This is my first challenge on ppcg!
Input
A string consisting of two different ascii characters. For example
ABAABBAAAAAABBAAABAABBAABA
Challenge
The task is to decode this string following these rules:
- Skip the first two characters
- Split the rest of the string into groups of 8 characters
- In each group, replace each character with
0if that character is the same as the first character of the original string, and with1otherwise - Now each group represents a byte. Convert each group to character from byte char code
- Concatenate all characters
Example
Let's decode the above string.
AB AABBAAAA AABBAAAB AABBAABA
^^ ^ ^ ^
| | | |
| \---------|---------/
| |
Skip Convert to binary
Notice that A is the first character in the original string and B is the second. Therefore, replace each A with 0 and each B with 1. Now we obtain:
00110000 00110001 00110010
which is [0x30, 0x31, 0x32] in binary. These values represent characters ["0", "1", "2"] respectively, so the final output should be 012.
Scoring
This is, of course, code-golf, which means make your code as short as possible. Score is measured in bytes.
Constraints and IO format
Standard rules apply. Here are some additional rules:
- You can assume valid input
- Input string consists of exactly two different characters
- The first two characters are different
- The minimal length of the input string is 2 characters
- The length will always give 2 modulo 8
- You can assume the string will always consist only of printable ASCII characters
- Both in the input and in the decoded string
- Leading and trailing whitespace are allowed in the output (everything that matches
/\s*/)
-
6\$\begingroup\$ Gotta say man, for a first challenge, this is one of the better formatted challenges I've ever seen. As an fyi, the community sandbox is a great place for feedback before posting so you don't get randomly rep bombed for a rule you didn't know. \$\endgroup\$Magic Octopus Urn– Magic Octopus Urn2018年04月23日 00:16:39 +00:00Commented Apr 23, 2018 at 0:16
-
\$\begingroup\$ @MagicOctopusUrn. Thank you! Didn't know about sandbox, I'll post there next time :) \$\endgroup\$user80067– user800672018年04月23日 00:18:03 +00:00Commented Apr 23, 2018 at 0:18
-
2\$\begingroup\$ I mostly use it so people can call me out on duplicate questions, very simple to follow rules, rather hard to know about dupes without memorizing meta :). I'd also recommend checking out the chatrooms, we have chats for almost every language you could hope to learn and questions are encouraged. \$\endgroup\$Magic Octopus Urn– Magic Octopus Urn2018年04月23日 00:18:28 +00:00Commented Apr 23, 2018 at 0:18
-
1\$\begingroup\$ Great first challenge! Some more test cases would be neat. \$\endgroup\$lynn– lynn2018年04月23日 16:33:29 +00:00Commented Apr 23, 2018 at 16:33
-
\$\begingroup\$ Really nice first challenge. Had fun playing with this one. \$\endgroup\$ElPedro– ElPedro2018年04月23日 19:18:23 +00:00Commented Apr 23, 2018 at 19:18
44 Answers 44
brainfuck, (削除) 76 71 (削除ここまで) 65 bytes
-6 bytes thanks to Nitrodon!
,>>,,[>>++++++++[-[->+<]<<<<[->+>-<<]>>[[-]>>+<<]>[->++<],>>]<.<]
Feels weird beating Python...
-
1\$\begingroup\$ Not if the 8 keywords in BF were as long as their Python counterpart. \$\endgroup\$user202729– user2027292018年04月23日 04:47:54 +00:00Commented Apr 23, 2018 at 4:47
-
\$\begingroup\$ It helps that BF automatically converts the unicode. \$\endgroup\$LastStar007– LastStar0072018年04月23日 09:49:37 +00:00Commented Apr 23, 2018 at 9:49
-
Stax, (削除) 15 (削除ここまで) 11 bytes
ó║\U⌂1⁄2íèäöñ
Run and debug it at staxlang.xyz!
(削除) Quick 'n' dirty approach. Working on improving it. (削除ここまで) Improved it!
Unpacked (13 bytes) and explanation
2:/8/{{[Im:bm
2:/ Split at index 2. Push head, then tail.
8/ Split into length-8 segments.
{ m Map block over each segment:
{ m Map block over each character:
[ Copy first two elements (below) in-place.
I Index of character in first two characters.
:b Convert from binary.
Implicit print as string.
-
\$\begingroup\$ Ahhhh... I knew this would beat us. \$\endgroup\$Magic Octopus Urn– Magic Octopus Urn2018年04月23日 00:29:34 +00:00Commented Apr 23, 2018 at 0:29
05AB1E, 10 bytes
¦¦Sk8ôJCçJ
-3 thanks to emigna.
Ù # Unique letters, in order they appear.
v # For each...
yN: # Push letter and index, replace in input.
} # End loop.
¦¦ # Remove first x2.
8ô # Split into eighths.
C # Convert to integer.
ç # Convert to char.
J # Join together entire result.
-
1\$\begingroup\$ You can use
01‡instead of the loop. EDIT: or even better:¦¦Sk8ôJCçJ\$\endgroup\$Emigna– Emigna2018年04月23日 06:33:43 +00:00Commented Apr 23, 2018 at 6:33 -
\$\begingroup\$ Ahhhh... I knew this would beat us. \$\endgroup\$Khuldraeseth na'Barya– Khuldraeseth na'Barya2019年07月29日 15:50:04 +00:00Commented Jul 29, 2019 at 15:50
JavaScript (Node.js), 67 bytes
s=>s.replace(/./g,x=(c,i)=>(x=x*2|c==s[1],Buffer(i<3|i&7^1?0:[x])))
How?
We use two different syntaxes of the Buffer constructor:
Buffer([n])generates a buffer containing the sole byte n and is coerced to the corresponding ASCII character. Only the 8 least significant bits of n are considered.Buffer(n)generates a buffer of n bytes. Therefore,Buffer(0)generates an empty buffer, which is coerced to an empty string.
Note: They both are deprecated in recent Node versions. Buffer.from([n]) and Buffer.alloc(n) should be used instead.
Commented
s => // given the input string s
s.replace(/./g, x = // initialize x to a non-numeric value (will be coerced to 0)
(c, i) => ( // for each character c at position i in s:
x = x * 2 | // shift x to the left
c == s[1], // and append the new bit, based on the comparison of c with s[1]
Buffer( // invoke the constructor of Buffer (see above):
i < 3 | // if i is less than 3
i & 7 ^ 1 ? // or i is not congruent to 1 modulo 8:
0 // replace c with an empty string
: // else:
[x] // replace c with the ASCII char. whose code is the LSB of x
) // end of Buffer constructor
)) // end of replace(); return the new string
bash, (削除) 59 (削除ここまで) (削除) 58 (削除ここまで) 52 bytes
tr -t "1ドル" 01 <<<1ドル|cut -c3-|fold -8|sed 'i2i
aP'|dc
Thanks to Cows quack for saving 6 bytes.
This challenge works remarkably well with a series of coreutils (and dc to do the conversion and output at the end). First, we use
tr -t "1ドル" 01 <<<1ドル
to transliterate the two characters in the input to zeroes and ones. The -t flag truncates the first argument to the length of the second, so this reduces to transliterating the first two characters in the input to 0 and 1, which is what we want. Then,
cut -c3-
removes the first two characters, and
fold -8
outputs 8 of the characters per line. Finally, the sed command turns each line into a dc snippet that reads the number as binary and outputs that byte.
-
\$\begingroup\$ Always nice to see a bash answer :) You can use sed to simplify the dc calculations by converting each line to dc code that prints each character out and then eval'ing it in dc tio.run/##S0oszvj/… (and the space after
cut -ccan be removed) \$\endgroup\$user41805– user418052018年04月23日 12:49:13 +00:00Commented Apr 23, 2018 at 12:49
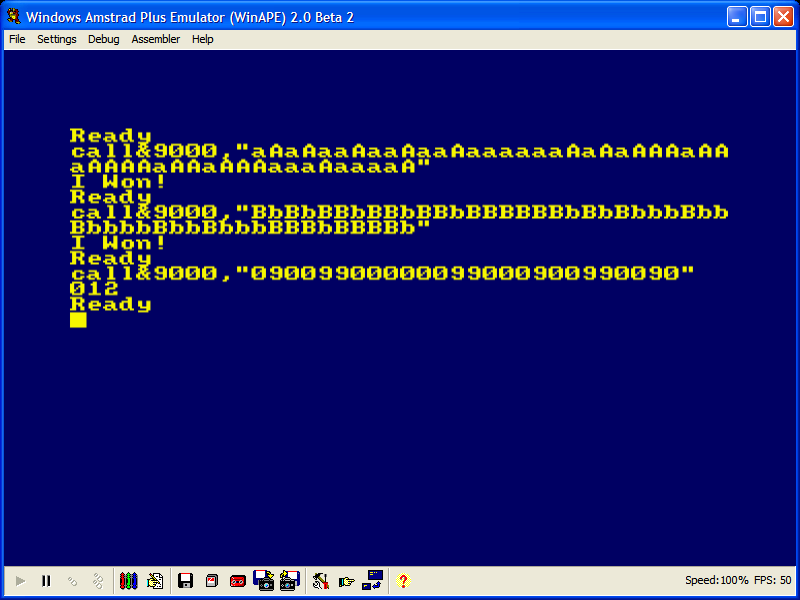
Z80 machine code on an Amstrad CPC, (削除) 32 31 (削除ここまで) 30 bytes
000001 0000 (9000) ORG &9000
000002 9000 EB EX DE, HL
000003 9001 46 LD B, (HL)
000004 9002 23 INC HL
000005 9003 5E LD E, (HL)
000006 9004 23 INC HL
000007 9005 56 LD D, (HL)
000009 9006 1A LD A, (DE)
000010 9007 05 DEC B
000011 9008 13 INC DE
000012 9009 4F LD C, A
000014 900A Light
000015 900A 26 01 LD H, &01
000016 900C Last
000017 900C 13 INC DE
000018 900D 05 DEC B
000019 900E C8 RET Z
000021 900F Loop
000022 900F 1A LD A, (DE)
000023 9010 B9 CP C
000024 9011 28 01 JR Z, Lable
000025 9013 37 SCF
000026 9014 Lable
000027 9014 ED 6A ADC HL, HL
000028 9016 30 F4 JR NC, Last
000029 9018 7D LD A, L
000030 9019 CD 5A BB CALL &BB5A
000032 901C 18 EC JR Light
The code takes the instruction replace each character with 0 if that character is the same as the first character of the original string, and with 1 otherwise literally and doesn't ever bother to check that a character matches the second character in the input string. It just checks for same-as-first-character and different-from-first-character.
I ran out of registers (the Z80 only has 7 easily usable 8-bit registers, the rest need longer instructions) so I put &01 in H, along with using L to build up the ASCII character (I just realised it's unnecessary to initialise L, saving one byte). When H overflows into the Carry flag, the character in L is ready to be output. Luckily, there is a 16-bit ADC (Add with Carry) that does the job of a left-shift instruction.
(DE) can only be read into A although (HL) can be read into any 8-bit register, so it was a compromise which one to use. I couldn't compare (DE) with C directly, so I had to load one into A first. The labels are just random words that start with L (a requirement of the assembler).
Athe Accumulator - the only register that can do comparisonsBthe counter register(削除) for the instruction. By rearranging the code, I was able to do the job ofDJNZ: Decrement (B) and Jump if Non Zero (削除ここまで)DJNZwith one fewer byteCthe first character in the input stringD,EasDEthe address of the current input characterHthe carry trigger (every 8th loop)Lthe output character being built up
{kind=link}
J, (削除) 17 (削除ここまで) 13 Bytes
u:_8#.2円}.1{=
-4 thanks to FrownyFrog
Old version:
u:_8#.2円&({.i.}.)
Explanation:
u:_8#.2円}.1{=
= | Self classify, for each unique element x of y, compute x = y, element-wise
1{ | Second row
2}. | Drop 2
_8#.\ | Convert non-intersecting subarrays of length 8 from binary
u: | Convert to characters
Examples:
= 'ABAABBAAAAAABBAAABAABBAABA'
1 0 1 1 0 0 1 1 1 1 1 1 0 0 1 1 1 0 1 1 0 0 1 1 0 1
0 1 0 0 1 1 0 0 0 0 0 0 1 1 0 0 0 1 0 0 1 1 0 0 1 0
2}.1{= 'ABAABBAAAAAABBAAABAABBAABA'
0 0 1 1 0 0 0 0 0 0 1 1 0 0 0 1 0 0 1 1 0 0 1 0
_8#.2円}.1{= 'ABAABBAAAAAABBAAABAABBAABA'
48 49 50
u:_8#.2円}.1{= 'ABAABBAAAAAABBAAABAABBAABA'
012
-
1\$\begingroup\$
2}.1{=to save 4 bytes. \$\endgroup\$FrownyFrog– FrownyFrog2018年04月22日 23:45:52 +00:00Commented Apr 22, 2018 at 23:45 -
\$\begingroup\$ Oh my, tied... I can't find another byte. \$\endgroup\$Magic Octopus Urn– Magic Octopus Urn2018年04月23日 00:13:55 +00:00Commented Apr 23, 2018 at 0:13
-
1\$\begingroup\$ @MagicOctopusUrn it's actually a snippet, it should have a
[:at the start :) \$\endgroup\$FrownyFrog– FrownyFrog2018年04月23日 02:48:46 +00:00Commented Apr 23, 2018 at 2:48
Python 2, 77 bytes
lambda s:[chr(int(`map(s.find,s)`[i:i+24:3],2))for i in range(7,3*len(s),24)]
R, 71 bytes
function(s)intToUtf8(2^(7:0)%*%matrix((y=utf8ToInt(s))[-1:-2]==y[2],8))
Surprisingly golfy!
First, converts the string to ascii code-points with utf8ToInt, saving it as y. Removing the first two characters with negative indexing is shorter than using tail.
The array y[-1:-2]==y[2] is equivalent to the bits when %*% (matrix multiplication) is applied, but first we reshape that array into a matrix with nrow=8, converting from a linear array to byte groupings. Fortuitously, we can then convert to the ascii code points using matrix multiplication with the appropriate powers of 2, 2^(7:0), and then we convert the code points back to a string with intToUtf8.
Python 3, 77 bytes
a,b,*r=input();x=i=0
for c in r:i*=2;i|=a!=c;x+=1;x%8or print(end=chr(i&255))
PHP, (削除) 73 (削除ここまで) 71 bytes
while($s=substr($argn,-6+$i+=8,8))echo~chr(bindec(strtr($s,$argn,10)));
Run as pipe with -nR or try it online.
golfings:
- start index at
-6and pre-increment by8 - exploit that
strtrignores excessive chars in the longer parameter (nosubstrneeded) - translating to
10and then inverting needs no quotes -> -1 byte - invert character instead of ascii code -->
~serves as word boundary -> -1 byte.
-
3\$\begingroup\$ At least you should match brainfuck:
for(;$s=substr($argn,2+8*$i++,8);)echo~chr(bindec(strtr($s,$argn,10)));\$\endgroup\$Christoph– Christoph2018年04月23日 11:00:34 +00:00Commented Apr 23, 2018 at 11:00 -
2\$\begingroup\$ @Christoph I like how Brainfuck is suddenly a standard for reasonable answer length. \$\endgroup\$Etheryte– Etheryte2018年04月23日 13:18:41 +00:00Commented Apr 23, 2018 at 13:18
Pyth, (削除) 20 (削除ここまで) 9 bytes
CittxLQQ2
Saved 11 bytes thanks to FryAmTheEggman.
Explanation
CittxLQQ2
xLQQ Find the index of each character in the string.
tt Exclude the first 2.
i 2 Convert from binary.
C Get the characters.
-
\$\begingroup\$ @FryAmTheEggman Thanks. Evidently I've still got a lot to learn about Pyth. \$\endgroup\$user48543– user485432018年04月23日 15:52:21 +00:00Commented Apr 23, 2018 at 15:52
-
\$\begingroup\$ Haha, so do I! It's a very intricate golfing language. I hope you continue golfing in it :) \$\endgroup\$FryAmTheEggman– FryAmTheEggman2018年04月23日 16:08:25 +00:00Commented Apr 23, 2018 at 16:08
Ruby, (削除) 82 (削除ここまで) 79 bytes
->s{s[2..-1].tr(s[0,2],'01').chars.each_slice(8).map{|s|s.join.to_i(2).chr}*''}
-
1\$\begingroup\$ Welcome to PPCG! I didn't see that there was already an answer in Ruby before i posted mine, but some typical golfing tricks apply to your approach too - e.g., the last
.joincan be replaced by*'', ands[0..1]bys[0,2]. \$\endgroup\$Kirill L.– Kirill L.2018年04月23日 09:26:35 +00:00Commented Apr 23, 2018 at 9:26
Japt, 11 bytes
¤£bXÃò8 ®Íd
Explanation
¤ :Slice from the 3rd character
£ Ã :Map over each X
bX : Get the first 0-based index of X in the input
ò8 :Split to an array of strings of length 8
® :Map
Í : Convert from base-2 string to base-10 integer
d : Get the character at that codepoint
-
\$\begingroup\$ Very clever use of the
s2shortcut, nice. \$\endgroup\$Etheryte– Etheryte2018年04月23日 12:35:16 +00:00Commented Apr 23, 2018 at 12:35
PHP + GNU Multiple Precision, (削除) 63 (削除ここまで) 61
<?=gmp_export(gmp_init(substr(strtr($argn,$argn,"01"),2),2));
sadly the GMP extention is not default activated (but shipped).
Run like this:
echo "ABABABAAAAABABAAAAAABAABBAABAAAABBABAAABBB" | php -F a.php
-
\$\begingroup\$
<?=saves 2 bytes and possibly the day. ;-) \$\endgroup\$Titus– Titus2018年04月23日 12:46:04 +00:00Commented Apr 23, 2018 at 12:46 -
\$\begingroup\$ @Titus yeah but sadly it doesn't work with
-R(I tried). \$\endgroup\$Christoph– Christoph2018年04月23日 13:22:49 +00:00Commented Apr 23, 2018 at 13:22 -
1\$\begingroup\$ try
-Finstead \$\endgroup\$Titus– Titus2018年04月23日 13:27:13 +00:00Commented Apr 23, 2018 at 13:27
Java 8, (削除) 143 (削除ここまで) (削除) 142 (削除ここまで) 141 bytes
s->{char i=47;for(;++i<50;)s=s.replace(s.charAt(i%2),i);for(i=2;i<s.length();)System.out.print((char)Long.parseLong(s.substring(i,i+=8),2));}
-1 byte thanks to @OlivierGrégoire.
Explanation:
s->{ // Method with String parameter and no return-type
char i=47; // Index character, starting at 47
for(;++i<50;) // Loop 2 times
s.replace(s.charAt(i%2),i) // Replace first characters to 0, second characters to 1
for(i=2;i<s.length();) // Loop `i` from 2 upwards over the String-length
System.out.print( // Print:
(char) // As character:
Long.parseLong( // Convert Binary-String to number
s.substring(i,i+=8) // The substring in range [i,i+8),
,2));}
-
\$\begingroup\$ 142 bytes \$\endgroup\$Olivier Grégoire– Olivier Grégoire2018年04月25日 16:23:51 +00:00Commented Apr 25, 2018 at 16:23
Python 3, (削除) 99 (削除ここまで) 86 bytes
lambda s:[chr(int(str(list(map(s.find,s[i:i+8])))[1::3],2))for i in range(2,len(s),8)]
Thanks to ASCII-only for basically the whole thing really
-
\$\begingroup\$ Nice, but it fails here. \$\endgroup\$user80067– user800672018年04月23日 00:16:29 +00:00Commented Apr 23, 2018 at 0:16
-
\$\begingroup\$ 86, port of python 2 method. returns as list though but at least it works \$\endgroup\$ASCII-only– ASCII-only2018年04月23日 00:34:55 +00:00Commented Apr 23, 2018 at 0:34
APL+WIN, 30 bytes
Index origin 0. Prompts for input of string
⎕av[2⊥ ̈(+0円=8|⍳⍴b)⊂b←2↓s≠↑s←⎕]
Explanation:
s≠↑s←⎕ prompts for string and creates binary vector not equal to first character
b←2↓s drops first two elements of binary
(+0円=8|⍳⍴b)⊂ splits binary into groups of 8
2⊥ ̈ converts each group to decimal
⎕av[...] displays decoded characters
-
\$\begingroup\$ I assume Quad-AV is in-line with ASCII for APL+WIN? \$\endgroup\$Adalynn– Adalynn2018年04月24日 22:23:28 +00:00Commented Apr 24, 2018 at 22:23
-
\$\begingroup\$ @Zacharý Yes for the first 128 characters. The special APL characters replace some of the characters in the extended ASCII character set. \$\endgroup\$Graham– Graham2018年04月25日 10:39:22 +00:00Commented Apr 25, 2018 at 10:39
Red, 110 bytes
func[s][t: 0 i: 128 foreach c next next s[if c = s/2[t: t + i]i: i / 2 if i = 0[prin to-char t t: 0 i: 128]]]
Explanation:
A simple straightforward solution, no builtins.
f: func [s] [ ; s is the argument (string)
t: 0 ; total - initially 0
i: 128 ; powers of 2, initially 0
b: s/2 ; b is the second charachter
foreach c next next s [ ; for each char in the input string after the 2nd one
if c = b [t: t + i] ; if it's equal to b than add the power of 2 to t
i: i / 2 ; previous power of 2
if i = 0 [ ; if it's 0
prin to-char t ; convert t to character and print it
t: 0 ; set t to 0
i: 128 ; i to 128
]
]
]
Google Sheets, 123 bytes
=ArrayFormula(Join("",IfError(Char(Bin2Dec(Substitute(Substitute(Mid(A1,3+8*(Row(A:A)-1),8),Left(A1),0),Mid(A1,2,1),1))),""
Input is in cell A1. Google will automatically add ))) to the end of the formula.
Explanation:
Mid(A1,3+8*(Row(A:A)-1),8)grabs chunks of characters 8 at a time, starting with the third.Substitute(Mid(~),Left(A1),0)replaces each instance of the first character with 0.Substitute(Substitute(~),Mid(A1,2,1),1)replaces the second character with 1.Char(Bin2Dec(Substitute(~)))converts the chunk to decimal and then to ASCII.IfError(Char(~,""))corrects all the errors that result from the fact thatRow(A:A)returns far more values than we soBin2Decgives us a lot of zero values andCharerrors out on zero.ArrayFormula(Join("",IfError(~)))joins together all theCharresults andArrayFormulais what makes theRow(A:A)return an array of values instead of just the first value.
Haskell, 75 bytes
f[_,_]=""
f(z:o:s)=toEnum(sum[2^b|(b,c)<-zip[7,6..0]s,c==o]):f(z:o:drop 8s)
Ruby, (削除) 61 (削除ここまで) 42 bytes
-19 bytes thanks to benj2240
->s{[s[2..-1].tr(s[0,2],"01")].pack("B*")}
-
\$\begingroup\$
packis an inspired choice, but right now you're sort of going the long way around. It can do even more of the work for you. \$\endgroup\$benj2240– benj22402018年04月23日 19:13:28 +00:00Commented Apr 23, 2018 at 19:13 -
1\$\begingroup\$ Yep, that was a total mind-block from my side... \$\endgroup\$Kirill L.– Kirill L.2018年04月23日 20:53:38 +00:00Commented Apr 23, 2018 at 20:53
-
\$\begingroup\$ Very cool. Not played with REXX for a long time. \$\endgroup\$ElPedro– ElPedro2018年04月25日 19:25:16 +00:00Commented Apr 25, 2018 at 19:25
Python 2, 88 bytes
i=input()
f=''.join('10'[x==i[0]]for x in i[2:])
while f:print chr(int(f[:8],2));f=f[8:]
Not the shortest - just an alternative way.
Following version prints the output on one line for 98 bytes although the rules state that trailing whitespace is allowed.:
i=input();f=''.join('10'[x==i[0]]for x in i[2:]);o=""
while f:o+=chr(int(f[:8],2));f=f[8:]
print o
-
\$\begingroup\$ Final output should be on one line, not three. \$\endgroup\$idrougge– idrougge2018年04月25日 13:54:12 +00:00Commented Apr 25, 2018 at 13:54
-
\$\begingroup\$ From OP: "Leading and trailing whitespace are allowed in the output (everything that matches /\s*/)". Newline matches
/\s*/. \$\endgroup\$ElPedro– ElPedro2018年04月25日 14:24:20 +00:00Commented Apr 25, 2018 at 14:24 -
1\$\begingroup\$ Sorry, I'm not well-enough versed in regex notation. :/ \$\endgroup\$idrougge– idrougge2018年04月25日 14:36:57 +00:00Commented Apr 25, 2018 at 14:36
-
\$\begingroup\$ Neither am I but i Googled it just to be sure ;-) \$\endgroup\$ElPedro– ElPedro2018年04月25日 14:49:52 +00:00Commented Apr 25, 2018 at 14:49
C# (Visual C# Compiler), 158 bytes
using System.Linq;a=>new string(a.Skip(2).Where((c,i)=>(i-2)%8==0).Select((c,i)=>(char)a.Skip(8*i+2).Take(8).Select((d,j)=>d!=a[0]?1<<7-j:0).Sum()).ToArray())
Scala, 95 bytes
s.substring(2).replace(s(0),'0').replace(s(1),'1').grouped(8).map(Integer.parseInt(_,2).toChar)
Haskell, (削除) 124 (削除ここまで) (削除) 105 (削除ここまで) 93 bytes
f(x:_:y)=fromEnum.(/=x)<$>y
g[]=[]
g s=(toEnum.sum.zipWith((*).(2^))[7,6..0])s:g(drop 8s)
g.f
f converts the string to a list of bits by comparing each character to the first one, turning the Bools into zeros and ones with fromEnum. g divides this list into groups of 8, converts them to decimal, and takes the value of the resulting number as an Enum, which Char is an instance of.
Changes:
- -19 bytes thanks to @Laikoni (removing import, embedding
mapinto function) - -12 bytes inspired by @Lynn's answer (getting rid of
takeby zipping with shorter list)
-
2\$\begingroup\$ You can use
toEnuminstead ofchrand drop the import. Also themapcan be included intog. The space between8 scan be removed. \$\endgroup\$Laikoni– Laikoni2018年04月23日 11:02:16 +00:00Commented Apr 23, 2018 at 11:02
Forth (gforth), 83 bytes
: f over c@ 0 rot 2 do 2* over i 4 pick + c@ <> - i 8 mod 1 = if emit 0 then loop ;
Input is a standard Forth string (address and length) output is printed to stdout
Explanation
over c@ \ get the value of the first character in the string
0 rot \ add a starting "byte" value of 0 and put the length on top of the stack
2 do \ start a loop from 2 to length-1
2* \ multiply the current byte value by 2 (shift "bits" left one)
over \ copy the reference char to the top of the stack
i 4 pick + \ add the index and the starting address to get address of the current char
c@ <> \ get the char at the address and check if not equal to the reference char
- \ subtract the value from our bit count, -1 is default "true" value in forth
i 8 mod 1 = \ check if we are at the last bit in a byte
if \ if we are
emit 0 \ print the character and start our new byte at 0
then \ and end the if statement
loop \ end the loop