまで) 112 bytes
def q(s):
d,*L,p=0,''
for c in s:d+=c in'{[(';d-=c in'}])';p,L=[[p+c,L],['',L+[p]]][1>d!=c==',']
return L+[p]
I realize this loses to the current Python answer by 2 bytes but I liked that it was an uncomplicated implementation of the most intuitive algorithm and wanted to add it.
6 bytes saved thanks to xnor.
Ungolfed it's pretty self-explanatory:
def split_string(s: str) -> list[str]:
depth = 0
piece = ''
L = []
for c in s:
depth += c in '{[('
depth -= c in '}])'
if depth == 0 and c == ',':
L += [piece]
piece = ''
else:
piece += c
return L + [piece]
Note that the last + [piece] depends on the promise that the string doesn't end on ,.
Also, I switched to a function because I realized that with input and print the code doesn't actually output a list, but rather prints something that would be as difficult to work with as the input. :) Otherwise, the solution would be the winning Python one at 105 bytes (ATO):
d,*L,p=0,''
for c in input():d+=c in'{[(';d-=c in'}])';p,L=[[p+c,L],['',L+[p]]][1>d!=c==',']
print(L+[p])
-
\$\begingroup\$ Hi! Here's some tricks to help you cut those 8 bytes. The empty list can be assigned using unpacking as
d,*L,p=0,''. Anif/elsecan generally be shortened to a list selector[_,_][condition]. Though reassigningpandLat once lets you write the condition only once, it's likely shorter to save the condition to a Boolean variable and reassignpandLseparately. The condition(d,c)==(0,',')can be chained as1>d!=c==',', but I encourage you to look for shorter ways to combine the two checks. \$\endgroup\$xnor– xnor2023年06月08日 23:23:25 +00:00Commented Jun 8, 2023 at 23:23 -
\$\begingroup\$ @xnor Thanks! Implemented all three (though without splitting the p,L assign) and saved 6 bytes. \$\endgroup\$Luke Sawczak– Luke Sawczak2023年06月08日 23:45:47 +00:00Commented Jun 8, 2023 at 23:45
-
\$\begingroup\$ 111 bytes with extended list slicing: tio.run/… \$\endgroup\$squareroot12621– squareroot126212024年07月22日 18:56:39 +00:00Commented Jul 22, 2024 at 18:56
-
\$\begingroup\$ 110 bytes by stealing the first slicing parameter from a Jelly answer: tio.run/… \$\endgroup\$squareroot12621– squareroot126212024年07月22日 19:05:48 +00:00Commented Jul 22, 2024 at 19:05
Javascript, (削除) 140 (削除ここまで) (削除) 132 (削除ここまで) 114 Bytes
Thanks to @KevinCruijssen for -8 Bytes!
c=>(n=[],l="",(c+',').split`,`.map(p=>l=a(/[([{]/)>a(/[)\]}]/)?l+','+p:(l&&n.push(l),p)),n);a=r=>l.split(r).length
-
\$\begingroup\$
p of (c+',')can bep of(c+',')for -1;split(',')can besplit`,`for -2;/\(|\[|\{/can be/[([{]/for -3;/\)|\]|\}/can be/[)}\]]/for -2. \$\endgroup\$Kevin Cruijssen– Kevin Cruijssen2023年06月05日 07:03:25 +00:00Commented Jun 5, 2023 at 7:03 -
\$\begingroup\$ @KevinCruijssen I just knew that the regexes could be so much shorter! Thanks. \$\endgroup\$Dadsdy– Dadsdy2023年06月05日 18:11:58 +00:00Commented Jun 5, 2023 at 18:11
-
\$\begingroup\$ Welcome to Code Golf, and nice answer! \$\endgroup\$2023年08月23日 04:26:47 +00:00Commented Aug 23, 2023 at 4:26
Scala, (削除) 140 (削除ここまで) 131 bytes
Golfed version. Try it online!
s=>(""/:(s+",x").split(",")){(t,p)=>if(t.split("[\\[({]").length==t.split("[)}\\]]").size){if(t.nonEmpty)println(t);p}else t+","+p}
Ungolfed version. Try it online!
object Main extends App {
type N = (String) => Unit
val n: N = (s: String) => {
var t = ""
for (p <- (s + ",x").split(",")) {
if (t.split("[\\[({]", -1).length == t.split("[)}\\]]", -1).length) {
if (t.nonEmpty) println(t)
t = p
}
else t += "," + p
}
}
val testCases = Array("asd,cds,fcd", "(1,2,3)", "(1),{[2,3],4}")
for (testCase <- testCases) {
println(s"Input: $testCase")
println("Output: ")
n(testCase)
println()
}
}
Arturo, 81 bytes
$=>[i:0loop split&'c->'i+dec/??index"([{^_^}])"c<=3prints(∧c=","0=i)?->"\n"->c]
$=>[ ; a function; assign arg to &
i:0 ; assign 0 to i
loop split&'c-> ; loop over input string; assign current letter to c
'i+ ; increment i in place by...
dec ; ...one less than...
index"([{^_^}])"c ; index of c in the string literal
?? ... 3 ; if this is null, replace it with 3
<=3 ; duplicate 3
/ ... 3 ; integer divide by 3
prints ; print the following w/o newline
(∧c=","0=i)? ; is c a comma and is i 0?
->"\n" ; newline
->c ; otherwise, c
] ; end function
Java (JDK), 107 (削除) 110 (削除ここまで) (削除) 122 (削除ここまで) bytes
-12 bytes after the added possibility to output the list as a string joined with linebreaks
-3 bytes thanks to ceilingcat
Port of my JS answer, see explanations here
s->{var r="";int a=0;for(var c:s.toCharArray())r+=c==44&(a+=("{[()]}".indexOf(c)+4)%7-3)==0?10:c;return r;}
Python:
import re
def split_string(s):
return re.split(r',(?![^(){}[\]]*[)\]}])', s)
JavaScript:
function splitString(s) {
return s.split(/,(?![^(){}[\]]*[)\]}])/);
}
Ruby:
def split_string(s)
s.split(/,(?![^(){}[\]]*[)\]}])/)
end
Java:
import java.util.regex.Pattern;
public class SplitString {
public static String[] splitString(String s) {
return s.split(",(?![^(){}\\[\\]]*[)\\]}])");
}
}
C++:
#include <iostream>
#include <regex>
#include <vector>
std::vector<std::string> splitString(const std::string& s) {
std::regex regex(",(?![^(){}\\[\\]]*[)\\]}])");
std::sregex_token_iterator iterator(s.begin(), s.end(), regex, -1);
std::sregex_token_iterator end;
return std::vector<std::string>(iterator, end);
}
```
-
4\$\begingroup\$ Welcome to Code Golf! This site is for competitive coding challenges, so answers should be attempts to solve the challenge with the shortest code possible in a language (or optimize some other criterion specified by the challenge). \$\endgroup\$2023年06月07日 20:42:43 +00:00Commented Jun 7, 2023 at 20:42
-
\$\begingroup\$ The regex doesn't seem to work with (1),(1,(2,3),4). regex101.com/r/Vcxitq/1 \$\endgroup\$Dadsdy– Dadsdy2023年06月07日 21:11:04 +00:00Commented Jun 7, 2023 at 21:11
Perl 5 (-p), 42 bytes
s/([({[]([^({[]|(?1))*[]})])(*SKIP)^|,/ /g
or +1 byte to avoid catastrophic backtracking
s/([({[]([^({[]|(?1))*?[]})])(*SKIP)^|,/ /g
Haskell + hgl, 36 bytes
cx<<sL","<gXy"[([{]/r*[)}/]]|[^([{]"
Explanation
gXy"[([{]/r*[)}/]]|[^([{]"tokenize the string using a regex. Each token is either a balanced string starting and ending with a brace, or a single (non-brace) character.sL","split the tokens along commas.cxconcat the tokens back to strings.
"A,[B](C)" -> ["A","[B][C]"]a valid test case? Or are balanced groups guaranteed to be separated by a comma? \$\endgroup\$"(1),((2,3),4)"->["(1)","((2,3),4)"](makes my naive answer fail ... I need another coffee). \$\endgroup\$