Given a non-empty string, keep removing the first and last characters until you get to one or two characters.
For example, if the string was abcde, your program should print:
abcde
bcd
c
However, if it was abcdef, it should stop at two characters:
abcdef
bcde
cd
Trailing newlines and trailing spaces at the end of each line are optional. You can have as many as you want or none.
Test cases
ABCDEFGHIJKLMNOPQRSTUVWXYZ -> ABCDEFGHIJKLMNOPQRSTUVWXYZ
BCDEFGHIJKLMNOPQRSTUVWXY
CDEFGHIJKLMNOPQRSTUVWX
DEFGHIJKLMNOPQRSTUVW
EFGHIJKLMNOPQRSTUV
FGHIJKLMNOPQRSTU
GHIJKLMNOPQRST
HIJKLMNOPQRS
IJKLMNOPQR
JKLMNOPQ
KLMNOP
LMNO
MN
ABCDEFGHIJKLMNOPQRSTUVWXYZ! -> ABCDEFGHIJKLMNOPQRSTUVWXYZ!
BCDEFGHIJKLMNOPQRSTUVWXYZ
CDEFGHIJKLMNOPQRSTUVWXY
DEFGHIJKLMNOPQRSTUVWX
EFGHIJKLMNOPQRSTUVW
FGHIJKLMNOPQRSTUV
GHIJKLMNOPQRSTU
HIJKLMNOPQRST
IJKLMNOPQRS
JKLMNOPQR
KLMNOPQ
LMNOP
MNO
N
A -> A
AB -> AB
Remember this is code-golf, so the code with the smallest number of bytes wins.
-
\$\begingroup\$ Can the output be a list of strings, instead of printing the strings? \$\endgroup\$Greg Martin– Greg Martin2016年11月19日 02:24:04 +00:00Commented Nov 19, 2016 at 2:24
-
\$\begingroup\$ @GregMartin Yes. \$\endgroup\$Oliver Ni– Oliver Ni2016年11月19日 02:29:05 +00:00Commented Nov 19, 2016 at 2:29
-
1\$\begingroup\$ Do we need to have the leading spaces on each line? \$\endgroup\$ETHproductions– ETHproductions2016年11月19日 02:29:45 +00:00Commented Nov 19, 2016 at 2:29
-
\$\begingroup\$ @ETHproductions Yes. \$\endgroup\$Oliver Ni– Oliver Ni2016年11月19日 02:35:43 +00:00Commented Nov 19, 2016 at 2:35
-
9\$\begingroup\$ @Oliver That's important information, you should include it in the text \$\endgroup\$Luis Mendo– Luis Mendo2016年11月19日 02:48:45 +00:00Commented Nov 19, 2016 at 2:48
27 Answers 27
V, 10 bytes
ò^llYpr $x
Explanation:
ò^ll " While there are at least two non-whitespace characters on the current line
Y " Yank this line
p " Paste it below
r " Replace the first character with a space
$ " Move to the end of the line
x " Delete a character
ES6 (Javascript), (削除) 47 (削除ここまで), (削除) 48 (削除ここまで), 43 bytes
EDIT: Replaced ternary operator with &&, prefixed padding string with the newline. Thanks @Neil for an excellent advice !
EDIT: included the function name for the recursive invocation, stripped one byte off by using a literal newline
Golfed
R=(s,p=`
`)=>s&&s+p+R(s.slice(1,-1),p+' ')
Test
R=(s,p=`
`)=>s&&s+p+R(s.slice(1,-1),p+' ')
console.log(R("ABCDEFGHIJKLMNOPQRSTUVWXYZ"))
ABCDEFGHIJKLMNOPQRSTUVWXYZ
BCDEFGHIJKLMNOPQRSTUVWXY
CDEFGHIJKLMNOPQRSTUVWX
DEFGHIJKLMNOPQRSTUVW
EFGHIJKLMNOPQRSTUV
FGHIJKLMNOPQRSTU
GHIJKLMNOPQRST
HIJKLMNOPQRS
IJKLMNOPQR
JKLMNOPQ
KLMNOP
LMNO
MN
console.log(R("ABCDEFGHIJKLMNOPQRSTUVWXYZ!"))
ABCDEFGHIJKLMNOPQRSTUVWXYZ!
BCDEFGHIJKLMNOPQRSTUVWXYZ
CDEFGHIJKLMNOPQRSTUVWXY
DEFGHIJKLMNOPQRSTUVWX
EFGHIJKLMNOPQRSTUVW
FGHIJKLMNOPQRSTUV
GHIJKLMNOPQRSTU
HIJKLMNOPQRST
IJKLMNOPQRS
JKLMNOPQR
KLMNOPQ
LMNOP
MNO
N
-
1\$\begingroup\$ I notice that @xnor starts with
pequal to a newline and a space; maybe that could help you too. \$\endgroup\$Neil– Neil2016年11月19日 13:22:06 +00:00Commented Nov 19, 2016 at 13:22 -
1\$\begingroup\$ Oh, and you can also use
s&&instead ofs?...:''. \$\endgroup\$Neil– Neil2016年11月19日 14:15:21 +00:00Commented Nov 19, 2016 at 14:15
Python, 45 bytes
f=lambda s,p='\n ':s and s+p+f(s[1:-1],p+' ')
Recursively outputs the string, plus a newline, plus the leading spaces for the next line, plus the recursive result for the shortened string with an extra space in the prefix.
If a leading newline was allowed, we could save a byte:
f=lambda s,p='\n':s and p+s+f(s[1:-1],p+' ')
Compare with a program (49 bytes in Python 2):
s=input();p=''
while s:print p+s;s=s[1:-1];p+=' '
Brainfuck, 67 bytes
>>,[.>,]<[>++++++++++.<[-]<[<]>[-]++++++++[-<++++>]<[<]>[.>]>[.>]<]
This should work on all brainfuck flavors.
Ungolfed code:
# Print and read input_string into memory
>>,[.>,]<
while input_string is not empty [
# Print newline
>+++++ +++++.<
# Remove last character
[-]
# GOTO start of input_string
<[<]>
# Remove first character
[-]
# Add space to space_buffer
+++++ +++[-<++++>]
# GOTO start of space_buffer
<[<]>
# Print space_buffer
[.>]
# Print input_string
>[.>]
<]
There should still be some bytes to chop off here; I've only recently began using brainfuck, so my pointer movement is probably very inefficient.
J, 39 19 16 bytes
[:|:]#"0~#\.<.#\
This was a nice example of how a different perspective can allow J to express a problem more naturally. Originally, I was seeing the problem "horizontally", as described in the OP -- a sequence with successive edges being removed:
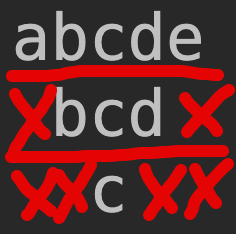{kind=link}
But you can also view it vertically, as a kind of upside down histogram:
{kind=link}
From this perspective, we are just repeating each letter some number of times, an operation J's copy primitive # can accomplish in 1 character.
Consider abcde:
#\.<.#\Determine the number of times to repeat each character, ie, produce the mask1 2 3 2 1:#\ => 1 2 3 4 5 #\. => 5 4 3 2 1 ---------------- <. => 1 2 3 2 1 NB. elementwise min]#"0~Use that mask to duplicate the input:a bb ccc dd e[:|:Transpose:abcde bcd c
Python 2, 50 bytes
def f(i,j=0):
print' '*j+i
if i:f(i[1:-1],j+1)
Simple recursive function that keeps shortening the string until it disappears.
Call as f('string')
Output
string
trin
ri
Perl, 31 bytes
30 bytes of code + -p flag.
s/( *)\S(.+).$/$&
1ドル2ドル/&&redo
To run it :
perl -pE 's/( *)\S(.+).$/$&
1ドル2ドル/&&redo' <<< "abcdef"
Explanations : The \S and .$ correspond to the first and last character, (.+) the middle and ( *) to the trailing spaces that are added every time we remove one character from the beginning. So the regex removes one character from the beginning, one from the end, and add one leading space each time.
GNU sed 24 Bytes
Includes +2 for -rn
:
p
s/[^ ](.+)./ 1円/
t
Prints, replaces the first non-space character with a space, and deletes the last character until nothing changes.
-
\$\begingroup\$ This is really nice. \$\endgroup\$Jonah– Jonah2021年05月11日 19:49:01 +00:00Commented May 11, 2021 at 19:49
MATL, 9 bytes
tg!*YRPRc
This produces trailing spaces and newlines.
Explanation
t % Input string implicitly. Duplicate
g! % Convert to logical and transpose: gives a column vector of ones
* % Multiply with broadcast. This gives a square matrix with the string's
% ASCII codes on each row
YR % Lower triangular part: make elements above the diagonal 0
P % Flip vertically
R % Upper triangular part: make elements below the diagonal 0
c % Convert to char. Implicitly display, with char 0 shown as space
Batch, 92 bytes
@set/ps=
@set t=
:g
@echo %t%%s%
@set t= %t%
@set s=%s:~1,-1%
@if not "%s%"=="" goto g
Takes input on STDIN.
C, 73 bytes
f(char*s){char*b=s,*e=s+strlen(s)-1;while(e-b>-1)puts(s),*b++=32,*e--=0;}
Ungolfed:
f(char*s) {
char *b=s,
*e=s+strlen(s)-1;
while (e-b>-1)
puts(s),
*b++=32,
*e--=0;
}
Usage:
main(){
char a[] = "abcde";
f(a);
}
05AB1E, 8 bytes
Code:
ÐvNú,¦ ̈D
Explanation:
Ð # Triplicate the input
v # Length times do...
Nú, # Prepend N spaces and print with a newline
¦ ̈ # Remove the first and the last character
D # Duplicate that string
Uses the CP-1252 encoding. Try it online!
Haskell, (削除) 47 (削除ここまで) 43 bytes
f s@(a:b:c)=s:map(' ':)(f.init$b:c)
f s=[s]
Try it on Ideone. Output is a list of strings which was allowed in the comments of the challenge. To print, run with (putStr.unlines.f) instead of just f.
Edit: Saved 4 bytes after noticing that trailing whitespace is allowed.
Prelude> (putStr.unlines.f)"codegolf"
codegolf
odegol
dego
eg
--(trailing whitespace)
Perl 6, 42 bytes
for get,{S/\w(.*)./ 0ドル/}.../\s..?$/ {.put}
Expanded:
for
# generate the sequence
get, # get a line from the input
{ # bare block lambda with implicit parameter 「$_」
# used to produce the rest of the sequence
S/ # replace
\w # a word character ( to be removed )
( # set 「0ドル」
.* # any number of any characters
)
. # any character ( to be removed )
/ 0ドル/ # append a space
}
... # repeat that until
/ # match
\s # whitespace
. # any character
.? # optional any character
$ # end of string
/
{
.put # print $_ with trailing newline
}
Vyxal C, 4 bytes
‡ḢṪ↔
i have turned to the dark side
i am now a flag abuser
thanks to lyxal for helping me get to the 4-byte sol (from 8 bytes)
Explanation
↔ While results have not reached a fixed point
‡ 2-byte function
Ḣ a[1:]
Ṫ a[:-1]
C Center the list and join on newlines
The below less cheese program does the same thing. øĊ is the same as the C flag.
Vyxal j, 6 bytes
‡ḢṪ↔øĊ
Since outputting a list was allowed, using the j flag to join on newlines is reasonable. You can also append ⁋ to use no flags at all.
-
\$\begingroup\$ I'm proud of you for joining the flag side of vyxal. Very good \$\endgroup\$2021年05月11日 05:20:32 +00:00Commented May 11, 2021 at 5:20
-
\$\begingroup\$ @lyxal i am suffering \$\endgroup\$2021年05月11日 05:22:29 +00:00Commented May 11, 2021 at 5:22
Jelly, 9 bytes
J’6ẋoUμ+Y
If the input is of length \2ドルn\$, this outputs with \$n\$ lines of trailing newlines and spaces
How it works
J’6ẋoUμ+Y - Main link. Takes a string A on the left
μ+ - Do the following twice:
J - Yield [1, 2, 3, ..., 2n]
’ - Decrement; [0, 1, 2, ..., 2n-1]
6ẋ - Repeat a space that many times; [[], [' '], [' ', ' '], ...]
U - Reverse A
o - Logical OR
Y - Join by newlines
The logical OR command o has the following behaviour:
[[], [5], [6, 7], [8, 9, 10]] o [1, 2, 3, 4] = [[1, 2, 3, 4], [5, 2, 3, 4], [6, 7, 3, 4], [8, 9, 10, 4]]
so only the leftmost characters are replaced by spaces. We do this twice, reversing each time, to get both the left and right side
C++14, 117 bytes
auto f(auto s){decltype(s)r;auto b=s.begin();auto e=s.rbegin();while(e.base()-b>0)r+=s+"\n",*b++=32,*e++=0;return r;}
Assumes input s is a std::string and returns the animated text.
Ungolfed:
auto f(auto s){
decltype(s)r;
auto b=s.begin();
auto e=s.rbegin();
while(e.base()-b>0){
r+=s+"\n";
*b++=32;
*e++=0;
}
return r;
}
Usage:
main(){
std::string a{"abcdef"};
std::cout << f(a);
std::string b{"abcde"};
std::cout << f(b);
}
Vim - 14 keystrokes
qqYp^r $x@qq@q
Explanation:
qq -- record a macro named 'q'
Y -- Copy current line
p -- Paste it
^r -- Replace the first non-space character on the new line with a space
$x -- Delete the last character on the line
@q -- Recursively call the 'q' macro
q -- Stop recording the 'q' macro
@q -- Run the 'q' macro
Vim automatically kills the macro once we're out of characters
Snap! - 16 blocks
Snap!
Output is self-centering. The 'wait' is for humans.
PHP, 91 bytes
<?for(;$i<.5*$l=strlen($s=$_GET[s]);$i++)echo str_pad(substr($s,$i,$l-$i*2),$l," ",2)."\n";
Usage: save in a file and call from the browser:
http://localhost/codegolf/string-middle.php?s=ABCDEFGHIJKLMNOPQRSTUVWXYZ
Raw output:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
BCDEFGHIJKLMNOPQRSTUVWXY
CDEFGHIJKLMNOPQRSTUVWX
DEFGHIJKLMNOPQRSTUVW
EFGHIJKLMNOPQRSTUV
FGHIJKLMNOPQRSTU
GHIJKLMNOPQRST
HIJKLMNOPQRS
IJKLMNOPQR
JKLMNOPQ
KLMNOP
LMNO
MN
http://localhost/codegolf/string-middle.php?s=1ABCDEFGHIJKLMNOPQRSTUVWXYZ
Raw output:
1ABCDEFGHIJKLMNOPQRSTUVWXYZ
ABCDEFGHIJKLMNOPQRSTUVWXY
BCDEFGHIJKLMNOPQRSTUVWX
CDEFGHIJKLMNOPQRSTUVW
DEFGHIJKLMNOPQRSTUV
EFGHIJKLMNOPQRSTU
FGHIJKLMNOPQRST
GHIJKLMNOPQRS
HIJKLMNOPQR
IJKLMNOPQ
JKLMNOP
KLMNO
LMN
M
Mathematica, 71 bytes
Table[#~StringTake~{i,-i},{i,Ceiling[StringLength@#/2]}]~Column~Center&
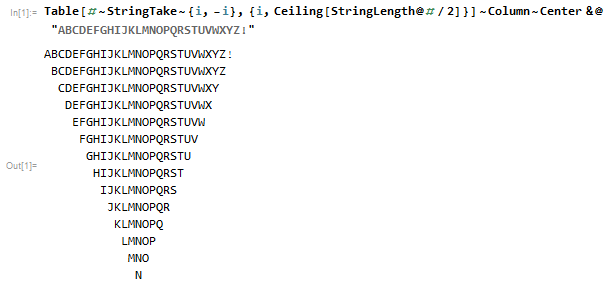{kind=link}
Stax, 7 bytes
ö÷e╧╤ù◘
Explanation
|]miTiNt
|]m map each suffix to:
iT remove iteration count elements from right
iNt pad with iteration count number of spaces on left
Stax, 117 bytes
c%{d
xitiT|c
{|,}20*|:xi{xitiTx%|CPFxP
{|,}20*|:xi{xitiTx%|CPFxitiNtP
{|,}20*|:xi{xitiTx%|CPFxitiTx%|CP
F
The more fun version. Since stax supports requestAnimationFrame from js, |, and |: can be used to animate each step.
APL (Dyalog Unicode), (削除) 25 (削除ここまで) (削除) 16 (削除ここまで) 15 bytes
-9 bytes thanks to Jonah's comment!
-1 bytes thanks to Adám!
{⍉↑⍵/ ̈⍨⌊∘⌽⍨⍳⍴⍵}
This is the dfn taking the string as right input ⍵.
⍳⍴⍵ the indices of the input string.
⌊∘⌽⍨ element-wise minimum of the indices with the indices reversed. This is the number of times each character appears.
⍵/ ̈⍨ repeat each character that many times.
↑ arranges the repeated characters in a 2d matrix, padding shorter strings with spaces.
⍉ transposes the matrix.
-
1\$\begingroup\$ After much pondering, I found another approach that might save you bytes too. I'll add explanation later, but basically the idea is to duplicate the letters "vertically" down. Ofc you have to do it horizontally, then transpose. \$\endgroup\$Jonah– Jonah2021年05月11日 18:59:39 +00:00Commented May 11, 2021 at 18:59
-
1\$\begingroup\$ @Jonah thanks a lot, this definitely saved some bytes. I've changed my code according to your comment, but from what I can tell this is now very similar to your J code. \$\endgroup\$ovs– ovs2021年05月11日 21:24:58 +00:00Commented May 11, 2021 at 21:24
-
\$\begingroup\$ Sixteen each :) \$\endgroup\$Jonah– Jonah2021年05月11日 23:57:13 +00:00Commented May 11, 2021 at 23:57
-
1\$\begingroup\$
(⌽⌊⊢)→⌊∘⌽⍨\$\endgroup\$Adám– Adám2022年02月02日 12:54:56 +00:00Commented Feb 2, 2022 at 12:54