This is a rewrite of the (currently closed) "Debunking Stroustrup's debunking of the myth "C++ is for large, complicated, programs only"" challenge.
Challenge
Write the shortest program or function that will:
- Download
http://www.stroustrup.com/C++.html, and - List all URLs contained in the HTML document.
A "URL" for this challenge is
- some string of characters
- contained in the
hrefattribute of an<a>tag - that starts with
http://orhttps://.
So <a href="someotherpage.html"> doesn't have a URL, but <a href="http://someotherpage.html"> does.
Additional Rules
- You may assume the downloaded HTML is valid.
- You may not assume the input is static: you must download the page each time your code is run.
- (as a consequence of above) You may not hardcode the output URLs: this is not kolmogorov-complexity, this is parsing.
- You may use either
http://www.stroustrup.com/C++.htmlorhttps://www.stroustrup.com/C++.htmlas your source URL.
Validation
The first 5 URLs on the page (based on a snapshot of the site on April 3, 2023) are:
https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md
http://webhostinggeeks.com/science/programming-language-be
https://coderseye.com/stroustrup-the-c-programming-language
http://edutranslator.com/jazyk-programmirovanija-c/
https://pngset.com/uz-cplusplus
There are 91 URLs in this particular snapshot.
18 Answers 18
Windows PowerShell, (削除) 70 (削除ここまで) (削除) 63 (削除ここまで) 61 bytes
Try it in a PowerShell Console (works in PowerShell Core 7.3 on Windows as well, but not in TIO)
(iwr www.stroustrup.com/C++.html|% L*).href-match'^https?://'
Ungolfed:
(Invoke-WebRequest -Uri 'http://www.stroustrup.com/C++.html' | ForEach-Object -MemberName Links).href -match '^https?://'
Nothing remarkable (except that PS is somewhat competitive here) going on; iwr is an alias for Invoke-WebRequest, the object returned is passed to % (an Alias for ForEach-Object) which will call the object's member Links (the only one matching L*). href contains the parsed URL, and the -match weeds out local links as requested.
Edit: Removed the http:// (-7 bytes), fixed the regex, replaced Link property with ForEach-Object; thanks to @Julian
Edit: -2 bytes thanks to thanks to @spookycoder: removed the quotes around the uri (d'oh).
-
1\$\begingroup\$ The
http://www.can be omitted andLinkscan be shortened to|% L*:(iwr 'stroustrup.com/C++.html'|% L*).href-match'^https?://', I also changed the regex to '^https?://' so that http links would be taken in account too? \$\endgroup\$Julian– Julian2023年04月28日 03:34:52 +00:00Commented Apr 28, 2023 at 3:34 -
1\$\begingroup\$ @Julian thanks for noticing; I swear I had the
?in the regex when I was counting the results with| measure. Thewwwcan't be omitted, as the response will then be coming fromhttps://stroustrup.com/C++.html, and the rules explicitly include the www. \$\endgroup\$user314159– user3141592023年04月28日 12:03:13 +00:00Commented Apr 28, 2023 at 12:03 -
1\$\begingroup\$ you may ommit the single quotes around the link for saving additional 2 bytes \$\endgroup\$spookycoder– spookycoder2023年04月29日 18:00:21 +00:00Commented Apr 29, 2023 at 18:00
pup, (削除) 72 (削除ここまで), (削除) 70 (削除ここまで), 63 bytes
curl -sL stroustrup.com/C++.html |
pup 'a[href^=http] attr{href}'
-
\$\begingroup\$ I think changing the second line to
pup 'a[href^=http] attr{href}'and getting rid of thegrepline is a couple of bytes shorter (not tested) \$\endgroup\$noodle person– noodle person2023年04月28日 11:40:13 +00:00Commented Apr 28, 2023 at 11:40 -
\$\begingroup\$ @Jacob: right you are, thanks \$\endgroup\$Thor– Thor2023年04月28日 12:20:30 +00:00Commented Apr 28, 2023 at 12:20
-
1\$\begingroup\$ You’ll want to get rid of
grepfrom the title as well. \$\endgroup\$noodle person– noodle person2023年04月28日 13:01:59 +00:00Commented Apr 28, 2023 at 13:01 -
1\$\begingroup\$
http://is not needed with-L. Anyway nice job on the cleanest looking solution. \$\endgroup\$qwr– qwr2023年04月29日 01:21:30 +00:00Commented Apr 29, 2023 at 1:21 -
\$\begingroup\$ You might be able to get rid of the newline too. \$\endgroup\$qwr– qwr2023年04月29日 01:24:47 +00:00Commented Apr 29, 2023 at 1:24
Factor 0.98 + html.parser.analyzer http.client, (削除) 143 (削除ここまで) (削除) 132 (削除ここまで) (削除) 128 (削除ここまで) (削除) 124 (削除ここまで) 93 bytes
[ "stroustrup.com/C++.html"http-get parse-html find-hrefs
[ protocol>> "http"head? ] filter ]
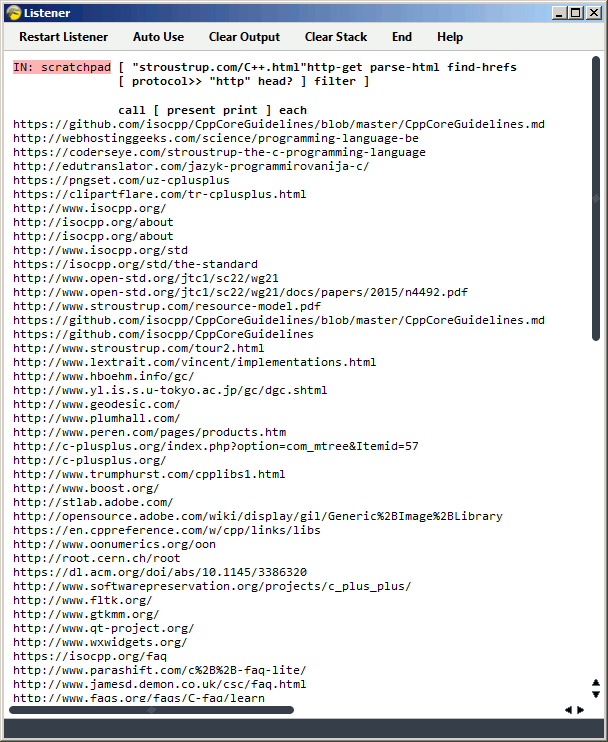{kind=link}
A function that returns a list of URLs.
"stroustrup.com/C++.html"http-getpush the http response and the raw html (as a string) of the url on the data stackparse-htmlparse the html into a sequence of tag tuplesfind-hrefsget all hrefs on the page as URLs[ protocol>> "http"head? ] filterselect the URLs whose protocols start withhttp
Bash, (削除) 50 (削除ここまで) (削除) 48 (削除ここまで) 40 bytes
curl -L stroustrup.com/C++.html|grep tp
Bash, (削除) 64 (削除ここまで) 56 bytes
(-8 thanks to Tihit)
With tags removed
curl -L stroustrup.com/C++.html|grep -oP '"\Khttp[^"]*'
-
1\$\begingroup\$ You can replace
https://www.with-L\$\endgroup\$Thiht– Thiht2023年04月28日 15:17:17 +00:00Commented Apr 28, 2023 at 15:17 -
\$\begingroup\$ Why wouldn't that match "
the tplink router is a good one"? \$\endgroup\$WoJ– WoJ2023年04月29日 12:40:09 +00:00Commented Apr 29, 2023 at 12:40 -
\$\begingroup\$ I can't find the string you are referring to anywhere? \$\endgroup\$Hunaphu– Hunaphu2023年04月29日 16:41:47 +00:00Commented Apr 29, 2023 at 16:41
05AB1E, 53 bytes
žZ.•‹Ìe ̈1w•’.ŒŒ/C++.ŠÎ’J.w'"¡ü2ʒ`žXžY‚Å?às...aØ·=Å¿*}€θ
.w is disabled on TIO, so here are two loose TIO's to verify it's working as intended:
žZ.•‹Ìe ̈1w•’.ŒŒ/C++.ŠÎ’J- Verify the url is correct: try it online.'"¡ü2ʒ`žXžY‚Å?às...aØ·=Å¿*}€θ- Verify the extraction of the URLs from the HTML content and final output is correct: try it online.
Explanation:
žZ # Push builtin constant "http://www."
.•‹Ìe ̈1w• # Push compressed string "stroustrup"
’.ŒŒ/C++.ŠÎ’ # Push dictionary string ".com/C++.html"
J # Join the three strings on the stack together to an URL
.w # Pop and download the HTML content of this URL
'"¡ '# Split it on double quotes '"'
ü2 # Get all overlapping pairs
ʒ # Filter this list of pairs by:
` # Pop and push the strings of the pair to the stack
žX # Push builtin "http://"
žY # Push builtin "https://"
‚ # Pair them together
Å? # Check for both whether the second string starts with these substrings
à # Pop and check if either of the two is truthy
s # Swap so the first string is at the top of the stack
...aØ·= # Push dictionary string "a href="
Å¿ # Check if the first string ends with this substring
* # Check whether both were truthy
}€ # After the filter: map over each overlapping pair:
θ # Leave just the last/second string of each
# (after which the list of URLs is output implicitly)
See this 05AB1E tip of mine (sections How to use the dictionary? and How to compress strings not part of the dictionary?) to understand why ’.ŒŒ/C++.ŠÎ’ is ".com/C++.html"; ...aØ·= is "a href="; and .•‹Ìe ̈1w• is "stroustrup".
Go, 218 bytes
import(."io";."net/http";."regexp")
func f(){r,_:=Get("http://www.stroustrup.com/C++.html")
b,_:=ReadAll(r.Body)
for _,e:=range MustCompile(`<a[^>]+href="(http.+?)"`).FindAllStringSubmatch(string(b),-1){println(e[1])}}
(you cannot) Attempt This Online!
Prints all URLs to STDERR, separated by newlines.
ATO doesn't allow web requests.
Vyxal, (削除) 49 (削除ここまで) (削除) 41 (削除ここまで) 39 bytes
`s≠L·ꜝǓ≥2.•1⁄8/C++.°¤` ̈U`1(ṅ•s?://[^"]+)`Ẏ
Example output from Crosshatch.
-8 by remembering https://www. is automatically appended to links if not present when calling ̈U
-2 by not including the closing " and > in the regex
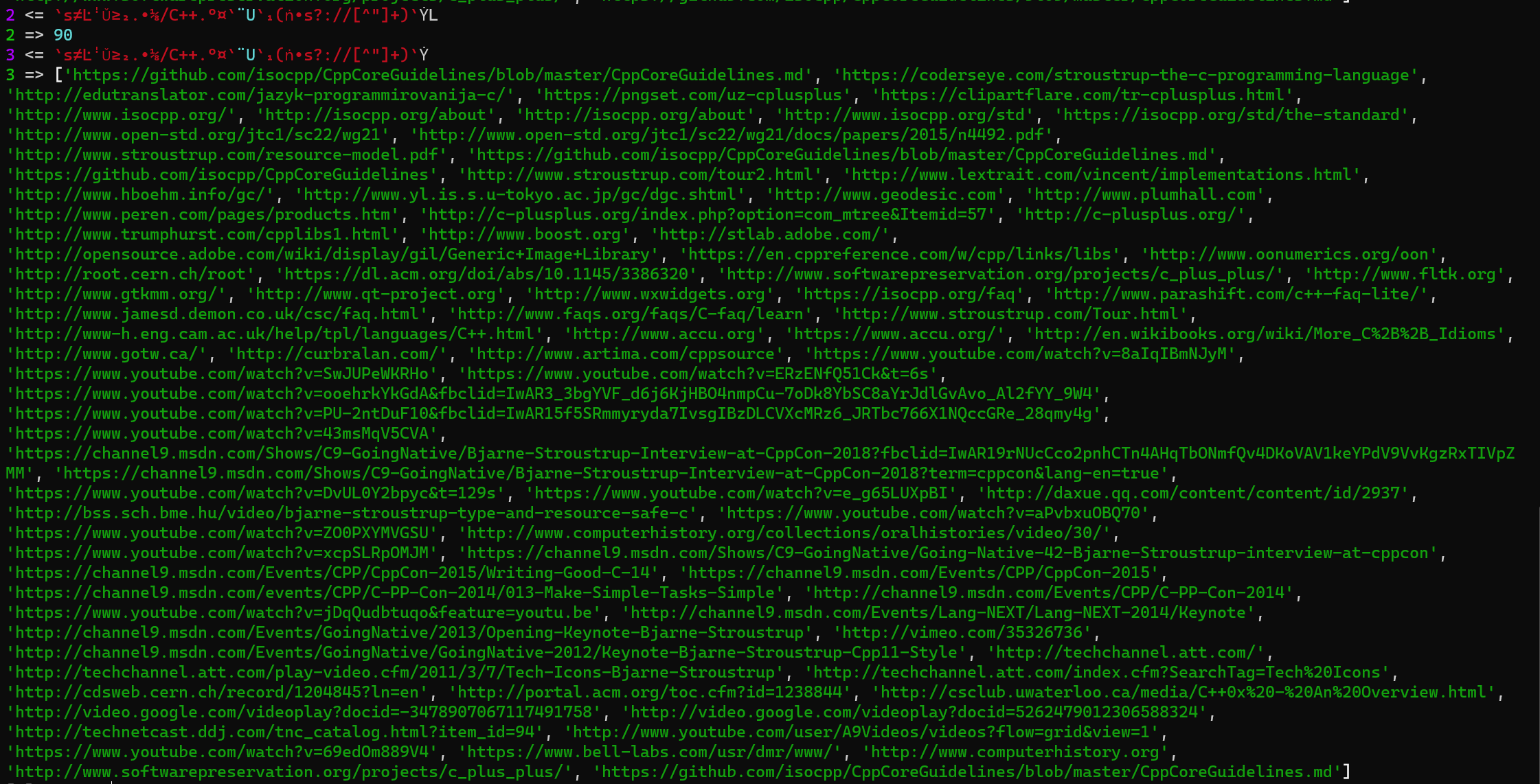{kind=link}
Explained
`s≠L·ꜝǓ≥2.•1⁄8/C++.°¤` ̈U`1(ṅ•s?://[^"]+)`Ẏ
`s≠L·ꜝǓ≥2.•1⁄8/C++.°¤` # stroustrup.com/C++.html
̈U # GET request
`1(ṅ•s?://[^"]+)` # <a href="(https?://[^"]+)
Ẏ # All regex matches
Python3 + requests, 109 bytes:
import requests as r,re
re.findall('a href="(https*[^"]+)',r.get('https://www.stroustrup.com/C++.html').text)
-
1\$\begingroup\$ I think you actually have to use the URL in the question rather than create a function which accepts any URL \$\endgroup\$The Thonnu– The Thonnu2023年04月27日 14:48:45 +00:00Commented Apr 27, 2023 at 14:48
-
\$\begingroup\$ Probably add a
printas well \$\endgroup\$The Thonnu– The Thonnu2023年04月27日 15:24:21 +00:00Commented Apr 27, 2023 at 15:24
C#, 221 bytes
Golfed
using System.Text.RegularExpressions;var r=await new HttpClient().GetStringAsync("https://www.stroustrup.com/C++.html");foreach(Match m in Regex.Matches(r,"<a.\\n?href=\"(https?.*?)(?=\")"))Console.WriteLine(m.Groups[1]);
Ungolfed
using System.Text.RegularExpressions;
var r = await new HttpClient().GetStringAsync("https://www.stroustrup.com/C++.html");
foreach (Match m in Regex.Matches(r, "<a.\\n?href=\"(https?.*?)(?=\")"))
Console.WriteLine(m.Groups[1]);
-
\$\begingroup\$ Welcome to Code Golf, and nice answer! \$\endgroup\$2023年04月28日 14:33:57 +00:00Commented Apr 28, 2023 at 14:33
hyperscript, (削除) 130 101 (削除ここまで) 62 bytes
def f()fetch"C++.html"put it into me return<[href^=ht/>'s@href
This program must be run from the site's root to avoid CORS issues. There is a snippet below that uses a CORS proxy to do the same without running on a different domain.
<script src="https://unpkg.com/[email protected]"></script>
<script type="text/hyperscript">
def f()fetch"//corsproxy.io/?https://stroustrup.com/C++.html"put it into me return<a[href^=ht/>'s@href
init put f().join("<br />") into <body />
</script>Ungolfed:
def f()
fetch "C++.html"
put it into me
return @href of <a [href^="http"] />
end
Usually hyperscript is very verbose, but it's perfect for a challenge like this. This function fetches the HTML, throws it into the <body>, selects all <a> whose href starts with http, and returns each's href. I was somehow able to get rid of almost every single piece of whitespace in the program because hyperscript doesn't need whitespace before or after parenthesis, string, query literal, or attribute literal tokens.
JavaScript (ES6), (削除) 193 ... 121 (削除ここまで) 117 bytes
Big port of my hyperscript answer, parsing HTML by chucking it into the <body>.
This program must be run from the site's root to avoid CORS issues. You can test it by pasting it into the browser console at this page. There is a snippet below that uses a CORS proxy to do the same without running on a different domain.
async _=>((d=document.body).innerHTML=await(await fetch`C++.html`).text(),[...d.querySelectorAll`[href*=":`].join`
`)
f=
async _=>((d=document.body).innerHTML=await(await fetch`//corsproxy.io/?https://stroustrup.com/C++.html`).text(),[...d.querySelectorAll`[href*=":`].join`
`)
f().then(s => document.write(`<pre>${s}</pre>`))async _ => ( // asynchronous function
(d=document.body) // alias the <body> to d
.innerHTML = // put into its html:
await (await fetch`...`).text(), // fetch the document
[...d.querySelectorAll`[href*=":`] // get all tags with href containing a ":"
.join`\n` // join by newlines (<a> stringified is its href)
)
JavaScript (ES6), (削除) 236 ... 134 (削除ここまで) 130 bytes
This parses HTML using the DOMParser#parseFromString method. Ditto for the CORS stuff.
async _=>[...new DOMParser().parseFromString(await(await fetch`C++.html`).text(),"text/html").querySelectorAll`[href*=":`].join`
`
f=
async _=>[...new DOMParser().parseFromString(await(await fetch`//corsproxy.io/?https://stroustrup.com/C++.html`).text(),"text/html").querySelectorAll`[href*=":`].join`
`
f().then(s => document.write(`<pre>${s}</pre>`))async _ => // asynchronous function
[... // cast to an array:
new DOMParser().parseFromString( // parse HTML from
await (await fetch`...`).text(), // fetch the document
"text/html"
).querySelectorAll`[href*=":` // get all tags with href containing a ":"
].join`\n` // join by newlines (<a> stringified is its href)
Saved 7 bytes on each version thanks to a cool trick pointed out by @tsh
Saved 39 bytes by running the program from the site's root, as pointed out by @Shaggy.
-
\$\begingroup\$ Is it correct? It returns (for me) many more urls than 91. \$\endgroup\$pajonk– pajonk2023年04月27日 19:51:56 +00:00Commented Apr 27, 2023 at 19:51
-
\$\begingroup\$ @pajonk Fixed and saved a bunch of bytes :) \$\endgroup\$noodle person– noodle person2023年04月28日 00:31:39 +00:00Commented Apr 28, 2023 at 0:31
-
\$\begingroup\$ Maybe
.map(a=>a.href)can be.join`\n`? \$\endgroup\$tsh– tsh2023年04月28日 02:16:31 +00:00Commented Apr 28, 2023 at 2:16 -
\$\begingroup\$
.joinwill automatically toString each item, which will yield their URLs. \$\endgroup\$tsh– tsh2023年04月28日 08:36:47 +00:00Commented Apr 28, 2023 at 8:36 -
\$\begingroup\$ @tsh Huh, I didn’t know that
<a>.toStringyields its href. Thanks for the tip. \$\endgroup\$noodle person– noodle person2023年04月28日 11:31:47 +00:00Commented Apr 28, 2023 at 11:31
Wolfram Language (Mathematica), 88 bytes
Import[s="https://www.stroustrup.com/";s<>"C++.html","Hyperlinks"]~Select~StringFreeQ@s&
Ruby 3 + nokogiri, 152 bytes
require'open-uri'
require'nokogiri'
p Nokogiri::HTML.parse(URI.open("https://www.stroustrup.com/C++.html").read).css("a[href^=http]").map{_1.attr"href"}
Outputs an array of strings of URLs. Doesn't assume anything about the structure of <a>s that might be deviously crafted to fudge regular expression approaches. We cannot use Nokogiri::XML because it doesn't correctly parse HTML URL query parameters.
Ruby 3, 113 bytes
require'open-uri'
URI.open("https://www.stroustrup.com/C++.html").read.scan(/<a[^>]+href="(http.+?)"/).map{p *_1}
Outputs a string on each line. Uses a regular expression approach which might be fooled in some cases (e.g. <a style=">" ...), although it produces the same sequene of URLs.
JavaScript, (削除) 79 (削除ここまで) 78 bytes
Must be run from the root folder of the site (consensus), returns a Promise containing an array of URLs (consensus).
async _=>(await(await fetch`C++.html`).text()).match(/(?<=href=").+:.+(?=")/g)
Here's a snippet that uses a proxy to allow it to bypass the site's CORS policy:
f=
async _=>(await(await fetch`//corsproxy.io/?https://stroustrup.com/C++.html`).text()).match(/(?<=href=").+:.+(?=")/g)
f().then(a=>console.log(a.join`\n`))-
\$\begingroup\$ Note that this uses lookbehind in the regex which is only supported in V8. \$\endgroup\$noodle person– noodle person2023年04月28日 19:22:48 +00:00Commented Apr 28, 2023 at 19:22
-
1\$\begingroup\$ @Jacob No it's not. See caniuse.com/js-regexp-lookbehind \$\endgroup\$Neil– Neil2023年04月29日 15:06:08 +00:00Commented Apr 29, 2023 at 15:06
-
\$\begingroup\$ @Neil Huh, I could have sworn I saw somewhere that it wasn't supported. Thanks for letting me know \$\endgroup\$noodle person– noodle person2023年04月29日 16:35:47 +00:00Commented Apr 29, 2023 at 16:35
Nim -d:ssl, 106 bytes
Dirty solution which might break on a different webpage.
import httpclient,re
echo newHttpClient().getContent"http://stroustrup.com/C++.html".findAll re"htt[^""]*"
Nim -d:ssl + Nimquery, 201 bytes
Should work on any possible webpage.
import htmlparser,httpclient,nimquery,re,xmltree
for e in newHttpClient().getContent"http://stroustrup.com/C++.html".parseHtml.querySelectorAll"a[href^='http://'],a[href^='https://']":echo e.attr"href"
Scala + jsoup, 220 bytes
Golfed version(220 bytes)
object A{def main(args:Array[String])=org.jsoup.Jsoup.parse(scala.io.Source.fromURL("https://www.stroustrup.com/C++.html").mkString).select("a[href]").eachAttr("abs:href").toArray.toList.map(_.toString).foreach(println)}
Ungolfed version
import java.net.URL
import scala.io.Source
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.select.Elements
object UrlExtractor {
def downloadHtml(url: String): String = {
Source.fromURL(url).mkString
}
def extractUrls(html: String): List[String] = {
val doc: Document = Jsoup.parse(html)
val elements: Elements = doc.select("a[href]")
elements.eachAttr("abs:href").toArray.toList.map(_.toString)
}
def main(args: Array[String]): Unit = {
// println("This is in UrlExtrator object.")
val url = "https://www.stroustrup.com/C++.html"
val html = downloadHtml(url)
// println(html)
val urls = extractUrls(html)
println("List of URLs:")
urls.foreach(println)
}
}
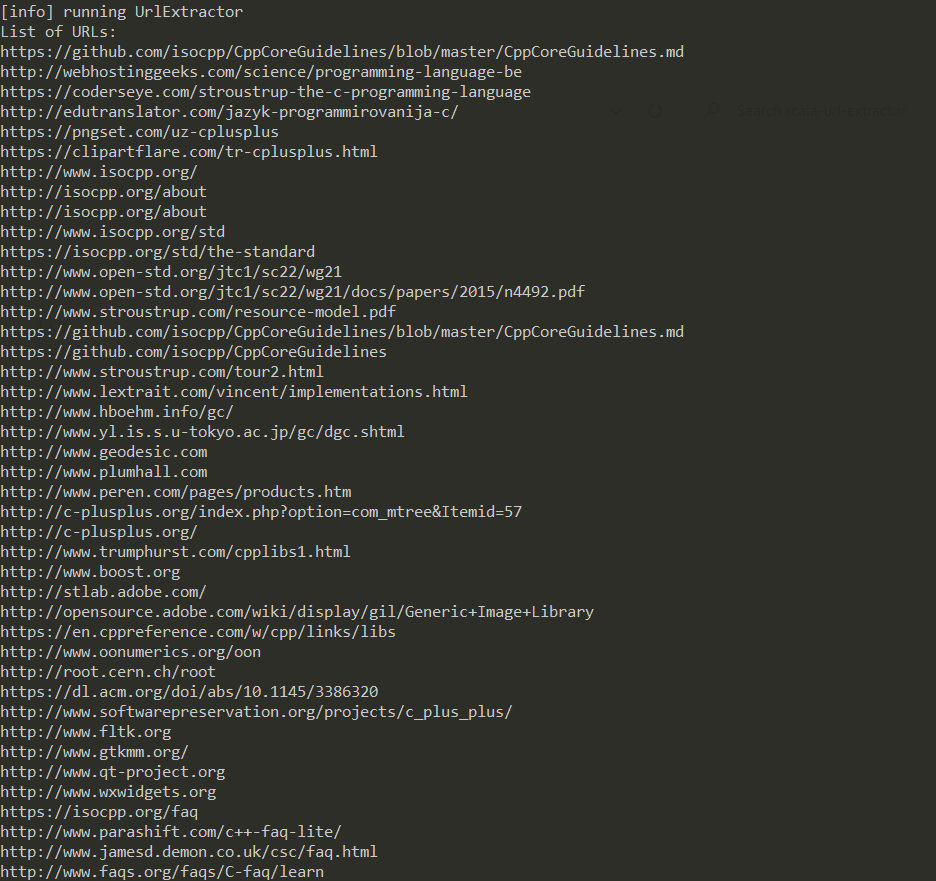{kind=link}
Bash + Retina, 40 bytes
curl -L stroustrup.com/C++.html|retina p
File p:
s`a.
S`href="
G`tp
".*
The tricky things are
aandhrefseperated by a newline- two links on the same line
R, 122 bytes
u = unlist(strsplit(readLines('http://www.stroustrup.com/C++.html'),'href="'))
regmatches(u,regexpr('(https?://[^"]+)',u))
Output looks like this:
[1] "https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md"
[2] "http://webhostinggeeks.com/science/programming-language-be"
[3] "https://coderseye.com/stroustrup-the-c-programming-language"
[4] "http://edutranslator.com/jazyk-programmirovanija-c/"
[5] "https://pngset.com/uz-cplusplus"
[6] "https://clipartflare.com/tr-cplusplus.html"
[7] "http://www.isocpp.org/"
[8] "http://isocpp.org/about"
[9] "http://isocpp.org/about"
[10] "http://www.isocpp.org/std"
[11] "https://isocpp.org/std/the-standard"
[12] "http://www.open-std.org/jtc1/sc22/wg21"
[13] "http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2015/n4492.pdf"
[14] "http://www.stroustrup.com/resource-model.pdf"
[15] "https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md"
[16] "https://github.com/isocpp/CppCoreGuidelines"
[17] "http://www.stroustrup.com/tour2.html"
[18] "http://www.lextrait.com/vincent/implementations.html"
[19] "http://www.hboehm.info/gc/"
[20] "http://www.yl.is.s.u-tokyo.ac.jp/gc/dgc.shtml"
[21] "http://www.geodesic.com"
[22] "http://www.plumhall.com"
[23] "http://www.peren.com/pages/products.htm"
[24] "http://c-plusplus.org/index.php?option=com_mtree&Itemid=57"
[25] "http://c-plusplus.org/"
[26] "http://www.trumphurst.com/cpplibs1.html"
[27] "http://www.boost.org"
[28] "http://stlab.adobe.com/"
[29] "http://opensource.adobe.com/wiki/display/gil/Generic+Image+Library"
[30] "https://en.cppreference.com/w/cpp/links/libs"
[31] "http://www.oonumerics.org/oon"
[32] "http://root.cern.ch/root"
[33] "https://dl.acm.org/doi/abs/10.1145/3386320"
[34] "http://www.softwarepreservation.org/projects/c_plus_plus/"
[35] "http://www.fltk.org"
[36] "http://www.gtkmm.org/"
[37] "http://www.qt-project.org"
[38] "http://www.wxwidgets.org"
[39] "https://isocpp.org/faq"
[40] "http://www.parashift.com/c++-faq-lite/"
[41] "http://www.jamesd.demon.co.uk/csc/faq.html"
[42] "http://www.faqs.org/faqs/C-faq/learn"
[43] "http://www.stroustrup.com/Tour.html"
[44] "http://www-h.eng.cam.ac.uk/help/tpl/languages/C++.html"
[45] "http://www.accu.org"
[46] "https://www.accu.org/"
[47] "http://en.wikibooks.org/wiki/More_C%2B%2B_Idioms"
[48] "http://www.gotw.ca/"
[49] "http://curbralan.com/"
[50] "http://www.artima.com/cppsource"
[51] "https://www.youtube.com/watch?v=8aIqIBmNJyM"
[52] "https://www.youtube.com/watch?v=SwJUPeWKRHo"
[53] "https://www.youtube.com/watch?v=ERzENfQ51Ck&t=6s"
[54] "https://www.youtube.com/watch?v=ooehrkYkGdA&fbclid=IwAR3_3bgYVF_d6j6KjHBO4nmpCu-7oDk8YbSC8aYrJdlGvAvo_Al2fYY_9W4"
[55] "https://www.youtube.com/watch?v=PU-2ntDuF10&fbclid=IwAR15f5SRmmyryda7IvsgIBzDLCVXcMRz6_JRTbc766X1NQccGRe_28qmy4g"
[56] "https://www.youtube.com/watch?v=43msMqV5CVA"
[57] "https://channel9.msdn.com/Shows/C9-GoingNative/Bjarne-Stroustrup-Interview-at-CppCon-2018?fbclid=IwAR19rNUcCco2pnhCTn4AHqTbONmfQv4DKoVAV1keYPdV9VvKgzRxTIVpZMM"
[58] "https://channel9.msdn.com/Shows/C9-GoingNative/Bjarne-Stroustrup-Interview-at-CppCon-2018?term=cppcon&lang-en=true"
[59] "https://www.youtube.com/watch?v=DvUL0Y2bpyc&t=129s"
[60] "https://www.youtube.com/watch?v=e_g65LUXpBI"
[61] "http://daxue.qq.com/content/content/id/2937"
[62] "http://bss.sch.bme.hu/video/bjarne-stroustrup-type-and-resource-safe-c"
[63] "https://www.youtube.com/watch?v=aPvbxuOBQ70"
[64] "https://www.youtube.com/watch?v=ZO0PXYMVGSU"
[65] "http://www.computerhistory.org/collections/oralhistories/video/30/"
[66] "https://www.youtube.com/watch?v=xcpSLRpOMJM"
[67] "https://channel9.msdn.com/Shows/C9-GoingNative/Going-Native-42-Bjarne-Stroustrup-interview-at-cppcon"
[68] "https://channel9.msdn.com/Events/CPP/CppCon-2015/Writing-Good-C-14"
[69] "https://channel9.msdn.com/Events/CPP/CppCon-2015"
[70] "https://channel9.msdn.com/events/CPP/C-PP-Con-2014/013-Make-Simple-Tasks-Simple"
[71] "http://channel9.msdn.com/Events/CPP/C-PP-Con-2014"
[72] "https://www.youtube.com/watch?v=jDqQudbtuqo&feature=youtu.be"
[73] "http://channel9.msdn.com/Events/Lang-NEXT/Lang-NEXT-2014/Keynote"
[74] "http://channel9.msdn.com/Events/GoingNative/2013/Opening-Keynote-Bjarne-Stroustrup"
[75] "http://vimeo.com/35326736"
[76] "http://channel9.msdn.com/Events/GoingNative/GoingNative-2012/Keynote-Bjarne-Stroustrup-Cpp11-Style"
[77] "http://techchannel.att.com/"
[78] "http://techchannel.att.com/play-video.cfm/2011/3/7/Tech-Icons-Bjarne-Stroustrup"
[79] "http://techchannel.att.com/index.cfm?SearchTag=Tech%20Icons"
[80] "http://cdsweb.cern.ch/record/1204845?ln=en"
[81] "http://portal.acm.org/toc.cfm?id=1238844"
[82] "http://csclub.uwaterloo.ca/media/C++0x%20-%20An%20Overview.html"
[83] "http://video.google.com/videoplay?docid=-3478907067117491758"
[84] "http://video.google.com/videoplay?docid=5262479012306588324"
[85] "http://technetcast.ddj.com/tnc_catalog.html?item_id=94"
[86] "http://www.youtube.com/user/A9Videos/videos?flow=grid&view=1"
[87] "https://www.youtube.com/watch?v=69edOm889V4"
[88] "https://www.bell-labs.com/usr/dmr/www/"
[89] "http://www.computerhistory.org"
[90] "http://www.softwarepreservation.org/projects/c_plus_plus/"
[91] "https://github.com/isocpp/CppCoreGuidelines/blob/master/CppCoreGuidelines.md"
f="http, which could produce false positives? \$\endgroup\$