{kind=link}
Computer Networking: A Top-Down Approach (7th Edition)
Computer Networking: A Top-Down Approach (7th Edition)
7th Edition
ISBN: 9780133594140
Author: James Kurose, Keith Ross
Publisher: PEARSON
expand_more
expand_more
format_list_bulleted
Bartleby Related Questions Icon
Related questions
Question
{kind=link}
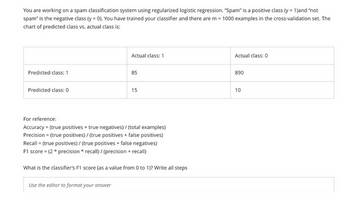
Transcribed Image Text:You are working on a spam classification system using regularized logistic regression. "Spam" is a positive class (y = 1)and "not
spam" is the negative class (y=0). You have trained your classifier and there are m= 1000 examples in the cross-validation set. The
chart of predicted class vs. actual class is:
Predicted class: 1
Predicted class: 0
Actual class: 1
85
15
For reference:
Accuracy = (true positives + true negatives)/(total examples)
Precision = (true positives)/(true positives + false positives)
Recall = (true positives)/ (true positives + false negatives)
F1 score = (2* precision * recall)/(precision + recall)
What is the classifier's F1 score (as a value from 0 to 1)? Write all steps
Use the editor to format your answer
Actual class: 0
890
10
Expert Solution
Check MarkThis question has been solved!
Explore an expertly crafted, step-by-step solution for a thorough understanding of key concepts.
bartleby
Step by stepSolved in 2 steps with 1 images
{kind=link}
Knowledge Booster
Background pattern image
Similar questions
- The benefits of switching to all-subsets regression from stepwise regression are broken forth in great depth below. .arrow_forwardYou decide to run a simpler model to predict churn, using only the variables tenure (in months) and TotalCharges (in US$). The output is given below. The AIC of this model is 4727.6 (in contrast to the AIC of 4240 for the full model). On the basis of this which model would be expected to give superior predictive performance? Actual ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) 2.471e-01 5.360e-02 4.611 4.01e-06 *** ## tenure < 2e-16 *** -1.124e-01 5.816e-03 -19.334 ## TotalCharges 8.236e-04 5.618e-05 14.660 < 2e-16 *** ## No --- ## Signif. codes: 0 ## Yes Yes ## Null deviance: 5701.5 on 4921 ## Residual deviance: 4721.6 on 4919 ## AIC: 4727.6 515 345 ## (Dispersion parameter for binomial family taken to be 1) ## Predicted ***** No 795 3267 0.001 Confusion Matrix (Training) **** Actual 0.01 Yes No degrees of freedom degrees of freedom Yes The simpler model (with just tenure and TotalCharges) The full model (with all variables) 0.05 0.1 220 145 Predicted No 339...arrow_forwardThe following is true about sensitivity: Group of answer choices a) The output of the model is said to be inversely sensitive if the output of the model changes a small amount for a large change in an input variable b) Sensitivity is not an important concept in modeling c) It can help the modeler tell, on a relative basis, what are the important variables d) A variable is considered NOT very sensitive if a small change in the variable results `in a large change in the output of the model.arrow_forward
- We've built a logistic regression model in RapidMiner, and would like to use it to make predictions for some new data points. Which operator do we need: Performance Apply Model Cross Validation O Nominal to Numerical.arrow_forwardQuestion 48. Let us return to the Titanic data set. We now have learned several models and want to choose the best one. We used three different methods to validate these models: The training error rate (apparent error rate), the error rate on an external test set and the error rate estimated by a 10-fold cross validation. Training Error | Error on the test set | Cross Validation Error 0.18 Learner Decision Tree 0.22 0.21 Random Forest 0.01 0.10 0.12 1-Nearest-Neighbour 0.18 0.19 Which of the following statements are correct? a) 1-Nearest-Neighbour has a perfect training error and hence it should be used here. b) Random Forests outperforms both 1-Nearest-Neighbour and the Decision Tree in terms of prediction error. c) Not just in this case, but in general, Cross Validation is the better validation strategy and should always be preferred over the error on a single test set. d) Not just in this case, but in general, Decision Trees always perform worse than Random Forests.arrow_forwardThis is a binary classification problem, y has two values (0 or 1), and X (feature) has three dimensions. • Use a logistic regression model to project X to y (classify X into two categories: 0 or 1). • The initialization is: w1 = 0, w2 = 0, w3 = 0, b = 0, Learning rate is 2. • You must use Gradient Descent for logistic regression in this question. • The regression should stop after one iteration. Calculation process and formulas must be included in your answer! You must answer this question by manual calculation, but not programming.arrow_forward
- Assume the following simple regression model, Y = β0 + β1X + ε ε ∼ N(0, σ^2 ) Now run the following R-code to generate values of σ^2 = sig2, β1 = beta1 and β0 = beta0. Simulate the parameters using the following codes: Code: # Simulation ## set.seed("12345") beta0 <- rnorm(1, mean = 0, sd = 1) ## The true beta0 beta1 <- runif(n = 1, min = 1, max = 3) ## The true beta1 sig2 <- rchisq(n = 1, df = 25) ## The true value of the error variance sigmaˆ2 ## Multiple simulation will require loops ## nsample <- 10 ## Sample size n.sim <- 100 ## The number of simulations sigX <- 0.2 ## The variances of X # # Simulate the predictor variable ## X <- rnorm(nsample, mean = 0, sd = sqrt(sigX)) Q1 Fix the sample size nsample = 10 . Here, the values of X are fixed. You just need to generate ε and Y . Execute 100 simulations (i.e., n.sim = 100). For each simulation, estimate the regression coefficients (β0, β1) and the error variance (σ 2 ). Calculate the mean of...arrow_forwardAn instructor who taught two sections of engineering statistics last term, the first with 25 students and the second with 40, decided to assign a term project. After all projects had been turned in, the instructor randomly ordered them before grading. Consider the first 15 graded projects. (a) What is the probability that exactly 10 of these are from the second section? (Round your answer to four decimal places.) (b) What is the probability that at least 10 of these are from the second section? (Round your answer to four decimal places.) (c) What is the probability that at least 10 of these are from the same section? (Round your answer to four decimal places.) (d) What are the mean value and standard deviation of the number among these 15 that are from the second section? (Round your mean to the nearest whole number and your standard deviation to three decimal places.) mean projectsstandard deviation projects (e) What are the mean value and standard deviation of...arrow_forwardUse decision tree to further explore the dataset, where the dependent variable is ‘smoker’. Please explain the approach taken. [No more than 300 words]arrow_forward
- In this section we create the model object and define the loss function and optimizer. For the loss function use nn.CrossEntropyLoss() instead of the mean-squared loss done in class. Use the same optimizer as in class. learning_rate = 0.001 num_epochs = 5 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #this is to use gpu if available # **create your neural net model here, call the variable 'model'** # ** complete following lines of code to define loss function and optimizer #criterion = **complete this** #optimizer = **complete this**arrow_forward2. Can you design a binary classification experiment with 100 total population (TP+TN+FP+ FN), with precision (TP/(TP+FP)) of 1/2, with sensitivity (TP/(TP+FN)) of 2/3, and specificity (TN/(FP+TN)) of 3/5? (Please consider the population to consist of 100 individuals.)arrow_forward
arrow_back_ios
arrow_forward_ios
Recommended textbooks for you
- Text book imageComputer Networking: A Top-Down Approach (7th Edi...Computer EngineeringISBN:9780133594140Author:James Kurose, Keith RossPublisher:PEARSONText book imageComputer Organization and Design MIPS Edition, Fi...Computer EngineeringISBN:9780124077263Author:David A. Patterson, John L. HennessyPublisher:Elsevier ScienceText book imageNetwork+ Guide to Networks (MindTap Course List)Computer EngineeringISBN:9781337569330Author:Jill West, Tamara Dean, Jean AndrewsPublisher:Cengage Learning
- Text book imageConcepts of Database ManagementComputer EngineeringISBN:9781337093422Author:Joy L. Starks, Philip J. Pratt, Mary Z. LastPublisher:Cengage LearningText book imagePrelude to ProgrammingComputer EngineeringISBN:9780133750423Author:VENIT, StewartPublisher:Pearson EducationText book imageSc Business Data Communications and Networking, T...Computer EngineeringISBN:9781119368830Author:FITZGERALDPublisher:WILEY
Text book image
Computer Networking: A Top-Down Approach (7th Edi...
Computer Engineering
ISBN:9780133594140
Author:James Kurose, Keith Ross
Publisher:PEARSON
Text book image
Computer Organization and Design MIPS Edition, Fi...
Computer Engineering
ISBN:9780124077263
Author:David A. Patterson, John L. Hennessy
Publisher:Elsevier Science
Text book image
Network+ Guide to Networks (MindTap Course List)
Computer Engineering
ISBN:9781337569330
Author:Jill West, Tamara Dean, Jean Andrews
Publisher:Cengage Learning
Text book image
Concepts of Database Management
Computer Engineering
ISBN:9781337093422
Author:Joy L. Starks, Philip J. Pratt, Mary Z. Last
Publisher:Cengage Learning
Text book image
Prelude to Programming
Computer Engineering
ISBN:9780133750423
Author:VENIT, Stewart
Publisher:Pearson Education
Text book image
Sc Business Data Communications and Networking, T...
Computer Engineering
ISBN:9781119368830
Author:FITZGERALD
Publisher:WILEY