Roary: rapid large-scale prokaryote pan genome analysis
- PMID: 26198102
- PMCID: PMC4817141
- DOI: 10.1093/bioinformatics/btv421
Roary: rapid large-scale prokaryote pan genome analysis
Abstract
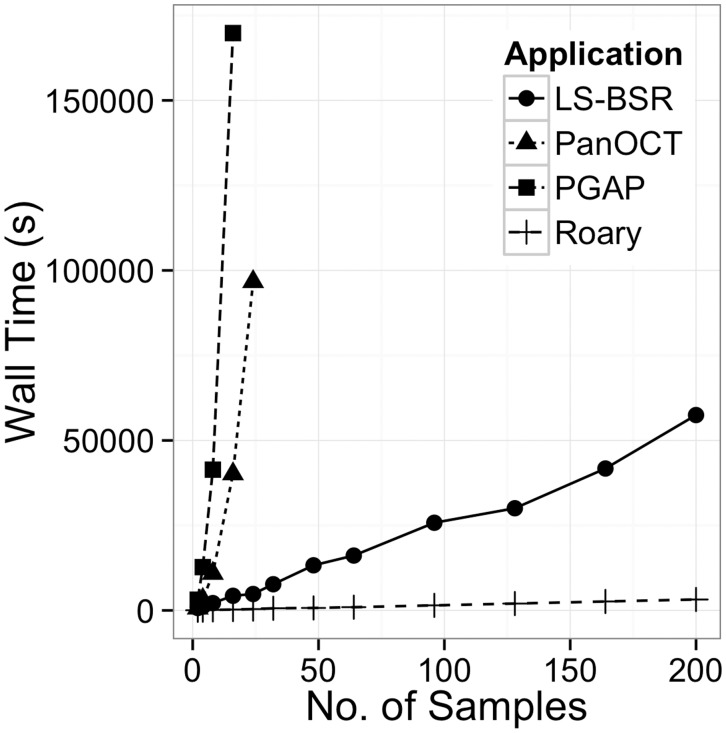
A typical prokaryote population sequencing study can now consist of hundreds or thousands of isolates. Interrogating these datasets can provide detailed insights into the genetic structure of prokaryotic genomes. We introduce Roary, a tool that rapidly builds large-scale pan genomes, identifying the core and accessory genes. Roary makes construction of the pan genome of thousands of prokaryote samples possible on a standard desktop without compromising on the accuracy of results. Using a single CPU Roary can produce a pan genome consisting of 1000 isolates in 4.5 hours using 13 GB of RAM, with further speedups possible using multiple processors.
Availability and implementation: Roary is implemented in Perl and is freely available under an open source GPLv3 license from http://sanger-pathogens.github.io/Roary
Contact: roary@sanger.ac.uk
Supplementary information: Supplementary data are available at Bioinformatics online.
© The Author 2015. Published by Oxford University Press.
Figures
{kind=link}
References
-
- Medini D., et al. (2005) The microbial pan-genome. Curr. Opin. Genet. Dev., 15, 589–594. - PubMed
-
- Nguyen N., et al. (2014) Building a pangenome reference for a population. In: Sharan R. (ed.) Research in Computational Molecular Biology, Springer International Publishing, pp. 207–221.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources